Zaawansowane tematy dotyczące usługi SAP CDC
DOTYCZY:  Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Napiwek
Wypróbuj usługę Data Factory w usłudze Microsoft Fabric — rozwiązanie analityczne typu all-in-one dla przedsiębiorstw. Usługa Microsoft Fabric obejmuje wszystko, od przenoszenia danych do nauki o danych, analizy w czasie rzeczywistym, analizy biznesowej i raportowania. Dowiedz się, jak bezpłatnie rozpocząć nową wersję próbną !
Dowiedz się więcej o zaawansowanych tematach dotyczących łącznika SAP CDC, takich jak integracja danych opartych na metadanych, debugowanie i nie tylko.
Parametryzacja przepływu danych mapowania sap CDC
Jedną z kluczowych zalet potoków i przepływów mapowania danych w usługach Azure Data Factory i Azure Synapse Analytics jest obsługa integracji danych opartych na metadanych. Dzięki tej funkcji można zaprojektować pojedynczy (lub kilka) sparametryzowanych potoków, których można użyć do obsługi integracji potencjalnie setek lub nawet tysięcy źródeł. Łącznik SAP CDC został zaprojektowany z tą zasadą: wszystkie odpowiednie właściwości, niezależnie od tego, czy jest to obiekt źródłowy, tryb uruchamiania, kolumny kluczy itp., można dostarczyć za pomocą parametrów w celu zmaksymalizowania elastyczności i ponownego wykorzystania potencjału przepływów danych mapowania sap CDC.
Aby zrozumieć podstawowe pojęcia dotyczące parametryzacji przepływów danych mapowania, przeczytaj temat Parametryzowanie przepływów danych mapowania.
W galerii szablonów usług Azure Data Factory i Azure Synapse Analytics znajdziesz potok szablonu i przepływ danych, który pokazuje, jak parametryzować pozyskiwanie danych sap CDC.
Parametryzacja źródła i trybu uruchamiania
Przepływy danych mapowania nie muszą wymagać artefaktu zestawu danych: przekształcenia źródła i ujścia oferują wbudowany typ źródła (lub typ ujścia). W takim przypadku wszystkie właściwości źródłowe zdefiniowane w zestawie danych usługi ADF można skonfigurować w opcjach Źródła przekształcenia źródła (lub karcie Ustawienia przekształcenia ujścia). Użycie wbudowanego zestawu danych zapewnia lepsze omówienie i upraszcza parametryzowanie przepływu danych mapowania, ponieważ konfiguracja kompletnego źródła (lub ujścia) jest utrzymywana w jednym miejscu.
W przypadku usługi SAP CDC właściwości, które są najczęściej ustawiane za pomocą parametrów, znajdują się na kartach Opcje źródła i Optymalizowanie. Gdy typ źródła jest wbudowany, następujące właściwości można sparametryzować w opcjach źródła.
- Kontekst ODP: prawidłowe wartości parametrów to
- ABAP_CDS dla widoków podstawowych usług danych ABAP
- BW dla dostawców informacji SAP BW lub SAP BW/4HANA
- Platforma HANA dla widoków informacji platformy SAP HANA
- OPROGRAMOWANIE SAPI dla źródeł danych SAP/extractors
- gdy serwer replikacji transformacji poziomej SAP (SLT) jest używany jako źródło, nazwa kontekstu ODP to SLT~<Queue Alias>. Wartość Alias kolejki można znaleźć w obszarze Dane administracyjne w konfiguracji SLT w kokpicie SLT (SAP transaction LTRC).
- ODP_SELF i RANDOM są kontekstami ODP używanymi do weryfikacji technicznej i testowania i zwykle nie są istotne.
- Nazwa odp: podaj nazwę ODP, z której chcesz wyodrębnić dane.
- Tryb uruchamiania: prawidłowe wartości parametrów to
- fullAndIncrementalLoad for Full w pierwszym przebiegu, a następnie przyrostowy, który inicjuje proces przechwytywania zmian danych i wyodrębnia bieżącą pełną migawkę danych.
- fullLoad for Full on every run ,który wyodrębnia bieżącą pełną migawkę danych bez inicjowania procesu przechwytywania zmian danych.
- incrementalLoad tylko dla zmian przyrostowych, które inicjują proces przechwytywania zmian danych bez wyodrębniania bieżącej pełnej migawki.
- Kolumny klucza: kolumny kluczy są dostarczane jako tablica ciągów (podwójnie cytowanych). Na przykład podczas pracy z tabelą SAP VBAP (pozycje zamówienia sprzedaży) definicja klucza musi być następująca: ["VBELN", "POSNR"] (lub ["MANDT","VBELN","POSNR"] w przypadku, gdy pole klienta jest również brane pod uwagę).
Parametryzacja warunków filtrowania dla partycjonowania źródłowego
Na karcie Optymalizacja można zdefiniować schemat partycjonowania źródłowego (zobacz optymalizowanie wydajności dla pełnych lub początkowych obciążeń) za pomocą parametrów. Zazwyczaj wymagane są dwa kroki:
- Zdefiniuj schemat partycjonowania źródłowego.
- Pozyskiwanie parametru partycjonowania do przepływu danych mapowania.
Definiowanie schematu partycjonowania źródłowego
Format w kroku 1 jest zgodny ze standardem JSON składającym się z tablicy definicji partycji, z których każda jest tablicą indywidualnych warunków filtrowania. Same te warunki to obiekty JSON ze strukturą dopasowaną do tak zwanych opcji wyboru w oprogramowaniu SAP. W rzeczywistości format wymagany przez platformę SAP ODP jest zasadniczo taki sam jak dynamiczne filtry DTP w systemie SAP BW:
{ "fieldName": <>, "sign": <>, "option": <>, "low": <>, "high": <> }
Na przykład
{ "fieldName": "VBELN", "sign": "I", "option": "EQ", "low": "0000001000" }
odpowiada klauzuli SQL WHERE ... WHERE "VBELN" = '0000001000', or
{ "fieldName": "VBELN", "sign": "I", "option": "BT", "low": "0000000000", "high": "0000001000" }
odpowiada klauzuli SQL WHERE ... GDZIE "VBELN" MIĘDZY "0000000000" I "0000001000"
Definicja JSON schematu partycjonowania zawierającego dwie partycje wygląda następująco
[
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2011", "high": "2015" }
],
[
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2016", "high": "2020" }
]
]
gdzie pierwsza partycja zawiera lata fiskalne (GJAHR) od 2011 do 2015 r., a druga partycja zawiera lata fiskalne od 2016 do 2020 r.
Uwaga
Usługa Azure Data Factory nie przeprowadza żadnych kontroli na tych warunkach. Na przykład użytkownik ponosi odpowiedzialność za zapewnienie, że warunki partycji nie nakładają się na siebie.
Warunki partycji mogą być bardziej złożone, składające się z wielu podstawowych warunków filtrowania. Nie ma żadnych logicznych kombinacji, które jawnie definiują sposób łączenia wielu warunków podstawowych w jednej partycji. Niejawna definicja w systemie SAP jest następująca:
- w tym warunki ("znak": "I") dla tej samej nazwy pola są łączone z OR (psychicznie, umieść nawiasy wokół wynikowego warunku)
- wykluczanie warunków ("znak": "E") dla tej samej nazwy pola są łączone z OR (ponownie, psychicznie, umieść nawiasy wokół wynikowego warunku)
- wynikowe warunki kroków 1 i 2 są następujące:
- w połączeniu z usługą AND w celu włączenia warunków,
- w połączeniu z AND NOT do wykluczania warunków.
Na przykład warunek partycji
[
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1000" },
{ "fieldName": "BUKRS", "sign": "I", "option": "EQ", "low": "1010" },
{ "fieldName": "GJAHR", "sign": "I", "option": "BT", "low": "2010", "high": "2025" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2023" },
{ "fieldName": "GJAHR", "sign": "E", "option": "EQ", "low": "2021" }
]
odpowiada klauzuli SQL WHERE ... WHERE ("BUKRS" = '1000' OR "BUKRS" = '1010') AND ("GJAHR" BETWEEN '2010' AND '2025') AND NOT ("GJAHR" = '2021' or "GJARH" = '2023')
Uwaga
Upewnij się, że używasz formatu wewnętrznego SAP dla wartości niskich i wysokich, zawierają zera wiodące i daty kalendarza ekspresowego jako osiem ciągów znaków z formatem "RRRRMDD".
Pozyskiwanie parametru partycjonowania do przepływu mapowania danych
Aby pozyskać schemat partycjonowania do przepływu danych mapowania, utwórz parametr przepływu danych (na przykład "sapPartitions"). Aby przekazać format JSON do tego parametru, należy go przekonwertować na ciąg przy użyciu funkcji @string():
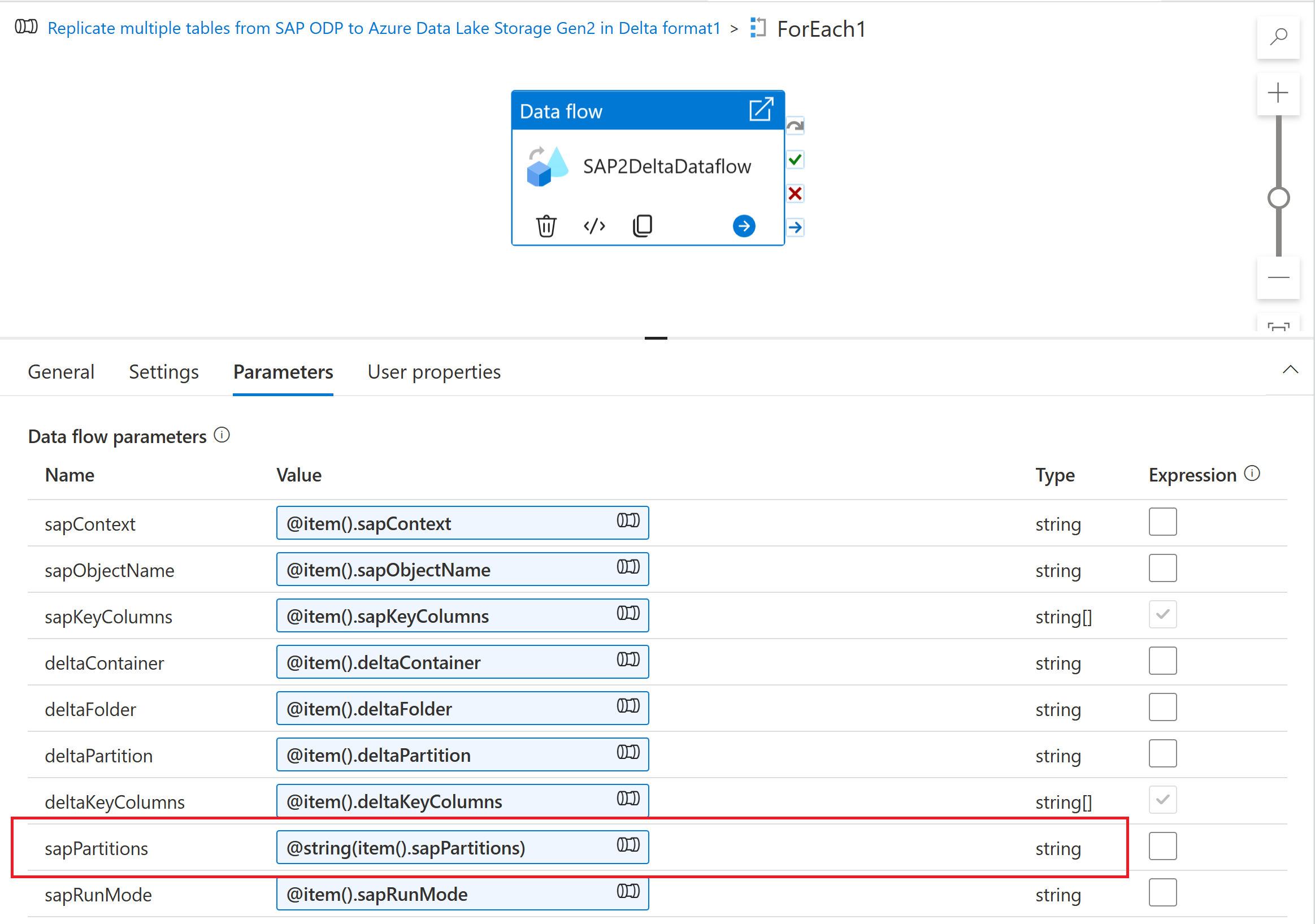
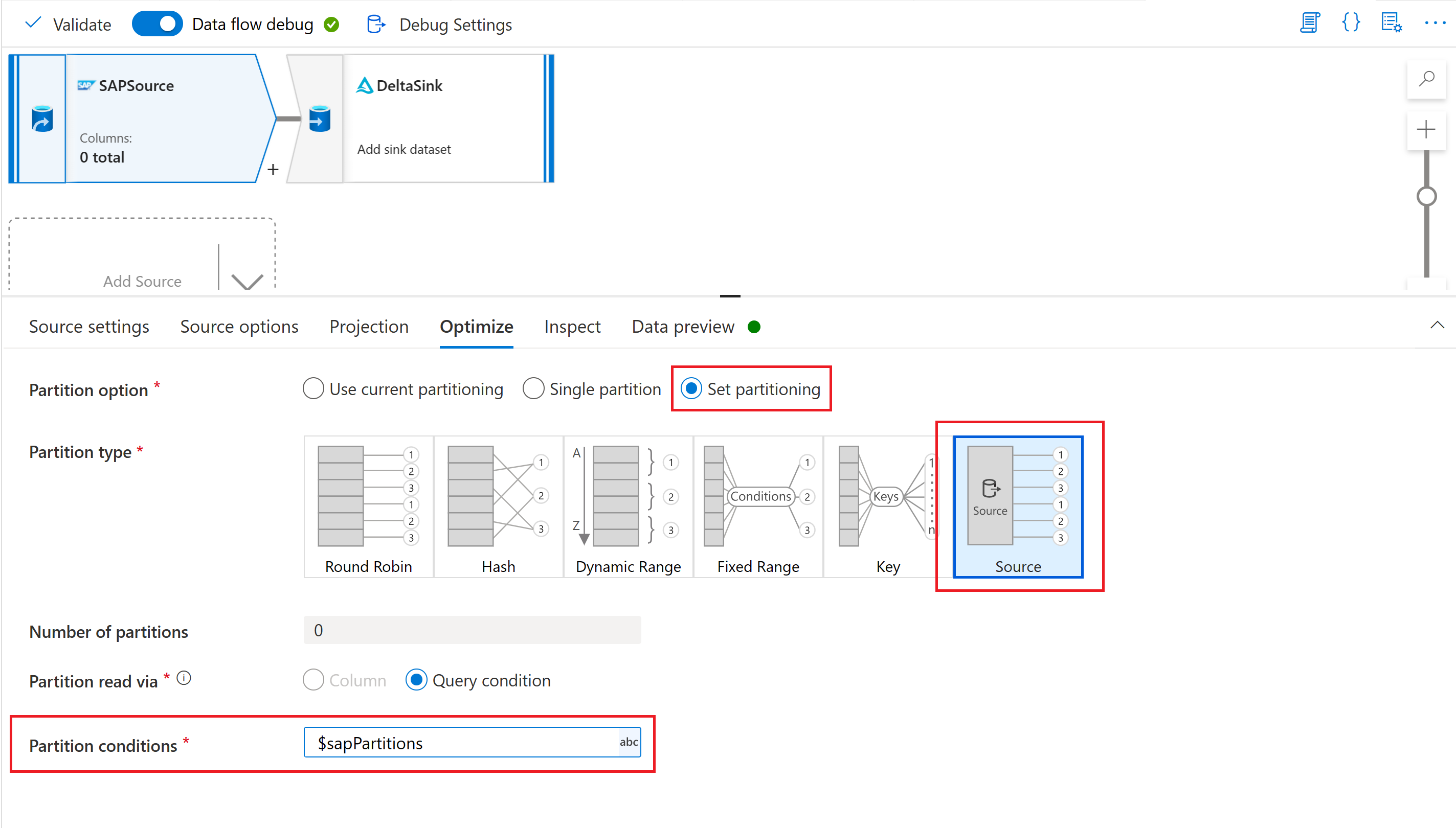
Na koniec na karcie Optymalizacja przekształcenia źródła w przepływie danych mapowania wybierz pozycję Typ partycji "Źródło", a następnie wprowadź parametr przepływu danych we właściwości Warunki partycji.
Parametryzacja klucza punktu kontrolnego
W przypadku korzystania z parametrycznego przepływu danych w celu wyodrębniania danych z wielu źródeł usługi SAP CDC ważne jest parametryzowanie klucza punktu kontrolnego w działaniu przepływu danych potoku. Klucz punktu kontrolnego jest używany przez usługę Azure Data Factory do zarządzania stanem procesu przechwytywania zmian danych. Aby uniknąć tego, że stan jednego procesu CDC zastępuje stan innego, upewnij się, że wartości klucza punktu kontrolnego są unikatowe dla każdego zestawu parametrów używanego w przepływie danych.
Uwaga
Najlepszym rozwiązaniem w celu zapewnienia unikatowości klucza punktu kontrolnego jest dodanie wartości klucza punktu kontrolnego do zestawu parametrów dla przepływu danych.
Aby uzyskać więcej informacji na temat klucza punktu kontrolnego, zobacz Przekształcanie danych za pomocą łącznika SAP CDC.
Debugowanie
Potoki usługi Azure Data Factory można wykonywać za pośrednictwem wyzwalanych lub debugowanych przebiegów. Podstawową różnicą między tymi dwiema opcjami jest to, że przebiegi debugowania wykonują przepływ danych i potok na podstawie bieżącej wersji modelowanej w interfejsie użytkownika, podczas gdy wyzwalane uruchomienia wykonują ostatnią opublikowaną wersję przepływu danych i potoku.
W przypadku usługi SAP CDC istnieje jeszcze jeden aspekt, który należy zrozumieć: aby uniknąć wpływu przebiegów debugowania na istniejący proces przechwytywania danych zmian, przebiegi debugowania używają innej wartości "procesu subskrybenta" (zobacz Monitorowanie przepływów danych SAP CDC) niż wyzwalane uruchomienia. W związku z tym tworzą oddzielne subskrypcje (czyli zmieniają procesy przechwytywania danych) w systemie SAP. Ponadto wartość "proces subskrybenta" dla przebiegów debugowania ma czas wygaśnięcia ograniczony do sesji interfejsu użytkownika przeglądarki.
Uwaga
Aby przetestować stabilność procesu przechwytywania danych zmian za pomocą usługi SAP CDC w dłuższym okresie (np. wiele dni), należy opublikować przepływ danych i potok oraz uruchomić wyzwalane uruchomienia.