Zarządzanie cyklem życia modelu przy użyciu rejestru modeli obszaru roboczego (starsza wersja)
Ważne
Ta dokumentacja obejmuje rejestr modeli obszarów roboczych. Jeśli twój obszar roboczy ma włączoną funkcję Unity Catalog, nie należy używać procedur tej strony. Zamiast tego zobacz Models in Unity Catalog.
Aby uzyskać wskazówki dotyczące aktualizacji rejestru modeli Workspace do aparatu Unity Catalog, zobacz Migrowanie przepływów pracy i modeli do Unity Catalog.
Jeśli domyślny catalog obszaru roboczego znajduje się w aparacie Unity (Catalog zamiast hive_metastore) i uruchamiasz klaster przy użyciu środowiska Databricks Runtime 13.3 LTS lub nowszego, modele są automatycznie tworzone w i ładowane z domyślnego catalogobszaru roboczego bez konieczności konfigurowania. Aby użyć rejestru modeli obszarów roboczych w tym przypadku, należy jawnie go zastosować, uruchamiając polecenie import mlflow; mlflow.set_registry_uri("databricks") na początku obciążenia. Niewielka liczba obszarów roboczych wherecatalog domyślnych została skonfigurowana na catalog w środowisku Unity Catalog przed styczniem 2024 r., a rejestr modeli obszarów roboczych był używany przed styczniem 2024 r. jest wykluczony z tego zachowania i domyślnie korzysta z rejestru modeli obszarów roboczych.
W tym artykule opisano sposób korzystania z rejestru modeli obszarów roboczych w ramach przepływu pracy uczenia maszynowego w celu zarządzania pełnym cyklem życia modeli uczenia maszynowego. Rejestr modeli obszaru roboczego to udostępniona przez usługę Databricks hostowana wersja rejestru modeli MLflow.
Rejestr modeli obszaru roboczego zapewnia:
- Pochodzenie modelu chronologicznego (eksperyment MLflow i uruchomienie modelu produkowanego w danym momencie).
- Obsługa modelu.
- Przechowywanie wersji modelu.
- Przejścia na etapy (na przykład z przemieszczania do środowiska produkcyjnego lub zarchiwizowanego).
- Elementy webhook umożliwiające automatyczne wyzwalanie akcji na podstawie zdarzeń rejestru.
- Powiadomienia e-mail dotyczące zdarzeń modelu.
Możesz również tworzyć i wyświetlać opisy modeli oraz pozostawiać komentarze.
Ten artykuł zawiera instrukcje dotyczące interfejsu użytkownika rejestru modeli obszarów roboczych i interfejsu API rejestru modeli obszaru roboczego.
Aby zapoznać się z omówieniem pojęć dotyczących rejestru modeli obszarów roboczych, zobacz MLflow for gen AI app and model lifecycle.
Tworzenie lub rejestrowanie modelu
Model można utworzyć lub zarejestrować przy użyciu interfejsu użytkownika albo zarejestrować model przy użyciu interfejsu API.
Tworzenie lub rejestrowanie modelu przy użyciu interfejsu użytkownika
Istnieją dwa sposoby rejestrowania modelu w rejestrze modeli obszarów roboczych. Można zarejestrować istniejący zapisany model na platformie MLflow lub utworzyć i zarejestrować nowy, pusty model, a następnie przypisać do niego wcześniej zapisany model.
Rejestrowanie istniejącego zarejestrowanego modelu z notesu
W obszarze roboczym znajdź przebieg MLflow zawierający model, który chcesz zarejestrować.
Kliknij ikonę Eksperyment
 na prawym pasku bocznym notesu.
na prawym pasku bocznym notesu.
Na pasku bocznym Przebiegi eksperymentów kliknij ikonę
 obok daty uruchomienia. Zostanie wyświetlona strona MLflow Run (Przebieg platformy MLflow). Na tej stronie przedstawiono szczegóły przebiegu, w tym parameters, metryki, tagi i list artefaktów.
obok daty uruchomienia. Zostanie wyświetlona strona MLflow Run (Przebieg platformy MLflow). Na tej stronie przedstawiono szczegóły przebiegu, w tym parameters, metryki, tagi i list artefaktów.
W sekcji Artifacts (Artefakty) kliknij katalog o nazwie xxx-model.
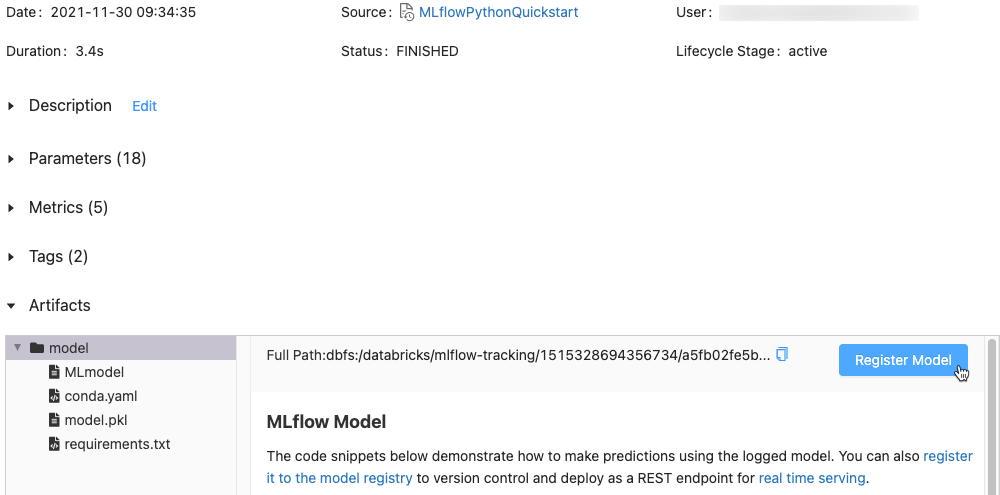
Kliknij przycisk Register model (Zarejestruj model) po prawej stronie.
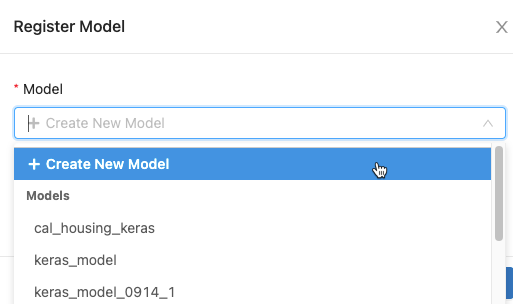
W oknie dialogowym kliknij pozycję Model i wykonaj jedną z następujących czynności:
-
Select
utwórz nowy model z menu rozwijanego. Zostanie wyświetlone pole Nazwa modelu. Wprowadź nazwę modelu, na przykład
scikit-learn-power-forecasting. - Select istniejący model z menu rozwijanego.
-
Select
utwórz nowy model z menu rozwijanego. Zostanie wyświetlone pole Nazwa modelu. Wprowadź nazwę modelu, na przykład
Kliknij pozycję Zarejestruj.
- W przypadku wybrania opcji Utwórz nowy model rejestruje model o nazwie
scikit-learn-power-forecasting, kopiuje model do bezpiecznej lokalizacji zarządzanej przez rejestr modeli obszarów roboczych i tworzy nową wersję modelu. - Jeśli wybrano istniejący model, spowoduje to zarejestrowanie nowej wersji wybranego modelu.
Po kilku chwilach przycisk Zarejestruj model zmieni się na link do nowej zarejestrowanej wersji modelu.
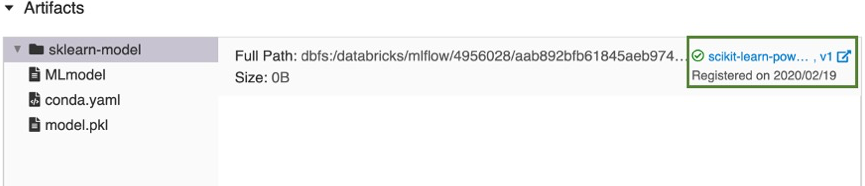
- W przypadku wybrania opcji Utwórz nowy model rejestruje model o nazwie
Kliknij link, aby otworzyć nową wersję modelu w interfejsie użytkownika rejestru modeli obszarów roboczych. Model można również znaleźć w rejestrze modeli obszaru roboczego, klikając pozycję
 Modele na pasku bocznym.
Modele na pasku bocznym.
Tworzenie nowego zarejestrowanego modelu i przypisywanie do niego zapisanego modelu
Możesz użyć przycisku Create model (Utwórz model) na stronie Registered models (Zarejestrowane modele), aby utworzyć nowy, pusty model, a następnie przypisać do niego zapisany model. Wykonaj te kroki:
Na stronie Registered models kliknij przycisk Create Model. Wprowadź nazwę modelu i kliknij pozycję Create (Utwórz).
Wykonaj kroki od 1 do 3 z sekcji Rejestrowanie istniejącego zapisanego modelu z notesu.
W oknie dialogowym "Rejestrowanie modelu" wprowadź select nazwę modelu, który utworzyłeś w kroku 1, a następnie kliknij "Zarejestruj". Spowoduje to zarejestrowanie modelu o utworzonej nazwie, skopiowanie modelu do bezpiecznej lokalizacji zarządzanej przez rejestr modeli obszaru roboczego i utworzenie wersji modelu:
Version 1.Po chwili w interfejsie użytkownika przebiegów platformy MLflow przycisk Register model zostanie zastąpiony linkiem do nowo zarejestrowanej wersji modelu. Teraz możesz
modelu z listy rozwijanej Model w oknie dialogowym Rejestrowanie modelu na stronie Przebiegi eksperymentów . Możesz również rejestrować nowe wersje modelu, wprowadzając jego nazwę w poleceniach interfejsu API takich jak Create ModelVersion.
Rejestrowanie modelu przy użyciu interfejsu API
Istnieją trzy programowe sposoby rejestrowania modelu w rejestrze modeli obszarów roboczych. Wszystkie metody kopiują model do bezpiecznej lokalizacji zarządzanej przez rejestr modeli obszaru roboczego.
Aby zapisać model i zarejestrować go z określoną nazwą podczas eksperymentu platformy MLflow, użyj metody
mlflow.<model-flavor>.log_model(...). Jeśli nie istnieje jeszcze zarejestrowany model z taką nazwą, ta metoda spowoduje zarejestrowanie nowego modelu, utworzenie wersji 1 i zwrócenie obiektu MLflowModelVersion. Jeśli już istnieje zarejestrowany model o takiej nazwie, ta metoda spowoduje utworzenie nowej wersji modelu i zwrócenie obiektu wersji.with mlflow.start_run(run_name=<run-name>) as run: ... mlflow.<model-flavor>.log_model(<model-flavor>=<model>, artifact_path="<model-path>", registered_model_name="<model-name>" )Aby zarejestrować model z określoną nazwą po zakończeniu wszystkich przebiegów eksperymentu i wybraniu najbardziej odpowiedniego modelu do zarejestrowania, użyj metody
mlflow.register_model(). W tej metodzie potrzebujesz identyfikatora przebiegu do użycia w argumenciemlruns:URI. Jeśli nie istnieje jeszcze zarejestrowany model z taką nazwą, ta metoda spowoduje zarejestrowanie nowego modelu, utworzenie wersji 1 i zwrócenie obiektu MLflowModelVersion. Jeśli już istnieje zarejestrowany model o takiej nazwie, ta metoda spowoduje utworzenie nowej wersji modelu i zwrócenie obiektu wersji.result=mlflow.register_model("runs:<model-path>", "<model-name>")Aby utworzyć nowy zarejestrowany model z określoną nazwą, użyj metody
create_registered_model()interfejsu API klienta platformy MLflow. Jeśli taka nazwa modelu już istnieje, metoda zwróci wyjątekMLflowException.client = MlflowClient() result = client.create_registered_model("<model-name>")
Możesz również zarejestrować model za pomocą dostawcy narzędzia Terraform usługi Databricks i databricks_mlflow_model.
Limity przydziału
Od maja 2024 r. dla wszystkich obszarów roboczych usługi Databricks rejestr modeli obszarów roboczych nakłada limity przydziału na łączną liczbę zarejestrowanych modeli i wersji modelu na obszar roboczy. Zobacz Limity zasobów. Jeśli przekroczono limity przydziału rejestru, usługa Databricks zaleca usunięcie zarejestrowanych modeli i wersji modelu, które nie są już potrzebne. Usługa Databricks zaleca również dostosowanie strategii rejestracji i przechowywania modelu, aby pozostać poniżej limit. Jeśli potrzebujesz zwiększenia limitów obszaru roboczego, skontaktuj się z zespołem ds. kont usługi Databricks.
W poniższym notesie pokazano, jak spisać i usuwać jednostki rejestru modelu.
Notes jednostek rejestru modelu obszaru roboczego spisu
Wyświetlanie modeli w interfejsie użytkownika
Strona Zarejestrowanych modeli
Po kliknięciu przycisku ![]() Modele na pasku bocznym zostanie wyświetlona strona Zarejestrowanych modeli. Na tej stronie przedstawiono wszystkie modele w rejestrze.
Modele na pasku bocznym zostanie wyświetlona strona Zarejestrowanych modeli. Na tej stronie przedstawiono wszystkie modele w rejestrze.
Na tej stronie możesz utworzyć nowy model .
Ponadto na tej stronie administratorzy obszaru roboczego mogą set uprawnienia do wszystkich modeli w rejestrze modeli obszaru roboczego.

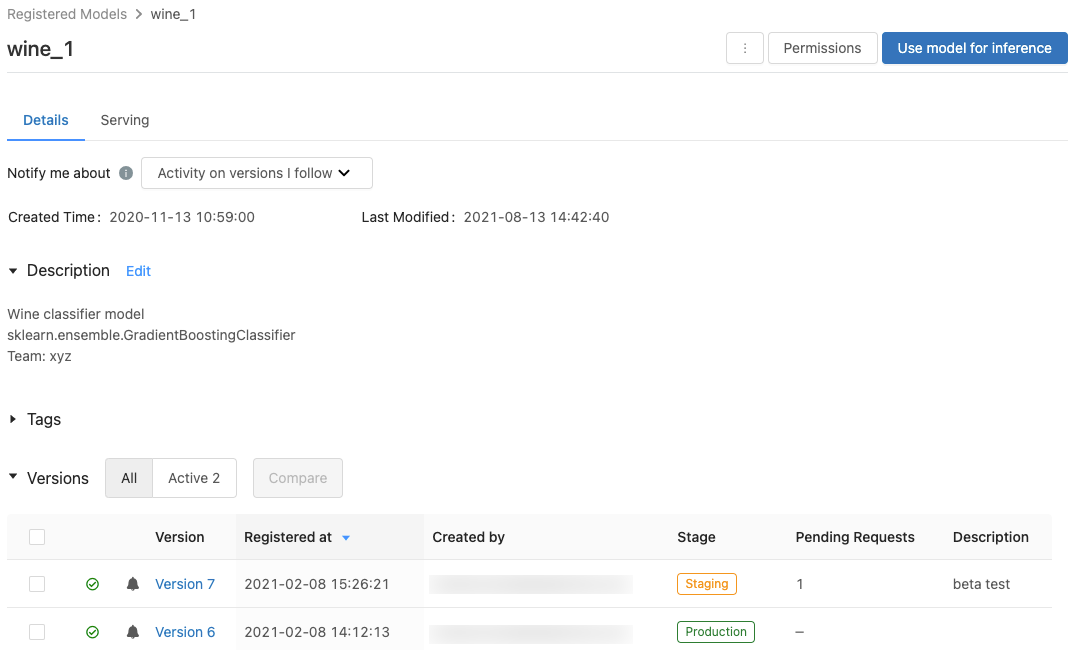
Zarejestrowana strona modelu
Aby wyświetlić zarejestrowaną stronę modelu dla modelu, kliknij nazwę modelu na stronie zarejestrowanych modeli. Strona zarejestrowanego modelu zawiera informacje o wybranym modelu i table z informacjami o każdej wersji modelu. Na tej stronie można również wykonywać następujące czynności:
- Set uruchomienie modelu.
- Automatycznie generate notatnik do użycia modelu do wnioskowania.
- Konfigurowanie powiadomień e-mail.
- Porównanie wersji modelu.
- Set uprawnienia dla modelu.
- Usuwanie modelu.
Strona wersji modelu
Aby wyświetlić stronę wersji modelu, wykonaj jedną z następujących czynności:
- Kliknij nazwę wersji w Najnowsza Wersjacolumn na stronie zarejestrowanych modeli.
- Kliknij nazwę wersji w wersji column na stronie zarejestrowanego modelu.
Na tej stronie są wyświetlane informacje o określonej wersji zarejestrowanego modelu, a także link do przebiegu źródłowego (wersja notesu, który został uruchomiony w celu utworzenia modelu). Na tej stronie można również wykonywać następujące czynności:
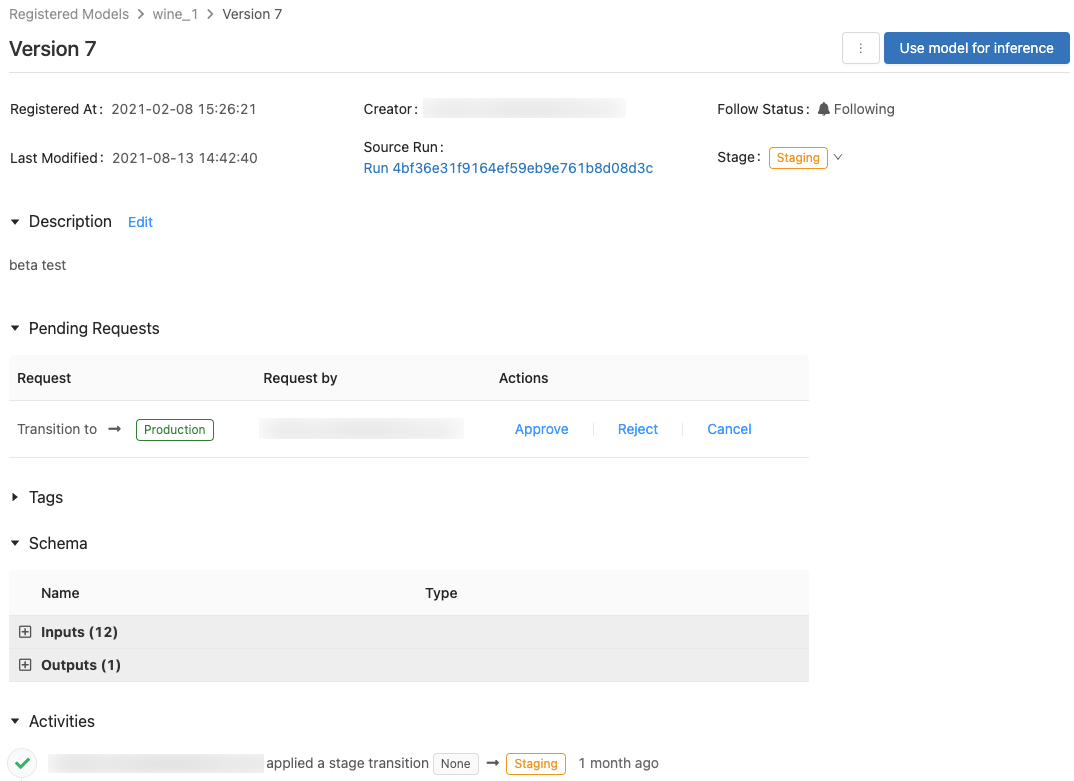
Kontrolowanie dostępu do modeli
Aby skonfigurować uprawnienia do modelu, musisz mieć co najmniej uprawnienia DO ZARZĄDZANIA. Aby uzyskać informacje na temat poziomów uprawnień modelu, zobacz Listy ACL modelu MLflow. Wersja modelu dziedziczy uprawnienia po modelu nadrzędnym. Nie można set uprawnień dla wersji modelu.
Na pasku bocznym kliknij pozycję
Modele.Select nazwa modelu.
Kliknij pozycję Uprawnienia. Zostanie otwarte okno dialogowe Ustawienia uprawnień

W oknie dialogowym selectSelect użytkownika, grupy lub jednostki usługi... listy rozwijanej i select użytkownika, grupy lub jednostki usługi.
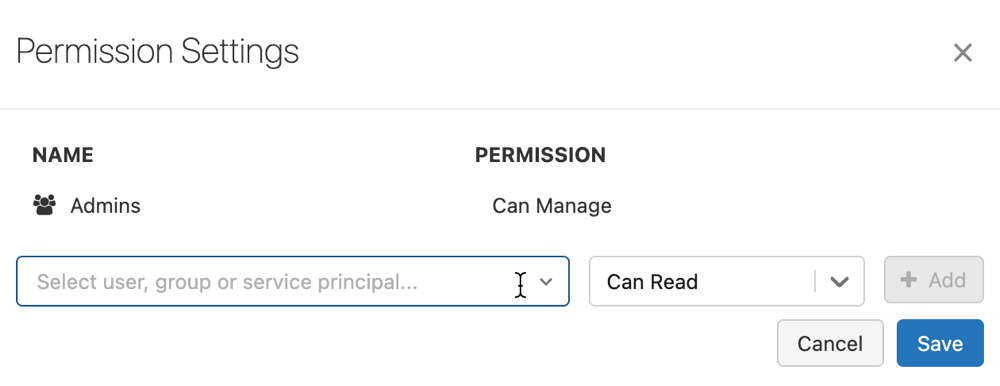
Select uprawnienia z listy rozwijanej uprawnień.
Kliknij przycisk Dodaj i kliknij przycisk Zapisz.
Administratorzy obszaru roboczego i użytkownicy z uprawnieniami CAN MANAGE na poziomie rejestru mogą set poziomów uprawnień we wszystkich modelach w obszarze roboczym, klikając Uprawnienia na stronie Modele.
Przenoszenie etapu modelu
Wersja modelu ma jeden z następujących etapów: Brak, Przejściowe, Produkcyjne lub Zarchiwizowane. Etap Staging jest przeznaczony do testowania i walidacji modeli, natomiast etap Production jest przeznaczony dla wersji modeli, które przeszły już procesy testowania lub przeglądu i zostały wdrożone w aplikacjach w celu wykonywania oceny na żywo. Zakłada się, że wersja modelu w archiwum jest już nieaktywna, można więc rozważyć jej usunięcie. Różne wersje modelu mogą znajdować się na różnych etapach.
Użytkownik z odpowiednimi uprawnieniami może przenosić wersję modelu między etapami. Jeśli masz uprawnienia do przeniesienia wersji modelu do określonego etapu, możesz wykonać to przeniesienie bezpośrednio. Jeśli nie masz takich uprawnień, możesz zażądać przeniesienia między etapami, a użytkownik mający uprawnienia do przenoszenia wersji modeli może wówczas zatwierdzić, odrzucić lub anulować to żądanie.
Etap modelu można przenieść przy użyciu interfejsu użytkownika lub interfejsu API.
Przenoszenie modeli między etapami przy użyciu interfejsu użytkownika
Skorzystaj z tych instrukcji, aby przenieść model do innego etapu.
Aby wyświetlić list dostępnych etapów modelu i dostępnych opcji, na stronie wersji modelu kliknij listę rozwijaną obok Etap: i zażądaj lub select przejście do innego etapu.
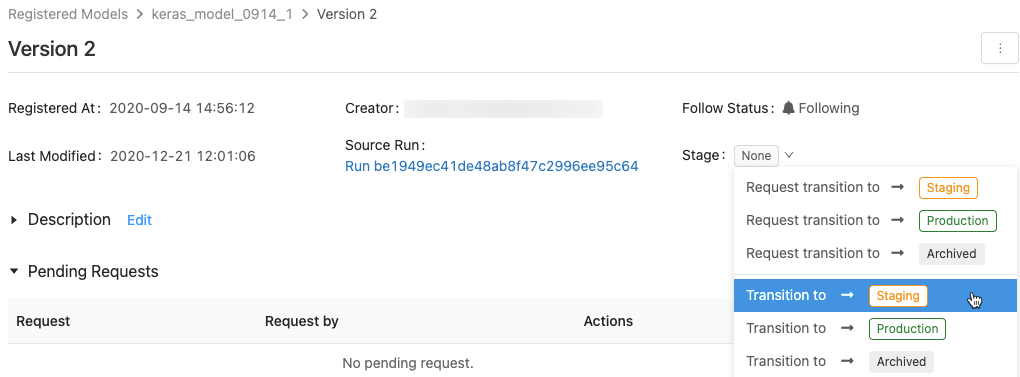
Opcjonalnie wprowadź komentarz i kliknij przycisk OK.
Przenoszenie wersji modelu do etapu produkcji
Po zakończeniu testowania i walidacji modelu możesz przenieść go lub zażądać przeniesienia do etapu produkcji.
Rejestr modeli obszaru roboczego zezwala na więcej niż jedną wersję zarejestrowanego modelu na każdym etapie. Jeśli chcesz, aby na etapie produkcji była tylko jedna wersja, możesz przenieść wszystkie wersje modelu znajdujące się obecnie na etapie produkcji do archiwum, zaznaczając pole wyboru Transition existing Production model versions to Archived (Przenieś istniejące produkcyjne wersje modelu do archiwum).
Zatwierdzanie, odrzucanie lub anulowanie żądania przeniesienia wersji modelu
Użytkownik bez uprawnień do przenoszenia modeli między etapami może zażądać takiego przeniesienia. Żądanie będzie widoczne w sekcji Pending Requests (Oczekujące żądania) na stronie wersji modelu:

Aby zatwierdzić, odrzucić lub anulować żądanie przeniesienia do innego etapu, kliknij link Approve (Zatwierdź), Reject (Odrzuć) lub Cancel (Anuluj).
Użytkownik, który utworzył żądanie, również może je anulować.
Wyświetlanie działań dotyczących wersji modelu
Aby wyświetlić wszystkie zmiany — zażądane, zatwierdzone, oczekujące i zastosowane do wersji modelu — przejdź do sekcji Activities (Działania). Rekord działań umożliwia śledzenie pochodzenia w cyklu życia modelu na potrzeby inspekcji.
Przenoszenie etapu modelu przy użyciu interfejsu API
Użytkownicy z odpowiednimi uprawnieniami mogą przenieść wersję modelu do nowego etapu.
Aby update etap wersji modelu do nowego etapu, użyj metody transition_model_version_stage() interfejsu API klienta MLflow:
client = MlflowClient()
client.transition_model_version_stage(
name="<model-name>",
version=<model-version>,
stage="<stage>",
description="<description>"
)
Zaakceptowane values dla <stage> to: "Staging"|"staging", "Archived"|"archived", "Production"|"production", "None"|"none".
Używanie modelu do wnioskowania
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
Po zarejestrowaniu modelu w rejestrze modeli obszaru roboczego można automatycznie generate notebooku, aby użyć modelu do wnioskowania wsadowego lub przesyłania strumieniowego. Alternatywnie możesz utworzyć punkt końcowy, aby użyć modelu do obsługi modeli w czasie rzeczywistym z obsługą modelu.
W prawym górnym rogu strony zarejestrowanego  modelu lub strony wersji modelu kliknij pozycję . Zostanie wyświetlone okno dialogowe Konfigurowanie wnioskowania modelu, które umożliwia skonfigurowanie wnioskowania wsadowego, przesyłania strumieniowego lub wnioskowania w czasie rzeczywistym.
modelu lub strony wersji modelu kliknij pozycję . Zostanie wyświetlone okno dialogowe Konfigurowanie wnioskowania modelu, które umożliwia skonfigurowanie wnioskowania wsadowego, przesyłania strumieniowego lub wnioskowania w czasie rzeczywistym.
Ważne
Anaconda Inc. zaktualizowała swoje warunki świadczenia usług dla kanałów anaconda.org. Na podstawie nowych warunków świadczenia usług możesz wymagać licencji komercyjnej, jeśli korzystasz z opakowania i dystrybucji anaconda. Aby uzyskać więcej informacji, zobacz Często zadawane pytania dotyczące wersji komercyjnej Anaconda. Korzystanie z jakichkolwiek kanałów Anaconda podlega warunkom świadczenia usług.
Modele MLflow zarejestrowane przed wersją 1.18 (Databricks Runtime 8.3 ML lub starsze) były domyślnie rejestrowane przy użyciu kanału Conda defaults (https://repo.anaconda.com/pkgs/) jako zależności. Ze względu na tę zmianę licencji usługa Databricks zatrzymała korzystanie z kanału defaults dla modeli zarejestrowanych przy użyciu platformy MLflow w wersji 1.18 lub nowszej. Zarejestrowany kanał domyślny to teraz conda-forge, co wskazuje na zarządzaną https://conda-forge.org/przez społeczność.
Jeśli zarejestrowano model przed MLflow w wersji 1.18 bez wykluczania defaults kanału ze środowiska conda dla modelu, ten model może mieć zależność od kanału defaults , którego być może nie zamierzasz.
Aby ręcznie potwierdzić, czy model ma tę zależność, możesz sprawdzić channel wartość w conda.yaml pliku spakowanym przy użyciu zarejestrowanego modelu. Na przykład model conda.yaml z zależnością kanału defaults może wyglądać następująco:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Ponieważ usługa Databricks nie może określić, czy korzystanie z repozytorium Anaconda do interakcji z modelami jest dozwolone w ramach relacji z platformą Anaconda, usługa Databricks nie zmusza swoich klientów do wprowadzania żadnych zmian. Jeśli korzystanie z repozytorium Anaconda.com za pośrednictwem korzystania z usługi Databricks jest dozwolone zgodnie z warunkami platformy Anaconda, nie musisz podejmować żadnych działań.
Jeśli chcesz zmienić kanał używany w środowisku modelu, możesz ponownie zarejestrować model w rejestrze modeli obszaru roboczego przy użyciu nowego conda.yamlelementu . Można to zrobić, określając kanał w parametrze conda_envlog_model().
Aby uzyskać więcej informacji na temat interfejsu log_model() API, zobacz dokumentację platformy MLflow dotyczącą odmiany modelu, z którą pracujesz, na przykład log_model dla biblioteki scikit-learn.
Aby uzyskać więcej informacji na conda.yaml temat plików, zobacz dokumentację platformy MLflow.
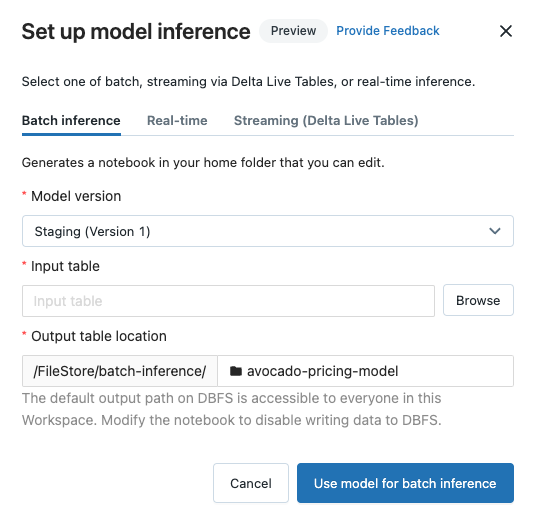
Konfigurowanie wnioskowania wsadowego
Podczas wykonywania tych kroków w celu utworzenia notesu wnioskowania wsadowego notes zostanie zapisany w folderze użytkownika w Batch-Inference folderze w folderze z nazwą modelu. Notes można edytować zgodnie z potrzebami.
Kliknij kartę Wnioskowanie wsadowe .
Z listy rozwijanej wersja modelu
wersji modelu do użycia. Pierwsze dwa elementy z listy rozwijanej to bieżąca wersja produkcyjna i tymczasowa modelu (jeśli istnieją). Gdy select jedną z tych opcji, notes automatycznie używa wersji produkcyjnej lub przejściowej od momentu jego uruchomienia. Nie musisz update notesu, gdy kontynuujesz opracowywanie modelu. Kliknij przycisk Przeglądaj obok pozycji Wprowadź table. Zostanie wyświetlone okno dialogowe danych wejściowych Select. W razie potrzeby możesz zmienić klaster na liście rozwijanej Obliczenia .
Uwaga
W przypadku obszarów roboczych z obsługą
aparatu Unity okno dialogowe danych wejściowych umożliwia z trzech poziomów, . Select table zawierające dane wejściowe dla modelu, a następnie kliknij przycisk Select. Wygenerowany notes automatycznie importuje te dane i wysyła je do modelu. Wygenerowany notes można edytować, jeśli dane wymagają jakichkolwiek przekształceń, zanim będą wprowadzane do modelu.
Przewidywania są zapisywane w folderze w katalogu
dbfs:/FileStore/batch-inference. Domyślnie przewidywania są zapisywane w folderze o takiej samej nazwie jak model. Każde uruchomienie wygenerowanego notesu zapisuje nowy plik do tego katalogu z znacznikiem czasu dołączonym do nazwy. Możesz również nie dołączać znacznika czasu i zastąpić plik kolejnymi przebiegami notesu; instrukcje są udostępniane w wygenerowanych notesach.Folder można zmienić where przewidywania są zapisywane, wpisując nową nazwę folderu w lokalizacji table lokalizacji lub klikając ikonę folderu, aby przejrzeć katalog i select inny folder.
Aby zapisać przewidywania w lokalizacji w środowisku Unity Catalog, należy edytować notes. Przykładowy notatnik pokazujący, jak trenować model uczenia maszynowego wykorzystujący dane w Unity Catalog i zapisywać wyniki z powrotem w Unity Catalog, znajdziesz w samouczku dotyczącym uczenia maszynowego.
Konfiguracja wnioskowania strumieniowego przy użyciu Delta Live Tables
Podczas wykonywania tych kroków w celu utworzenia notesu wnioskowania przesyłania strumieniowego notes zostanie zapisany w folderze użytkownika w DLT-Inference folderze w folderze o nazwie modelu. Notes można edytować zgodnie z potrzebami.
Kliknij kartę Streaming (Delta Live Tables).
Z listy rozwijanej wersja modelu
wersji modelu do użycia. Pierwsze dwa elementy z listy rozwijanej to bieżąca wersja produkcyjna i tymczasowa modelu (jeśli istnieją). Gdy select jedną z tych opcji, notes automatycznie używa wersji produkcyjnej lub przejściowej od momentu jego uruchomienia. Nie musisz update notesu podczas opracowywania modelu. Kliknij przycisk Przeglądaj obok pola Input table. Pojawia się okno dialogowe danych wejściowych Select. W razie potrzeby możesz zmienić klaster na liście rozwijanej Obliczenia .
Uwaga
W przypadku obszarów roboczych z włączoną obsługą Unity
okno dialogowe danych wejściowych pozwala na z trzech poziomów, . Select table zawierające dane wejściowe dla modelu, a następnie kliknij przycisk Select. Wygenerowany notes tworzy przekształcenie danych, które używa
wejściowych jako źródło i integruje funkcję UDF inferencji PySpark MLflow w celu wykonywania przewidywań modelu. Wygenerowany notes można edytować, jeśli dane wymagają dodatkowych przekształceń przed zastosowaniem modelu lub po nim. Podaj nazwę wyjściową Delta Live Table. Notatnik tworzy dynamiczne table o podanej nazwie i używa go do przechowywania przewidywań modelu. Wygenerowany notatnik można zmodyfikować, aby dostosować docelowy zestaw danych zgodnie z potrzebami, na przykład: zdefiniuj strumień table na żywo jako dane wyjściowe, dodaj informacje schema lub ograniczenia dotyczące jakości danych.
Następnie możesz utworzyć nowy potok usługi Delta Live Tables za pomocą tego notesu lub dodać go do istniejącego potoku jako dodatkową bibliotekę notesów.
Konfigurowanie wnioskowania w czasie rzeczywistym
Obsługa modelu uwidacznia modele uczenia maszynowego MLflow jako skalowalne punkty końcowe interfejsu API REST. Aby utworzyć punkt końcowy obsługujący model, zobacz Tworzenie niestandardowych punktów końcowych obsługujących model.
Przekazywanie opinii
Ta funkcja jest dostępna w wersji zapoznawczej i chcielibyśmy get Twoją opinię. Aby przekazać opinię, kliknij Provide Feedback okno dialogowe Konfigurowanie wnioskowania modelu.
Porównanie wersji modelu
Wersje modeli można porównać w rejestrze modeli obszaru roboczego.
- Na stronie zarejestrowanego modeluselect co najmniej dwie wersje modelu, klikając pole wyboru po lewej stronie wersji modelu.
- Kliknij pozycję Porównaj.
- Pojawi się ekran Porównania wersji
<N>, na którym table porównuje parameters, schemaoraz poszczególne metryki wybranych wersji modelu. W dolnej części ekranu można select typ wykresu (punktowy, konturowy lub równoległy) oraz wybrać parameters albo metryki do wykreślenia.
Kontrolowanie preferencji powiadomień
Rejestr modeli obszaru roboczego można skonfigurować, aby powiadomić Cię pocztą e-mail o działaniach dotyczących zarejestrowanych modeli i wersji modelu, które określisz.
Na zarejestrowanej stronie modelu w menu Powiadom mnie o wyświetlonych trzech opcjach:
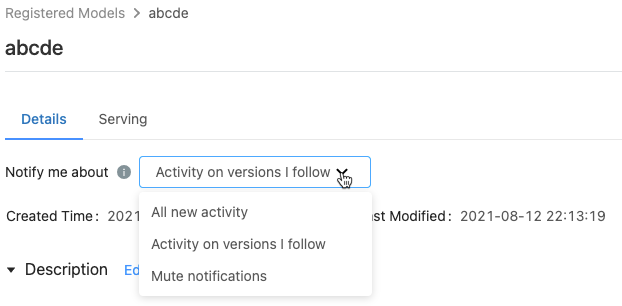
- Wszystkie nowe działanie: Wysyłaj powiadomienia e-mail dotyczące wszystkich działań we wszystkich wersjach modelu tego modelu. Jeśli utworzono zarejestrowany model, to ustawienie jest ustawieniem domyślnym.
- Aktywność w wersjach, które obserwuję: Wysyłaj powiadomienia e-mail tylko o obserwowanych wersjach modelu. Po wybraniu tej opcji otrzymasz powiadomienia dotyczące wszystkich obserwowanych wersji modelu; nie można wyłączyć powiadomień dla określonej wersji modelu.
- Powiadomienia wyciszenia: nie wysyłaj powiadomień e-mail dotyczących działań w tym zarejestrowanym modelu.
Następujące zdarzenia wyzwalają powiadomienie e-mail:
- Tworzenie nowej wersji modelu
- Żądanie przeniesienia etapu
- Przenoszenie etapu
- Nowe komentarze
Po wykonaniu dowolnej z następujących czynności automatycznie subskrybujesz powiadomienia dotyczące modelu:
- Komentarz do tej wersji modelu
- Przenoszenie etapu wersji modelu
- Tworzenie żądania przeniesienia dla etapu modelu
Aby sprawdzić, czy korzystasz z wersji modelu, zapoznaj się z polem Obserwuj stan na stronie wersji modelu lub na table wersji modelu na stronie zarejestrowanego modelu.
Wyłącz wszystkie powiadomienia e-mail
Powiadomienia e-mail można wyłączyć na karcie Ustawienia rejestru modelu obszaru roboczego w menu Ustawienia użytkownika:
- Kliknij swoją nazwę użytkownika w prawym górnym rogu obszaru roboczego usługi Azure Databricks, a selectUstawienia z menu rozwijanego.
- W pasku bocznym ustawień selectPowiadomienia.
- Wyłącz powiadomienia e-mail rejestru modeli.
Administrator konta może wyłączyć powiadomienia e-mail dla całej organizacji na stronie ustawień administratora.
Maksymalna liczba wysłanych wiadomości e-mail
Rejestr modeli obszarów roboczych ogranicza liczbę wiadomości e-mail wysyłanych do każdego użytkownika dziennie na działanie. Na przykład, jeśli otrzymasz 20 wiadomości e-mail w ciągu jednego dnia dotyczących nowych wersji modelu utworzonych dla zarejestrowanego modelu, Rejestr Modeli Workspace wyśle e-mail z informacją, że dzienny limit limit został osiągnięty i do następnego dnia nie zostaną wysłane żadne dodatkowe wiadomości e-mail dotyczące tego zdarzenia.
Aby zwiększyć limit liczby dozwolonych wiadomości e-mail, skontaktuj się z zespołem konta usługi Azure Databricks.
Elementy webhook
Ważne
Ta funkcja jest dostępna w publicznej wersji zapoznawczej.
Elementy webhook umożliwiają nasłuchiwanie zdarzeń rejestru modeli obszaru roboczego, dzięki czemu integracje mogą automatycznie wyzwalać akcje. Za pomocą elementów webhook można zautomatyzować i zintegrować potok uczenia maszynowego z istniejącymi narzędziami i przepływami pracy ciągłej integracji/ciągłego wdrażania. Możesz na przykład wyzwolić kompilacje ciągłej integracji po utworzeniu nowej wersji modelu lub powiadomić członków zespołu za pomocą usługi Slack za każdym razem, gdy wymagane jest przejście modelu do środowiska produkcyjnego.
Dodawanie adnotacji do modelu lub wersji modelu
Możesz przekazać informacje dotyczące modelu lub wersji modelu, dodając adnotację. Możesz na przykład dołączyć omówienie problemu lub informacje na temat używanych metodologii i algorytmów.
Dodawanie adnotacji do modelu lub wersji modelu przy użyciu interfejsu użytkownika
Interfejs użytkownika usługi Azure Databricks udostępnia kilka sposobów dodawania adnotacji do modeli i wersji modelu. Informacje tekstowe można dodawać przy użyciu opisu lub komentarzy, a także dodawać tagi klucz-wartość z możliwością wyszukiwania. Opisy i tagi są dostępne dla modeli i wersji modelu; komentarze są dostępne tylko dla wersji modelu.
- Opisy mają na celu podanie informacji o modelu.
- Komentarze umożliwiają utrzymanie ciągłej dyskusji na temat działań dotyczących wersji modelu.
- Tagi umożliwiają dostosowanie metadanych modelu, aby ułatwić znajdowanie określonych modeli.
Dodaj lub update opis dla modelu lub wersji modelu
Na stronie zarejestrowanego modelu lub wersji modelu kliknij przycisk Edytuj obok pozycji Opis. Pojawia się edycja window.
Dodaj lub edytuj opis w edycji window.
Kliknij przycisk Zapisz, aby zapisać zmiany lub Anuluj, aby zamknąć window.
Jeśli wprowadzono opis wersji modelu, będzie on wyświetlony w Opiscolumntable na stronie zarejestrowanego modelu . column wyświetla maksymalnie 32 znaki lub jeden wiersz tekstu, w zależności od tego, co jest krótsze.
Dodawanie komentarzy dla wersji modelu
- Przewiń w dół stronę wersji modelu i kliknij strzałkę w dół obok pozycji Działania.
- Wpisz komentarz w polu edycji window i kliknij pozycję Dodaj Komentarz.
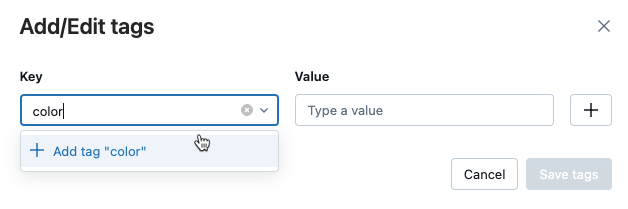
Dodawanie tagów dla wersji modelu lub modelu
Na stronie zarejestrowanego modelu lub wersji modelu kliknij
 , jeśli jeszcze nie jest otwarty. Pojawia się tag table.
, jeśli jeszcze nie jest otwarty. Pojawia się tag table.
Kliknij pola Nazwa i Wartość, a następnie wpisz klucz i wartość tagu.
Kliknij przycisk Dodaj.
Edytowanie lub usuwanie tagów dla modelu lub wersji modelu
Aby edytować lub usunąć istniejący tag, użyj ikon w Actionscolumn.

Dodawanie adnotacji do wersji modelu przy użyciu interfejsu API
Aby update opis wersji modelu, użyj metody update_model_version() interfejsu API klienta MLflow:
client = MlflowClient()
client.update_model_version(
name="<model-name>",
version=<model-version>,
description="<description>"
)
Aby set lub update tag dla zarejestrowanego modelu lub wersji modelu, użyj metody klienta API MLflow set_registered_model_tag()lub set_model_version_tag():
client = MlflowClient()
client.set_registered_model_tag()(
name="<model-name>",
key="<key-value>",
tag="<tag-value>"
)
client = MlflowClient()
client.set_model_version_tag()(
name="<model-name>",
version=<model-version>,
key="<key-value>",
tag="<tag-value>"
)
Zmienianie nazwy modelu (tylko interfejs API)
Aby zmienić nazwę zarejestrowanego modelu, użyj metody rename_registered_model() interfejsu API klienta platformy MLflow:
client=MlflowClient()
client.rename_registered_model("<model-name>", "<new-model-name>")
Uwaga
Nazwę zarejestrowanego modelu można zmienić tylko wówczas, gdy nie ma on żadnych wersji lub gdy wszystkie wersje mają przypisany etap None lub Archived.
Wyszukiwanie modelu
Modele można wyszukiwać w rejestrze modeli obszaru roboczego przy użyciu interfejsu użytkownika lub interfejsu API.
Uwaga
Podczas wyszukiwania modelu zwracane są tylko modele, dla których masz co najmniej uprawnienia CAN READ.
Wyszukiwanie modelu przy użyciu interfejsu użytkownika
Aby wyświetlić zarejestrowane modele, kliknij pozycję ![]() Modele na pasku bocznym.
Modele na pasku bocznym.
Aby wyszukać określony model, wprowadź tekst w polu wyszukiwania. Możesz wprowadzić nazwę modelu lub dowolną część nazwy:
Możesz również wyszukiwać tagi. Wprowadź tagi w tym formacie: tags.<key>=<value>. Aby wyszukać wiele tagów, użyj AND operatora .

Możesz wyszukać zarówno nazwę modelu, jak i tagi przy użyciu składni wyszukiwania MLflow. Na przykład:

Wyszukiwanie modelu przy użyciu interfejsu API
Zarejestrowane modele można wyszukać w rejestrze modeli obszaru roboczego przy użyciu metody interfejsu API klienta MLflow search_registered_models()
Jeśli masz set tagów w modelach, możesz również wyszukiwać je za pomocą search_registered_models().
print(f"Find registered models with a specific tag value")
for m in client.search_registered_models(f"tags.`<key-value>`='<tag-value>'"):
pprint(dict(m), indent=4)
Możesz również wyszukać określoną nazwę modelu oraz jego szczegóły wersji list przy użyciu metody search_model_versions() interfejsu API klienta MLflow.
from pprint import pprint
client=MlflowClient()
[pprint(mv) for mv in client.search_model_versions("name='<model-name>'")]
Zostaną zwrócone następujące dane wyjściowe:
{ 'creation_timestamp': 1582671933246,
'current_stage': 'Production',
'description': 'A random forest model containing 100 decision trees '
'trained in scikit-learn',
'last_updated_timestamp': 1582671960712,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'ae2cc01346de45f79a44a320aab1797b',
'source': './mlruns/0/ae2cc01346de45f79a44a320aab1797b/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 1 }
{ 'creation_timestamp': 1582671960628,
'current_stage': 'None',
'description': None,
'last_updated_timestamp': 1582671960628,
'name': 'sk-learn-random-forest-reg-model',
'run_id': 'd994f18d09c64c148e62a785052e6723',
'source': './mlruns/0/d994f18d09c64c148e62a785052e6723/artifacts/sklearn-model',
'status': 'READY',
'status_message': None,
'user_id': None,
'version': 2 }
Usuwanie modelu lub wersji modelu
Model można usunąć za pomocą interfejsu użytkownika lub interfejsu API.
Usuwanie modelu lub wersji modelu przy użyciu interfejsu użytkownika
Ostrzeżenie
Nie można cofnąć tej akcji. Zamiast usuwać wersję modelu z rejestru, możesz przenieść ją do etapu Archived. Po usunięciu modelu wszystkie artefakty modelu przechowywane przez rejestr modeli obszaru roboczego i wszystkie metadane skojarzone z zarejestrowanym modelem zostaną usunięte.
Uwaga
Można usuwać tylko modele i wersje modeli przypisane do etapu None lub Archived. Jeśli zarejestrowany model ma wersje na etapie Staging lub Production, przed usunięciem modelu trzeba przenieść je do etapu None lub Archived.
Aby usunąć wersję modelu:
- Kliknij pozycję Modele na pasku bocznym.
- Kliknij nazwę modelu.
- Kliknij wersję modelu.
- Kliknij menu kebab
 w prawym górnym rogu ekranu i selectUsuń z menu rozwijanego.
w prawym górnym rogu ekranu i selectUsuń z menu rozwijanego.
Aby usunąć model:
- Kliknij pozycję Modele na pasku bocznym.
- Kliknij nazwę modelu.
- Kliknij menu kebab w prawym górnym rogu ekranu i selectUsuń z menu rozwijanego.
Usuwanie modelu lub wersji modelu przy użyciu interfejsu API
Ostrzeżenie
Nie można cofnąć tej akcji. Zamiast usuwać wersję modelu z rejestru, możesz przenieść ją do etapu Archived. Po usunięciu modelu wszystkie artefakty modelu przechowywane przez rejestr modeli obszaru roboczego i wszystkie metadane skojarzone z zarejestrowanym modelem zostaną usunięte.
Uwaga
Można usuwać tylko modele i wersje modeli przypisane do etapu None lub Archived. Jeśli zarejestrowany model ma wersje na etapie Staging lub Production, przed usunięciem modelu trzeba przenieść je do etapu None lub Archived.
Usuwanie wersji modelu
Aby usunąć wersję modelu, użyj metody delete_model_version() interfejsu API klienta platformy MLflow:
# Delete versions 1,2, and 3 of the model
client = MlflowClient()
versions=[1, 2, 3]
for version in versions:
client.delete_model_version(name="<model-name>", version=version)
Usuń model
Aby usunąć model, użyj metody delete_registered_model() interfejsu API klienta platformy MLflow:
client = MlflowClient()
client.delete_registered_model(name="<model-name>")
Udostępnianie modeli między obszarami roboczymi
Usługa Databricks zaleca używanie modeli w środowisku Unity Catalog do udostępniania modeli między obszarami roboczymi. Usługa Unity Catalog zapewnia wbudowaną obsługę dostępu między obszarami roboczymi, zarządzania i rejestrowania logów audytowych.
Jeśli jednak korzystasz z rejestru modeli obszarów roboczych, możesz również udostępniać modele w wielu obszarach roboczych przy użyciu niektórych ustawień. Można na przykład opracowywać i rejestrować model we własnym obszarze roboczym, a następnie uzyskiwać do niego dostęp z innego obszaru roboczego przy użyciu zdalnego rejestru modeli obszaru roboczego. Jest to przydatne, gdy wiele zespołów współdzieli dostęp do modeli. Możesz utworzyć wiele obszarów roboczych i używać modeli w tych środowiskach i zarządzać nimi.
Kopiowanie obiektów MLflow między obszarami roboczymi
Aby zaimportować lub wyeksportować obiekty MLflow do lub z obszaru roboczego usługi Azure Databricks, możesz użyć opartego na społeczności projektu open source MLflow Export-Import w celu migracji eksperymentów, modeli i przebiegów między obszarami roboczymi.
Za pomocą tych narzędzi można wykonywać następujące czynności:
- Udostępnianie i współpraca z innymi analitykami danych na tym samym lub innym serwerze śledzenia. Na przykład możesz sklonować eksperyment z innego użytkownika do obszaru roboczego.
- Skopiuj model z jednego obszaru roboczego do innego, na przykład z obszaru projektowego do produkcyjnego obszaru roboczego.
- Skopiuj eksperymenty MLflow i uruchom je z lokalnego serwera śledzenia do obszaru roboczego usługi Databricks.
- Tworzenie kopii zapasowych eksperymentów i modeli o krytycznym znaczeniu dla innego obszaru roboczego usługi Databricks.
Przykład
W tym przykładzie pokazano, jak utworzyć aplikację uczenia maszynowego za pomocą rejestru modeli obszaru roboczego.