Szybsze cykle wydawania są jedną z głównych zalet architektur mikrousług. Jednak bez dobrego procesu ciągłej integracji/ciągłego wdrażania nie uzyskasz elastyczności, którą obiecują mikrousługi. W tym artykule opisano wyzwania i zaleca się kilka podejść do problemu.
Co to jest ciągła integracja/ciągłe wdrażanie?
Kiedy mówimy o ciągłej integracji/ciągłego wdrażania, naprawdę mówimy o kilku powiązanych procesach: ciągłej integracji, ciągłego dostarczania i ciągłego wdrażania.
ciągła integracja. Zmiany kodu są często scalane z gałęzią główną. Zautomatyzowane procesy kompilacji i testowania zapewniają, że kod w gałęzi głównej jest zawsze jakością produkcyjną.
ciągłe dostarczanie. Wszelkie zmiany kodu, które przechodzą proces ciągłej integracji, są automatycznie publikowane w środowisku przypominającym środowisko produkcyjne. Wdrożenie w środowisku produkcyjnym na żywo może wymagać ręcznego zatwierdzania, ale w przeciwnym razie jest zautomatyzowane. Celem jest to, że kod powinien być zawsze gotowy do wdrożenia w środowisku produkcyjnym.
ciągłe wdrażanie. Zmiany kodu, które przechodzą poprzednie dwa kroki, są automatycznie wdrażane w środowisku produkcyjnym.
Poniżej przedstawiono kilka celów niezawodnego procesu ciągłej integracji/ciągłego wdrażania dla architektury mikrousług:
Każdy zespół może tworzyć i wdrażać usługi, które są jej właścicielami niezależnie, bez wpływu na inne zespoły lub zakłócania ich działania.
Zanim nowa wersja usługi zostanie wdrożona w środowisku produkcyjnym, zostanie wdrożona w środowiskach tworzenia i testowania/kontroli jakości na potrzeby walidacji. Bramy jakości są wymuszane na każdym etapie.
Nową wersję usługi można wdrożyć obok poprzedniej wersji.
Obowiązują wystarczające zasady kontroli dostępu.
W przypadku konteneryzowanych obciążeń można ufać obrazom kontenerów wdrożonym w środowisku produkcyjnym.
Dlaczego niezawodny potok ciągłej integracji/ciągłego wdrażania ma znaczenie
W tradycyjnej aplikacji monolitycznej istnieje pojedynczy potok kompilacji, którego dane wyjściowe są plikiem wykonywalnym aplikacji. Wszystkie prace programistyczne są wprowadzane do tego potoku. Jeśli zostanie znaleziona usterka o wysokim priorytcie, należy zintegrować, przetestować i opublikować poprawkę, co może opóźnić wydanie nowych funkcji. Możesz rozwiązać te problemy, korzystając z dobrze uwzględnionych modułów i używając gałęzi funkcji, aby zminimalizować wpływ zmian kodu. Jednak wraz ze wzrostem złożoności aplikacji i dodaniu większej liczby funkcji proces wydawania monolitu zwykle staje się bardziej kruchy i może ulec awarii.
Zgodnie z filozofią mikrousług nigdy nie powinno być długie szkolenie wydania, w którym każdy zespół musi się w kolejce. Zespół tworzący usługę "A" może w dowolnym momencie wydać aktualizację bez oczekiwania na scalenie, przetestowanie i wdrożenie zmian w usłudze "B".
diagram 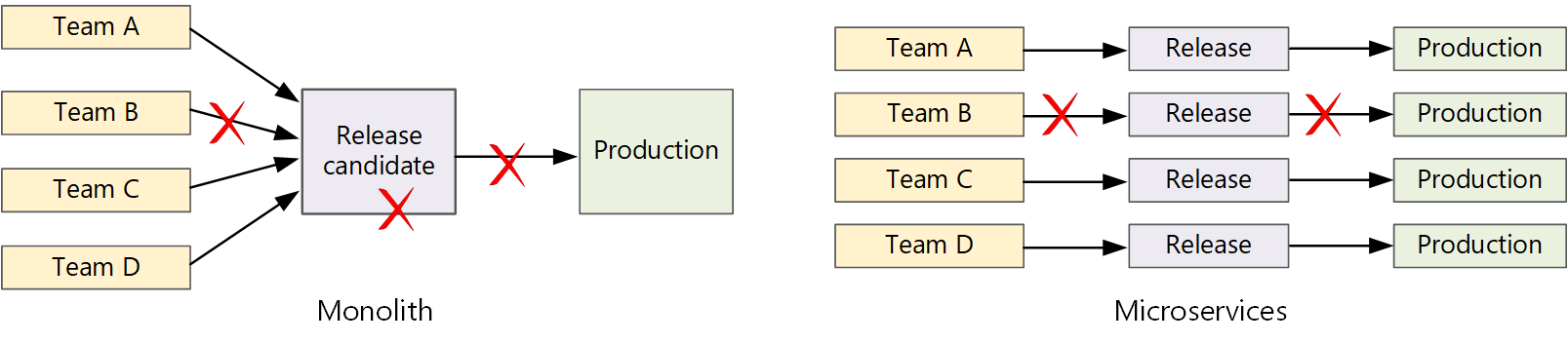
Aby osiągnąć wysoką szybkość wydawania, potok wydania musi być zautomatyzowany i wysoce niezawodny, aby zminimalizować ryzyko. W przypadku wydania do środowiska produkcyjnego co najmniej raz dziennie regresje lub przerwy w działaniu usługi muszą być rzadkie. W tym samym czasie, jeśli zła aktualizacja zostanie wdrożona, musisz mieć niezawodny sposób szybkiego wycofywania lub wycofywania do poprzedniej wersji usługi.
Wyzwania
Wiele małych niezależnych baz kodu. Każdy zespół jest odpowiedzialny za tworzenie własnej usługi przy użyciu własnego potoku kompilacji. W niektórych organizacjach zespoły mogą używać oddzielnych repozytoriów kodu. Oddzielne repozytoria mogą prowadzić do sytuacji, w której wiedza na temat sposobu kompilowania systemu jest rozłożona na zespoły, a nikt w organizacji nie wie, jak wdrożyć całą aplikację. Co się dzieje na przykład w scenariuszu odzyskiwania po awarii, jeśli chcesz szybko wdrożyć w nowym klastrze?
ograniczania ryzyka: ma ujednolicony i zautomatyzowany potok do kompilowania i wdrażania usług, dzięki czemu ta wiedza nie jest "ukryta" w każdym zespole.
wiele języków i struktur. Każdy zespół korzystający z własnych technologii może być trudny do utworzenia pojedynczego procesu kompilacji, który działa w całej organizacji. Proces kompilacji musi być wystarczająco elastyczny, aby każdy zespół mógł dostosować go do wyboru języka lub struktury.
ograniczania ryzyka: konteneryzowanie procesu kompilacji dla każdej usługi. W ten sposób system kompilacji musi mieć możliwość uruchamiania kontenerów.
integracja i testowanie obciążenia. Zespoły publikujące aktualizacje we własnym tempie mogą być trudne do zaprojektowania niezawodnego kompleksowego testowania, zwłaszcza gdy usługi mają zależności od innych usług. Ponadto uruchomienie pełnego klastra produkcyjnego może być kosztowne, dlatego jest mało prawdopodobne, aby każdy zespół uruchamiał własny pełny klaster w skali produkcyjnej, tylko do testowania.
Release Management. Każdy zespół powinien mieć możliwość wdrożenia aktualizacji w środowisku produkcyjnym. Nie oznacza to, że każdy członek zespołu ma uprawnienia do tego. Jednak posiadanie scentralizowanej roli Menedżera wersji może zmniejszyć szybkość wdrożeń.
środki zaradcze: tym bardziej proces ciągłej integracji/ciągłego wdrażania jest zautomatyzowany i niezawodny, tym mniej powinno być konieczne dla urzędu centralnego. Oznacza to, że możesz mieć różne zasady dotyczące wydawania głównych aktualizacji funkcji w porównaniu z drobnymi poprawkami błędów. Decentralizacja nie oznacza zerowego ładu.
aktualizacje usługi service. Podczas aktualizowania usługi do nowej wersji nie należy przerywać innych usług, które od niej zależą.
środki zaradcze: użyj technik wdrażania, takich jak niebiesko-zielony lub kanary, w przypadku zmian niełamających się. W przypadku zmian powodujących niezgodność interfejsu API wdróż nową wersję obok poprzedniej wersji. Dzięki temu usługi, które korzystają z poprzedniego interfejsu API, można zaktualizować i przetestować pod kątem nowego interfejsu API. Zobacz Aktualizowanie usługponiżej.
Monorepo a multi-repo
Przed utworzeniem przepływu pracy ciągłej integracji/ciągłego wdrażania musisz wiedzieć, jak baza kodu będzie ustrukturyzowana i zarządzana.
- Czy zespoły pracują w oddzielnych repozytoriach lub w monorepo (pojedyncze repozytorium)?
- Jaka jest strategia rozgałęziania?
- Kto może wypychać kod do środowiska produkcyjnego? Czy istnieje rola menedżera wersji?
Podejście monorepo zyskuje na korzyść, ale istnieją zalety i wady obu.
| Monorepo | Wiele repozytoriów | |
|---|---|---|
| zalety | Udostępnianie kodu Łatwiejsze do standaryzacji kodu i narzędzi Łatwiejsze refaktoryzację kodu Odnajdywanie — pojedynczy widok kodu |
Wyczyść własność na zespół Potencjalnie mniej konfliktów scalania Pomaga wymuszenie oddzielenia mikrousług |
| wyzwania | Zmiany kodu udostępnionego mogą mieć wpływ na wiele mikrousług Większy potencjał konfliktów scalania Narzędzia muszą być skalowane do dużej bazy kodu Kontrola dostępu Bardziej złożony proces wdrażania |
Trudniejsze do udostępnienia kodu Trudniejsze do wymuszania standardów kodowania Zarządzanie zależnościami Baza kodów rozproszonych, słaba możliwość odnajdywania Brak udostępnionej infrastruktury |
Aktualizowanie usług
Istnieją różne strategie aktualizowania usługi, która jest już w środowisku produkcyjnym. W tym miejscu omówiono trzy typowe opcje: aktualizacja stopniowa, wdrożenie niebieskie-zielone i wydanie kanary.
Aktualizacje stopniowe
W ramach aktualizacji stopniowej wdrażasz nowe wystąpienia usługi, a nowe wystąpienia zaczynają odbierać żądania od razu. Gdy pojawią się nowe wystąpienia, poprzednie wystąpienia zostaną usunięte.
Przykład. W rozwiązaniu Kubernetes aktualizacje stopniowe są zachowaniem domyślnym podczas aktualizowania specyfikacji zasobnika dla Deployment. Kontroler wdrażania tworzy nowy zestaw replik dla zaktualizowanych zasobników. Następnie skaluje nowy zestaw replik w górę podczas skalowania w dół starego, aby zachować żądaną liczbę replik. Nie usuwa starych zasobników, dopóki nowe nie będą gotowe. Platforma Kubernetes przechowuje historię aktualizacji, dzięki czemu można w razie potrzeby wycofać aktualizację.
Przykład. Usługa Azure Service Fabric domyślnie używa strategii aktualizacji stopniowej. Ta strategia najlepiej nadaje się do wdrażania wersji usługi z nowymi funkcjami bez konieczności zmieniania istniejących interfejsów API. Usługa Service Fabric uruchamia wdrożenie uaktualnienia przez zaktualizowanie typu aplikacji do podzestawu węzłów lub domeny aktualizacji. Następnie jest on przekazywany do następnej domeny aktualizacji do momentu uaktualnienia wszystkich domen. Jeśli aktualizacja domeny uaktualnienia nie powiedzie się, typ aplikacji zostanie przywrócony do poprzedniej wersji we wszystkich domenach. Należy pamiętać, że typ aplikacji z wieloma usługami (i jeśli wszystkie usługi są aktualizowane w ramach jednego wdrożenia uaktualnienia) jest podatny na awarię. Jeśli jedna usługa nie zostanie zaktualizowana, cała aplikacja zostanie wycofana z poprzedniej wersji, a pozostałe usługi nie zostaną zaktualizowane.
Jednym z wyzwań dotyczących rolowania aktualizacji jest to, że podczas procesu aktualizacji uruchomiono i odbierano ruch w różnych starych i nowych wersjach. W tym okresie każde żądanie może zostać skierowane do jednej z dwóch wersji.
W przypadku zmian powodujących niezgodność interfejsu API dobrym rozwiązaniem jest obsługa obu wersji jednocześnie do momentu zaktualizowania wszystkich klientów poprzedniej wersji. Zobacz przechowywanie wersji interfejsu API.
Wdrożenie niebiesko-zielone
We wdrożeniu niebieskim zielonym wdrażasz nową wersję wraz z poprzednią wersją. Po zweryfikowaniu nowej wersji należy przełączyć cały ruch jednocześnie z poprzedniej wersji na nową wersję. Po przełączeniu należy monitorować aplikację pod kątem wszelkich problemów. Jeśli coś pójdzie nie tak, możesz zamienić się z powrotem na starą wersję. Zakładając, że nie ma żadnych problemów, możesz usunąć starą wersję.
W przypadku bardziej tradycyjnej aplikacji monolitycznej lub N-warstwowej wdrożenie niebiesko-zielone zwykle oznacza aprowizowanie dwóch identycznych środowisk. Nowa wersja zostanie wdrożona w środowisku przejściowym, a następnie przekierowanie ruchu klienta do środowiska przejściowego — na przykład przez zamianę adresów VIP. W architekturze mikrousług aktualizacje są wykonywane na poziomie mikrousług, więc zazwyczaj należy wdrożyć aktualizację w tym samym środowisku i użyć mechanizmu odnajdywania usługi do zamiany.
przykład. W rozwiązaniu Kubernetes nie trzeba aprowizować oddzielnego klastra w celu wykonania wdrożeń niebiesko-zielonych. Zamiast tego można skorzystać z selektorów. Utwórz nowy zasób wdrażania
Jedną z wad wdrożenia blue-green jest to, że podczas aktualizacji jest uruchomionych dwa razy więcej zasobników dla usługi (bieżący i następny). Jeśli zasobniki wymagają dużej ilości zasobów procesora CPU lub pamięci, może być konieczne tymczasowe skalowanie klastra w poziomie w celu obsługi użycia zasobów.
Wydanie canary
W wydaniu kanarowym wdrażasz zaktualizowaną wersję dla niewielkiej liczby klientów. Następnie monitorujesz zachowanie nowej usługi przed wdrożeniem jej na wszystkich klientach. Pozwala to na powolne wdrażanie w kontrolowany sposób, obserwowanie rzeczywistych danych i dostrzeganie problemów, zanim wszyscy klienci zostaną dotknięci.
Wydanie kanary jest bardziej złożone do zarządzania niż niebiesko-zielone lub stopniowe aktualizacje, ponieważ należy dynamicznie kierować żądania do różnych wersji usługi.
przykład. Na platformie Kubernetes można skonfigurować Service, aby obejmowała dwa zestawy replik (po jednym dla każdej wersji) i ręcznie dostosować liczbę replik. Jednak takie podejście jest raczej grubsze, ze względu na sposób równoważenia obciążenia platformy Kubernetes w zasobnikach. Jeśli na przykład masz łącznie 10 replik, ruch można przesuwać tylko w 10% przyrostach. Jeśli używasz siatki usług, możesz użyć reguł routingu siatki usług, aby zaimplementować bardziej zaawansowaną strategię wydawania kanary.
Następne kroki
- ścieżka szkoleniowa : Definiowanie i implementowanie ciągłej integracji
- szkolenie : wprowadzenie do ciągłego dostarczania
- architektura mikrousług
- Dlaczego warto używać podejścia mikrousług do tworzenia aplikacji