Analizowanie sentimentu przy użyciu CLI (interfejsu wiersza polecenia) ML.NET
Dowiedz się, jak używać interfejsu wiersza polecenia ML.NET do automatycznego generowania modelu ML.NET i bazowego kodu języka C#. Udostępniasz zestaw danych i zadanie uczenia maszynowego, które chcesz zaimplementować, a interfejs wiersza polecenia używa aparatu automatycznego uczenia maszynowego do tworzenia kodu źródłowego generowania i wdrażania modelu, a także modelu klasyfikacji.
W tym samouczku wykonasz następujące czynności:
- Przygotowywanie danych do wybranego zadania uczenia maszynowego
- Uruchamianie polecenia
mlnet classificationz poziomu interfejsu wiersza polecenia - Przeglądanie wyników metryk jakości
- Omówienie wygenerowanego kodu w języku C# do korzystania z modelu w aplikacji
- Eksplorowanie wygenerowanego kodu w języku C#, który został użyty do wytrenowania modelu
Notatka
Ten artykuł dotyczy narzędzia interfejsu wiersza polecenia ML.NET, które jest obecnie dostępne w wersji zapoznawczej, a materiał może ulec zmianie. Aby uzyskać więcej informacji, odwiedź stronę ML.NET.
Interfejs wiersza polecenia ML.NET jest częścią ML.NET, a jego głównym celem jest "demokratyzacja" ML.NET dla deweloperów .NET, tak aby podczas nauki ML.NET nie musisz pisać kodu od zera, aby rozpocząć pracę.
Interfejs wiersza polecenia ML.NET można uruchomić w dowolnym wierszu polecenia (Windows, Mac lub Linux), aby wygenerować modele ML.NET dobrej jakości i kod źródłowy na podstawie udostępnionych zestawów danych szkoleniowych.
Warunki wstępne
- SDK .NET 8 lub nowszy
- (Opcjonalnie) Visual Studio
- ML.NET CLI
Możesz uruchomić wygenerowane projekty kodu języka C# z poziomu programu Visual Studio lub za pomocą interfejsu wiersza polecenia platformy dotnet run (.NET CLI).
Przygotowywanie danych
Użyjemy istniejącego zestawu danych do scenariusza "Analiza sentymentu", jako zadanie uczenia maszynowego klasyfikacji binarnej. Możesz użyć własnego zestawu danych w podobny sposób, a model i kod zostaną wygenerowane dla Ciebie.
Pobierz plik zip zestawu danych z etykietami opinii UCI (zobacz cytaty w poniższej notatce)i rozpakuj go w dowolnym wybranym folderze.
Notatka
Zestaw danych używany w tym samouczku pochodzi z artykułu "Od grupy do poszczególnych etykiet przy użyciu głębokich cech", Kotzias i inni. KDD 2015 i hostowane w repozytorium UCI Machine Learning — Dua, D. i Karra Taniskidou, E. (2017). Repozytorium UCI Machine Learning [http://archive.ics.uci.edu/ml]. Irvine, CA: University of California, School of Information and Computer Science.
Skopiuj plik
yelp_labelled.txtdo dowolnego utworzonego wcześniej folderu (na przykład/cli-test).Otwórz preferowany wiersz polecenia i przejdź do folderu, w którym skopiowano plik zestawu danych. Na przykład:
cd /cli-testZa pomocą dowolnego edytora tekstów, takiego jak Visual Studio Code, możesz otworzyć i eksplorować plik zestawu danych
yelp_labelled.txt. Widać, że struktura to:Plik nie ma nagłówka. Użyjesz indeksu kolumny.
Istnieją tylko dwie kolumny:
Tekst (indeks kolumny 0) Etykieta (indeks kolumny 1) Wow... Kochał to miejsce. 1 Skórka nie jest dobra. 0 Nie smaczne i tekstura była po prostu paskudna. 0 ... WIELE WIĘCEJ LINIJEK TEKSTU... ... (1 lub 0)...
Upewnij się, że plik zestawu danych został zamknięty z poziomu edytora.
Teraz możesz rozpocząć korzystanie z CLI dla tego scenariusza "Analiza sentymentu".
Notatka
Po ukończeniu tego samouczka możesz również wypróbować własne zestawy danych, o ile są one gotowe do wykorzystania w dowolnym z zadań uczenia maszynowego obecnie obsługiwanych przez wersję zapoznawczą interfejsu wiersza poleceń ML.NET, które to zadania to "Klasyfikacja binarna", "Klasyfikacja", "Regresja", oraz "Rekomendacje".
Uruchamianie polecenia "klasyfikacja mlnet"
Uruchom następujące polecenie w konsoli ML.NET:
mlnet classification --dataset "yelp_labelled.txt" --label-col 1 --has-header false --train-time 10To polecenie uruchamia polecenie
mlnet classification:-
klasyfikacji ML - używa pliku jako zestawu danych
yelp_labelled.txtszkoleniowego i testowego (wewnętrznie interfejs wiersza polecenia będzie używał walidacji krzyżowej lub podzieli go na dwa zestawy danych, jeden do szkolenia i jeden do testowania) - gdzie kolumna celu/obiektu, którą chcesz przewidzieć (często określana jako "etykieta") jest kolumną z indeksem 1 (jest to druga kolumna, ponieważ indeks jest rozpoczynany od zera)
- Nie używa nagłówka pliku z nazwami kolumn, ponieważ ten konkretny plik zestawu danych nie ma nagłówka.
- planowany czas eksploracji i szkolenia dla eksperymentu wynosi 10 sekund
Zostaną wyświetlone dane wyjściowe z interfejsu wiersza polecenia podobne do następujących:
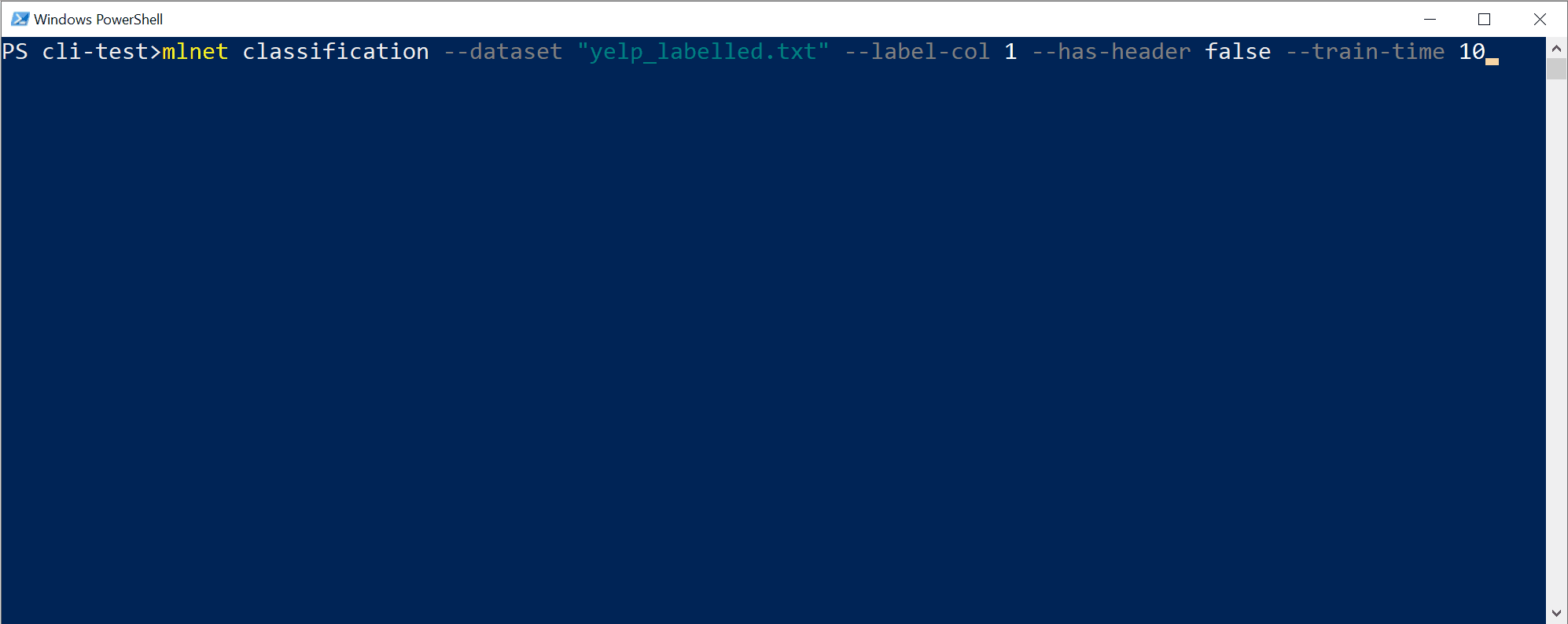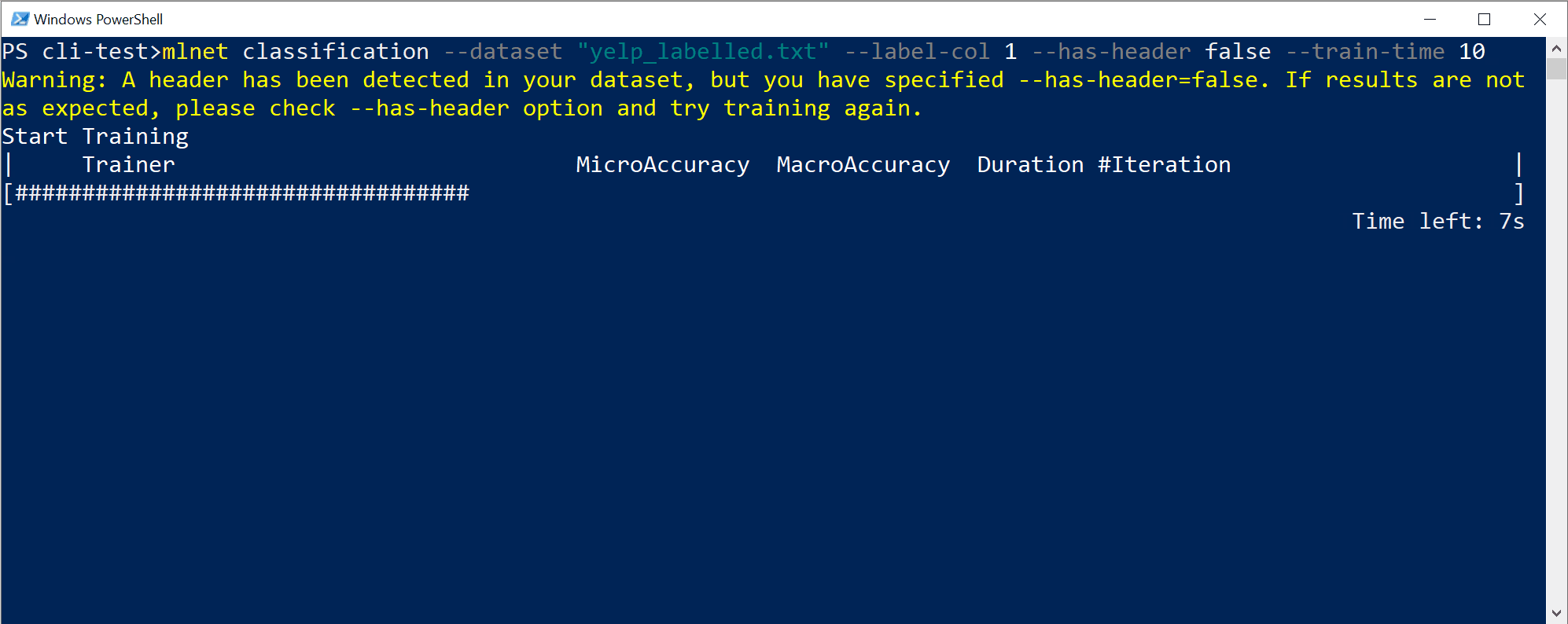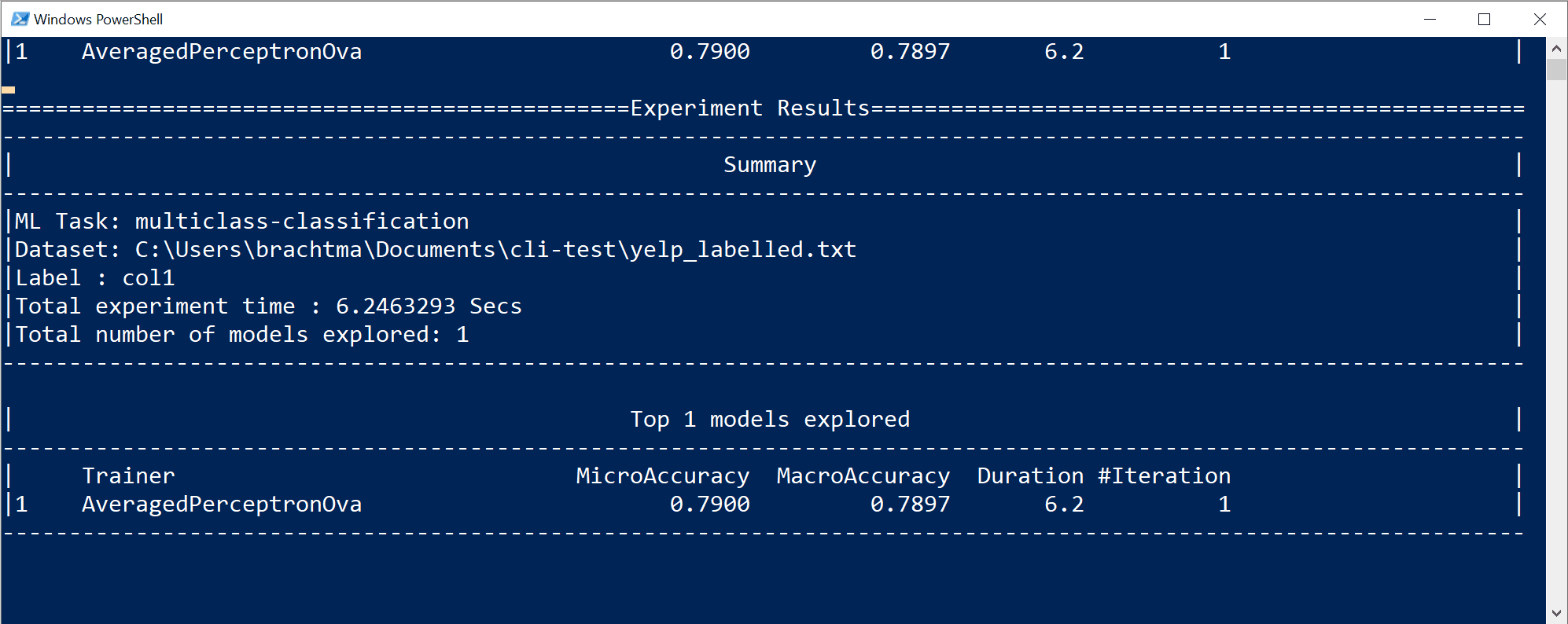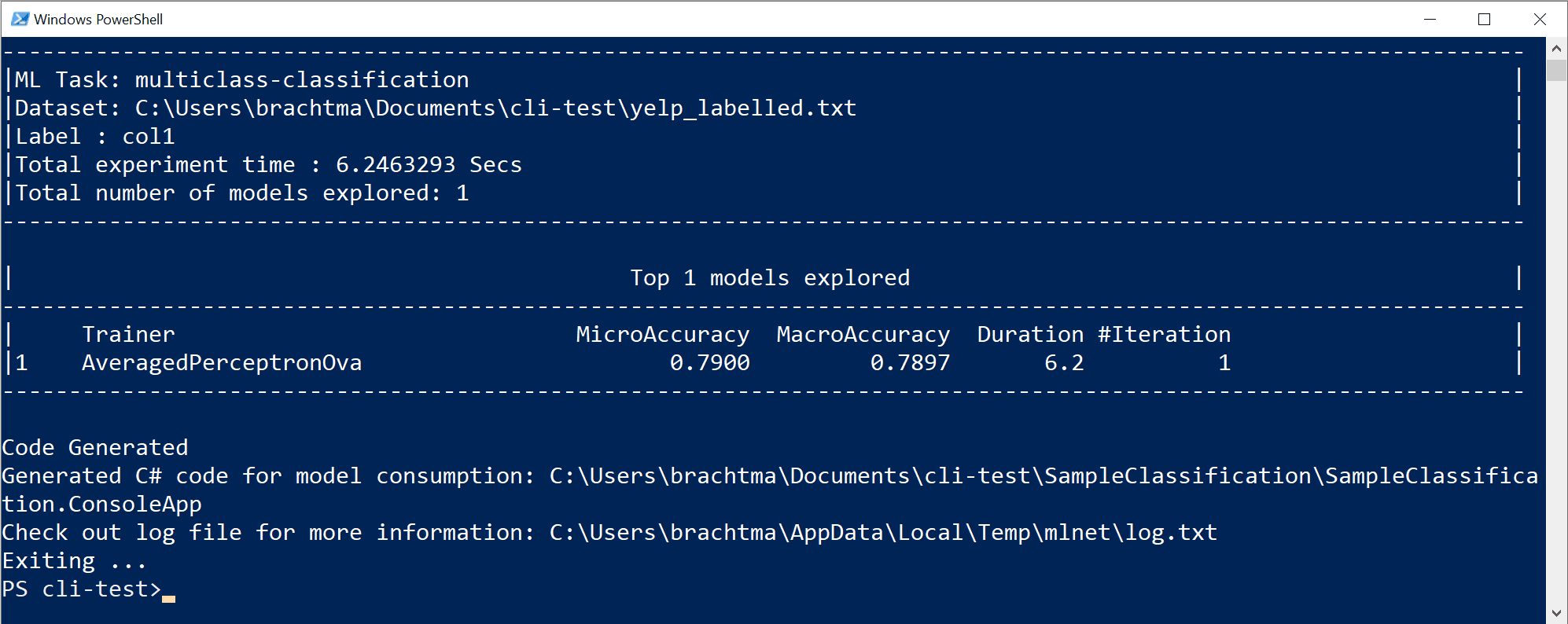
W tym konkretnym przypadku w ciągu zaledwie 10 sekund i przy podanym małym zestawie danych narzędzie interfejsu wiersza polecenia mogło uruchomić sporo iteracji, co oznacza trenowanie wiele razy na podstawie różnych kombinacji algorytmów/konfiguracji z różnymi wewnętrznymi przekształceniami danych i hiperparami algorytmu.
Na koniec model "najlepszej jakości" znaleziony w 10 sekundach jest modelem używającym określonego trenera/algorytmu z dowolną konkretną konfiguracją. W zależności od czasu eksploracji polecenie może wygenerować inny wynik. Wybór jest oparty na wielu wyświetlanych metrykach, takich jak
Accuracy.Informacje o metrykach jakości modelu
Pierwszą i najłatwiejszą metryką do oceny modelu klasyfikacji binarnej jest dokładność, co jest proste do zrozumienia. "Dokładność jest proporcją prawidłowych przewidywań z zestawem danych testowych". Im bliżej 100% (1,00), tym lepiej.
Jednak istnieją przypadki, w których pomiar za pomocą metryki dokładność nie jest wystarczający, zwłaszcza gdy etykiety (0 i 1 w tym przypadku) są niezrównoważone w zestawie danych testowych.
Aby uzyskać dodatkowe metryki i więcej szczegółowych informacji na temat metryk, takich jak Accuracy, AUC, AUCPR i F1-score używane do oceny różnych modeli, zobacz Understanding ML.NET metrics.
Notatka
Możesz wypróbować dokładnie ten sam zestaw danych i ustawić kilka minut dla
--max-exploration-time(czyli na przykład trzy minuty, co oznacza 180 sekund), co pozwoli znaleźć lepszy "najlepszy model" dzięki innej konfiguracji przepływu trenowania dla tego zestawu danych (który jest dość mały, 1000 wierszy).Aby znaleźć "najlepszy/dobry model", który jest "modelem gotowym do produkcji" przeznaczonym dla większych zestawów danych, należy wykonać eksperymenty z interfejsem wiersza polecenia zwykle określając znacznie więcej czasu eksploracji w zależności od rozmiaru zestawu danych. W wielu przypadkach może być wymagane wiele godzin czasu eksploracji, zwłaszcza jeśli zestaw danych jest duży w wierszach i kolumnach.
-
Poprzednie wykonanie polecenia wygenerowało następujące zasoby:
- Model serializowany .zip ("najlepszy model") gotowy do użycia.
- Kod języka C# do uruchamiania/oceniania wygenerowanego modelu (aby tworzyć przewidywania w aplikacjach użytkowników końcowych za pomocą tego modelu).
- Kod szkoleniowy języka C# używany do generowania tego modelu (cele szkoleniowe).
- Plik dziennika ze wszystkimi iteracjami, zawierający szczegółowe informacje o każdym testowanym algorytmie, wraz z jego kombinacją hiperparametrów i przekształceń danych.
Pierwsze dwa zasoby (.ZIP plik modelu i kod C# do uruchamiania tego modelu) mogą być używane bezpośrednio w aplikacjach użytkowników końcowych (ASP.NET Core aplikacja webowa, usługi, aplikacja desktopowa itp.), aby dokonywać prognoz przy użyciu wygenerowanego modelu uczenia maszynowego.
Trzeci zasób, kod trenowania, pokazuje, jaki kod interfejsu API ML.NET był używany przez wiersz polecenia do trenowania wygenerowanego modelu, co pozwala zbadać, jaki konkretny trener/algorytm i hiperparametry zostały wybrane przez wiersz polecenia.
Te wyliczone zasoby zostały wyjaśnione w poniższych krokach samouczka.
Zapoznaj się z wygenerowanym kodem C# do uruchamiania modelu w celu dokonywania prognoz.
W programie Visual Studio otwórz rozwiązanie wygenerowane w folderze o nazwie
SampleClassificationw oryginalnym folderze docelowym (nazwa została nazwana/cli-testw samouczku). Powinno zostać wyświetlone rozwiązanie podobne do:
Notatka
Samouczek sugeruje korzystanie z programu Visual Studio, ale możesz również eksplorować wygenerowany kod C# (dwa projekty) przy użyciu dowolnego edytora tekstu i uruchomić wygenerowaną aplikację konsolową z
dotnet CLIna komputerze z systemem macOS, Linux lub Windows.- Wygenerowana aplikacja konsolowa zawiera kod wykonawczy, który należy przejrzeć, a następnie zwykle ponownie użyć kodu oceniania (kodu uruchamianego przez model uczenia maszynowego w celu przewidywania) przez przeniesienie tego prostego kodu (zaledwie kilka wierszy) do aplikacji użytkownika końcowego, gdzie chcesz dokonać prognoz.
- Wygenerowany plik mbconfig to plik konfiguracji, który może służyć do ponownego trenowania modelu za pomocą interfejsu wiersza polecenia lub narzędzia Model Builder. Będzie to również zawierać dwa skojarzone z nim pliki kodu i plik zip.
- Plik trenowania
zawiera kod umożliwiający skompilowanie potoku modelu przy użyciu interfejsu API ML.NET. - Plik konsumpcji zawiera kod do wykorzystania modelu.
- Plik zip , który jest modelem wygenerowanym z interfejsu wiersza polecenia.
- Plik trenowania
Otwórz plik SampleClassification.consumption.cs w pliku mbconfig. Zobaczysz, że istnieją klasy wejściowe i wyjściowe. Są to klasy danych lub klasy POCO używane do przechowywania danych. Klasy zawierają standardowy kod, który jest przydatny, jeśli zestaw danych zawiera dziesiątki lub nawet setki kolumn.
- Klasa
ModelInputjest używana podczas odczytywania danych z zestawu danych. - Klasa
ModelOutputsłuży do uzyskiwania wyniku przewidywania (danych przewidywania).
- Klasa
Otwórz plik Program.cs i zapoznaj się z kodem. W kilku wierszach możesz uruchomić model i utworzyć przykładowe przewidywanie.
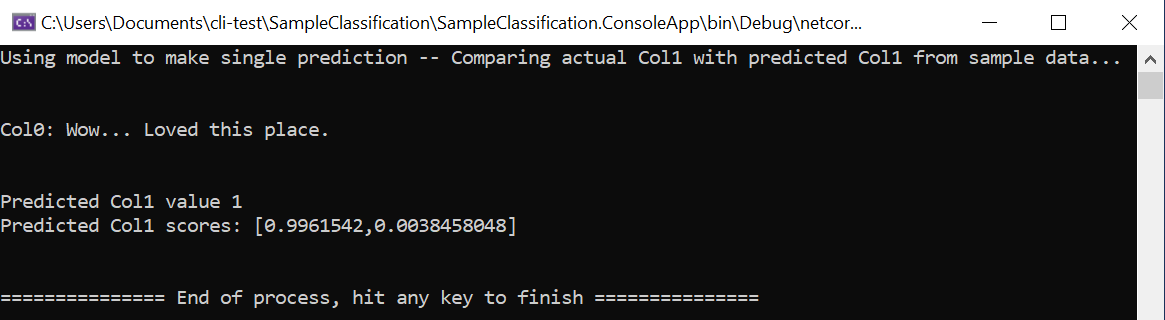
static void Main(string[] args) { // Create single instance of sample data from first line of dataset for model input ModelInput sampleData = new ModelInput() { Col0 = @"Wow... Loved this place.", }; // Make a single prediction on the sample data and print results var predictionResult = SampleClassification.Predict(sampleData); Console.WriteLine("Using model to make single prediction -- Comparing actual Col1 with predicted Col1 from sample data...\n\n"); Console.WriteLine($"Col0: {sampleData.Col0}"); Console.WriteLine($"\n\nPredicted Col1 value {predictionResult.PredictedLabel} \nPredicted Col1 scores: [{String.Join(",", predictionResult.Score)}]\n\n"); Console.WriteLine("=============== End of process, hit any key to finish ==============="); Console.ReadKey(); }Pierwsze wiersze kodu tworzą pojedyncze przykładowe dane. W takim przypadku pojedyncze przykładowe dane są oparte na pierwszym wierszu zestawu danych, który ma być używany do przewidywania. Możesz również utworzyć własne "zakodowane" dane, aktualizując kod:
ModelInput sampleData = new ModelInput() { Col0 = "The ML.NET CLI is great for getting started. Very cool!" };Następny wiersz kodu używa metody
SampleClassification.Predict()dla określonych danych wejściowych w celu przewidywania i zwracania wyników (na podstawie schematu ModelOutput.cs).Ostatnie wiersze kodu wyświetlają właściwości przykładowych danych (w tym przypadku Komentarza), a także predykcję sentymentu i odpowiadające jej wyniki dla pozytywnego sentymentu (1) i negatywnego sentymentu (2).
Uruchom projekt, używając oryginalnych przykładowych danych załadowanych z pierwszego wiersza zestawu danych lub podając własne niestandardowe, zakodowane na podstawie kodu przykładowe dane. Powinieneś otrzymać przewidywanie porównywalne z:
Spróbuj zmienić zakodowane przykładowe dane na inne zdania z różnymi tonacjami i zobaczyć, jak model przewiduje pozytywną lub negatywną tonację.
Unowocześnij swoje aplikacje dla użytkowników końcowych poprzez wykorzystanie prognoz modeli uczenia maszynowego.
Możesz użyć podobnego kodu oceniania modelu uczenia maszynowego, aby uruchomić model w aplikacji użytkownika końcowego i przewidywać.
Na przykład można bezpośrednio przenieść ten kod do dowolnej aplikacji klasycznej systemu Windows, takiej jak WPF i WinForms i uruchomić model w taki sam sposób, jak w aplikacji konsolowej.
Jednak sposób implementowania tych wierszy kodu w celu uruchomienia modelu uczenia maszynowego powinien być zoptymalizowany (czyli buforować model .zip plik i ładować go raz) i mieć pojedyncze obiekty zamiast tworzyć je na każdym żądaniu, zwłaszcza jeśli aplikacja musi być skalowalna, taka jak aplikacja internetowa lub usługa rozproszona, jak wyjaśniono w poniższej sekcji.
Uruchamianie modeli ML.NET w skalowalnych aplikacjach internetowych i usługach core ASP.NET (aplikacje wielowątowe)
Tworzenie obiektu modelu (ITransformer ładowane z pliku .zip modelu) i obiekt PredictionEngine należy zoptymalizować szczególnie w przypadku uruchamiania w skalowalnych aplikacjach internetowych i usługach rozproszonych. W pierwszym przypadku optymalizacja obiektu modelu (ITransformer) jest bezpośrednia. Ponieważ obiekt ITransformer jest bezpieczny dla wielu wątków, można buforować go jako singleton lub obiekt statyczny, aby załadować model tylko raz.
W przypadku drugiego obiektu, PredictionEngine, sytuacja nie jest tak prosta, ponieważ obiekt PredictionEngine nie jest bezpieczny pod względem wątków, a zatem nie można go zainicjować jako pojedynczego lub statycznego obiektu w aplikacji ASP.NET Core. Problem z bezpieczeństwem wątków i skalowalnością jest głęboko omówiony w tym wpisie na blogu.
Jednak wszystko stało się dla Ciebie o wiele łatwiejsze niż to, co wyjaśniono w tym wpisie w blogu. Pracowaliśmy nad prostszym podejściem i utworzyliśmy ".NET Integration Package", którego można łatwo używać w aplikacjach i usługach ASP.NET Core, rejestrując je w usługach DI aplikacji (usługi wstrzykiwania zależności), a następnie bezpośrednio z niego korzystać w swoim kodzie. Zapoznaj się z poniższym samouczkiem i przykładem, aby to zrobić:
- Samouczek : Uruchamianie modeli ML.NET w skalowalnych aplikacjach sieciowych ASP.NET Core i WebAPI
- Przykład "": skalowalny model "ML.NET" w "ASP.NET Core WebAPI"
Zapoznaj się z wygenerowanym kodem w języku C#, który został użyty do przeszkolenia modelu „najlepszej jakości”
W celu uzyskania bardziej zaawansowanych celów szkoleniowych możesz również eksplorować wygenerowany kod języka C#, który był używany przez narzędzie interfejsu wiersza polecenia do trenowania wygenerowanego modelu.
Ten kod modelu trenowania jest generowany w pliku o nazwie SampleClassification.training.cs, dzięki czemu można zbadać ten kod trenowania.
Co ważniejsze, w przypadku tego konkretnego scenariusza (model analizy sentymentu) możesz również porównać wygenerowany kod szkoleniowy z kodem opisanym w poniższym poradniku.
Warto porównać wybrany algorytm i konfigurację potoku danych w samouczku z kodem wygenerowanym przez narzędzie interfejsu CLI. W zależności od tego, ile czasu poświęcasz na iterowanie i wyszukiwanie lepszych modeli, wybrany algorytm oraz jego hiperparametry i konfiguracja przepływu danych mogą się różnić.
W tym samouczku nauczyłeś się, jak:
- Przygotowywanie danych do wybranego zadania uczenia maszynowego (problem do rozwiązania)
- Uruchom polecenie 'mlnet classification' w narzędziu wiersza polecenia
- Przeglądanie wyników metryk jakości
- Zapoznaj się z wygenerowanym kodem języka C#, aby uruchomić model (kod do użycia w aplikacji użytkownika końcowego)
- Zapoznaj się z wygenerowanym kodem języka C#, który został użyty do wytrenowania modelu o "najlepszej jakości" w celu generowania dochodów.
Zobacz też
- Automatyzacja trenowania modeli z użyciem interfejsu wiersza polecenia ML.NET
- samouczek : Uruchamianie modeli ML.NET w skalowalnych aplikacjach sieciowych ASP.NET Core i WebAPI
- Przykład : Skalowalny Model ML.NET w ASP.NET Core WebAPI
- Przewodnik referencyjny polecenia automatycznego trenowania w ML.NET
- Telemetria w ML.NET CLI