Podział odpowiedzialności zapytań poleceń (CQRS) to wzorzec projektowy, który oddziela operacje odczytu i zapisu dla magazynu danych na oddzielne modele danych. Dzięki temu każdy model może być zoptymalizowany niezależnie i może zwiększyć wydajność, skalowalność i bezpieczeństwo aplikacji.
Kontekst i problem
W tradycyjnych architekturach pojedynczy model danych jest często używany zarówno na potrzeby operacji odczytu, jak i zapisu. Takie podejście jest proste i dobrze sprawdza się w przypadku podstawowych operacji CRUD (zobacz rysunek 1).
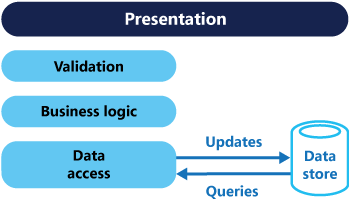
Rysunek 1. Tradycyjna architektura CRUD.
Jednak w miarę zwiększania się aplikacji optymalizacja operacji odczytu i zapisu w jednym modelu danych staje się coraz trudniejsza. Operacje odczytu i zapisu często mają różne wymagania dotyczące wydajności i skalowania. Tradycyjna architektura CRUD nie uwzględnia tej asymetrii. Prowadzi to do kilku wyzwań:
Niezgodność danych: Reprezentacje odczytu i zapisu danych często się różnią. Niektóre pola wymagane podczas aktualizacji mogą być niepotrzebne podczas odczytu.
Rywalizacja o blokadę: Operacje równoległe w tym samym zestawie danych mogą powodować rywalizację o blokadę.
Problemy z wydajnością: Tradycyjne podejście może mieć negatywny wpływ na wydajność ze względu na obciążenie magazynu danych i warstwy dostępu do danych oraz złożoność zapytań wymaganych do pobrania informacji.
Obawy dotyczące zabezpieczeń: Zarządzanie zabezpieczeniami staje się trudne, gdy jednostki podlegają operacjom odczytu i zapisu. To nakładanie się może uwidaczniać dane w niezamierzonych kontekstach.
Połączenie tych obowiązków może spowodować zbyt skomplikowany model, który próbuje zrobić zbyt wiele.
Rozwiązanie
Użyj wzorca CQRS, aby oddzielić operacje zapisu (polecenia) z operacji odczytu (zapytań). Polecenia są odpowiedzialne za aktualizowanie danych. Zapytania są odpowiedzialne za pobieranie danych.
Informacje o poleceniach. Polecenia powinny reprezentować określone zadania biznesowe, a nie aktualizacje danych niskiego poziomu. Na przykład w aplikacji do rezerwacji hotelowych użyj opcji "Book hotel room" zamiast "Set ReservationStatus to Reserved". Takie podejście lepiej odzwierciedla intencję akcji użytkownika i wyrównuje polecenia z procesami biznesowymi. Aby upewnić się, że polecenia zakończyły się pomyślnie, może być konieczne udoskonalenie przepływu interakcji użytkownika, logiki po stronie serwera i rozważenie przetwarzania asynchronicznego.
| Obszar uściślenia | Zalecenie |
|---|---|
| Walidacja po stronie klienta | Zweryfikuj niektóre warunki przed wysłaniem polecenia, aby zapobiec oczywistym niepowodzeniom. Jeśli na przykład żadne pokoje nie są dostępne, wyłącz przycisk "Książka" i podaj jasny, przyjazny dla użytkownika komunikat w interfejsie użytkownika wyjaśniający, dlaczego rezerwacja nie jest możliwa. Ta konfiguracja zmniejsza niepotrzebne żądania serwera i zapewnia natychmiastowe opinie użytkownikom, zwiększając ich środowisko. |
| Logika po stronie serwera | Zwiększ logikę biznesową, aby bezpiecznie obsługiwać przypadki brzegowe i błędy. Aby na przykład rozwiązać warunki wyścigu (wielu użytkowników próbujących zarezerwować ostatni dostępny pokój), rozważ dodanie użytkowników do listy oczekujących lub sugerowanie alternatywnych opcji. |
| Przetwarzanie asynchroniczne | Można również przetwarzać polecenia asynchronicznie, umieszczając je w kolejce, zamiast obsługiwać je synchronicznie. |
Omówienie zapytań. Zapytania nigdy nie zmieniają danych. Zamiast tego zwracają obiekty transferu danych (DTO), które przedstawiają wymagane dane w wygodnym formacie bez żadnej logiki domeny. To wyraźne rozdzielenie zagadnień upraszcza projektowanie i wdrażanie systemu.
Omówienie separacji modeli odczytu i zapisu
Oddzielenie modelu odczytu od modelu zapisu upraszcza projektowanie i implementację systemu przez rozwiązanie odrębnych problemów dotyczących zapisów i odczytów danych. Ta separacja zwiększa przejrzystość, skalowalność i wydajność, ale wprowadza pewne kompromisy. Na przykład narzędzia do tworzenia szkieletów, takie jak struktury O/RM, nie mogą automatycznie generować kodu CQRS ze schematu bazy danych, co wymaga niestandardowej logiki w celu pomostowania luki.
W poniższych sekcjach omówiono dwa podstawowe podejścia do implementowania separacji modeli odczytu i zapisu w usługach CQRS. Każde podejście wiąże się z unikatowymi korzyściami i wyzwaniami, takimi jak synchronizacja i zarządzanie spójnością.
Separacja modeli w jednym magazynie danych
Takie podejście reprezentuje podstawowy poziom CQRS, w którym modele odczytu i zapisu współużytkują pojedynczą bazową bazę danych, ale utrzymują odrębną logikę dla swoich operacji. Definiując oddzielne zagadnienia, ta strategia zwiększa prostotę, zapewniając jednocześnie korzyści ze skalowalności i wydajności dla typowych przypadków użycia. Podstawowa architektura CQRS umożliwia oddzielenie modelu zapisu od modelu odczytu podczas korzystania z udostępnionego magazynu danych (zobacz rysunek 2).
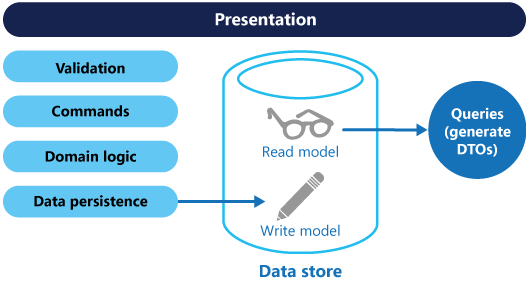
Rysunek 2. Podstawowa architektura CQRS z jednym magazynem danych.
Takie podejście zwiększa przejrzystość, wydajność i skalowalność, definiując odrębne modele do obsługi problemów dotyczących zapisu i odczytu:
Modelu zapisu: Zaprojektowany do obsługi poleceń aktualizujących lub utrwalających dane. Obejmuje ona walidację, logikę domeny i zapewnia spójność danych dzięki optymalizacji pod kątem integralności transakcyjnej i procesów biznesowych.
model odczytu: Zaprojektowany w celu obsługi zapytań dotyczących pobierania danych. Koncentruje się on na generowaniu obiektów DTO (obiektów transferu danych) lub projekcjach zoptymalizowanych pod kątem warstwy prezentacji. Zwiększa wydajność zapytań i czas odpowiedzi, unikając logiki domeny.
Fizyczne rozdzielenie modeli w oddzielnych magazynach danych
Bardziej zaawansowana implementacja CQRS używa odrębnych magazynów danych dla modeli odczytu i zapisu. Rozdzielenie magazynów danych odczytu i zapisu umożliwia skalowanie każdego z nich w celu dopasowania ich do obciążenia. Umożliwia również korzystanie z innej technologii magazynowania dla każdego magazynu danych. Możesz użyć bazy danych dokumentów do odczytu magazynu danych i relacyjnej bazy danych dla magazynu danych zapisu (zobacz rysunek 3).
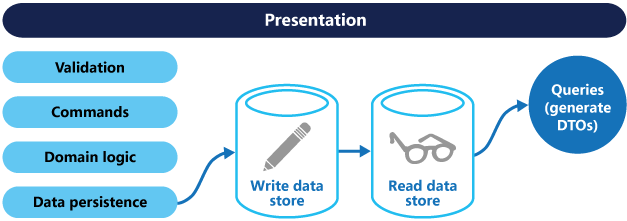
Rysunek 3. Architektura CQRS z oddzielnymi magazynami danych odczytu i zapisu.
Synchronizowanie oddzielnych magazynów danych: W przypadku korzystania z oddzielnych magazynów należy upewnić się, że oba magazyny pozostają zsynchronizowane. Typowym wzorcem jest posiadanie zdarzeń publikowania modelu zapisu za każdym razem, gdy aktualizuje bazę danych, której model odczytu używa do odświeżania danych. Aby uzyskać więcej informacji na temat używania zdarzeń, zobacz Styl architektury opartej na zdarzeniach. Zazwyczaj jednak nie można zarejestrować brokerów komunikatów i baz danych w jednej transakcji rozproszonej. W związku z tym podczas aktualizowania bazy danych i publikowania zdarzeń mogą występować wyzwania w zagwarantowaniu spójności. Aby uzyskać więcej informacji, zobacz idempotentnego przetwarzania komunikatów.
Odczyt magazynu danych: Magazyn danych do odczytu może używać własnego schematu danych zoptymalizowanego pod kątem zapytań. Może na przykład przechowywać zmaterializowany widok danych, aby uniknąć złożonych sprzężeń lub mapowań O/RM. Magazyn do odczytu może być repliką tylko do odczytu magazynu zapisu lub mieć inną strukturę. Wdrażanie wielu replik tylko do odczytu może zwiększyć wydajność, zmniejszając opóźnienia i zwiększając dostępność, szczególnie w scenariuszach rozproszonych.
Zalety CQRS
Niezależne skalowanie. Usługa CQRS umożliwia niezależne skalowanie modeli odczytu i zapisu, co może pomóc zminimalizować rywalizację o blokadę i zwiększyć wydajność systemu pod obciążeniem.
Zoptymalizowane schematy danych. Operacje odczytu mogą używać schematu zoptymalizowanego pod kątem zapytań. Operacje zapisu używają schematu zoptymalizowanego pod kątem aktualizacji.
Zabezpieczenia. Oddzielając odczyty i zapisy, można upewnić się, że tylko odpowiednie jednostki domeny lub operacje mają uprawnienia do wykonywania akcji zapisu na danych.
Separacja problemów. Dzielenie obowiązków odczytu i zapisu powoduje bardziej czytelne, bardziej konserwowalne modele. Strona zapisu zwykle obsługuje złożoną logikę biznesową, podczas gdy strona odczytu może pozostać prosta i skoncentrowana na wydajności zapytań.
Prostsze zapytania. Podczas przechowywania zmaterializowanego widoku w bazie danych odczytu aplikacja może uniknąć złożonych sprzężeń podczas wykonywania zapytań.
Problemy i zagadnienia dotyczące implementacji
Niektóre wyzwania związane z implementacją tego wzorca obejmują:
zwiększona złożoność. Chociaż podstawowa koncepcja CQRS jest prosta, może ona wprowadzić znaczną złożoność w projekcie aplikacji, szczególnie w połączeniu ze wzorcem określania źródła zdarzeń.
Wyzwania związane z obsługą komunikatów. Mimo że obsługa komunikatów nie jest wymagana w przypadku magazynu CQRS, często służy do przetwarzania poleceń i publikowania zdarzeń aktualizacji. W przypadku angażowania komunikatów system musi uwzględniać potencjalne problemy, takie jak błędy komunikatów, duplikaty i ponawianie prób. Zapoznaj się ze wskazówkami dotyczącymi kolejek priorytetowych , aby uzyskać strategie obsługi poleceń o różnych priorytetach.
Spójność ostateczna. Gdy bazy danych odczytu i zapisu są oddzielone, dane odczytu mogą nie odzwierciedlać najnowszych zmian natychmiast, co prowadzi do nieaktualnych danych. Zapewnienie, że magazyn modeli odczytu pozostaje up-to-date ze zmianami w magazynie modeli zapisu może być trudny. Ponadto wykrywanie i obsługa scenariuszy, w których użytkownik działa na nieaktualnych danych, wymaga starannego rozważenia.
Kiedy należy używać wzorca CQRS
Wzorzec CQRS jest przydatny w scenariuszach, które wymagają wyraźnego rozdzielenia między modyfikacjami danych (poleceniami) i zapytaniami o dane (odczyty). Rozważ użycie magazynu CQRS w następujących sytuacjach:
domeny współpracy: W środowiskach, w których wielu użytkowników uzyskuje dostęp do tych samych danych i modyfikuje je jednocześnie, CQRS pomaga zmniejszyć konflikty scalania. Polecenia mogą zawierać wystarczającą stopień szczegółowości, aby zapobiec konfliktom, a system może rozwiązać wszystkie, które występują w logice poleceń.
oparte na zadaniach interfejsy użytkownika: Aplikacje, które prowadzą użytkowników przez złożone procesy jako serię kroków lub ze złożonymi modelami domeny korzystają z CQRS.
Model zapisu ma pełny stos przetwarzania poleceń z logiką biznesową, walidacją danych wejściowych i weryfikacją biznesową. Model zapisu może traktować zestaw skojarzonych obiektów jako pojedynczą jednostkę zmian danych, znać jako agregujące w terminologii projektowej opartej na domenie. Model zapisu może również zapewnić, że te obiekty są zawsze w stanie spójnym.
Model odczytu nie ma logiki biznesowej ani stosu walidacji. Zwraca obiekt DTO do użycia w modelu widoku. Model odczytu jest ostatecznie spójny z modelem zapisu.
Dostrajanie wydajności: Systemy, w których wydajność odczytów danych musi być dostrojona oddzielnie od wydajności zapisów danych, zwłaszcza gdy liczba odczytów jest większa niż liczba zapisów, skorzystaj z CQRS. Model odczytu jest skalowany w poziomie w celu obsługi dużych woluminów zapytań, podczas gdy model zapisu działa na mniejszej liczbie wystąpień, aby zminimalizować konflikty scalania i zachować spójność.
Separacja zagadnień programistycznych: CQRS umożliwia zespołom niezależnie pracę. Jeden zespół koncentruje się na implementowaniu złożonej logiki biznesowej w modelu zapisu, podczas gdy inny opracowuje składniki modelu odczytu i interfejsu użytkownika.
Ewoluujące systemy: CQRS obsługuje systemy, które zmieniają się wraz z upływem czasu. Uwzględnia nowe wersje modelu, częste zmiany reguł biznesowych lub inne modyfikacje bez wpływu na istniejące funkcje.
integracja systemu: systemy integrujące się z innymi podsystemami, zwłaszcza te korzystające z określania źródła zdarzeń, pozostają dostępne nawet wtedy, gdy podsystem tymczasowo ulegnie awarii. Usługa CQRS izoluje awarie, uniemożliwiając pojedynczemu składnikowi wpływ na cały system.
Kiedy nie należy używać CQRS
Unikaj CQRS w następujących sytuacjach:
Domena lub reguły biznesowe są proste.
Wystarczy prosty interfejs użytkownika w stylu CRUD i operacje dostępu do danych.
Projekt obciążenia
Architekt powinien ocenić, jak używać wzorca CQRS w projekcie obciążenia, aby sprostać celom i zasadom opisanym w filarach Azure Well-Architected Framework. Na przykład:
| Filar | Jak ten wzorzec obsługuje cele filaru |
|---|---|
| Wydajność pomagawydajnie sprostać zapotrzebowaniu dzięki optymalizacjom skalowania, danych, kodu. | Rozdzielenie operacji odczytu i zapisu w obciążeniach odczytu do zapisu umożliwia ukierunkowaną wydajność i optymalizacje skalowania dla konkretnego celu każdej operacji. - PE:05 Skalowanie i partycjonowanie - PE:08 Wydajność danych |
Podobnie jak w przypadku każdej decyzji projektowej, należy rozważyć wszelkie kompromisy w stosunku do celów innych filarów, które mogą zostać wprowadzone przy użyciu tego wzorca.
Łączenie określania źródła zdarzeń i CQRS
Niektóre implementacje CQRS obejmują wzorzec określania źródła zdarzeń, który przechowuje stan systemu jako cykl chronologiczny zdarzeń. Każde zdarzenie przechwytuje zmiany wprowadzone w danych w danym momencie. Aby określić bieżący stan, system odtwarza te zdarzenia w kolejności. W tej kombinacji:
Magazyn zdarzeń to model zapisu i pojedyncze źródło prawdy.
Model odczytu generuje zmaterializowane widoki z tych zdarzeń, zazwyczaj w wysoce zdenormalizowanej formie. Te widoki optymalizują pobieranie danych, dostosowując struktury do wymagań dotyczących zapytań i wyświetlania.
Zalety łączenia określania źródła zdarzeń i CQRS
Te same zdarzenia, które aktualizują model zapisu, mogą służyć jako dane wejściowe do modelu odczytu. Model odczytu może następnie utworzyć migawkę bieżącego stanu w czasie rzeczywistym. Te migawki optymalizują zapytania, zapewniając wydajne, wstępnie skompilowane widoki danych.
Zamiast bezpośrednio przechowywać bieżący stan, system używa strumienia zdarzeń jako magazynu zapisu. Takie podejście zmniejsza konflikty aktualizacji w agregacjach i zwiększa wydajność i skalowalność. System może przetworzyć te zdarzenia asynchronicznie w celu skompilowania lub zaktualizowania zmaterializowanych widoków dla magazynu odczytu.
Ponieważ magazyn zdarzeń działa jako pojedyncze źródło prawdy, można łatwo ponownie wygenerować zmaterializowane widoki lub dostosować się do zmian w modelu odczytu, odtwarzając zdarzenia historyczne. W istocie zmaterializowane widoki działają jako trwała pamięć podręczna tylko do odczytu zoptymalizowana pod kątem szybkich i wydajnych zapytań.
Zagadnienia dotyczące łączenia określania źródła zdarzeń i CQRS
Przed połączeniem wzorca CQRS ze wzorcem określania źródła zdarzeń należy ocenić następujące zagadnienia:
spójność ostateczna: Ponieważ magazyny zapisu i odczytu są oddzielne, aktualizacje magazynu odczytu mogą opóźnić generowanie zdarzeń, co skutkuje spójnością ostateczną.
Zwiększona złożoność: łączenie CQRS z określaniem źródła zdarzeń wymaga innego podejścia projektowego, co może utrudnić pomyślną implementację. Musisz napisać kod w celu generowania, przetwarzania i obsługi zdarzeń oraz tworzenia lub aktualizowania widoków dla modelu odczytu. Jednak określanie źródła zdarzeń upraszcza modelowanie domeny i umożliwia łatwe kompilowanie lub tworzenie nowych widoków przez zachowanie historii i intencji wszystkich zmian danych.
Wydajność generowania widoku: Generowanie zmaterializowanych widoków dla modelu odczytu może zużywać dużo czasu i zasobów. To samo dotyczy projekcji danych przez odtworzenie i przetwarzanie zdarzeń dla określonych jednostek lub kolekcji. Ten efekt zwiększa się, gdy obliczenia obejmują analizowanie lub sumowanie wartości w długich okresach, ponieważ należy zbadać wszystkie powiązane zdarzenia. Implementowanie migawek danych w regularnych odstępach czasu. Na przykład przechowuj okresowe migawki zagregowanych sum (liczbę wystąpień określonej akcji) lub bieżący stan jednostki. Migawki zmniejszają konieczność wielokrotnego przetwarzania pełnej historii zdarzeń, co zwiększa wydajność.
Przykład wzorca CQRS
Poniższy kod pokazuje pewne fragmenty przykładu wdrożenia podejścia CQRS, które używają różnych definicji modeli odczytu i zapisu. Interfejsy modelu nie wymagają żadnych funkcji podstawowych magazynów danych oraz mogą ewoluować i mogą być niezależnie strojone, ponieważ te interfejsy są rozdzielone.
Poniższy kod przedstawia definicję modelu odczytu.
// Query interface
namespace ReadModel
{
public interface ProductsDao
{
ProductDisplay FindById(int productId);
ICollection<ProductDisplay> FindByName(string name);
ICollection<ProductInventory> FindOutOfStockProducts();
ICollection<ProductDisplay> FindRelatedProducts(int productId);
}
public class ProductDisplay
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal UnitPrice { get; set; }
public bool IsOutOfStock { get; set; }
public double UserRating { get; set; }
}
public class ProductInventory
{
public int Id { get; set; }
public string Name { get; set; }
public int CurrentStock { get; set; }
}
}
System pozwala użytkownikom oceniać produkty. Kod aplikacji realizuje to przy użyciu polecenia RateProduct pokazanego w poniższym kodzie.
public interface ICommand
{
Guid Id { get; }
}
public class RateProduct : ICommand
{
public RateProduct()
{
this.Id = Guid.NewGuid();
}
public Guid Id { get; set; }
public int ProductId { get; set; }
public int Rating { get; set; }
public int UserId {get; set; }
}
System używa klasy ProductsCommandHandler do obsługi poleceń wysyłanych przez aplikację. Klienci wysyłają zazwyczaj polecenia do domeny za pośrednictwem systemu obsługi komunikatów, takiego jak kolejka. Procedura obsługi poleceń akceptuje te polecenia i wywołuje metody interfejsu domeny. Stopień szczegółowości każdego polecenia pozwala zmniejszyć prawdopodobieństwo żądań powodujących konflikt. Poniższy kod przedstawia zarys klasy ProductsCommandHandler.
public class ProductsCommandHandler :
ICommandHandler<AddNewProduct>,
ICommandHandler<RateProduct>,
ICommandHandler<AddToInventory>,
ICommandHandler<ConfirmItemShipped>,
ICommandHandler<UpdateStockFromInventoryRecount>
{
private readonly IRepository<Product> repository;
public ProductsCommandHandler (IRepository<Product> repository)
{
this.repository = repository;
}
void Handle (AddNewProduct command)
{
...
}
void Handle (RateProduct command)
{
var product = repository.Find(command.ProductId);
if (product != null)
{
product.RateProduct(command.UserId, command.Rating);
repository.Save(product);
}
}
void Handle (AddToInventory command)
{
...
}
void Handle (ConfirmItemsShipped command)
{
...
}
void Handle (UpdateStockFromInventoryRecount command)
{
...
}
}
Następne kroki
Podczas implementowania tego wzorca są przydatne następujące wzorce i wskazówki:
- Partycjonowanie danych poziomych, pionowych i funkcjonalnych. W tym artykule opisano najlepsze rozwiązania dotyczące dzielenia danych na partycje, które mogą być zarządzane i uzyskiwane oddzielnie, aby zwiększyć skalowalność, zmniejszyć rywalizację i zoptymalizować wydajność.
Powiązane zasoby
Wzorzec określania źródła zdarzeń. Opisuje sposób używania określania źródła zdarzeń ze wzorcem CQRS. Pokazuje on, jak uprościć zadania w złożonych domenach, jednocześnie zwiększając wydajność, skalowalność i czas odpowiedzi. Wyjaśniono również, jak zapewnić spójność danych transakcyjnych przy zachowaniu pełnych dzienników inspekcji i historii, które mogą umożliwić akcje wyrównywujące.
Materialized View pattern (Wzorzec zmaterializowanego widoku). Model odczytu implementacji CQRS może zawierać zmaterializowane widoki danych modelu zapisu lub może on służyć do generowania zmaterializowanych widoków.