Uruchamianie punktów końcowych wsadowych z usługi Azure Data Factory
DOTYCZY: Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Rozszerzenie interfejsu wiersza polecenia platformy Azure w wersji 2 (current)Zestaw PYTHON SDK azure-ai-ml v2 (bieżąca)
Dane big data wymagają usługi, która umożliwia organizowanie i operacjonalizacja procesów w celu uściślenia tych ogromnych magazynów nieprzetworzonych danych do praktycznych analiz biznesowych. Zarządzana usługa w chmurze w usłudze Azure Data Factory obsługuje te złożone hybrydowe projekty integracji wyodrębniania-transformacji(ETL), wyodrębniania i przekształcania obciążenia (ELT) oraz projektów integracji danych.
Usługa Azure Data Factory umożliwia tworzenie potoków, które mogą organizować wiele przekształceń danych i zarządzać nimi jako pojedynczą jednostką. Punkty końcowe usługi Batch są doskonałym kandydatem do uzyskania kroku w takim przepływie pracy przetwarzania.
W tym artykule dowiesz się, jak używać punktów końcowych wsadowych w działaniach usługi Azure Data Factory, korzystając z działania Web Invoke i interfejsu API REST.
Napiwek
W przypadku korzystania z potoków danych w usłudze Fabric można wywołać punkt końcowy wsadowy bezpośrednio przy użyciu działania usługi Azure Machine Learning. Zalecamy używanie usługi Fabric do orkiestracji danych, jeśli jest to możliwe, aby korzystać z najnowszych funkcji. Działanie usługi Azure Machine Learning w usłudze Azure Data Factory może pracować tylko z elementami zawartości z usługi Azure Machine Learning w wersji 1. Aby uzyskać więcej informacji, zobacz Uruchamianie modeli usługi Azure Machine Learning z sieci szkieletowej przy użyciu punktów końcowych wsadowych (wersja zapoznawcza).
Wymagania wstępne
Model wdrożony jako punkt końcowy partii. Użyj klasyfikatora stanu serca utworzonego w temacie Używanie modeli MLflow we wdrożeniach wsadowych.
Zasób usługi Azure Data Factory. Aby utworzyć fabrykę danych, wykonaj kroki opisane w przewodniku Szybki start: tworzenie fabryki danych przy użyciu witryny Azure Portal.
Po utworzeniu fabryki danych przejdź do niej w witrynie Azure Portal i wybierz pozycję Uruchom studio:


Uwierzytelnianie względem punktów końcowych wsadowych
Usługa Azure Data Factory może wywoływać interfejsy API REST punktów końcowych wsadowych przy użyciu działania Web Invoke . Punkty końcowe usługi Batch obsługują identyfikator Entra firmy Microsoft na potrzeby autoryzacji, a żądanie skierowane do interfejsów API wymaga odpowiedniej obsługi uwierzytelniania. Aby uzyskać więcej informacji, zobacz Działania internetowe w usługach Azure Data Factory i Azure Synapse Analytics.
Do uwierzytelniania w punktach końcowych wsadowych można użyć jednostki usługi lub tożsamości zarządzanej. Zalecamy użycie tożsamości zarządzanej, ponieważ upraszcza korzystanie z wpisów tajnych.
Tożsamość zarządzana usługi Azure Data Factory umożliwia komunikowanie się z punktami końcowymi wsadowymi. W takim przypadku musisz tylko upewnić się, że zasób usługi Azure Data Factory został wdrożony przy użyciu tożsamości zarządzanej.
Jeśli nie masz zasobu usługi Azure Data Factory lub został on już wdrożony bez tożsamości zarządzanej, wykonaj tę procedurę, aby utworzyć ją: tożsamość zarządzana przypisana przez system.
Uwaga
Po wdrożeniu nie można zmienić tożsamości zasobu w usłudze Azure Data Factory. Jeśli musisz zmienić tożsamość zasobu po jego utworzeniu, musisz ponownie utworzyć zasób.
Po wdrożeniu przyznaj dostęp do tożsamości zarządzanej zasobu utworzonego w obszarze roboczym usługi Azure Machine Learning. Zobacz Udzielanie dostępu. W tym przykładzie jednostka usługi wymaga:
- Uprawnienie w obszarze roboczym do odczytywania wdrożeń wsadowych i wykonywania na nich akcji.
- Uprawnienia do odczytu/zapisu w magazynach danych.
- Uprawnienia do odczytu w dowolnej lokalizacji w chmurze (konto magazynu) wskazane jako dane wejściowe.
Informacje o potoku
W tym przykładzie utworzysz potok w usłudze Azure Data Factory, który może wywołać dany punkt końcowy wsadowy za pośrednictwem niektórych danych. Potok komunikuje się z punktami końcowymi wsadowymi usługi Azure Machine Learning przy użyciu interfejsu REST. Aby uzyskać więcej informacji na temat korzystania z interfejsu API REST punktów końcowych wsadowych, zobacz Tworzenie zadań i danych wejściowych dla punktów końcowych wsadowych.
Potok wygląda następująco:

Potok zawiera następujące działania:
Uruchom usługę Batch-Endpoint: działanie internetowe, które używa identyfikatora URI punktu końcowego wsadowego do wywoływania. Przekazuje identyfikator URI danych wejściowych, w którym znajdują się dane i oczekiwany plik wyjściowy.
Oczekiwanie na zadanie: jest to działanie pętli, które sprawdza stan utworzonego zadania i czeka na jego ukończenie, jako Ukończone lub Zakończone. To działanie z kolei używa następujących działań:
- Sprawdź stan: Działanie sieci Web, które wysyła zapytanie o stan zasobu zadania, który został zwrócony jako odpowiedź działania Uruchom punkt końcowy usługi Batch.
- Czekaj: Działanie oczekiwania, które kontroluje częstotliwość sondowania stanu zadania. Ustawiliśmy wartość domyślną 120 (2 minuty).
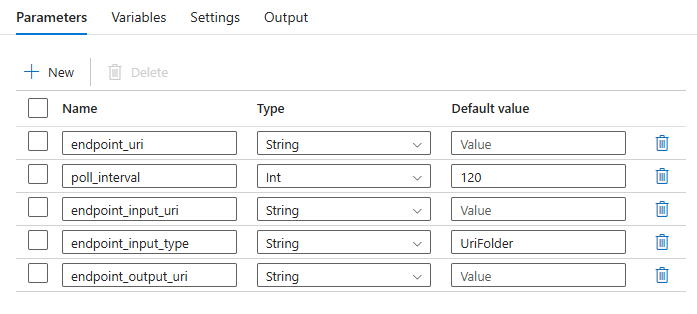
Potok wymaga skonfigurowania następujących parametrów:
| Parametr | Opis | Przykładowa wartość |
|---|---|---|
endpoint_uri |
Identyfikator URI oceniania punktu końcowego | https://<endpoint_name>.<region>.inference.ml.azure.com/jobs |
poll_interval |
Liczba sekund oczekiwania przed sprawdzeniem stanu zadania pod kątem ukończenia. Wartość domyślna to 120. |
120 |
endpoint_input_uri |
Dane wejściowe punktu końcowego. Obsługiwane są wiele typów danych wejściowych. Upewnij się, że tożsamość zarządzana używana do wykonywania zadania ma dostęp do lokalizacji bazowej. Alternatywnie, jeśli używasz magazynów danych, upewnij się, że poświadczenia są tam wskazane. | azureml://datastores/.../paths/.../data/ |
endpoint_input_type |
Typ danych wejściowych, które podajesz. Obecnie punkty końcowe wsadowe obsługują foldery (UriFolder) i plik (UriFile). Wartość domyślna to UriFolder. |
UriFolder |
endpoint_output_uri |
Wyjściowy plik danych punktu końcowego. Musi to być ścieżka do pliku wyjściowego w magazynie danych dołączonym do obszaru roboczego usługi Machine Learning. Nie jest obsługiwany żaden inny typ identyfikatorów URI. Możesz użyć domyślnego magazynu danych usługi Azure Machine Learning o nazwie workspaceblobstore. |
azureml://datastores/workspaceblobstore/paths/batch/predictions.csv |

Ostrzeżenie
Należy pamiętać, że endpoint_output_uri powinna to być ścieżka do pliku, który jeszcze nie istnieje. W przeciwnym razie zadanie kończy się niepowodzeniem z powodu błędu , który już istnieje.
Tworzenie potoku
Aby utworzyć ten potok w istniejącej usłudze Azure Data Factory i wywołać punkty końcowe wsadowe, wykonaj następujące kroki:
Upewnij się, że środowisko obliczeniowe, w którym działa punkt końcowy wsadowy, ma uprawnienia do instalowania danych w usłudze Azure Data Factory jako danych wejściowych. Jednostka, która wywołuje punkt końcowy, nadal udziela dostępu.
W tym przypadku jest to usługa Azure Data Factory. Jednak obliczenia, w których działa punkt końcowy wsadowy, muszą mieć uprawnienia do instalowania konta magazynu zapewniane przez usługę Azure Data Factory. Aby uzyskać szczegółowe informacje, zobacz Uzyskiwanie dostępu do usług magazynu.
Otwórz program Azure Data Factory Studio. Wybierz ikonę ołówka, aby otworzyć okienko Autor, a następnie w obszarze Zasoby fabryczne wybierz znak plus.
Wybierz pozycję Importuj potok>z szablonu potoku.
Wybierz plik .zip.
Podgląd potoku jest wyświetlany w portalu. Wybierz Użyj tego szablonu.
Potok zostanie utworzony za pomocą nazwy Run-BatchEndpoint.
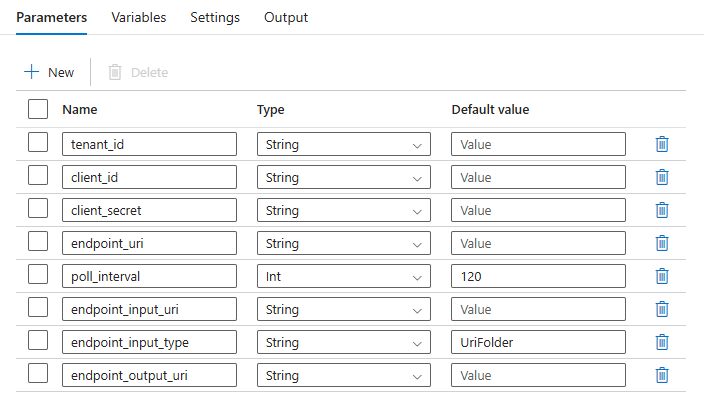
Skonfiguruj parametry wdrożenia wsadowego:
Ostrzeżenie
Upewnij się, że punkt końcowy usługi Batch ma domyślne wdrożenie skonfigurowane przed przesłaniem do niego zadania. Utworzony potok wywołuje punkt końcowy. Należy utworzyć i skonfigurować domyślne wdrożenie.
Napiwek
Aby uzyskać najlepszą możliwość ponownego użycia, użyj utworzonego potoku jako szablonu i wywołaj go z poziomu innych potoków usługi Azure Data Factory przy użyciu działania Wykonaj potok. W takim przypadku nie konfiguruj parametrów w potoku wewnętrznym, ale przekaż je jako parametry z zewnętrznego potoku, jak pokazano na poniższej ilustracji:
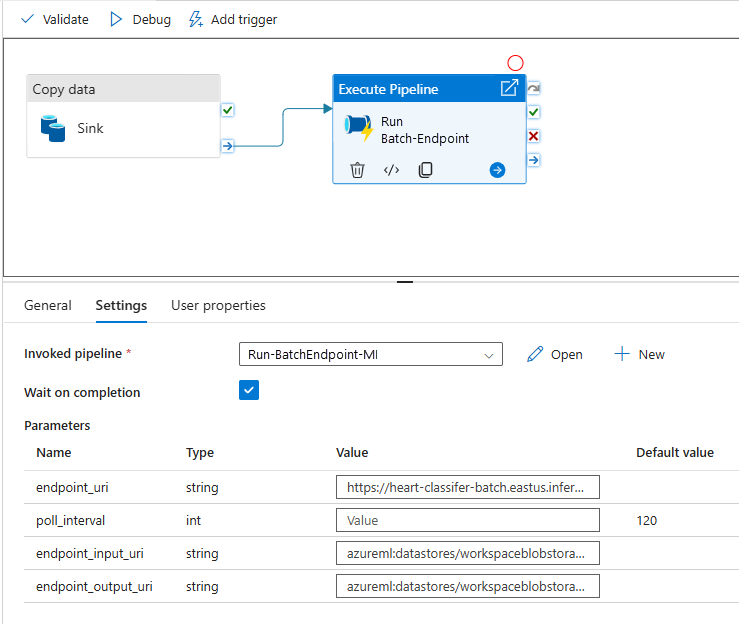
Potok jest gotowy do użycia.
Ograniczenia
W przypadku korzystania z wdrożeń wsadowych usługi Azure Machine Learning należy wziąć pod uwagę następujące ograniczenia:
Dane wejściowe danych
- Jako dane wejściowe są obsługiwane tylko magazyny danych usługi Azure Machine Learning lub konta usługi Azure Storage (Azure Blob Storage, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2). Jeśli dane wejściowe są w innym źródle, użyj usługi Azure Data Factory działanie Kopiuj przed wykonaniem zadania wsadowego w celu ujścia danych do zgodnego magazynu.
- Zadania punktu końcowego usługi Batch nie eksplorują zagnieżdżonych folderów. Nie mogą one działać z zagnieżdżonych struktur folderów. Jeśli dane są dystrybuowane w wielu folderach, należy spłaszczać strukturę.
- Upewnij się, że skrypt oceniania podany we wdrożeniu może obsługiwać dane zgodnie z oczekiwaniami, które mają być przekazywane do zadania. Jeśli model to MLflow, aby uzyskać ograniczenia dotyczące obsługiwanych typów plików, zobacz Wdrażanie modeli MLflow we wdrożeniach wsadowych.
Dane wyjściowe
- Obsługiwane są tylko zarejestrowane magazyny danych usługi Azure Machine Learning. Zalecamy zarejestrowanie konta magazynu używanego przez usługę Azure Data Factory jako magazynu danych w usłudze Azure Machine Learning. W ten sposób można zapisywać z powrotem na tym samym koncie magazynu, na którym czytasz.
- Tylko konta usługi Azure Blob Storage są obsługiwane w przypadku danych wyjściowych. Na przykład usługa Azure Data Lake Storage Gen2 nie jest obsługiwana jako dane wyjściowe w zadaniach wdrażania wsadowego. Jeśli musisz wyprowadzić dane do innej lokalizacji lub ujścia, użyj działanie Kopiuj usługi Azure Data Factory po uruchomieniu zadania wsadowego.