Wyszukiwanie wektorów mozaiki sztucznej inteligencji
Ten artykuł zawiera omówienie rozwiązania bazy danych wektorów usługi Databricks, wyszukiwania wektorów mozaiki sztucznej inteligencji, w tym tego, co to jest i jak działa.
Co to jest wyszukiwanie wektorów mozaiki sztucznej inteligencji?
Mosaic AI Vector Search to wektorowa baza danych wbudowana w platformę analizy danych usługi Databricks i zintegrowana z jej narzędziami do zapewniania ładu i produktywności. Wektorowa baza danych to baza danych zoptymalizowana pod kątem przechowywania i pobierania osadzonych. Osadzanie to matematyczne reprezentacje semantycznej zawartości danych, zwykle danych tekstowych lub obrazów. Osadzanie jest generowane przez duży model językowy i jest kluczowym składnikiem wielu aplikacji GenAI, które zależą od znajdowania dokumentów lub obrazów, które są podobne do siebie. Przykłady to systemy RAG, systemy rekomendacji oraz rozpoznawanie obrazów i wideo.
Z Mosaic AI Wyszukiwanie Wektorów, tworzysz indeks wyszukiwania wektorów z Delta table. Indeks zawiera osadzone dane z metadanymi. Następnie możesz wykonać zapytanie względem indeksu przy użyciu interfejsu API REST, aby zidentyfikować najbardziej podobne wektory i zwrócić skojarzone dokumenty. Można zorganizować indeks, aby automatycznie sync po zaktualizowaniu bazowej Delty table.
Aplikacja Mosaic AI Vector Search obsługuje następujące elementy:
- Wyszukiwanie podobieństwa słowa kluczowego hybrydowego.
- Filtrowanie.
- Listy kontroli dostępu (ACL) do zarządzania punktami końcowymi wyszukiwania wektorów.
- Sync tylko wybrane columns.
- Zapisz i sync wygenerowane osadzenia.
Jak działa wyszukiwanie wektorów mozaiki sztucznej inteligencji?
Wyszukiwanie wektorów mozaiki sztucznej inteligencji używa algorytmu Hierarchiczny mały świat (HNSW) dla przybliżonego wyszukiwania najbliższych sąsiadów i metryki odległości L2 w celu mierzenia podobieństwa wektora osadzania. Jeśli chcesz użyć podobieństwa cosinus, musisz znormalizować osadzanie punktu danych przed ich wprowadzeniem do wyszukiwania wektorowego. Gdy punkty danych są znormalizowane, klasyfikacja wygenerowana przez odległość L2 jest taka sama, jak klasyfikacja tworzy podobieństwo cosinusu.
Wyszukiwanie wektorów mozaiki sztucznej inteligencji obsługuje również wyszukiwanie słów kluczowych hybrydowych, które łączy wyszukiwanie osadzania oparte na wektorach z tradycyjnymi technikami wyszukiwania opartymi na słowach kluczowych. Takie podejście dopasowuje dokładne wyrazy w zapytaniu, a jednocześnie używa wyszukiwania podobieństwa opartego na wektorach w celu przechwycenia relacji semantycznych i kontekstu zapytania.
Dzięki zintegrowaniu tych dwóch technik wyszukiwanie słów kluczowych hybrydowych pobiera dokumenty zawierające nie tylko dokładne słowa kluczowe, ale także te, które są koncepcyjnie podobne, zapewniając bardziej kompleksowe i odpowiednie wyniki wyszukiwania. Ta metoda jest szczególnie przydatna w aplikacjach RAG, where dane źródłowe mają unikatowe słowa kluczowe, takie jak kody SKU lub identyfikatory, które nie są odpowiednie do czystego wyszukiwania opartego na podobieństwie.
Aby uzyskać szczegółowe informacje na temat interfejsu API, zobacz Dokumentację zestawu SDK języka Python i Wykonywanie zapytań względem punktu końcowego wyszukiwania wektorów.
Obliczanie wyszukiwania podobieństwa
Obliczenie wyszukiwania podobieństwa używa następującej formuły:
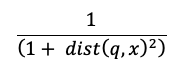
where
dist to odległość euklidesowa między q zapytania a wpisem indeksu x:
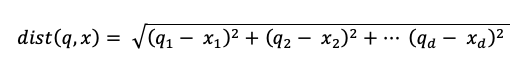
Algorytm wyszukiwania słów kluczowych
Wyniki istotności są obliczane przy użyciu rozwiązania Okapi BM25. Przeszukiwane są wszystkie columns tekstu lub ciągu, w tym osadzanie tekstu źródłowego i columns metadanych w formacie tekstowym lub ciągu. Funkcja tokenizacji dzieli się na granice wyrazów, usuwa znaki interpunkcyjne i konwertuje cały tekst na małe litery.
Jak połączone są wyszukiwanie podobieństwa i wyszukiwanie słów kluczowych
Wyniki wyszukiwania słów kluczowych i wyszukiwania podobieństwa są łączone przy użyciu funkcji RRF (Reciprocal Rank Fusion).
Funkcja RRF ponownie podkreśla każdy dokument z każdej metody przy użyciu wyniku:
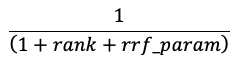
W powyższym równaniu ranga zaczyna się od 0, sumuje wyniki dla każdego dokumentu i zwraca najwyższe dokumenty oceniania.
rrf_param steruje względnym znaczeniem dokumentów o wyższych i niższych rangach. Na podstawie literatury, wartość rrf_param wynosi od set do 60.
Wyniki są znormalizowane, tak aby najwyższy wynik wynosi 1, a najniższy wynik wynosi 0, używając następującego równania:
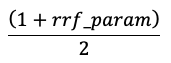
Opcje udostępniania osadzania wektorów
Aby utworzyć bazę danych wektorów w usłudze Databricks, musisz najpierw zdecydować, jak zapewnić osadzanie wektorów. Usługa Databricks obsługuje trzy opcje:
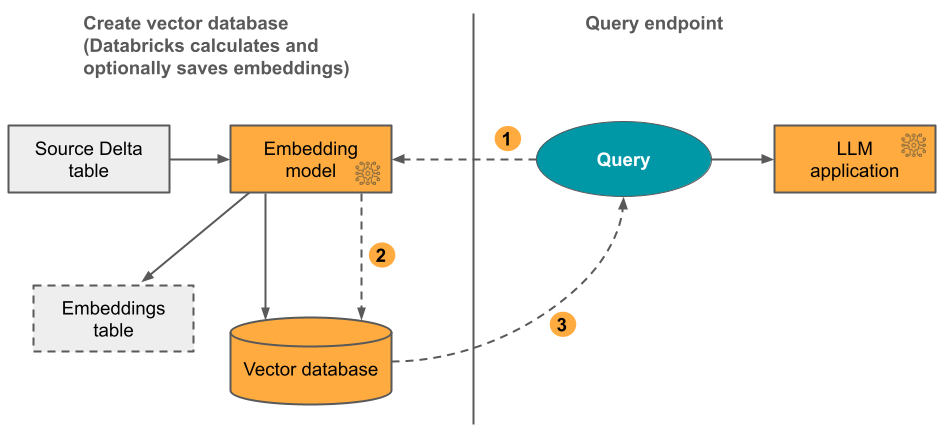
Opcja 1: Indeks Delta Sync z osadzonymi elementami obliczanymi przez Databricks Udostępniasz źródłową Delta table zawierającą dane w formacie tekstowym. Usługa Databricks oblicza reprezentacje przy użyciu określonego modelu i opcjonalnie zapisuje reprezentacje do table w programie Unity Catalog. W miarę aktualizowania delty table indeks pozostaje zsynchronizowany z deltą table.
Na poniższym diagramie przedstawiono proces:
- Obliczanie osadzania zapytań. Zapytanie może zawierać filtry metadanych.
- Wykonaj wyszukiwanie podobieństwa, aby zidentyfikować najbardziej odpowiednie dokumenty.
- Zwróć najbardziej odpowiednie dokumenty i dołącz je do zapytania.
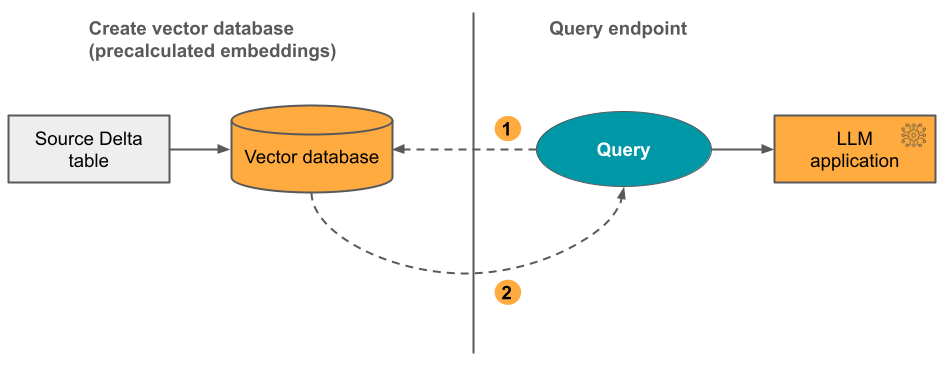
Opcja 2: Indeks Delta Sync z samodzielnie zarządzanymi osadzeniami Udostępniasz źródło Delta table, które zawiera wstępnie obliczone osadzenia. W miarę aktualizowania delty table indeks pozostaje zsynchronizowany z deltą table.
Na poniższym diagramie przedstawiono proces:
- Zapytanie składa się z osadzania i może zawierać filtry metadanych.
- Wykonaj wyszukiwanie podobieństwa, aby zidentyfikować najbardziej odpowiednie dokumenty. Zwróć najbardziej odpowiednie dokumenty i dołącz je do zapytania.
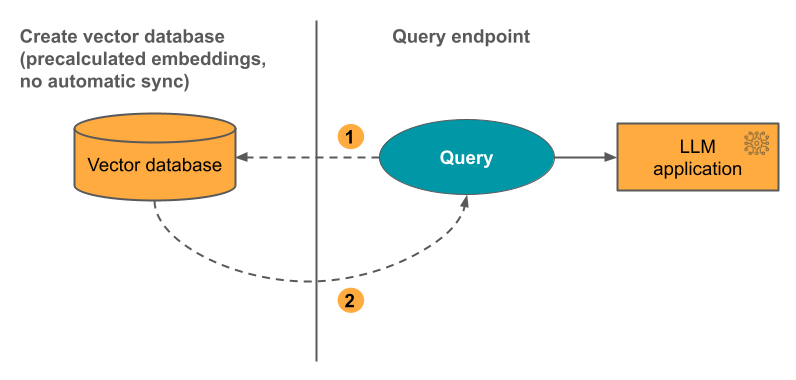
Opcja 3: Indeks bezpośredniego dostępu wektorowego Należy ręcznie update indeks przy użyciu interfejsu API REST, gdy osadzenia table zmieniają się.
Na poniższym diagramie przedstawiono proces:
Jak wykonać wyszukiwanie wektorowe Mosaic AI set
Aby użyć funkcji Wyszukiwania wektorów sztucznej inteligencji mozaiki, należy utworzyć następujące elementy:
Punkt końcowy wyszukiwania wektorów. Ten punkt końcowy obsługuje indeks wyszukiwania wektorowego. Możesz wykonywać zapytania do punktu końcowego i update przy użyciu interfejsu API REST lub zestawu SDK. Aby uzyskać instrukcje, zobacz Tworzenie punktu końcowego wyszukiwania wektorów.
Punkty końcowe są skalowane automatycznie w górę, aby obsługiwać rozmiar indeksu lub liczbę współbieżnych żądań. Punkty końcowe nie są automatycznie skalowane w dół.
Indeks wyszukiwania wektorowego. Indeks wyszukiwania wektorów jest tworzony z Delty table i jest zoptymalizowany pod kątem umożliwienia realizowania przybliżonych wyszukiwań najbliższych sąsiadów w czasie rzeczywistym. Celem wyszukiwania jest zidentyfikowanie dokumentów, które są podobne do zapytania. Indeksy wyszukiwania wektorowego pojawiają się i są kontrolowane przez Unity Catalog. Aby uzyskać instrukcje, zobacz Tworzenie indeksu wyszukiwania wektorów.
Ponadto jeśli zdecydujesz się, aby usługa Databricks obliczała osadzanie, możesz użyć wstępnie skonfigurowanego punktu końcowego interfejsów API modelu podstawowego lub utworzyć punkt końcowy obsługujący model służący do obsługi wybranego modelu osadzania. Aby uzyskać instrukcje, zobacz interfejsy API modelu modelu z płatnością za token lub Tworzenie modelu podstawowego obsługującego punkty końcowe.
Aby wykonać zapytanie dotyczące punktu końcowego obsługującego model, należy użyć interfejsu API REST lub zestawu SDK języka Python. Zapytanie może definiować filtry na podstawie dowolnego column w Delcie table. Aby uzyskać szczegółowe informacje, zobacz Używanie filtrów dla zapytań, dokumentacji interfejsu API lub dokumentacji zestawu SDK języka Python.
Wymagania
- Obszar roboczy z funkcją Catalog włączoną dla Unity.
- Włączono bezserwerowe obliczenia. Aby uzyskać instrukcje, zobacz Connect to serverless compute (Nawiązywanie połączenia z obliczeniami bezserwerowych).
- Źródło table musi mieć włączony Przepływ Zmian Danych. Aby uzyskać instrukcje, zobacz Use Delta Lake change data feed on Azure Databricks (Używanie zestawienia zmian usługi Delta Lake w usłudze Azure Databricks).
- Aby utworzyć indeks wyszukiwania wektorowego, musisz mieć uprawnienia CREATE TABLE w catalogschemawhere, gdzie indeks zostanie utworzony.
Uprawnienia do tworzenia punktów końcowych wyszukiwania wektorów i zarządzania nimi są konfigurowane przy użyciu list kontroli dostępu. Zobacz Listy ACL punktu końcowego wyszukiwania wektorów.
Ochrona i uwierzytelnianie danych
Usługa Databricks implementuje następujące mechanizmy kontroli zabezpieczeń w celu ochrony danych:
- Każde żądanie klienta do wyszukiwania wektorów sztucznej inteligencji mozaiki jest logicznie izolowane, uwierzytelniane i autoryzowane.
- Wyszukiwanie wektorów mozaiki sztucznej inteligencji szyfruje wszystkie dane magazynowane (AES-256) i podczas przesyłania (TLS 1.2+).
Aplikacja Mosaic AI Vector Search obsługuje dwa tryby uwierzytelniania:
Token głównego obiektu usługi. Administrator może generate tokena jednostki usługi i przekazać go do SDK lub interfejsu API. Zobacz Use service principals (Używanie jednostek usługi). W przypadku przypadków użycia w środowisku produkcyjnym usługa Databricks zaleca użycie tokenu jednostki usługi.
# Pass in a service principal vsc = VectorSearchClient(workspace_url="...", service_principal_client_id="...", service_principal_client_secret="..." )Osobisty token dostępu. Możesz użyć osobistego tokenu dostępu do uwierzytelniania za pomocą narzędzia Mosaic AI Vector Search. Zobacz osobisty token uwierzytelniania dostępu. Jeśli używasz zestawu SDK w środowisku notatnika, zestaw SDK automatycznie generuje token PAT na potrzeby uwierzytelniania.
# Pass in the PAT token client = VectorSearchClient(workspace_url="...", personal_access_token="...")
Klucze zarządzane przez klienta (CMK) są obsługiwane w punktach końcowych utworzonych 8 maja 2024 r.
Monitorowanie użycia i kosztów
Rozliczany system użycia table umożliwia monitorowanie użycia i kosztów skojarzonych z indeksami wyszukiwania wektorowego i punktami końcowymi. Oto przykładowe zapytanie:
WITH all_vector_search_usage (
SELECT *,
CASE WHEN usage_metadata.endpoint_name IS NULL
THEN 'ingest'
ELSE 'serving'
END as workload_type
FROM system.billing.usage
WHERE billing_origin_product = 'VECTOR_SEARCH'
),
daily_dbus AS (
SELECT workspace_id,
cloud,
usage_date,
workload_type,
usage_metadata.endpoint_name as vector_search_endpoint,
SUM(usage_quantity) as dbus
FROM all_vector_search_usage
GROUP BY all
ORDER BY 1,2,3,4,5 DESC
)
SELECT * FROM daily_dbus
Aby uzyskać szczegółowe informacje na temat zawartości użycia bilingowego table, zobacz System rozliczania użycia table referencja. Dodatkowe zapytania znajdują się w poniższym przykładowym notesie.
System wyszukiwania wektorowego w zeszycie zapytań tables
Limity rozmiaru zasobów i danych
Poniższy table podsumowuje limity rozmiarów zasobów i danych dla punktów końcowych i indeksów wyszukiwania wektorowego:
| Zasób | Poziom szczegółowości | Limit |
|---|---|---|
| Punkty końcowe wyszukiwania wektorowego | Na obszar roboczy | 100 |
| Osadzanie | Na punkt końcowy | 320,000,000 |
| Wymiar osadzania | Na indeks | 4096 |
| Indeksy | Na punkt końcowy | 50 |
| Columns | Na indeks | 50 |
| Columns | Obsługiwane typy: bajty, krótkie, liczba całkowita, długa, zmiennoprzecinkowa, podwójna, wartość logiczna, ciąg, sygnatura czasowa, data | |
| Pola metadanych | Na indeks | 50 |
| Nazwa indeksu | Na indeks | 128 znaków |
Następujące limity dotyczą tworzenia i update indeksów wyszukiwania wektorowego:
| Zasób | Poziom szczegółowości | Limit |
|---|---|---|
| Rozmiar wiersza dla indeksu Delta Sync | Na indeks | 100 KB |
| Osadzanie rozmiaru źródła column dla indeksu Delta Sync | Na indeks | 32764 bajty |
| Rozmiar żądania zbiorczego upsert limit dla indeksu wektora bezpośredniego | Na indeks | 10 MB |
| Rozmiar żądania masowego usuwania limit dla indeksu wektora bezpośredniego | Na indeks | 10 MB |
Następujące limity dotyczą interfejsu API zapytań.
| Zasób | Poziom szczegółowości | Limit |
|---|---|---|
| Długość tekstu kwerendy | Na zapytanie | 32764 bajty |
| Maksymalna liczba zwróconych wyników | Na zapytanie | 10,000 |
Ograniczenia
- Uprawnienia na poziomie wiersza i column nie są obsługiwane. Można jednak zaimplementować własne listy ACL na poziomie aplikacji przy użyciu interfejsu API filtrowania.