Interakcyjne rozmieszczanie danych za pomocą platformy Apache Spark w usłudze Azure Machine Learning
Uzdatnianie danych staje się jednym z najważniejszych aspektów projektów uczenia maszynowego. Integracja integracji usługi Azure Machine Learning z usługą Azure Synapse Analytics zapewnia dostęp do puli platformy Apache Spark — wspieranej przez usługę Azure Synapse — na potrzeby interakcyjnego uzdatniania danych korzystającego z notesów usługi Azure Machine Learning.
Z tego artykułu dowiesz się, jak obsługiwać uzdatnianie danych przy użyciu
- Bezserwerowe obliczenia platformy Spark
- Dołączona pula platformy Synapse Spark
Wymagania wstępne
- Subskrypcja platformy Azure; Jeśli nie masz subskrypcji platformy Azure, przed rozpoczęciem utwórz bezpłatne konto .
- Obszar roboczy usługi Azure Machine Learning. Aby uzyskać więcej informacji, odwiedź stronę Tworzenie zasobów obszaru roboczego.
- Konto magazynu usługi Azure Data Lake Storage (ADLS) Gen 2. Aby uzyskać więcej informacji, odwiedź stronę Tworzenie konta magazynu usługi Azure Data Lake Storage (ADLS) Gen 2. generacji.
- (Opcjonalnie): usługa Azure Key Vault. Aby uzyskać więcej informacji, odwiedź stronę Tworzenie usługi Azure Key Vault .
- (Opcjonalnie): jednostka usługi. Aby uzyskać więcej informacji, odwiedź stronę Tworzenie jednostki usługi.
- (Opcjonalnie): dołączona pula platformy Synapse Spark w obszarze roboczym usługi Azure Machine Learning.
Przed rozpoczęciem zadań uzdatniania danych dowiedz się więcej o procesie przechowywania wpisów tajnych
- Klucz dostępu do konta usługi Azure Blob Storage
- Token sygnatury dostępu współdzielonego (SAS)
- Informacje o jednostce usługi Azure Data Lake Storage (ADLS) Gen 2
w usłudze Azure Key Vault. Musisz również wiedzieć, jak obsługiwać przypisania ról na kontach usługi Azure Storage. W poniższych sekcjach w tym dokumencie opisano te pojęcia. Następnie poznamy szczegóły interakcyjnego uzdatniania danych przy użyciu pul platformy Spark w notesach usługi Azure Machine Learning.
Napiwek
Aby dowiedzieć się więcej o konfiguracji przypisywania ról konta usługi Azure Storage lub jeśli uzyskujesz dostęp do danych na kontach magazynu przy użyciu przekazywania tożsamości użytkownika, odwiedź stronę Dodawanie przypisań ról na kontach usługi Azure Storage, aby uzyskać więcej informacji.
Interakcyjne rozmieszczanie danych za pomocą platformy Apache Spark
W przypadku interakcyjnego uzdatniania danych za pomocą platformy Apache Spark w notesach usługi Azure Machine Learning usługa Azure Machine Learning oferuje bezserwerowe obliczenia spark i dołączoną pulę platformy Synapse Spark. Przetwarzanie bezserwerowe platformy Spark nie wymaga tworzenia zasobów w obszarze roboczym usługi Azure Synapse. Zamiast tego w pełni zarządzane bezserwerowe zasoby obliczeniowe platformy Spark stają się dostępne bezpośrednio w notesach usługi Azure Machine Learning. Korzystanie z bezserwerowych obliczeń platformy Spark jest najprostszym sposobem uzyskiwania dostępu do klastra Spark w usłudze Azure Machine Learning.
Bezserwerowe zasoby obliczeniowe platformy Spark w notesach usługi Azure Machine Learning
Bezserwerowe zasoby obliczeniowe platformy Spark są domyślnie dostępne w notesach usługi Azure Machine Learning. Aby uzyskać dostęp do niego w notesie, wybierz pozycję Bezserwerowe obliczenia Spark w obszarze Azure Machine Learning Serverless Spark z menu wyboru Obliczenia .
Interfejs użytkownika notesów udostępnia również opcje konfiguracji sesji platformy Spark dla bezserwerowych obliczeń platformy Spark. Aby skonfigurować sesję platformy Spark:
- Wybierz pozycję Konfiguruj sesję w górnej części ekranu.
- Wybierz pozycję Wersja platformy Apache Spark z menu rozwijanego.
Ważne
Środowisko uruchomieniowe usługi Azure Synapse dla platformy Apache Spark: anonsy
- Środowisko uruchomieniowe usługi Azure Synapse dla platformy Apache Spark 3.2:
- Data ogłoszenia EOLA: 8 lipca 2023 r.
- Data zakończenia wsparcia: 8 lipca 2024 r. Po tej dacie środowisko uruchomieniowe zostanie wyłączone.
- Apache Spark 3.3:
- Data ogłoszenia EOLA: 12 lipca 2024 r.
- Data zakończenia wsparcia technicznego: 31 marca 2025 r. Po tej dacie środowisko uruchomieniowe zostanie wyłączone.
- Aby zapewnić ciągłą obsługę i optymalną wydajność, zalecamy migrację do platformy Apache Spark 3.4
- Środowisko uruchomieniowe usługi Azure Synapse dla platformy Apache Spark 3.2:
- Wybierz pozycję Typ wystąpienia z menu rozwijanego. Te typy są obecnie obsługiwane:
Standard_E4s_v3Standard_E8s_v3Standard_E16s_v3Standard_E32s_v3Standard_E64s_v3
- Wprowadź wartość limitu czasu sesji platformy Spark w minutach.
- Wybierz, czy chcesz dynamicznie przydzielać funkcje wykonawcze
- Wybierz liczbę funkcji wykonawczych dla sesji platformy Spark.
- Wybierz pozycję Rozmiar funkcji wykonawczej z menu rozwijanego.
- Wybierz pozycję Rozmiar sterownika z menu rozwijanego.
- Aby skonfigurować sesję platformy Spark przy użyciu pliku Conda, zaznacz pole wyboru Przekaż plik conda. Następnie wybierz pozycję Przeglądaj i wybierz plik Conda z odpowiednią konfiguracją sesji platformy Spark.
- Dodaj właściwości ustawień konfiguracji, wartości wejściowe w polach tekstowych Właściwość i Wartość , a następnie wybierz pozycję Dodaj.
- Wybierz Zastosuj.
- W oknie podręcznym Konfiguruj nową sesję? wybierz pozycję Zatrzymaj sesję.
Zmiany konfiguracji sesji są utrwalane i stają się dostępne dla innej sesji notesu, która została uruchomiona przy użyciu bezserwerowych obliczeń platformy Spark.
Napiwek
Jeśli używasz pakietów Conda na poziomie sesji, możesz poprawić czas zimnego rozpoczęcia sesji platformy Spark, jeśli ustawisz zmienną spark.hadoop.aml.enable_cache konfiguracji na true. Zimny początek sesji z pakietami Conda na poziomie sesji zwykle trwa od 10 do 15 minut, gdy sesja rozpoczyna się po raz pierwszy. Jednak kolejne zimne rozpoczęcie sesji ze zmienną konfiguracji ustawioną na wartość true zwykle trwa od trzech do pięciu minut.
Importowanie i rozmieszczanie danych z usługi Azure Data Lake Storage (ADLS) Gen 2
Dostęp do danych przechowywanych na kontach magazynu usługi Azure Data Lake Storage (ADLS) Gen 2 można uzyskiwać i rozmieszczać przy użyciu abfss:// identyfikatorów URI danych. W tym celu należy postępować zgodnie z jednym z dwóch mechanizmów dostępu do danych:
- Przekazywanie tożsamości użytkownika
- Dostęp do danych opartych na jednostce usługi
Napiwek
Przetwarzanie danych za pomocą bezserwerowego przetwarzania platformy Spark i przekazywanie tożsamości użytkownika w celu uzyskania dostępu do danych na koncie magazynu usługi Azure Data Lake Storage (ADLS) Gen 2 wymaga najmniejszej liczby kroków konfiguracji.
Aby rozpocząć interakcyjne uzdatnianie danych za pomocą przekazywania tożsamości użytkownika:
Sprawdź, czy tożsamość użytkownika ma przypisanie roli Współautor i Współautor danych obiektu blob usługi Storage na koncie magazynu usługi Azure Data Lake Storage (ADLS) Gen 2.
Aby użyć bezserwerowych obliczeń platformy Spark, wybierz pozycję Bezserwerowe obliczenia platformy Spark w obszarze Bezserwerowa platforma Spark w obszarze Azure Machine Learning Serverless Spark z menu wyboru Obliczenia .
Aby użyć dołączonej puli platformy Synapse Spark, wybierz dołączoną pulę platformy Synapse Spark w obszarze Pule platformy Synapse Spark z menu wyboru Obliczenia .
Ten przykładowy kod uzdatniania danych Titanic pokazuje użycie identyfikatora URI danych w formacie
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>ipyspark.pandaspyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/data/wrangled", index_col="PassengerId", )Uwaga
Ten przykładowy kod w języku Python używa metody
pyspark.pandas. Obsługuje to tylko środowisko uruchomieniowe platformy Spark w wersji 3.2 lub nowszej.
Aby wrangle danych przez dostęp za pośrednictwem jednostki usługi:
Sprawdź, czy jednostka usługi ma przypisanie roli Współautor i Współautor danych obiektu blob usługi Storage na koncie magazynu usługi Azure Data Lake Storage (ADLS) Gen 2.
Utwórz wpisy tajne usługi Azure Key Vault dla identyfikatora dzierżawy jednostki usługi, identyfikatora klienta i wartości wpisów tajnych klienta.
W menu wyboru Obliczenia wybierz pozycję Przetwarzanie bezserwerowe Spark w obszarze Azure Machine Learning Serverless Spark. Możesz również wybrać dołączoną pulę platformy Synapse Spark w obszarze Pule platformy Synapse Spark z menu wyboru Obliczenia .
Ustaw identyfikator dzierżawy jednostki usługi, identyfikator klienta i wartości wpisów tajnych klienta w konfiguracji i wykonaj poniższy przykładowy kod.
Wywołanie
get_secret()w kodzie zależy od nazwy usługi Azure Key Vault oraz nazw wpisów tajnych usługi Azure Key Vault utworzonych dla identyfikatora dzierżawy jednostki usługi, identyfikatora klienta i klucza tajnego klienta. Ustaw odpowiednią nazwę/wartości właściwości w konfiguracji:- Właściwość Identyfikator klienta:
fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Właściwość wpisu tajnego klienta:
fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Właściwość identyfikatora dzierżawy:
fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net - Wartość identyfikatora dzierżawy:
https://login.microsoftonline.com/<TENANT_ID>/oauth2/token
from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary # Set up service principal tenant ID, client ID and secret from Azure Key Vault client_id = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_ID_SECRET_NAME>") tenant_id = token_library.getSecret("<KEY_VAULT_NAME>", "<TENANT_ID_SECRET_NAME>") client_secret = token_library.getSecret("<KEY_VAULT_NAME>", "<CLIENT_SECRET_NAME>") # Set up service principal which has access of the data sc._jsc.hadoopConfiguration().set( "fs.azure.account.auth.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "OAuth" ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth.provider.type.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider", ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.id.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_id, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.secret.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", client_secret, ) sc._jsc.hadoopConfiguration().set( "fs.azure.account.oauth2.client.endpoint.<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net", "https://login.microsoftonline.com/" + tenant_id + "/oauth2/token", )- Właściwość Identyfikator klienta:
Za pomocą danych Titanic zaimportuj i wrangle dane przy użyciu identyfikatora URI danych w
abfss://<FILE_SYSTEM_NAME>@<STORAGE_ACCOUNT_NAME>.dfs.core.windows.net/<PATH_TO_DATA>formacie, jak pokazano w przykładzie kodu.
Importowanie i rozmieszczanie danych z usługi Azure Blob Storage
Dostęp do danych usługi Azure Blob Storage można uzyskać przy użyciu klucza dostępu konta magazynu lub tokenu sygnatury dostępu współdzielonego (SAS). Te poświadczenia należy przechowywać w usłudze Azure Key Vault jako wpis tajny i ustawiać je jako właściwości w konfiguracji sesji.
Aby rozpocząć interakcyjne uzdatnianie danych:
W lewym panelu usługi Azure Machine Learning Studio wybierz pozycję Notesy.
W menu wyboru Obliczenia wybierz pozycję Przetwarzanie bezserwerowe Spark w obszarze Azure Machine Learning Serverless Spark. Możesz również wybrać dołączoną pulę platformy Synapse Spark w obszarze Pule platformy Synapse Spark z menu wyboru Obliczenia .
Aby skonfigurować klucz dostępu do konta magazynu lub token sygnatury dostępu współdzielonego (SAS) na potrzeby dostępu do danych w notesach usługi Azure Machine Learning:
Dla klucza dostępu ustaw
fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netwłaściwość , jak pokazano w tym fragmencie kodu:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary access_key = token_library.getSecret("<KEY_VAULT_NAME>", "<ACCESS_KEY_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.account.key.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", access_key )Dla tokenu
fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.netSAS ustaw właściwość, jak pokazano w tym fragmencie kodu:from pyspark.sql import SparkSession sc = SparkSession.builder.getOrCreate() token_library = sc._jvm.com.microsoft.azure.synapse.tokenlibrary.TokenLibrary sas_token = token_library.getSecret("<KEY_VAULT_NAME>", "<SAS_TOKEN_SECRET_NAME>") sc._jsc.hadoopConfiguration().set( "fs.azure.sas.<BLOB_CONTAINER_NAME>.<STORAGE_ACCOUNT_NAME>.blob.core.windows.net", sas_token, )Uwaga
Wywołania
get_secret()we wcześniejszych fragmentach kodu wymagają nazwy usługi Azure Key Vault oraz nazw wpisów tajnych utworzonych dla klucza dostępu konta usługi Azure Blob Storage lub tokenu SAS.
Wykonaj kod uzdatniania danych w tym samym notesie. Sformatuj identyfikator URI danych jako
wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/<PATH_TO_DATA>, podobnie jak pokazano w tym fragmencie kodu:import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "wasbs://<BLOB_CONTAINER_NAME>@<STORAGE_ACCOUNT_NAME>.blob.core.windows.net/data/wrangled", index_col="PassengerId", )Uwaga
Ten przykładowy kod w języku Python używa metody
pyspark.pandas. Obsługuje to tylko środowisko uruchomieniowe platformy Spark w wersji 3.2 lub nowszej.
Importowanie i rozmieszczanie danych z magazynu danych usługi Azure Machine Learning
Aby uzyskać dostęp do danych z magazynu danych usługi Azure Machine Learning, zdefiniuj ścieżkę do danych w magazynie danych przy użyciu formatu azureml://datastores/<DATASTORE_NAME>/paths/<PATH_TO_DATA>URI . Aby interaktywnie rozmieścić dane z magazynu danych usługi Azure Machine Learning w sesji notesów:
Wybierz pozycję Bezserwerowe zasoby obliczeniowe platformy Spark w obszarze Bezserwerowa platforma Spark w usłudze Azure Machine Learning z menu wyboru Obliczenia lub wybierz dołączoną pulę platformy Synapse Spark w obszarze Pule platformy Synapse Spark z menu wyboru Obliczenia .
W tym przykładzie kodu pokazano, jak odczytywać i wrangle danych Titanic z magazynu danych usługi Azure Machine Learning przy użyciu
azureml://identyfikatora URI magazynu danych,pyspark.pandasipyspark.ml.feature.Imputer.import pyspark.pandas as pd from pyspark.ml.feature import Imputer df = pd.read_csv( "azureml://datastores/workspaceblobstore/paths/data/titanic.csv", index_col="PassengerId", ) imputer = Imputer(inputCols=["Age"], outputCol="Age").setStrategy( "mean" ) # Replace missing values in Age column with the mean value df.fillna( value={"Cabin": "None"}, inplace=True ) # Fill Cabin column with value "None" if missing df.dropna(inplace=True) # Drop the rows which still have any missing value df.to_csv( "azureml://datastores/workspaceblobstore/paths/data/wrangled", index_col="PassengerId", )Uwaga
Ten przykładowy kod w języku Python używa metody
pyspark.pandas. Obsługuje to tylko środowisko uruchomieniowe platformy Spark w wersji 3.2 lub nowszej.
Magazyny danych usługi Azure Machine Learning mogą uzyskiwać dostęp do danych przy użyciu poświadczeń konta usługi Azure Storage
- klucz dostępu
- Token SAS
- jednostka usługi
lub używają dostępu do danych bez poświadczeń. W zależności od typu magazynu danych i bazowego typu konta usługi Azure Storage wybierz odpowiedni mechanizm uwierzytelniania, aby zapewnić dostęp do danych. Ta tabela zawiera podsumowanie mechanizmów uwierzytelniania w celu uzyskania dostępu do danych w magazynach danych usługi Azure Machine Learning:
| Storage account type | Dostęp do danych bez poświadczeń | Mechanizm dostępu do danych | Przypisania ról |
|---|---|---|---|
| Azure Blob | Nie. | Klucz dostępu lub token SAS | Brak wymaganych przypisań ról |
| Azure Blob | Tak | Przekazywanie tożsamości użytkownika* | Tożsamość użytkownika powinna mieć odpowiednie przypisania ról na koncie usługi Azure Blob Storage |
| Azure Data Lake Storage (ADLS) Gen 2 | Nie. | Jednostka usługi | Jednostka usługi powinna mieć odpowiednie przypisania ról na koncie magazynu usługi Azure Data Lake Storage (ADLS) Gen 2 |
| Azure Data Lake Storage (ADLS) Gen 2 | Tak | Przekazywanie tożsamości użytkownika | Tożsamość użytkownika powinna mieć odpowiednie przypisania ról na koncie magazynu usługi Azure Data Lake Storage (ADLS) Gen 2 |
* Przekazywanie tożsamości użytkownika działa w przypadku magazynów danych bez poświadczeń wskazujących konta usługi Azure Blob Storage tylko wtedy, gdy nie włączono usuwania nietrwałego.
Uzyskiwanie dostępu do danych w domyślnym udziale plików
Domyślny udział plików jest instalowany zarówno do bezserwerowych obliczeń platformy Spark, jak i dołączonych pul platformy Synapse Spark.
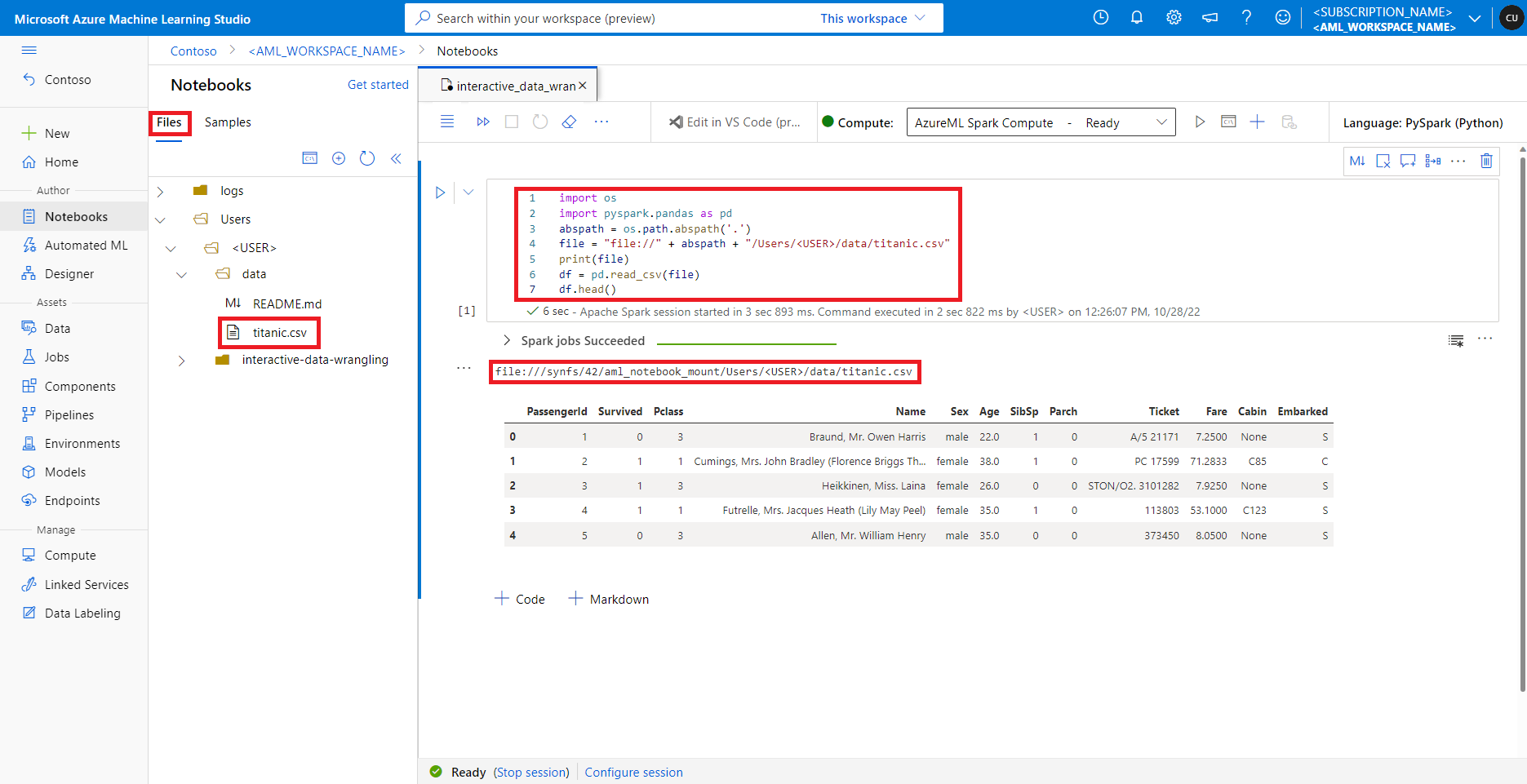
W usłudze Azure Machine Learning Studio pliki w domyślnym udziale plików są wyświetlane w drzewie katalogów na karcie Pliki . Kod notesu może uzyskiwać bezpośredni dostęp do plików przechowywanych w tym udziale plików wraz ze ścieżką file:// bezwzględną pliku bez większej liczby konfiguracji. Ten fragment kodu pokazuje, jak uzyskać dostęp do pliku przechowywanego w domyślnym udziale plików:
import os
import pyspark.pandas as pd
from pyspark.ml.feature import Imputer
abspath = os.path.abspath(".")
file = "file://" + abspath + "/Users/<USER>/data/titanic.csv"
print(file)
df = pd.read_csv(file, index_col="PassengerId")
imputer = Imputer(
inputCols=["Age"],
outputCol="Age").setStrategy("mean") # Replace missing values in Age column with the mean value
df.fillna(value={"Cabin" : "None"}, inplace=True) # Fill Cabin column with value "None" if missing
df.dropna(inplace=True) # Drop the rows which still have any missing value
output_path = "file://" + abspath + "/Users/<USER>/data/wrangled"
df.to_csv(output_path, index_col="PassengerId")
Uwaga
Ten przykładowy kod w języku Python używa metody pyspark.pandas. Obsługuje to tylko środowisko uruchomieniowe platformy Spark w wersji 3.2 lub nowszej.
Następne kroki
- Przykłady kodu dla interakcyjnego uzdatniania danych za pomocą platformy Apache Spark w usłudze Azure Machine Learning
- Optymalizowanie zadań platformy Apache Spark w usłudze Azure Synapse Analytics
- Co to są potoki usługi Azure Machine Learning?
- Przesyłanie zadań platformy Spark w usłudze Azure Machine Learning