Pobieranie architektur referencyjnych usługi Lakehouse
W tym artykule opisano wskazówki dotyczące architektury dla usługi Lakehouse pod względem źródła danych, pozyskiwania, przekształcania, wykonywania zapytań i przetwarzania, obsługi, analizy/danych wyjściowych i magazynu.
Każda architektura referencyjna ma plik PDF do pobrania w formacie 11 x 17 (A3).
Ogólna architektura referencyjna
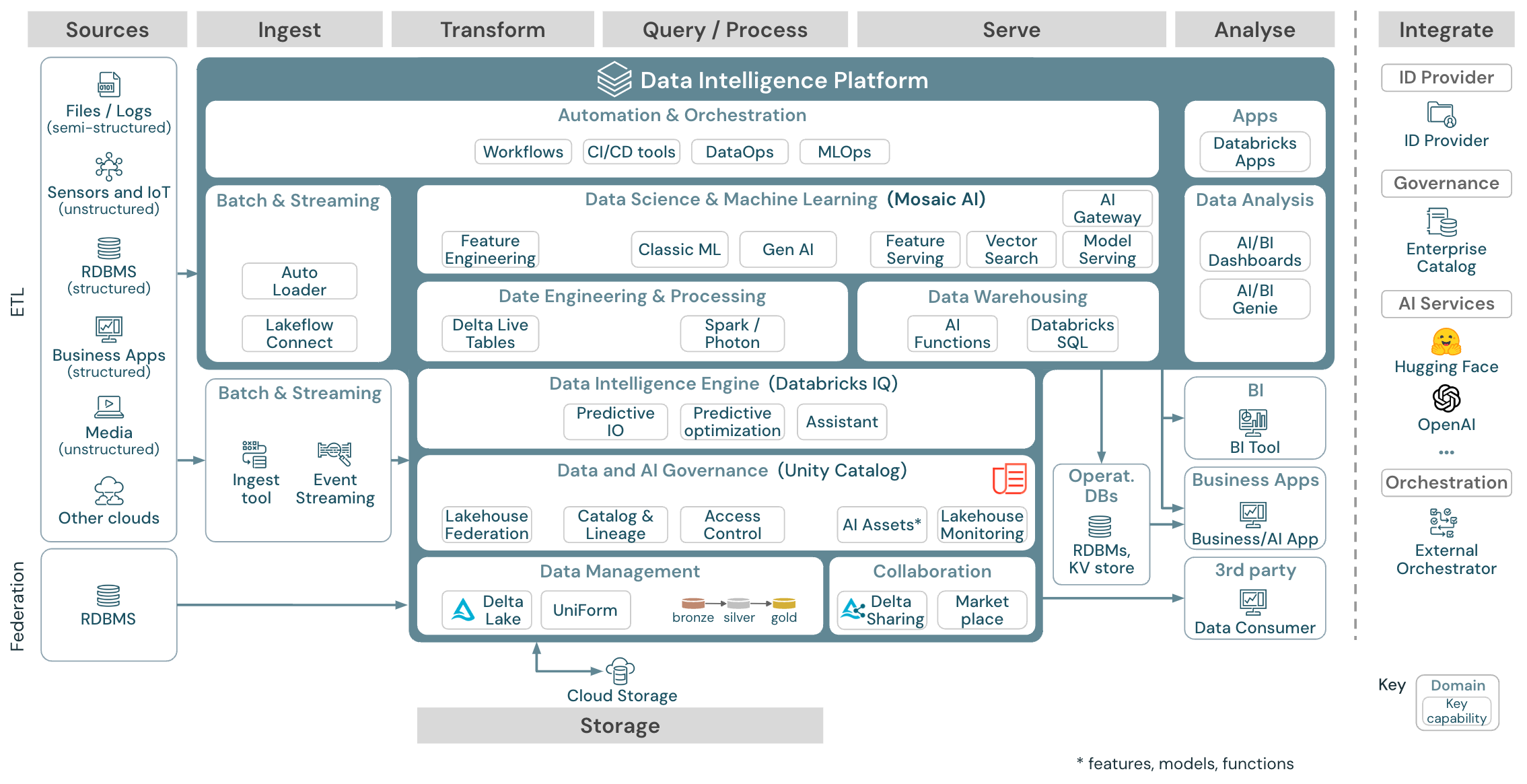
Pobierz: Ogólna architektura referencyjna usługi Lakehouse dla usługi Databricks (PDF)
Organizacja architektur referencyjnych
Architektura referencyjna jest ustrukturyzowana wzdłuż ścieżek ścieżek ścieżek źródłowych, pozyskiwania, przekształcania, wykonywania zapytań i przetwarzania, obsługi, analizy i magazynowania:
Source
Architektura rozróżnia dane częściowo ustrukturyzowane i nieustrukturyzowane (czujniki i IoT, nośniki, pliki/dzienniki) i dane ustrukturyzowane (RDBMS, aplikacje biznesowe). Źródła SQL (RDBMS) można również zintegrować z usługą Lakehouse i Unity Catalog bez uwierzytelniania ETL za pośrednictwem federacji lakehouse. Ponadto dane mogą być ładowane z innych dostawców usług w chmurze.
Spożywać
Dane można pozyskiwać do magazynu lakehouse za pośrednictwem partii lub przesyłania strumieniowego:
- Pliki dostarczane do magazynu w chmurze można ładować bezpośrednio przy użyciu modułu automatycznego ładującego usługi Databricks.
- W przypadku pozyskiwania danych wsadowych z aplikacji dla przedsiębiorstw do usługi Delta Lake usługa Databricks Lakehouse opiera się na narzędziach pozyskiwania partnerów z określonymi adapterami dla tych systemów rekordów.
- Zdarzenia przesyłania strumieniowego można pozyskiwać bezpośrednio z systemów przesyłania strumieniowego zdarzeń, takich jak Kafka, przy użyciu przesyłania strumieniowego ze strukturą usługi Databricks. Źródła przesyłania strumieniowego mogą być czujnikami, IoT lub procesami przechwytywania zmian danych.
Storage
Dane są zwykle przechowywane w systemie magazynu w chmurze, w którym potoki ETL używają architektury medalonu do przechowywania danych w sposób wyselekcjonowy jako pliki/tabele delty.
Przekształcanie i przetwarzanie zapytań
Usługa Databricks lakehouse używa aparatów Apache Spark i Photon do wszystkich przekształceń i zapytań.
Ze względu na prostotę struktura deklaratywna DLT (delta live tables) jest dobrym wyborem do tworzenia niezawodnych, konserwowalnych i testowalnych potoków przetwarzania danych.
Obsługiwane przez platformy Apache Spark i Photon platforma analizy danych usługi Databricks obsługuje oba typy obciążeń: zapytania SQL za pośrednictwem magazynów SQL oraz obciążenia SQL, Python i Scala za pośrednictwem klastrów obszarów roboczych.
W przypadku nauki o danych (modelowanie uczenia maszynowego i sztuczna inteligencja generacji) platforma AI i Machine Learning usługi Databricks udostępnia wyspecjalizowane środowiska uruchomieniowe uczenia maszynowego dla rozwiązania AutoML i kodowania zadań uczenia maszynowego. Wszystkie przepływy pracy nauki o danych i metodyce MLOps są najlepiej obsługiwane przez platformę MLflow.
Służyć
W przypadku przypadków użycia usług DWH i ANALIZY biznesowej usługa Databricks lakehouse udostępnia usługę Databricks SQL, magazyn danych obsługiwany przez magazyny SQL i bezserwerowe magazyny SQL.
W przypadku uczenia maszynowego obsługa modeli to skalowalna, w czasie rzeczywistym możliwość obsługi modelu klasy korporacyjnej hostowana na płaszczyźnie sterowania usługi Databricks.
Operacyjne bazy danych: systemy zewnętrzne, takie jak operacyjne bazy danych, mogą służyć do przechowywania i dostarczania końcowych produktów danych do aplikacji użytkowników.
Współpraca: Partnerzy biznesowi uzyskują bezpieczny dostęp do potrzebnych danych za pośrednictwem funkcji udostępniania różnicowego. W oparciu o udostępnianie różnicowe platforma Marketplace usługi Databricks jest otwartym forum do wymiany produktów danych.
Analiza
Końcowe aplikacje biznesowe znajdują się w tym torze pływania. Przykłady obejmują klientów niestandardowych, takich jak aplikacje sztucznej inteligencji połączone z usługą Mosaic AI Model Serving na potrzeby wnioskowania w czasie rzeczywistym lub aplikacji, które uzyskują dostęp do danych wypychanych z usługi Lakehouse do operacyjnej bazy danych.
W przypadku przypadków użycia analizy biznesowej analitycy zazwyczaj używają narzędzi analizy biznesowej do uzyskiwania dostępu do magazynu danych. Deweloperzy SQL mogą dodatkowo używać edytora SQL usługi Databricks (nie pokazanego na diagramie) na potrzeby zapytań i pulpitów nawigacyjnych.
Platforma analizy danych oferuje również pulpity nawigacyjne umożliwiające tworzenie wizualizacji danych i udostępnianie szczegółowych informacji.
Możliwości obciążeń
Ponadto usługa Databricks Lakehouse oferuje możliwości zarządzania, które obsługują wszystkie obciążenia:
Zarządzanie danymi i sztuczną inteligencją
Centralnym systemem zarządzania danymi i sztuczną inteligencją w usłudze Databricks Data Intelligence Platform jest wykaz aparatu Unity. Wykaz aparatu Unity udostępnia jedno miejsce do zarządzania zasadami dostępu do danych, które mają zastosowanie we wszystkich obszarach roboczych i obsługuje wszystkie zasoby utworzone lub używane w usłudze Lakehouse, takie jak tabele, woluminy, funkcje (magazyn funkcji) i modele (rejestr modeli). Wykaz aparatu Unity może również służyć do przechwytywania pochodzenia danych środowiska uruchomieniowego między zapytaniami uruchamianymi w usłudze Databricks.
Monitorowanie usługi Databricks lakehouse umożliwia monitorowanie jakości danych we wszystkich tabelach na koncie. Może również śledzić wydajność modeli uczenia maszynowego i punktów końcowych obsługujących model.
Aby można było zaobserwować, tabele systemowe to magazyn analityczny hostowany w usłudze Databricks danych operacyjnych twojego konta. Tabele systemowe mogą służyć do obserwacji historycznej na koncie.
Aparat analizy danych
Platforma analizy danych usługi Databricks umożliwia całej organizacji korzystanie z danych i sztucznej inteligencji. Jest ona obsługiwana przez usługę DatabricksIQ i łączy generowanie sztucznej inteligencji z zaletami zjednoczenia usługi Lakehouse w celu zrozumienia unikatowych semantyki danych.
Asystent usługi Databricks jest dostępny w notesach usługi Databricks, edytorze SQL i edytorze plików jako asystenta sztucznej inteligencji obsługującego kontekst dla deweloperów.
Aranżacja
Zadania usługi Databricks organizuje przetwarzanie danych, uczenie maszynowe i potoki analizy na platformie analizy danych usługi Databricks. Delta Live Tables umożliwia tworzenie niezawodnych i konserwowalnych potoków ETL przy użyciu składni deklaratywnej.
Architektura referencyjna platformy analizy danych na platformie Azure
Architektura referencyjna usługi Azure Databricks pochodzi z ogólnej architektury referencyjnej przez dodanie usług specyficznych dla platformy Azure dla elementów Source, Ingest, Serve, Analysis/Output i Storages.
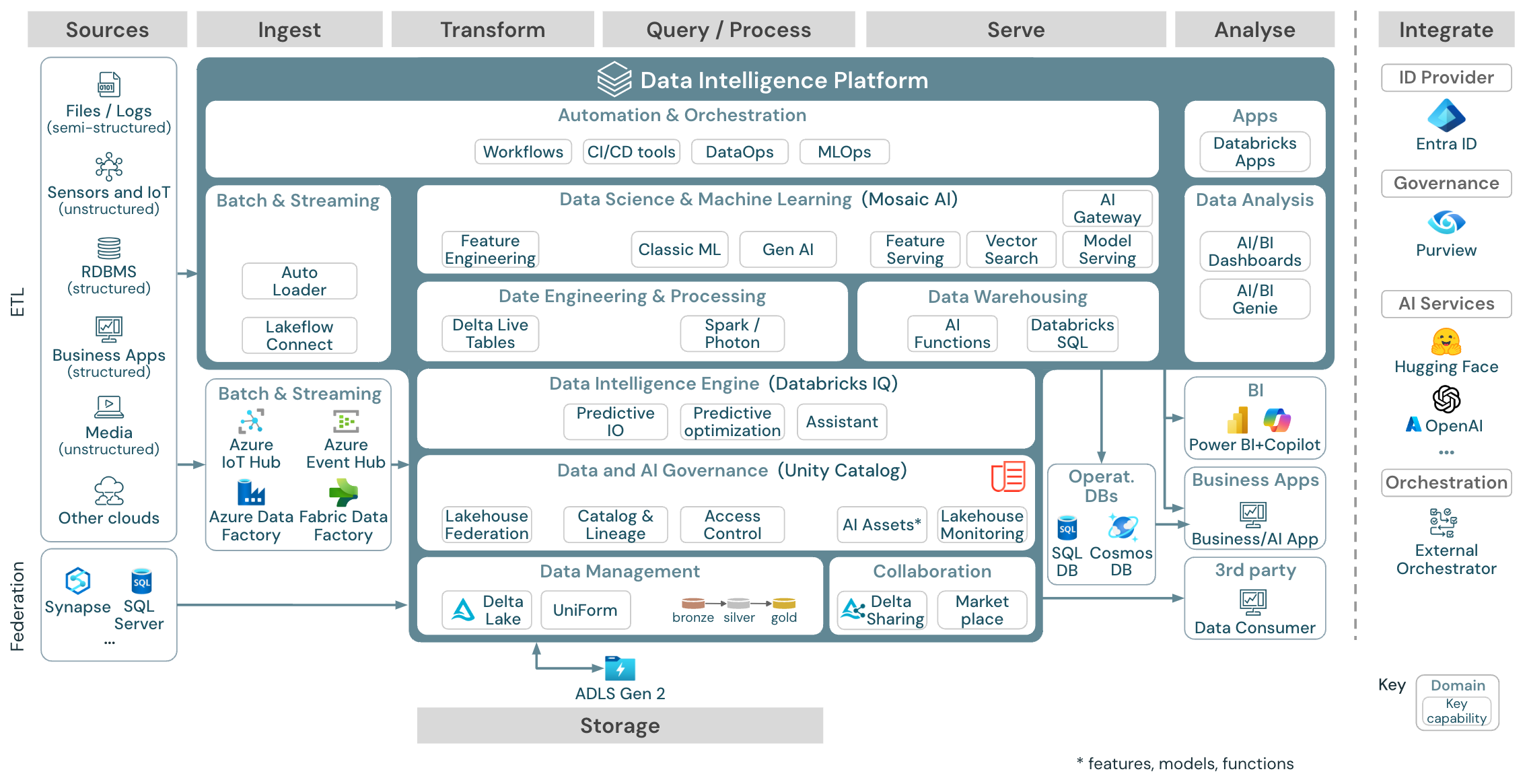
Pobierz: architektura referencyjna usługi Databricks Lakehouse na platformie Azure
Architektura referencyjna platformy Azure przedstawia następujące usługi specyficzne dla platformy Azure na potrzeby pozyskiwania, magazynowania, obsługi i analizy/danych wyjściowych:
- Usługi Azure Synapse i SQL Server jako systemy źródłowe dla usługi Lakehouse Federation
- Usługi Azure IoT Hub i Azure Event Hubs na potrzeby pozyskiwania strumieniowego
- Usługa Azure Data Factory do pozyskiwania wsadowego
- Usługa Azure Data Lake Storage Gen 2 (ADLS) jako magazyn obiektów
- Usługi Azure SQL DB i Azure Cosmos DB jako operacyjne bazy danych
- Usługa Azure Purview jako wykaz przedsiębiorstwa, do którego UC wyeksportuje informacje o schemacie i pochodzenia
- Usługa Power BI jako narzędzie analizy biznesowej
Uwaga
- Ten widok architektury referencyjnej koncentruje się tylko na usługach platformy Azure i usłudze Databricks Lakehouse. Lakehouse w usłudze Databricks to otwarta platforma, która integruje się z dużym ekosystemem narzędzi partnerskich.
- Wyświetlane usługi dostawcy usług w chmurze nie są wyczerpujące. Są one wybrane do zilustrowania koncepcji.
Przypadek użycia: Batch ETL
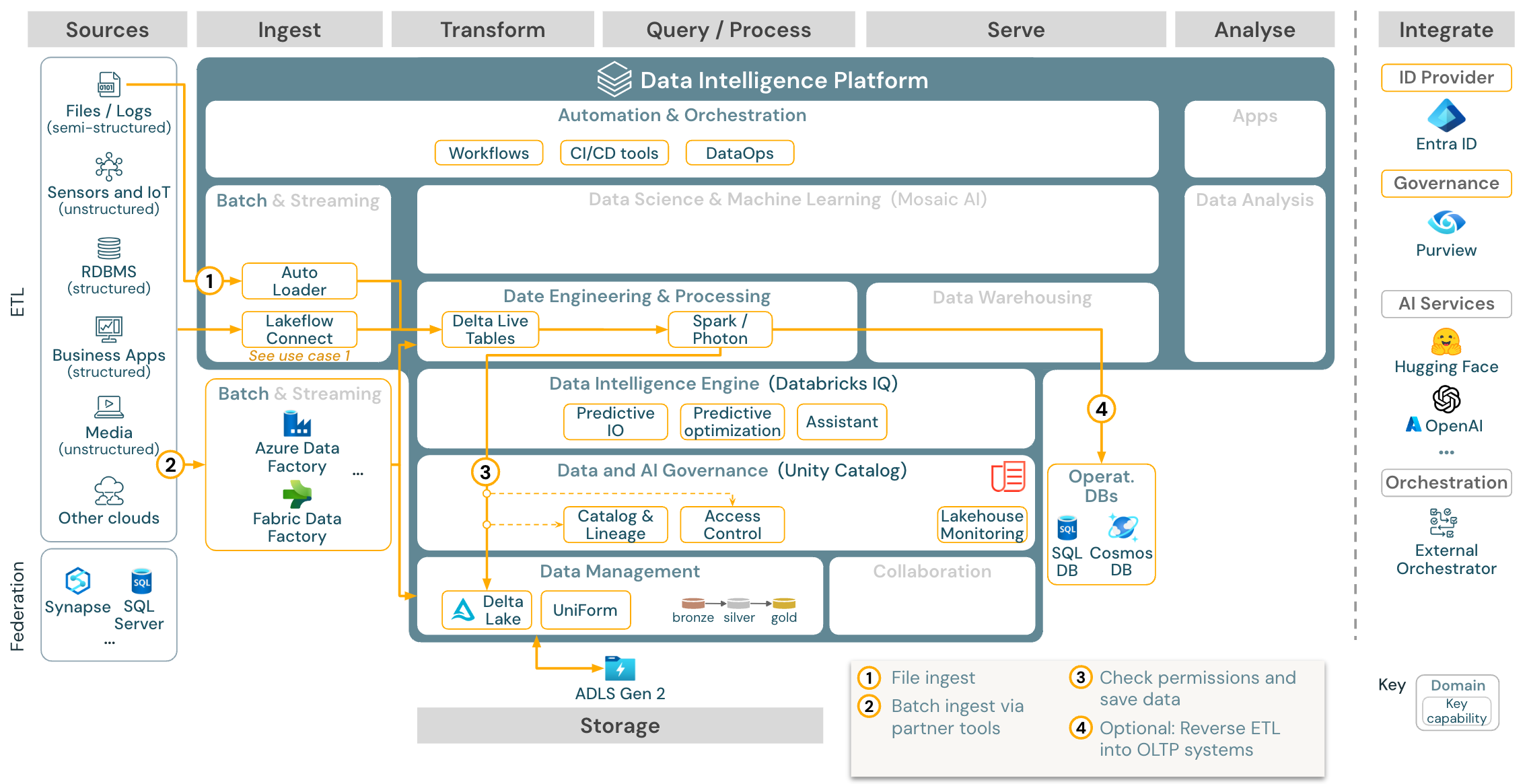
Pobieranie: Architektura referencyjna protokołu ETL usługi Batch dla usługi Azure Databricks
Narzędzia pozyskiwania używają kart specyficznych dla źródła, aby odczytywać dane ze źródła, a następnie przechowywać je w magazynie w chmurze, z którego moduł automatycznego ładowania może go odczytać, lub bezpośrednio wywołać usługę Databricks (na przykład z narzędziami pozyskiwania partnerów zintegrowanymi z usługą Databricks lakehouse). Aby załadować dane, aparat ETL usługi Databricks i aparat przetwarzania — za pośrednictwem biblioteki DLT — uruchamia zapytania. Pojedyncze lub wielozadane przepływy pracy mogą być orkiestrowane przez zadania usługi Databricks i zarządzane przez wykaz aparatu Unity (kontrola dostępu, inspekcja, pochodzenie itd.). Jeśli systemy operacyjne o małych opóźnieniach wymagają dostępu do określonych złotych tabel, można je wyeksportować do operacyjnej bazy danych, takiej jak RDBMS lub magazyn klucz-wartość na końcu potoku ETL.
Przypadek użycia: przesyłanie strumieniowe i przechwytywanie zmian danych (CDC)
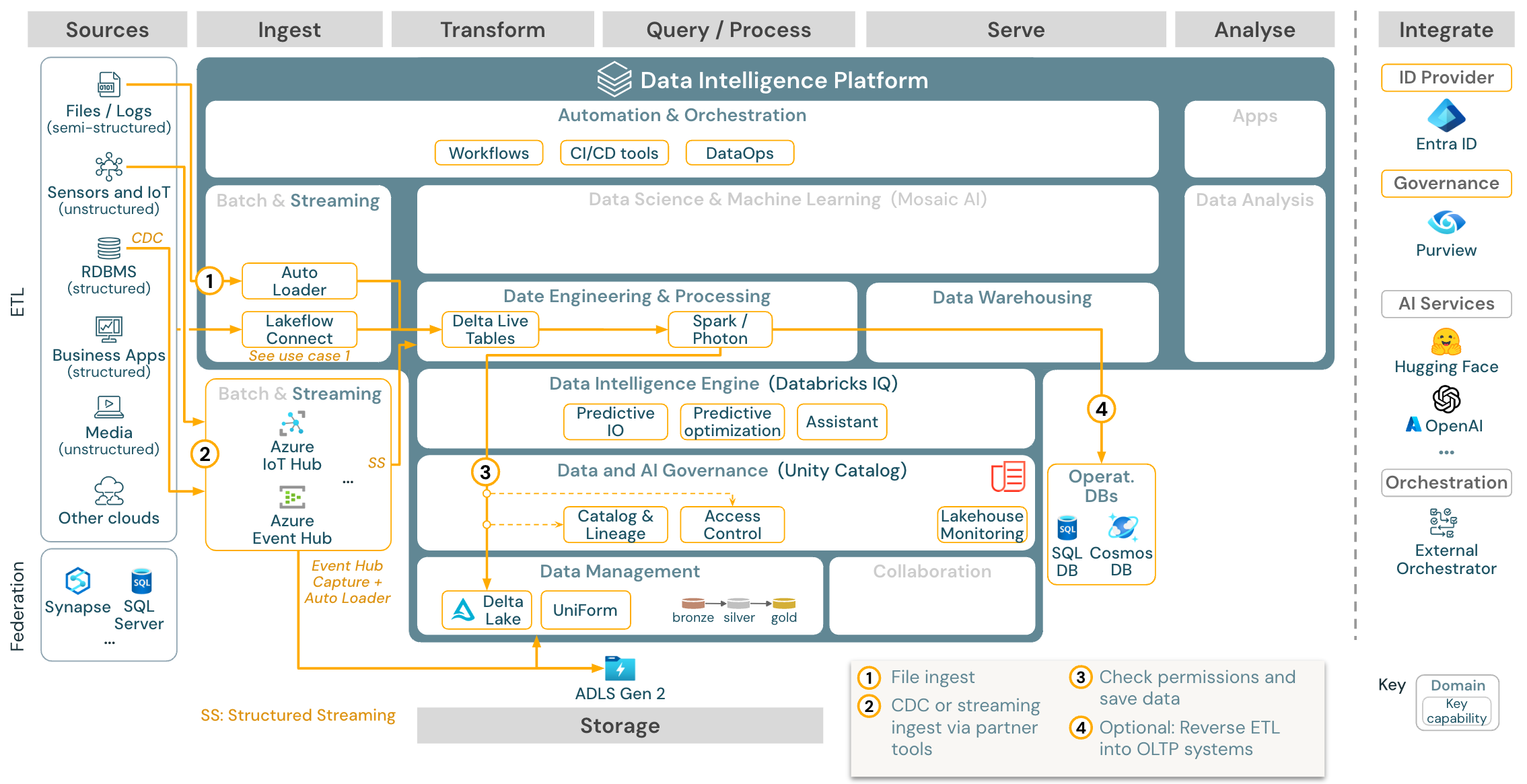
Aparat ETL usługi Databricks używa przesyłania strumieniowego ze strukturą platformy Spark do odczytywania z kolejek zdarzeń, takich jak Apache Kafka lub Azure Event Hub. Kroki podrzędne są zgodne z podejściem powyższego przypadku użycia usługi Batch.
Przechwytywanie danych zmian w czasie rzeczywistym (CDC) zwykle używa kolejki zdarzeń do przechowywania wyodrębnionych zdarzeń. W tym miejscu przypadek użycia jest zgodny z przypadkiem użycia przesyłania strumieniowego.
Jeśli usługa CDC jest wykonywana w partii, w której wyodrębnione rekordy są najpierw przechowywane w magazynie w chmurze, program Autoloader usługi Databricks może je odczytać, a przypadek użycia jest zgodny z etL usługi Batch.
Przypadek użycia: Uczenie maszynowe i sztuczna inteligencja
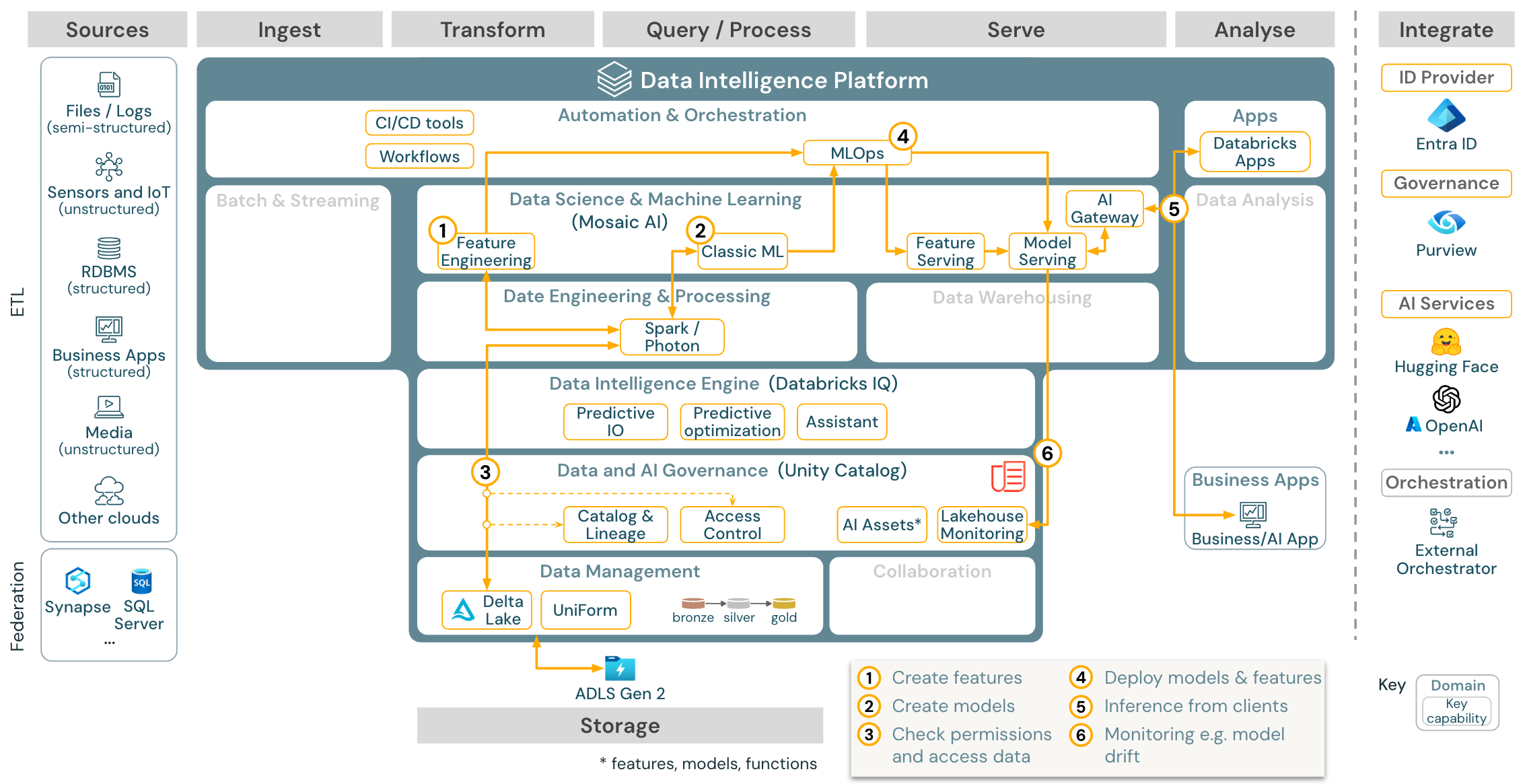
W przypadku uczenia maszynowego platforma analizy danych usługi Databricks udostępnia sztuczną inteligencję Mozaiki, która jest wyposażona w najnowocześniejsze biblioteki maszynowe i głębokie. Zapewnia ona funkcje, takie jak magazyn funkcji i rejestr modeli (zarówno zintegrowany z katalogiem aparatu Unity), funkcje z małą ilością kodu z rozwiązaniem AutoML, jak i integracja MLflow z cyklem życia nauki o danych.
Wszystkie zasoby związane z nauką o danych (tabele, funkcje i modele) podlegają katalogowi aparatu Unity, a analitycy danych mogą organizować swoje zadania przy użyciu zadań usługi Databricks.
Aby wdrożyć modele w sposób skalowalny i klasy korporacyjnej, użyj funkcji MLOps, aby opublikować modele w obsłudze modeli.
Przypadek użycia: Pobieranie rozszerzonej generacji (Gen AI)
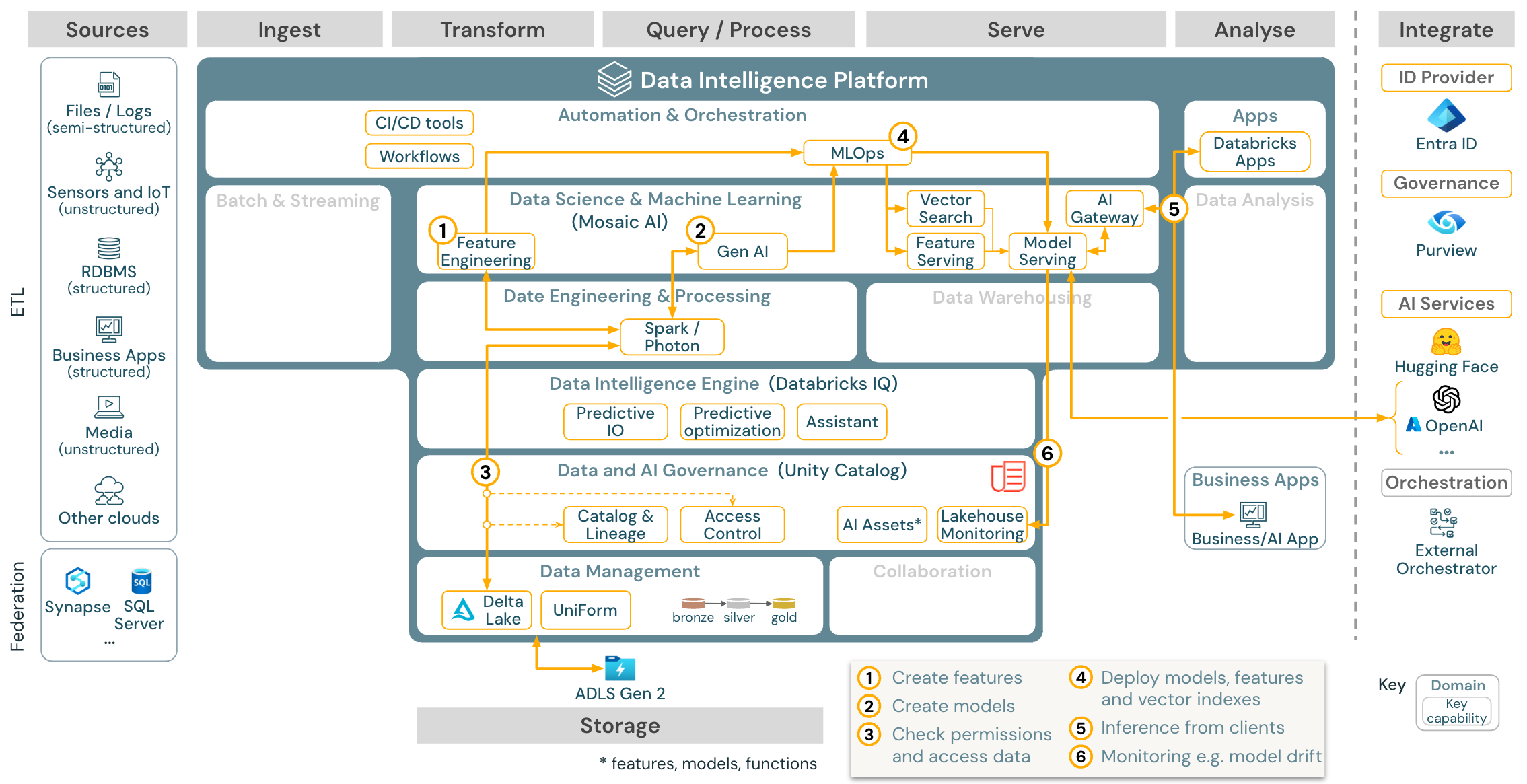
Pobierz: Architektura referencyjna rag usługi Gen AI dla usługi Azure Databricks
W przypadku przypadków użycia sztucznej inteligencji generowania sztucznej inteligencji sztuczna inteligencja jest dostarczana z najnowocześniejszymi bibliotekami i konkretnymi możliwościami sztucznej inteligencji generacji od monitowania inżynieryjnego do precyzyjnego dostrajania istniejących modeli i wstępnego trenowania od podstaw. W powyższej architekturze przedstawiono przykład, w jaki sposób można zintegrować wyszukiwanie wektorów w celu utworzenia aplikacji AI RAG (pobierania rozszerzonej generacji).
Aby wdrożyć modele w sposób skalowalny i klasy korporacyjnej, użyj funkcji MLOps, aby opublikować modele w obsłudze modeli.
Przypadek użycia: analiza analizy biznesowej i SQL
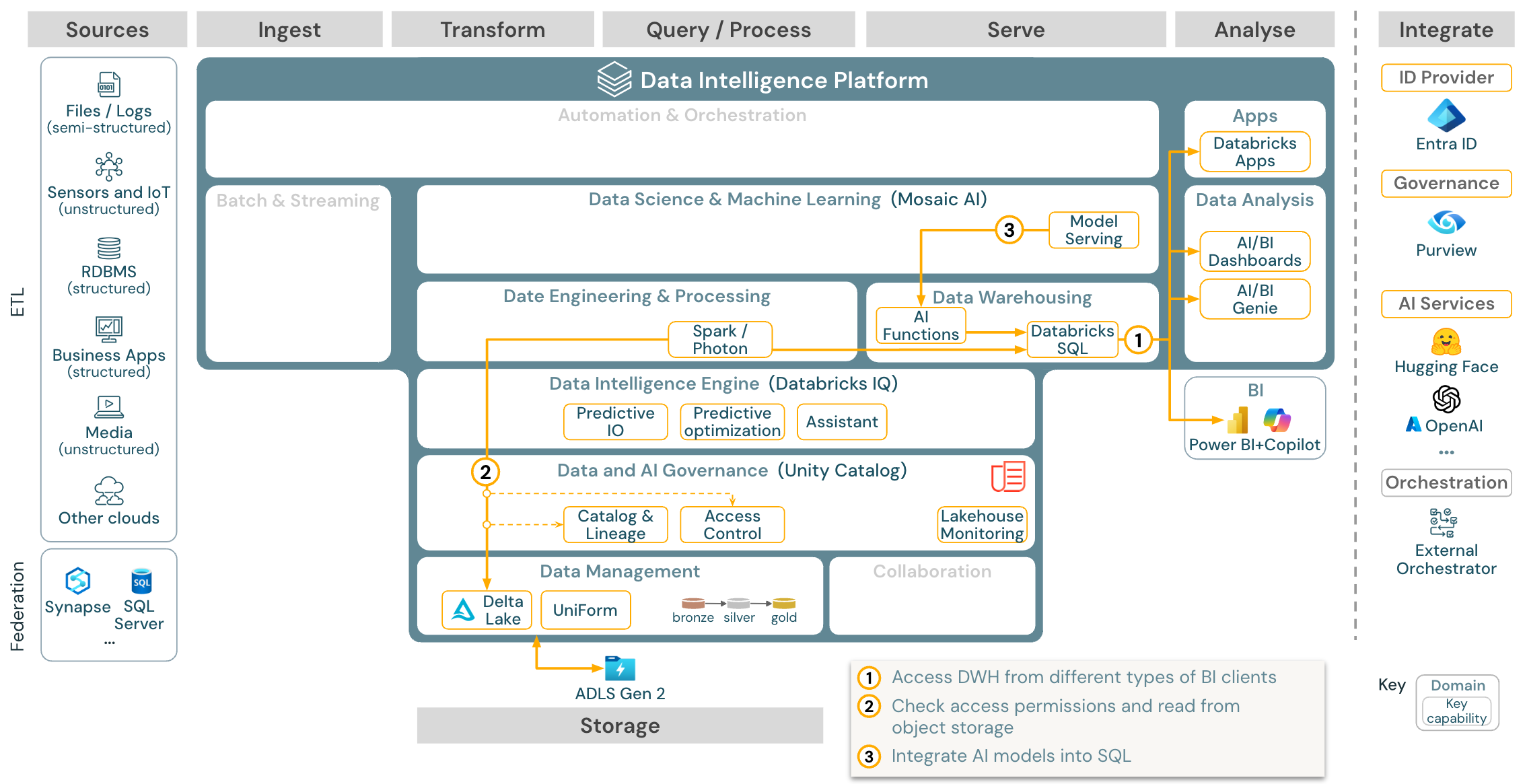
Pobieranie: architektura referencyjna analizy biznesowej i sql dla usługi Azure Databricks
W przypadku przypadków użycia analizy biznesowej analitycy biznesowi mogą używać pulpitów nawigacyjnych, edytora SQL usługi Databricks lub określonych narzędzi analizy biznesowej, takich jak Tableau lub Power BI. We wszystkich przypadkach aparat jest usługą Databricks SQL (bezserwerową lub bezserwerową), a odnajdywanie, eksploracja i kontrola dostępu są udostępniane przez wykaz aparatu Unity.
Przypadek użycia: federacja usługi Lakehouse
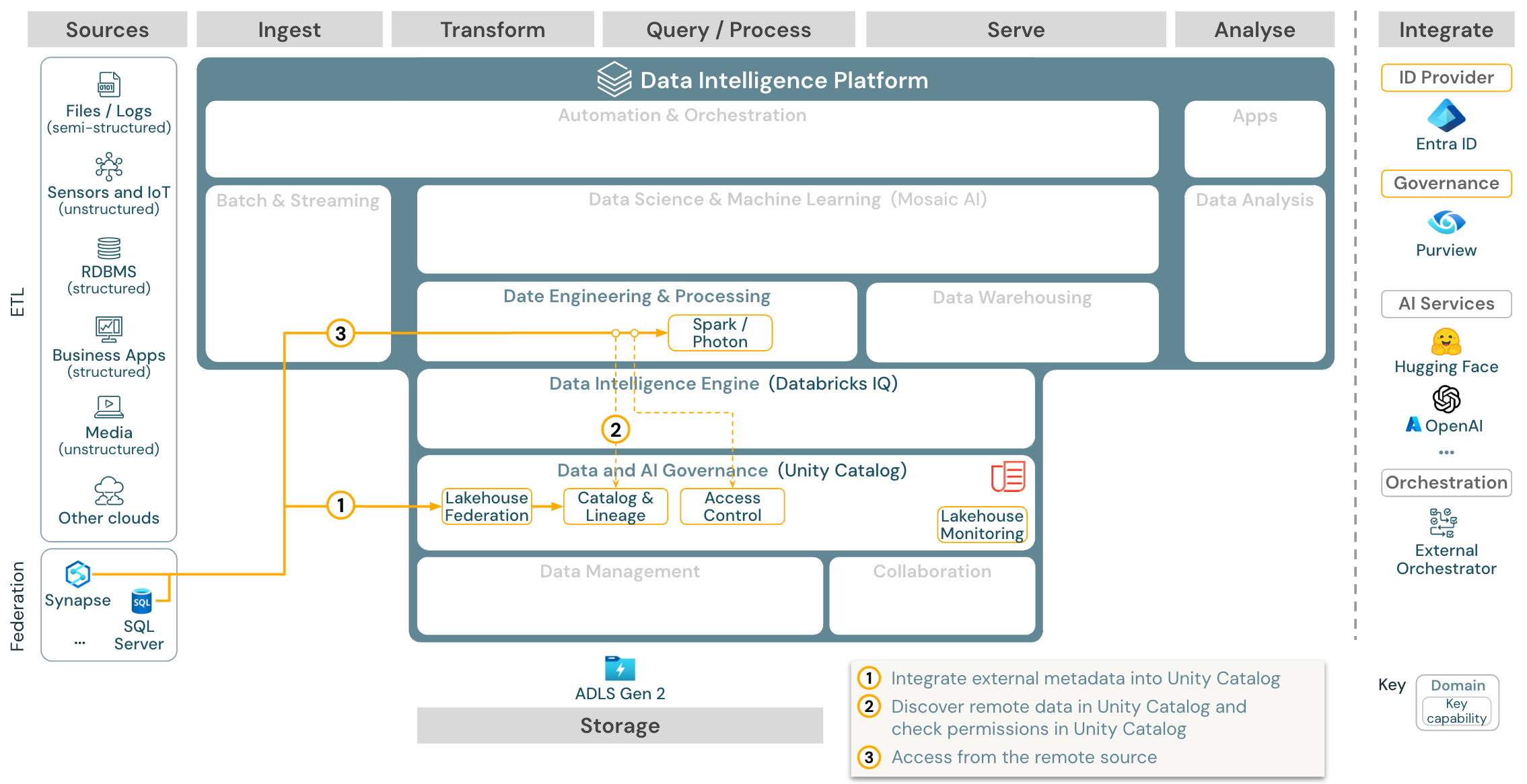
Pobieranie: Architektura referencyjna federacji usługi Lakehouse dla usługi Azure Databricks
Federacja usługi Lakehouse umożliwia integrację zewnętrznych baz danych SQL (takich jak MySQL, Postgres, SQL Server lub Azure Synapse) z usługą Databricks.
Wszystkie obciążenia (AI, DWH i BI) mogą korzystać z tego bez konieczności etl danych do magazynu obiektów. Wykaz źródeł zewnętrznych jest mapowany do katalogu aparatu Unity i szczegółowej kontroli dostępu można zastosować do uzyskiwania dostępu za pośrednictwem platformy Databricks.
Przypadek użycia: Udostępnianie danych przedsiębiorstwa
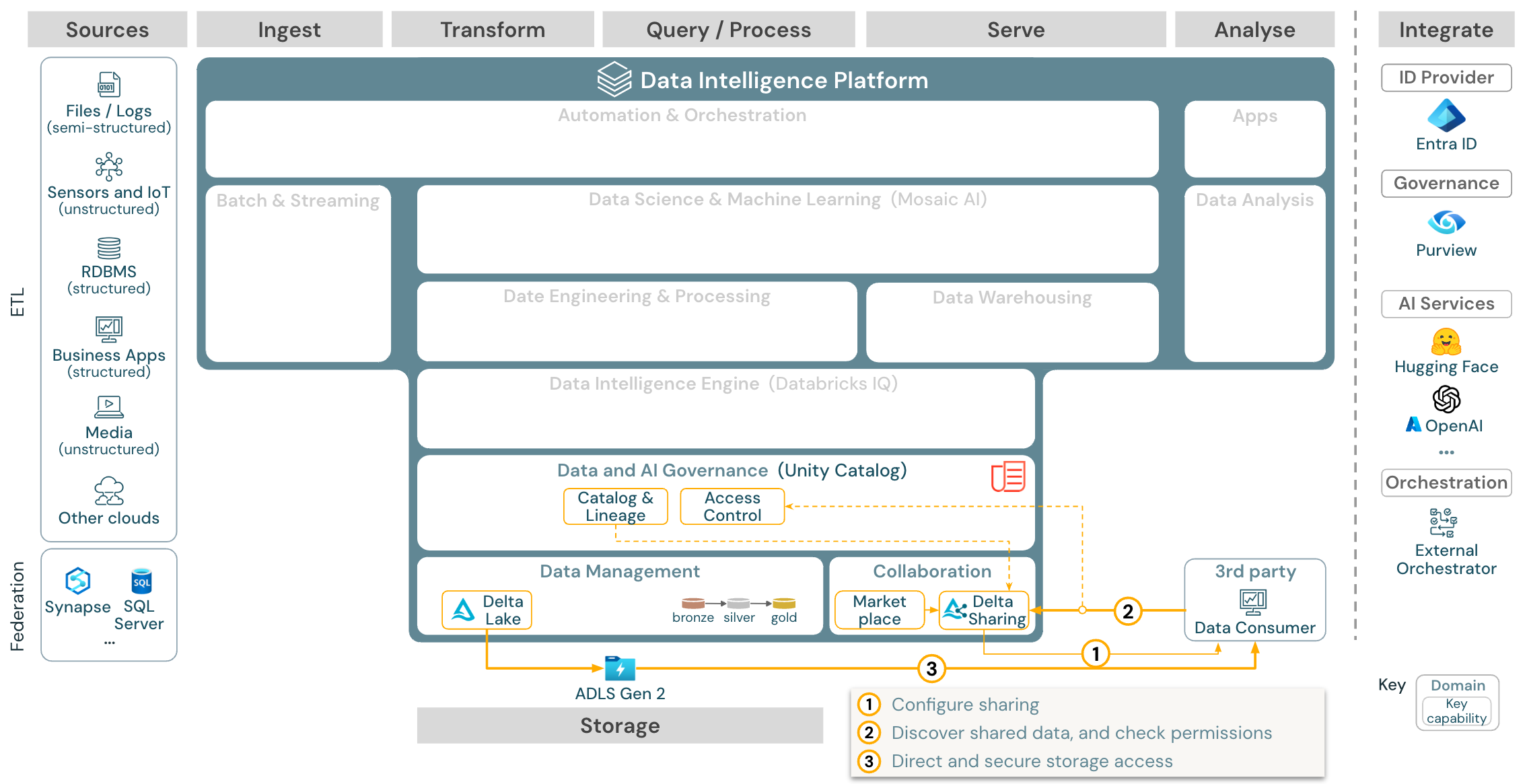
Udostępnianie danych klasy korporacyjnej jest udostępniane przez udostępnianie różnicowe. Zapewnia bezpośredni dostęp do danych w magazynie obiektów zabezpieczonym przez katalog aparatu Unity, a witryna Databricks Marketplace to otwarte forum wymiany produktów danych.