Kształtowanie wyników wyszukiwania lub modyfikowanie kompozycji wyników wyszukiwania w usłudze Azure AI Search
W tym artykule opisano kompozycję wyników wyszukiwania i sposób kształtowania wyników wyszukiwania w celu dopasowania ich do scenariuszy. Wyniki wyszukiwania są zwracane w odpowiedzi zapytania. Kształt odpowiedzi jest określany przez parametry w samym zapytaniu. Te parametry obejmują:
- Liczba dopasowań znalezionych w indeksie (
count) - Liczba dopasowań zwracanych w odpowiedzi (domyślnie 50, konfigurowalnych za pomocą
topelementu ) lub na stronę (skipitop) - Wynik wyszukiwania dla każdego wyniku, używany do klasyfikowania (
@search.score) - Pola uwzględnione w wynikach wyszukiwania (
select) - Logika sortowania (
orderby) - Wyróżnianie terminów w wyniku, dopasowywanie całego lub częściowego terminu w treści
- Opcjonalne elementy z semantycznego rankera (
answersu górycaptionsdla każdego dopasowania)
Wyniki wyszukiwania mogą zawierać pola najwyższego poziomu, ale większość odpowiedzi składa się z pasujących dokumentów w tablicy.
Klienci i interfejsy API służące do definiowania odpowiedzi na zapytanie
Aby skonfigurować odpowiedź na zapytanie, możesz użyć następujących klientów:
- Eksplorator wyszukiwania w witrynie Azure Portal przy użyciu widoku JSON, dzięki czemu można określić dowolny obsługiwany parametr
- Dokumenty — POST (interfejsy API REST)
- SearchClient.Search, metoda (Zestaw Azure SDK dla platformy .NET)
- SearchClient.Search, metoda (Zestaw Azure SDK dla języka Python)
- SearchClient.Search, metoda (Azure for JavaScript)
- SearchClient.Search, metoda (Azure for Java)
Kompozycja wyników
Wyniki są głównie tabelaryczne, składające się z pól wszystkich retrievable pól lub ograniczone tylko do tych pól określonych w parametrze select . Wiersze to pasujące dokumenty, zazwyczaj uporządkowane według istotności, chyba że logika zapytania wyklucza klasyfikację istotności.
Możesz wybrać pola w wynikach wyszukiwania. Chociaż dokument wyszukiwania może zawierać dużą liczbę pól, zazwyczaj tylko kilka z nich jest potrzebnych do reprezentowania każdego dokumentu w wynikach. W żądaniu zapytania dołącz, select=<field list> aby określić, które retrievable pola powinny być wyświetlane w odpowiedzi.
Wybierz pola, które oferują kontrast i różnice między dokumentami, zapewniając wystarczające informacje, aby zaprosić odpowiedź na kliknięcie w części użytkownika. W witrynie handlu elektronicznego może to być nazwa produktu, opis, marka, kolor, rozmiar, cena i ocena. W przypadku wbudowanego indeksu hotels-sample może to być pola "select" w poniższym przykładzie:
POST /indexes/hotels-sample-index/docs/search?api-version=2024-07-01
{
"search": "sandy beaches",
"select": "HotelId, HotelName, Description, Rating, Address/City",
"count": true
}
Porady dotyczące nieoczekiwanych wyników
Czasami dane wyjściowe zapytania nie są tym, czego oczekujesz. Na przykład może się okazać, że niektóre wyniki wydają się być duplikatami lub wynik, który powinien pojawić się w górnej części, znajduje się w dolnej części wyników. Gdy wyniki zapytania są nieoczekiwane, możesz wypróbować te modyfikacje zapytań, aby sprawdzić, czy wyniki się poprawią:
Zmień
searchMode=anywartość (domyślną), abysearchMode=allwymagać dopasowania we wszystkich kryteriach zamiast kryteriów. Jest to szczególnie istotne, gdy operatory logiczne są uwzględniane w zapytaniu.Poeksperymentuj z różnymi analizatorami leksykalnymi lub analizatorami niestandardowymi, aby sprawdzić, czy zmienia wynik zapytania. Analizator domyślny dzieli wyrazy na wyrazy i zmniejsza liczbę wyrazów do formularzy głównych, co zwykle poprawia niezawodność odpowiedzi zapytania. Jeśli jednak musisz zachować łączniki lub jeśli ciągi zawierają znaki specjalne, może być konieczne skonfigurowanie analizatorów niestandardowych w celu upewnienia się, że indeks zawiera tokeny w odpowiednim formacie. Aby uzyskać więcej informacji, zobacz Wyszukiwanie częściowe terminy i wzorce ze znakami specjalnymi (łączniki, symbol wieloznaczny, regex, wzorce).
Zliczanie dopasowań
Parametr count zwraca liczbę dokumentów w indeksie, które są uważane za dopasowanie zapytania. Aby zwrócić liczbę, dodaj count=true do żądania zapytania. Nie ma maksymalnej wartości nałożonej przez usługę wyszukiwania. W zależności od zapytania i zawartości dokumentów liczba może być tak wysoka, jak każdy dokument w indeksie.
Liczba jest dokładna, gdy indeks jest stabilny. Jeśli system aktywnie dodawa, aktualizuje lub usuwa dokumenty, liczba jest przybliżona, z wyłączeniem wszystkich dokumentów, które nie są w pełni indeksowane.
Liczba nie będzie miała wpływu na rutynową konserwację ani inne obciążenia w usłudze wyszukiwania. Jeśli jednak masz wiele partycji i jedną replikę, możesz doświadczyć krótkoterminowych wahań liczby dokumentów (kilka minut) podczas ponownego uruchamiania partycji.
Napiwek
Aby sprawdzić operacje indeksowania, możesz potwierdzić, czy indeks zawiera oczekiwaną liczbę dokumentów, dodając puste count=true zapytanie wyszukiwania search=* . Wynikiem jest pełna liczba dokumentów w indeksie.
Podczas testowania składni zapytania można szybko określić, count=true czy modyfikacje zwracają większe lub mniejsze wyniki, co może być przydatne.
Liczba wyników w odpowiedzi
Usługa Azure AI Search używa stronicowania po stronie serwera, aby zapobiec pobieraniu zbyt wielu dokumentów jednocześnie przez zapytania. Parametry zapytania określające liczbę wyników w odpowiedzi to top i skip. top odwołuje się do liczby wyników wyszukiwania na stronie. skip jest interwałem top, i informuje wyszukiwarkę, ile wyników należy pominąć przed uzyskaniem następnego zestawu.
Domyślny rozmiar strony to 50, a maksymalny rozmiar strony to 1000. Jeśli określisz wartość większą niż 1000 i istnieje więcej niż 1000 wyników znalezionych w indeksie, zwracane są tylko pierwsze 1000 wyników. Jeśli liczba dopasowań przekracza rozmiar strony, odpowiedź zawiera informacje dotyczące pobierania następnej strony wyników. Na przykład:
"@odata.nextLink": "https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01"
Najlepsze dopasowania są określane przez wynik wyszukiwania, przy założeniu, że zapytanie jest wyszukiwaniem pełnotekstowym lub semantycznym. W przeciwnym razie najważniejsze dopasowania są dowolną kolejnością dla dokładnie dopasowanych zapytań (gdzie uniform @search.score=1.0 wskazuje dowolną klasyfikację).
Ustaw top wartość , aby zastąpić wartość domyślną 50. W nowszych interfejsach API w wersji zapoznawczej, jeśli używasz zapytania hybrydowego, możesz określić wartość maxTextRecallSize , aby zwrócić maksymalnie 10 000 dokumentów.
Aby kontrolować stronicowanie wszystkich dokumentów zwróconych w zestawie wyników, użyj polecenia top i skip razem. To zapytanie zwraca pierwszy zestaw 15 pasujących dokumentów oraz liczbę dopasowań łącznej liczby dopasowań.
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 0
}
To zapytanie zwraca drugi zestaw, pomijając pierwsze 15, aby uzyskać następne 15 (od 16 do 30):
POST https://contoso-search-eastus.search.windows.net/indexes/realestate-us-sample-index/docs/search?api-version=2024-07-01
{
"search": "condos with a view",
"count": true,
"top": 15,
"skip": 15
}
Wyniki zapytań podzielonych na strony nie są gwarantowane stabilnie, jeśli indeks bazowy się zmienia. Stronicowanie zmienia wartość skip dla każdej strony, ale każde zapytanie jest niezależne i działa w bieżącym widoku danych, ponieważ istnieje w indeksie w czasie zapytania (innymi słowy, nie ma buforowania ani migawki wyników, takich jak te znajdujące się w bazie danych ogólnego przeznaczenia).
Poniżej przedstawiono przykład sposobu pobierania duplikatów. Załóżmy indeks z czterema dokumentami:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
{ "id": "4", "rating": 1 }
Teraz załóżmy, że wyniki są zwracane dwa naraz, uporządkowane według klasyfikacji. Wykonasz to zapytanie, aby uzyskać pierwszą stronę wyników: $top=2&$skip=0&$orderby=rating desc, generując następujące wyniki:
{ "id": "1", "rating": 5 }
{ "id": "2", "rating": 3 }
W usłudze załóżmy, że piąty dokument jest dodawany do indeksu między wywołaniami zapytania: { "id": "5", "rating": 4 }. Wkrótce potem wykonasz zapytanie, aby pobrać drugą stronę: $top=2&$skip=2&$orderby=rating desci uzyskać następujące wyniki:
{ "id": "2", "rating": 3 }
{ "id": "3", "rating": 2 }
Zwróć uwagę, że dokument 2 jest pobierany dwa razy. Jest to spowodowane tym, że nowy dokument 5 ma większą wartość klasyfikacji, więc sortuje przed dokumentem 2 i ląduje na pierwszej stronie. Chociaż to zachowanie może być nieoczekiwane, typowe jest zachowanie wyszukiwarki.
Stronicowanie dużej liczby wyników
Alternatywną techniką stronicowania jest użycie kolejności sortowania i filtru zakresu jako obejścia problemu.skip
W tym obejście sortowanie i filtrowanie są stosowane do pola identyfikatora dokumentu lub innego pola, które jest unikatowe dla każdego dokumentu. Unikatowe pole musi zawierać filterable atrybuty i sortable atrybuty w indeksie wyszukiwania.
Wyślij zapytanie, aby zwrócić pełną stronę posortowanych wyników.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc" }Wybierz ostatni wynik zwrócony przez zapytanie wyszukiwania. Przykładowy wynik zawierający tylko wartość identyfikatora jest pokazany tutaj.
{ "id": "50" }Użyj tej wartości identyfikatora w zapytaniu zakresu, aby pobrać następną stronę wyników. To pole identyfikatora powinno mieć unikatowe wartości. W przeciwnym razie stronicowanie może zawierać zduplikowane wyniki.
POST /indexes/good-books/docs/search?api-version=2024-07-01 { "search": "divine secrets", "top": 50, "orderby": "id asc", "filter": "id ge 50" }Stronicowanie kończy się, gdy zapytanie zwraca zero wyników.
Uwaga
filterable Atrybuty i sortable można włączyć tylko wtedy, gdy pole jest najpierw dodawane do indeksu, nie można ich włączyć w istniejącym polu.
Porządkowanie wyników
W kwerendzie wyszukiwania pełnotekstowego wyniki można sklasyfikować według:
- wynik wyszukiwania
- semantyczny wynik reranker
- kolejność sortowania
sortablew polu
Możesz również zwiększyć wszystkie dopasowania znalezione w określonych polach, dodając profil oceniania.
Kolejność według wyniku wyszukiwania
W przypadku zapytań wyszukiwania pełnotekstowego wyniki są automatycznie klasyfikowane przez wynik wyszukiwania przy użyciu algorytmu BM25, obliczanego na podstawie częstotliwości terminów, długości dokumentu i średniej długości dokumentu.
Zakres @search.score jest niezwiązany lub od 0 do (ale nie obejmuje) 1,00 w starszych usługach.
W przypadku dowolnego algorytmu @search.score wartość równa 1,00 wskazuje nieznakowany lub niesklasowany zestaw wyników, w którym wynik 1,0 jest jednolity we wszystkich wynikach. Wyniki bez podkreślenia występują, gdy formularz zapytania jest wyszukiwaniem rozmytym, symbolem wieloznacznymi lub kwerendami regularnymi lub pustym wyszukiwaniem (search=*). Jeśli musisz narzucić strukturę klasyfikacji dla wyników bez podkreślenia, rozważ orderby wyrażenie, aby osiągnąć ten cel.
Order by the semantic reranker (Kolejność według semantycznego rerankera)
Jeśli używasz semantycznego klasyfikatora, @search.rerankerScore określa kolejność sortowania wyników.
Zakres @search.rerankerScore wynosi od 1 do 4,00, gdzie wyższy wynik wskazuje silniejszy wynik semantyczny.
Order with orderby (Zamówienie z kolejnością)
Jeśli spójne porządkowanie jest wymaganiem aplikacji, możesz zdefiniować orderby wyrażenie w polu. Do zamawiania wyników mogą służyć tylko pola indeksowane jako "sortowalne".
Pola często używane w klasyfikacji orderby , dacie i lokalizacji. Filtrowanie według lokalizacji wymaga, aby wyrażenie filtru geo.distance() wywołuje funkcję oprócz nazwy pola.
Pola liczbowe (, Edm.Int32, Edm.Int64) są sortowane w kolejności liczbowej (Edm.Doublena przykład 1, 2, 10, 11, 20).
Pola ciągów (Edm.ComplexTypeEdm.String, pola podrzędne) są sortowane w kolejności sortowania ASCII lub Sortowanie Unicode w zależności od języka.
Zawartość liczbowa w polach ciągów jest sortowana alfabetycznie (1, 10, 11, 2, 20).
Wielkie litery ciągi są sortowane przed małymi literami (APPLE, Apple, BANANA, Banana, Apple, apple, banana). Normalizator tekstu można przypisać do wstępnego przetwarzania tekstu przed sortowaniem w celu zmiany tego zachowania. Użycie tokenizatora z małą literą w polu nie ma wpływu na zachowanie sortowania, ponieważ usługa Azure AI Search sortuje w nieanalizowanej kopii pola.
Ciągi prowadzące z diakrytycznymi pojawiają się ostatnio (Äpfel, Öffnen, Üben)
Zwiększanie istotności przy użyciu profilu oceniania
Innym podejściem, które promuje spójność zamówień, jest użycie niestandardowego profilu oceniania. Profile oceniania zapewniają większą kontrolę nad klasyfikowaniem elementów w wynikach wyszukiwania z możliwością zwiększania dopasowań znalezionych w określonych polach. Dodatkowa logika oceniania może pomóc zastąpić drobne różnice między replikami, ponieważ wyniki wyszukiwania dla każdego dokumentu są bardziej oddalone. Zalecamy algorytm klasyfikowania dla tego podejścia.
Wyróżnianie trafień
Wyróżnianie trafień odnosi się do formatowania tekstu (na przykład pogrubienia lub żółtego wyróżnienia) stosowanego do pasujących terminów w wyniku, co ułatwia wykrycie dopasowania. Wyróżnianie jest przydatne w przypadku dłuższych pól zawartości, takich jak pole opisu, gdzie dopasowanie nie jest od razu oczywiste.
Zwróć uwagę, że wyróżnianie jest stosowane do poszczególnych terminów. Nie ma możliwości wyróżniania zawartości całego pola. Jeśli chcesz wyróżnić frazę, musisz podać pasujące terminy (lub frazę) w ciągu zapytania ujętego w cudzysłów. Ta technika została szczegółowo opisana w tej sekcji.
Instrukcje wyróżniania trafień są udostępniane w żądaniu zapytania. Zapytania wyzwalające rozszerzanie zapytań w a aparatu, takie jak wyszukiwanie rozmyte i wieloznaczne, mają ograniczoną obsługę wyróżniania trafień.
Wymagania dotyczące wyróżniania trafień
- Pola muszą być
Edm.StringlubCollection(Edm.String) - Pola muszą być przypisywane pod adresem
searchable
Określanie wyróżniania w żądaniu
Aby zwrócić wyróżnione terminy, dołącz parametr wyróżnienia w żądaniu zapytania. Parametr jest ustawiony na rozdzielaną przecinkami listę pól.
Domyślnie znacznik formatu to <em>, ale można zastąpić tag przy użyciu parametrów highlightPreTag i highlightPostTag . Kod klienta obsługuje odpowiedź (na przykład zastosowanie czcionki pogrubionej lub żółtego tła).
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "divine secrets",
"highlight": "title, original_title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>"
}
Domyślnie usługa Azure AI Search zwraca maksymalnie pięć wyróżnień na pole. Tę liczbę można dostosować, dołączając kreskę, po której następuje liczba całkowita. Na przykład "highlight": "description-10" zwraca maksymalnie 10 wyróżnionych terminów dotyczących dopasowywania zawartości w polu opisu.
Wyróżnione wyniki
W przypadku dodawania wyróżniania do zapytania odpowiedź zawiera element @search.highlights dla każdego wyniku, dzięki czemu kod aplikacji może być przeznaczony dla tej struktury. Lista pól określonych dla "wyróżnienia" znajduje się w odpowiedzi.
W wyszukiwaniu słów kluczowych każdy termin jest skanowany niezależnie. Zapytanie dotyczące "boskich wpisów tajnych" zwraca dopasowania do dowolnego dokumentu zawierającego dowolny termin.
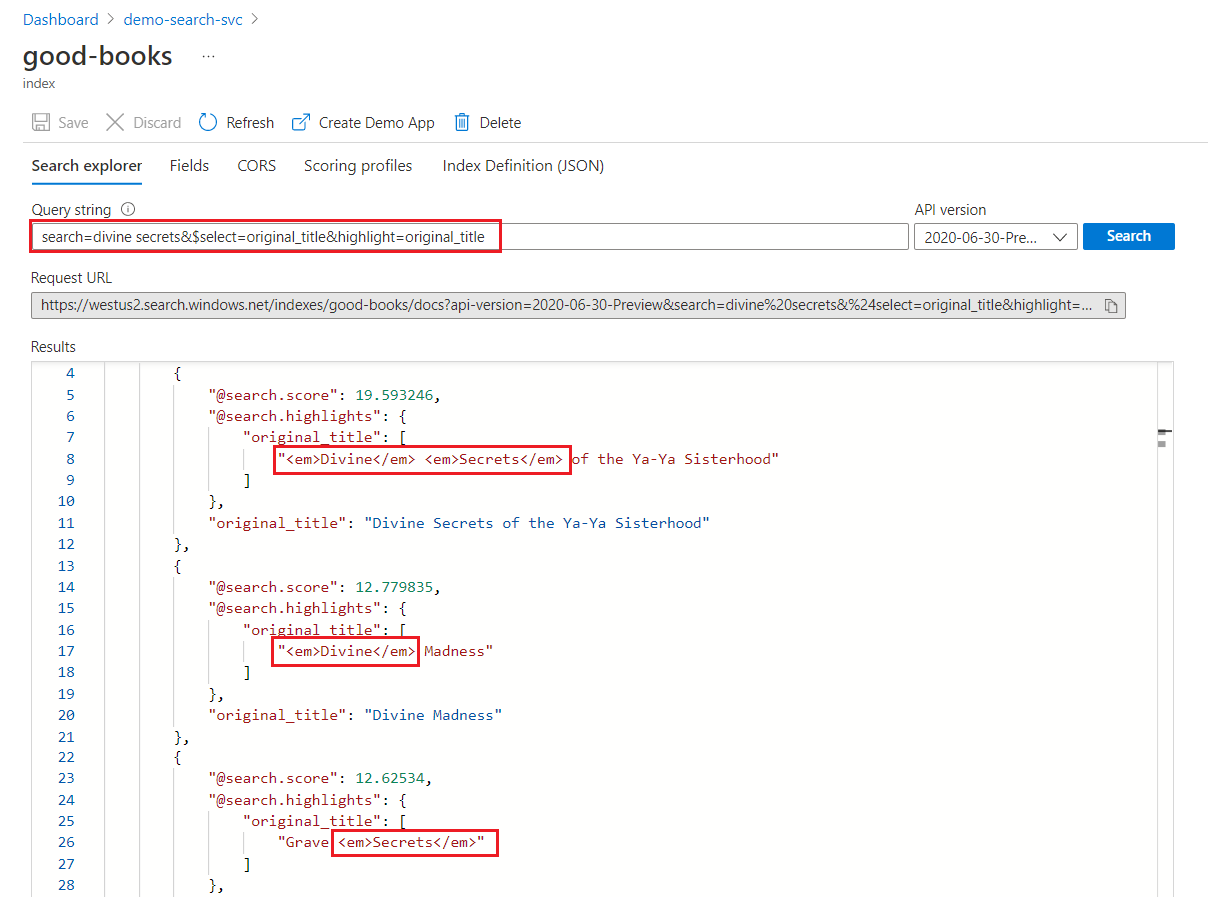
Wyróżnianie wyszukiwania słów kluczowych
W wyróżnionym polu formatowanie jest stosowane do całych terminów. Na przykład na meczu z "The Divine Secrets of the Ya-Ya Sisterhood" formatowanie jest stosowane do każdego terminu oddzielnie, mimo że są one kolejne.
"@odata.count": 39,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"original_title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
],
"title": [
"<em>Divine</em> <em>Secrets</em> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
},
{
"@search.score": 12.779835,
"@search.highlights": {
"original_title": [
"<em>Divine</em> Madness"
],
"title": [
"<em>Divine</em> Madness (Cherub, #5)"
]
},
"original_title": "Divine Madness",
"title": "Divine Madness (Cherub, #5)"
},
{
"@search.score": 12.62534,
"@search.highlights": {
"original_title": [
"Grave <em>Secrets</em>"
],
"title": [
"Grave <em>Secrets</em> (Temperance Brennan, #5)"
]
},
"original_title": "Grave Secrets",
"title": "Grave Secrets (Temperance Brennan, #5)"
}
]
Wyróżnianie wyszukiwania fraz
Formatowanie całego terminu ma zastosowanie nawet w wyszukiwaniu fraz, gdzie wiele terminów jest ujęta w podwójny cudzysłów. Poniższy przykład jest tym samym zapytaniem, z tą różnicą, że "boskie wpisy tajne" są przesyłane jako fraza ujęta w cudzysłów (niektórzy klienci REST wymagają ucieczki od znaków cudzysłowu wewnętrznego z ukośnikiem \"odwrotnym):
POST /indexes/good-books/docs/search?api-version=2024-07-01
{
"search": "\"divine secrets\"",
"select": "title,original_title",
"highlight": "title",
"highlightPreTag": "<b>",
"highlightPostTag": "</b>",
"count": true
}
Ponieważ kryteria mają teraz oba terminy, w indeksie wyszukiwania znajduje się tylko jedno dopasowanie. Odpowiedź na poprzednie zapytanie wygląda następująco:
{
"@odata.count": 1,
"value": [
{
"@search.score": 19.593246,
"@search.highlights": {
"title": [
"<b>Divine</b> <b>Secrets</b> of the Ya-Ya Sisterhood"
]
},
"original_title": "Divine Secrets of the Ya-Ya Sisterhood",
"title": "Divine Secrets of the Ya-Ya Sisterhood"
}
]
}
Wyróżnianie fraz dla starszych usług
usługa wyszukiwania, które zostały utworzone przed 15 lipca 2020 r., implementują inne środowisko wyróżniania dla zapytań fraz.
W poniższych przykładach przyjęto założenie, że ciąg zapytania zawiera frazę "super bowl" zawierającą cudzysłów. Przed lipcem 2020 r. wyróżniono dowolny termin w frazie:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is <em>super</em> awesome with a <em>bowl</em> of chips"
]
W przypadku usług wyszukiwania utworzonych po lipcu 2020 r. zwracane są tylko frazy zgodne z pełnym zapytaniem frazy w pliku @search.highlights:
"@search.highlights": {
"sentence": [
"The <em>super</em> <em>bowl</em> is super awesome with a bowl of chips"
]
Następne kroki
Aby szybko wygenerować stronę wyszukiwania dla klienta, rozważ następujące opcje:
Utwórz aplikację demonstracyjną w witrynie Azure Portal, tworzy stronę HTML z paskiem wyszukiwania, nawigacją aspektową i obszarem miniatury, jeśli masz obrazy.
Dodawanie wyszukiwania do aplikacji ASP.NET Core (MVC) to samouczek i przykład kodu, który tworzy funkcjonalnego klienta.
Dodawanie wyszukiwania do aplikacji internetowych to samouczek języka C# i przykład kodu, który korzysta z bibliotek Języka JavaScript platformy React na potrzeby środowiska użytkownika. Aplikacja jest wdrażana przy użyciu usługi Azure Static Web Apps i implementuje stronicowanie.