CREATE EXTERNAL TABLE (Transact-SQL)
Tworzy tabelę zewnętrzną.
Ten artykuł zawiera składnię, argumenty, uwagi, uprawnienia i przykłady dla wybranego produktu SQL.
Aby uzyskać więcej informacji na temat konwencji składni, zobacz Transact-SQL konwencje składni.
Wybieranie produktu
W poniższym wierszu wybierz nazwę produktu, którą cię interesuje, i zostanie wyświetlona tylko informacja o tym produkcie.
* SQL Server *
usługi
Azure Synapse
analizy
Omówienie: SQL Server
To polecenie tworzy zewnętrzną tabelę dla technologii PolyBase w celu uzyskania dostępu do danych przechowywanych w klastrze Hadoop lub zewnętrznej tabeli usługi Azure Blob Storage PolyBase, która odwołuje się do danych przechowywanych w klastrze hadoop lub usłudze Azure Blob Storage.
Dotyczy: PROGRAMU SQL Server 2016 (lub nowszego)
Użyj tabeli zewnętrznej z zewnętrznym źródłem danych dla zapytań polyBase. Zewnętrzne źródła danych są używane do nawiązywania łączności i obsługi tych podstawowych przypadków użycia:
- Wirtualizacja danych i ładowanie danych przy użyciu PolyBase
- Operacje ładowania zbiorczego przy użyciu programu SQL Server lub usługi SQL Database przy użyciu
BULK INSERTlubOPENROWSET
Zobacz również CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Składnia
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'folder_or_filepath',
DATA_SOURCE = external_data_source_name,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ ,...n ] ]
)
[;]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumenty
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Jedna do trzech części nazwy tabeli do utworzenia. W przypadku tabeli zewnętrznej program SQL przechowuje tylko metadane tabeli wraz z podstawowymi statystykami dotyczącymi pliku lub folderu, do którego odwołuje się usługa Hadoop lub Azure Blob Storage. Żadne rzeczywiste dane nie są przenoszone ani przechowywane w programie SQL Server.
Ważny
Aby uzyskać najlepszą wydajność, jeśli sterownik zewnętrznego źródła danych obsługuje trzyczęściową nazwę, zdecydowanie zaleca się podanie trzyczęściowej nazwy.
<column_definition> [ ,...n ]
FUNKCJA CREATE EXTERNAL TABLE obsługuje możliwość konfigurowania nazwy kolumny, typu danych, wartości null i sortowania. Nie można użyć domyślnego ograniczenia w tabelach zewnętrznych.
Definicje kolumn, w tym typy danych i liczba kolumn, muszą być zgodne z danymi w plikach zewnętrznych. Jeśli wystąpi niezgodność, wiersze pliku zostaną odrzucone podczas wykonywania zapytań dotyczących rzeczywistych danych.
LOCATION = 'folder_or_filepath'
Określa folder lub ścieżkę pliku i nazwę pliku dla rzeczywistych danych w usłudze Hadoop lub Azure Blob Storage. Ponadto magazyn obiektów zgodny z programem S3 jest obsługiwany od wersji SQL Server 2022 (16.x)). Lokalizacja rozpoczyna się od folderu głównego. Folder główny to lokalizacja danych określona w zewnętrznym źródle danych.
W programie SQL Server instrukcja CREATE EXTERNAL TABLE tworzy ścieżkę i folder, jeśli jeszcze nie istnieje. Następnie możesz użyć funkcji INSERT INTO, aby wyeksportować dane z lokalnej tabeli programu SQL Server do zewnętrznego źródła danych. Aby uzyskać więcej informacji, zobacz Zapytania polyBase.
Jeśli określisz lokalizację jako folder, zapytanie polyBase wybrane z tabeli zewnętrznej pobierze pliki z folderu i wszystkich jego podfolderów. Podobnie jak w usłudze Hadoop technologia PolyBase nie zwraca ukrytych folderów. Nie zwraca również plików, dla których nazwa pliku zaczyna się podkreśleniu (_) ani kropką (.).
Jeśli LOCATION='/webdata/'poniższego przykładu, zapytanie PolyBase zwróci wiersze z mydata.txt i mydata2.txt. Nie zwróci mydata3.txt, ponieważ jest to plik w ukrytym podfolderze. I nie zwróci _hidden.txt, ponieważ jest to ukryty plik.
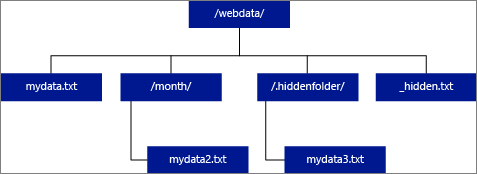
Aby zmienić wartość domyślną i tylko odczytywać z folderu głównego, ustaw atrybut <polybase.recursive.traversal> na wartość "false" w pliku konfiguracji core-site.xml. Ten plik znajduje się w <SqlBinRoot>\PolyBase\Hadoop\Conf w katalogu głównym bin programu SQL Server. Na przykład C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn.
DATA_SOURCE = external_data_source_name
Określa nazwę zewnętrznego źródła danych, które zawiera lokalizację danych zewnętrznych. Ta lokalizacja jest systemem plików Hadoop (HDFS), kontenerem usługi Azure Blob Storage lub usługą Azure Data Lake Store. Aby utworzyć zewnętrzne źródło danych, użyj CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Określa nazwę obiektu formatu pliku zewnętrznego, który przechowuje typ pliku i metodę kompresji dla danych zewnętrznych. Aby utworzyć format pliku zewnętrznego, użyj CREATE EXTERNAL FILE FORMAT.
Formaty plików zewnętrznych mogą być ponownie używane przez wiele podobnych plików zewnętrznych.
Opcje odrzucania
Tej opcji można używać tylko z zewnętrznymi źródłami danych, gdzie TYPE = HADOOP.
Można określić parametry odrzucenia, które określają, jak technologia PolyBase będzie obsługiwać zanieczyszczonych rekordów pobieranych z zewnętrznego źródła danych. Rekord danych jest uznawany za "zanieczyszczony", jeśli rzeczywiste typy danych lub liczba kolumn nie są zgodne z definicjami kolumn tabeli zewnętrznej.
Jeśli nie określisz ani nie zmienisz wartości odrzucania, program PolyBase używa wartości domyślnych. Te informacje o parametrach odrzucania są przechowywane jako dodatkowe metadane podczas tworzenia tabeli zewnętrznej za pomocą instrukcji CREATE EXTERNAL TABLE. Gdy przyszła instrukcja SELECT lub SELECT INTO wybierze dane z tabeli zewnętrznej, program PolyBase użyje opcji odrzucenia, aby określić liczbę lub procent wierszy, które mogą zostać odrzucone, zanim rzeczywiste zapytanie zakończy się niepowodzeniem. Zapytanie zwróci (częściowe) wyniki do momentu przekroczenia progu odrzucenia. Następnie kończy się niepowodzeniem z odpowiednim komunikatem o błędzie.
REJECT_TYPE = wartość | procent
Wyjaśnia, czy opcja REJECT_VALUE jest określona jako wartość literału, czy wartość procentowa.
wartości
REJECT_VALUE jest wartością literału, a nie wartością procentową. Zapytanie zakończy się niepowodzeniem, gdy liczba odrzuconych wierszy przekroczy reject_value.
Jeśli na przykład REJECT_VALUE = 5 i REJECT_TYPE = value, zapytanie SELECT zakończy się niepowodzeniem po odrzuceniu pięciu wierszy.
procent
REJECT_VALUE jest wartością procentową, a nie wartością literału. Zapytanie zakończy się niepowodzeniem, gdy wartość procentowa wierszy, które zakończyły się niepowodzeniem, przekroczy reject_value. Procent wierszy, które zakończyły się niepowodzeniem, jest obliczany w odstępach czasu.
REJECT_VALUE = reject_value
Określa wartość lub procent wierszy, które można odrzucić przed niepowodzeniem zapytania.
W przypadku REJECT_TYPE = wartość reject_value musi być liczbą całkowitą z zakresu od 0 do 2147 483 647.
Dla REJECT_TYPE = procent, reject_value musi być zmiennoprzecinkowy z zakresu od 0 do 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Ten atrybut jest wymagany podczas określania REJECT_TYPE = procent. Określa liczbę wierszy do pobrania przed ponownym obliczeniu wartości procentowej odrzuconych wierszy przez program PolyBase.
Parametr reject_sample_value musi być liczbą całkowitą z zakresu od 0 do 2 147 483 647.
Jeśli na przykład REJECT_SAMPLE_VALUE = 1000, program PolyBase obliczy procent nieudanych wierszy po próbie zaimportowania 1000 wierszy z pliku danych zewnętrznych. Jeśli procent nieudanych wierszy jest mniejszy niż reject_value, program PolyBase próbuje pobrać kolejne 1000 wierszy. Po podjęciu próby zaimportowania kolejnych 1000 wierszy w dalszym ciągu oblicza procent nieudanych wierszy.
Nuta
Ponieważ program PolyBase oblicza procent wierszy, które zakończyły się niepowodzeniem w odstępach czasu, rzeczywisty procent wierszy, które zakończyły się niepowodzeniem, może przekroczyć reject_value.
Przykład:
W tym przykładzie pokazano, jak trzy opcje ODRZUć współdziałają ze sobą. Jeśli na przykład REJECT_TYPE = procent, REJECT_VALUE = 30 i REJECT_SAMPLE_VALUE = 100, może wystąpić następujący scenariusz:
- Program PolyBase próbuje pobrać pierwsze 100 wierszy; 25 nie powiodło się i 75 powiodło się.
- Procent nieudanych wierszy jest obliczany jako 25%, który jest mniejszy niż wartość odrzucenia 30%. W związku z tym technologia PolyBase kontynuuje pobieranie danych z zewnętrznego źródła danych.
- Program PolyBase próbuje załadować kolejne 100 wierszy; tym razem 25 wierszy powiedzie się, a 75 wierszy zakończy się niepowodzeniem.
- Procent nieudanych wierszy jest ponownie obliczany jako 50%. Wartość procentowa nieudanych wierszy przekroczyła 30% wartość odrzucania.
- Zapytanie PolyBase kończy się niepowodzeniem z 50% odrzuconymi wierszami po próbie zwrócenia pierwszych 200 wierszy. Zwróć uwagę, że pasujące wiersze zostały zwrócone przed przekroczeniem progu odrzucenia przez zapytanie PolyBase.
REJECTED_ROW_LOCATION = lokalizacji katalogu
Dotyczy: PROGRAMU SQL Server 2019 CU6 i nowszych wersji usługi Azure Synapse Analytics.
Określa katalog w zewnętrznym źródle danych, że odrzucone wiersze i odpowiedni plik błędu należy zapisać.
Jeśli określona ścieżka nie istnieje, technologia PolyBase tworzy jedną w Twoim imieniu. Zostanie utworzony katalog podrzędny o nazwie _rejectedrows. Znak _ gwarantuje, że katalog zostanie uniknięty dla innego przetwarzania danych, chyba że jawnie nazwany w parametrze location. W tym katalogu znajduje się folder utworzony na podstawie czasu przesłania obciążenia w formacie YearMonthDay -HourMinuteSecond (np. 20230330-173205). W tym folderze są zapisywane dwa typy plików, plik _reason i plik danych. Tej opcji można używać tylko z zewnętrznymi źródłami danych, w których TYPE = HADOOP i dla tabel zewnętrznych przy użyciu DELIMITEDTEXTFORMAT_TYPE. Aby uzyskać więcej informacji, zobacz CREATE EXTERNAL DATA SOURCE i CREATE EXTERNAL FILE FORMAT.
Pliki przyczyny i pliki danych mają queryID skojarzone z instrukcją CTAS. Ponieważ dane i przyczyna znajdują się w oddzielnych plikach, odpowiadające im pliki mają pasujący sufiks.
Uprawnienia
Wymaga następujących uprawnień użytkownika:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ALTER ANY EXTERNAL FILE FORMAT (dotyczy tylko usług Hadoop i zewnętrznych źródeł danych usługi Azure Storage)
- CONTROL DATABASE (dotyczy tylko usług Hadoop i zewnętrznych źródeł danych usługi Azure Storage)
Należy pamiętać, że zdalne logowanie określone w poświadczeniu O ZAKRESIE BAZY danych używane w CREATE EXTERNAL TABLE polecenia musi mieć uprawnienia Odczyt dla ścieżki/tabeli/kolekcji w zewnętrznym źródle danych określonym w parametrze LOCATION. Jeśli planujesz użyć tej tabeli zewnętrznej do wyeksportowania danych do zewnętrznego źródła danych usługi Hadoop lub usługi Azure Storage, określone logowanie musi mieć uprawnienie do zapisu na ścieżce określonej w lokalizacji. Należy pamiętać, że usługa Hadoop nie jest obsługiwana w programie SQL Server 2022 (16.x).
W przypadku usługi Azure Blob Storage podczas konfigurowania kluczy dostępu i sygnatury dostępu współdzielonego (SAS) w witrynie Azure Portal konta magazynu usługi Azure Blob Storage lub ADLS Gen2 należy skonfigurować uprawnienia Dozwolone przyznać co najmniej uprawnienia odczyt i zapisu. uprawnienia listy mogą być również wymagane podczas wyszukiwania między folderami. Należy również wybrać Kontener i Object jako dozwolone typy zasobów.
Ważny
Uprawnienie ALTER ANY EXTERNAL DATA SOURCE przyznaje każdemu podmiotowi zabezpieczeń możliwość tworzenia i modyfikowania dowolnego zewnętrznego obiektu źródła danych, a w związku z tym przyznaje również możliwość dostępu do wszystkich poświadczeń w zakresie bazy danych. To uprawnienie musi być uznawane za wysoce uprzywilejowane i dlatego musi zostać przyznane tylko zaufanym podmiotom zabezpieczeń w systemie.
Obsługa błędów
Podczas wykonywania instrukcji CREATE EXTERNAL TABLE program PolyBase próbuje nawiązać połączenie z zewnętrznym źródłem danych. Jeśli próba nawiązania połączenia zakończy się niepowodzeniem, instrukcja zakończy się niepowodzeniem, a tabela zewnętrzna nie zostanie utworzona. Wykonanie polecenia może potrwać co najmniej minutę, ponieważ program PolyBase ponawia próbę połączenia, zanim ostatecznie zakończy się niepowodzeniem zapytania.
Uwagi
W scenariuszach zapytań ad hoc, takich jak SELECT FROM EXTERNAL TABLE, polyBase przechowuje wiersze pobierane z zewnętrznego źródła danych w tabeli tymczasowej. Po zakończeniu wykonywania zapytania program PolyBase usuwa i usuwa tabelę tymczasową. Żadne trwałe dane nie są przechowywane w tabelach SQL.
Z kolei w scenariuszu importowania, takim jak SELECT INTO FROM EXTERNAL TABLE, program PolyBase przechowuje wiersze pobierane z zewnętrznego źródła danych jako trwałe dane w tabeli SQL. Nowa tabela jest tworzona podczas wykonywania zapytania, gdy program PolyBase pobiera dane zewnętrzne.
Technologia PolyBase może wypchnąć niektóre obliczenia zapytań do usługi Hadoop, aby zwiększyć wydajność zapytań. Ta akcja jest nazywana wypychanym predykatem. Aby ją włączyć, określ opcję lokalizacji menedżera zasobów usługi Hadoop w CREATE EXTERNAL DATA SOURCE.
Można utworzyć wiele tabel zewnętrznych odwołujących się do tych samych lub różnych zewnętrznych źródeł danych.
Ograniczenia i ograniczenia
Ponieważ dane tabeli zewnętrznej nie są objęte bezpośrednią kontrolą zarządzania programem SQL Server, można je zmienić lub usunąć w dowolnym momencie przez proces zewnętrzny. W związku z tym wyniki zapytania względem tabeli zewnętrznej nie mają gwarancji, że są deterministyczne. To samo zapytanie może zwracać różne wyniki przy każdym uruchomieniu względem tabeli zewnętrznej. Podobnie zapytanie może zakończyć się niepowodzeniem, jeśli dane zewnętrzne zostaną przeniesione lub usunięte.
Można utworzyć wiele tabel zewnętrznych, które odwołują się do różnych zewnętrznych źródeł danych. Jeśli jednocześnie uruchamiasz zapytania względem różnych źródeł danych usługi Hadoop, każde źródło usługi Hadoop musi używać tego samego ustawienia konfiguracji serwera "hadoop connectivity". Na przykład nie można jednocześnie uruchomić zapytania względem klastra usługi Cloudera Hadoop i klastra Hortonworks Hadoop, ponieważ używają one różnych ustawień konfiguracji. Aby zapoznać się z ustawieniami konfiguracji i obsługiwanymi kombinacjami, zobacz Konfiguracja łączności programu PolyBase.
Gdy tabela zewnętrzna używa DELIMITEDTEXT, CSV, PARQUETlub DELTA jako typów danych, tabele zewnętrzne obsługują tylko statystyki dla jednej kolumny na CREATE STATISTICS polecenia.
Tylko te instrukcje języka definicji danych (DDL) są dozwolone w tabelach zewnętrznych:
- CREATE TABLE i DROP TABLE
- TWORZENIE STATYSTYK I USUWANIE STATYSTYK
- TWORZENIE WIDOKU I UPUSZCZANIA WIDOKU
Konstrukcje i operacje nie są obsługiwane:
- Ograniczenie DOMYŚLNE w kolumnach tabeli zewnętrznej
- Operacje języka manipulowania danymi (DML) usuwania, wstawiania i aktualizowania
Ograniczenia zapytań
Program PolyBase może używać maksymalnie 33 000 plików na folder podczas uruchamiania 32 współbieżnych zapytań programu PolyBase. Ta maksymalna liczba obejmuje zarówno pliki, jak i podfoldery w każdym folderze HDFS. Jeśli stopień współbieżności jest mniejszy niż 32, użytkownik może uruchamiać zapytania PolyBase względem folderów w systemie plików HDFS zawierających więcej niż 33 000 plików. Zalecamy, aby ścieżki plików zewnętrznych były krótkie i nie używać więcej niż 30 000 plików na folder HDFS. W przypadku przywołowania zbyt wielu plików może wystąpić wyjątek braku pamięci maszyny wirtualnej Java (JVM).
Ograniczenia szerokości tabeli
Program PolyBase w programie SQL Server 2016 ma limit szerokości wiersza wynoszący 32 KB na podstawie maksymalnego rozmiaru pojedynczego prawidłowego wiersza według definicji tabeli. Jeśli suma schematu kolumny jest większa niż 32 KB, program PolyBase nie może wykonywać zapytań dotyczących danych.
Ograniczenia typu danych
W tabelach zewnętrznych polyBase nie można używać następujących typów danych:
- geografii
- geometria
- hierarchyid
- obrazu
- tekst
- ntext
- xml
- Dowolny typ zdefiniowany przez użytkownika
Ograniczenia specyficzne dla źródła danych
Wyrocznia
Synonimy Oracle nie są obsługiwane w przypadku użycia z technologią PolyBase.
Tabele zewnętrzne kolekcji bazy danych MongoDB zawierające tablice
Aby utworzyć tabele zewnętrzne w kolekcjach bazy danych MongoDB, które zawierają tablice, należy użyć rozszerzenia Data Virtualization dla usługi Azure Data Studio w celu utworzenia instrukcji CREATE EXTERNAL TABLE na podstawie schematu wykrytego przez sterownik OdBC PolyBase dla bazy danych MongoDB. Akcje spłaszczania są wykonywane automatycznie przez sterownik. Alternatywnie można użyć sp_data_source_objects (Transact-SQL) do wykrywania schematu kolekcji (kolumn) i ręcznego tworzenia tabeli zewnętrznej. Procedura składowana sp_data_source_table_columns również automatycznie wykonuje spłaszczanie za pośrednictwem sterownika OdBC PolyBase dla sterownika MongoDB. Rozszerzenie Data Virtualization dla usługi Azure Data Studio i sp_data_source_table_columns używać tych samych wewnętrznych procedur składowanych do wykonywania zapytań względem schematu zewnętrznego.
Blokowania
Blokada udostępniona obiektu SCHEMARESOLUTION.
Bezpieczeństwo
Pliki danych dla tabeli zewnętrznej są przechowywane w usłudze Hadoop lub Azure Blob Storage. Te pliki danych są tworzone i zarządzane przez własne procesy. Twoim zadaniem jest zarządzanie zabezpieczeniami danych zewnętrznych.
Przykłady
A. Tworzenie tabeli zewnętrznej z danymi w formacie rozdzielanym tekstem
W tym przykładzie przedstawiono wszystkie kroki wymagane do utworzenia tabeli zewnętrznej, która ma dane sformatowane w plikach rozdzielanych tekstem. Definiuje zewnętrzne źródło danych mydatasource i format pliku zewnętrznego myfileformat. Te obiekty na poziomie bazy danych są następnie przywołyne w instrukcji CREATE EXTERNAL TABLE. Aby uzyskać więcej informacji, zobacz CREATE EXTERNAL DATA SOURCE i CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR ='|')
);
CREATE EXTERNAL TABLE ClickStream (
url varchar(50),
event_date date,
user_IP varchar(50)
)
WITH (
LOCATION='/webdata/employee.tbl',
DATA_SOURCE = mydatasource,
FILE_FORMAT = myfileformat
)
;
B. Tworzenie tabeli zewnętrznej z danymi w formacie RCFile
W tym przykładzie przedstawiono wszystkie kroki wymagane do utworzenia tabeli zewnętrznej, która ma dane sformatowane jako RCFiles. Definiuje zewnętrzne źródło danych mydatasource_rc i format pliku zewnętrznego myfileformat_rc. Te obiekty na poziomie bazy danych są następnie przywołyne w instrukcji CREATE EXTERNAL TABLE. Aby uzyskać więcej informacji, zobacz CREATE EXTERNAL DATA SOURCE i CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
)
;
CREATE EXTERNAL TABLE ClickStream_rc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/employee_rc.tbl',
DATA_SOURCE = mydatasource_rc,
FILE_FORMAT = myfileformat_rc
)
;
C. Tworzenie tabeli zewnętrznej z danymi w formacie ORC
W tym przykładzie przedstawiono wszystkie kroki wymagane do utworzenia tabeli zewnętrznej zawierającej dane sformatowane jako pliki ORC. Definiuje zewnętrzne źródło danych mydatasource_orc i zewnętrzny format pliku myfileformat_orc. Te obiekty na poziomie bazy danych są następnie przywołyne w instrukcji CREATE EXTERNAL TABLE. Aby uzyskać więcej informacji, zobacz CREATE EXTERNAL DATA SOURCE i CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
)
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
)
;
CREATE EXTERNAL TABLE ClickStream_orc (
url varchar(50),
event_date date,
user_ip varchar(50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
)
;
D. Wykonywanie zapytań dotyczących danych usługi Hadoop
ClickStream to tabela zewnętrzna łącząca się z employee.tbl rozdzielonym plikiem tekstowym w klastrze Hadoop. Poniższe zapytanie wygląda podobnie do zapytania względem standardowej tabeli. Jednak to zapytanie pobiera dane z usługi Hadoop, a następnie oblicza wyniki.
SELECT TOP 10 (url) FROM ClickStream WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Dołączanie danych usługi Hadoop przy użyciu danych SQL
To zapytanie wygląda podobnie jak standardowe join w dwóch tabelach SQL. Różnica polega na tym, że technologia PolyBase pobiera dane strumienia kliknięć z usługi Hadoop, a następnie łączy je z tabelą UrlDescription. Jedna tabela jest tabelą zewnętrzną, a druga jest standardową tabelą SQL.
SELECT url.description
FROM ClickStream cs
JOIN UrlDescription url ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Importowanie danych z usługi Hadoop do tabeli SQL
W tym przykładzie zostanie utworzona nowa tabela SQL ms_user, która trwale przechowuje wynik sprzężenia między standardową tabelą SQL user a tabelą zewnętrzną ClickStream.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. Tworzenie tabeli zewnętrznej dla programu SQL Server
Przed utworzeniem poświadczeń o zakresie bazy danych baza danych musi mieć klucz główny, aby chronić poświadczenia. Aby uzyskać więcej informacji, zobacz CREATE MASTER KEY i CREATE DATABASE SCOPED CREDENTIAL.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'S0me!nfo';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH IDENTITY = 'username', Secret = 'password';
GO
Utwórz nowe zewnętrzne źródło danych o nazwie SQLServerInstancei tabelę zewnętrzną o nazwie sqlserver.customer:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
GO
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer(
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
Ja. Tworzenie tabeli zewnętrznej dla programu Oracle
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name)
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. Note this may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_ORDERPRIORITY] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR(15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL(38) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='DB1.mySchema.customer',
DATA_SOURCE= external_data_source_name
);
J. Tworzenie tabeli zewnętrznej dla teradata
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. Tworzenie tabeli zewnętrznej dla bazy danych MongoDB
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH IDENTITY = 'username', Secret = 'password';
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. Wykonywanie zapytań względem magazynu obiektów zgodnego z usługą S3 za pośrednictwem tabeli zewnętrznej
Dotyczy: PROGRAMU SQL Server 2022 (16.x) i nowszych
W poniższym przykładzie pokazano użycie języka T-SQL do wykonywania zapytań względem pliku parquet przechowywanego w magazynie obiektów zgodnym z usługą S3 za pośrednictwem wykonywania zapytań względem tabeli zewnętrznej. W przykładzie użyto ścieżki względnej w zewnętrznym źródle danych.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/'
, CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat WITH(FORMAT_TYPE = PARQUET);
GO
CREATE EXTERNAL TABLE Region(
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152) )
WITH (LOCATION = '/region/', DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat);
GO
Następne kroki
Dowiedz się więcej o powiązanych pojęciach w następujących artykułach:
* Azure SQL Database *
Azure Synapse
analizy
Omówienie: Azure SQL Database
W usłudze Azure SQL Database tworzy tabelę zewnętrzną dla zapytań elastycznych (w wersji zapoznawczej).
Zobacz również CREATE EXTERNAL DATA SOURCE.
Składnia
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH ( <sharded_external_table_options> )
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name,
SCHEMA_NAME = N'nonescaped_schema_name',
OBJECT_NAME = N'nonescaped_object_name',
[DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN]]
)
[;]
Argumenty
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Jedna do trzech części nazwy tabeli do utworzenia. W przypadku tabeli zewnętrznej program SQL przechowuje tylko metadane tabeli wraz z podstawowymi statystykami dotyczącymi pliku lub folderu, do którego odwołuje się usługa Azure SQL Database. Żadne rzeczywiste dane nie są przenoszone ani przechowywane w usłudze Azure SQL Database.
Ważny
Aby uzyskać najlepszą wydajność, jeśli sterownik zewnętrznego źródła danych obsługuje trzyczęściową nazwę, zdecydowanie zaleca się podanie trzyczęściowej nazwy.
<column_definition> [ ,...n ]
FUNKCJA CREATE EXTERNAL TABLE obsługuje możliwość konfigurowania nazwy kolumny, typu danych, wartości null i sortowania. Nie można użyć domyślnego ograniczenia w tabelach zewnętrznych.
Nuta
tekst, ntext, xmli json typów danych nie są obsługiwane w przypadku kolumn w tabelach zewnętrznych dla usługi Azure SQL Database.
Definicje kolumn, w tym typy danych i liczba kolumn, muszą być zgodne z danymi w plikach zewnętrznych. Jeśli wystąpi niezgodność, wiersze pliku zostaną odrzucone podczas wykonywania zapytań dotyczących rzeczywistych danych.
Opcje tabeli zewnętrznej podzielone na fragmenty
Określa zewnętrzne źródło danych (źródło danych programu innego niż SQL Server) i metodę dystrybucji dla elastic query.
DATA_SOURCE
Klauzula DATA_SOURCE definiuje zewnętrzne źródło danych (mapę fragmentów), które jest używane dla tabeli zewnętrznej. Aby zapoznać się z przykładem, zobacz Create external tables (Tworzenie tabel zewnętrznych).
Ważny
Usługa Azure SQL Database obsługuje tworzenie tabel zewnętrznych do typów ZEWNĘTRZNYCH ŹRÓDEŁ DANYCH RDMS i SHARD_MAP_MANAGER. Usługa Azure SQL Database nie obsługuje tworzenia tabel zewnętrznych w usłudze Azure Blob Storage.
SCHEMA_NAME i OBJECT_NAME
Klauzule SCHEMA_NAME i OBJECT_NAME mapuje definicję tabeli zewnętrznej na tabelę w innym schemacie. Jeśli pominięto, przyjmuje się, że schemat obiektu zdalnego ma być "dbo", a jego nazwa jest taka sama jak zdefiniowana nazwa tabeli zewnętrznej. Jest to przydatne, jeśli nazwa tabeli zdalnej jest już zajęta w bazie danych, w której chcesz utworzyć tabelę zewnętrzną. Na przykład chcesz zdefiniować tabelę zewnętrzną, aby uzyskać zagregowany widok widoków wykazu lub widoków DMV w warstwie danych skalowanej w poziomie. Ponieważ widoki wykazu i dynamiczne widoki zarządzania już istnieją lokalnie, nie można używać ich nazw dla definicji tabeli zewnętrznej. Zamiast tego użyj innej nazwy i użyj nazwy widoku wykazu lub dynamicznego widoku zarządzania w klauzulach SCHEMA_NAME i/lub OBJECT_NAME. Aby zapoznać się z przykładem, zobacz Create external tables (Tworzenie tabel zewnętrznych).
DYSTRYBUCJA
Fakultatywny. Ten argument jest wymagany tylko dla baz danych typu SHARD_MAP_MANAGER. Ten argument określa, czy tabela jest traktowana jako tabela z fragmentami, czy też zreplikowana tabela. W przypadku tabel SHARDED (nazwa kolumny) dane z różnych tabel nie nakładają się. REPLIKOWANA określa, że tabele mają te same dane na każdym fragmentze. ROUND_ROBIN wskazuje, że do dystrybucji danych jest używana metoda specyficzna dla aplikacji.
Klauzula DISTRIBUTION określa dystrybucję danych używaną dla tej tabeli. Procesor zapytań wykorzystuje informacje podane w klauzuli DISTRIBUTION w celu utworzenia najbardziej wydajnych planów zapytań.
- SHARDED oznacza, że dane są partycjonowane w poziomie w bazach danych. Kluczem partycjonowania dla dystrybucji danych jest parametr
sharding_column_name. - REPLIKOWANE oznacza, że identyczne kopie tabeli znajdują się w każdej bazie danych. Twoim zadaniem jest zapewnienie, że repliki są identyczne w bazach danych.
- ROUND_ROBIN oznacza, że tabela jest partycjonowana poziomo przy użyciu metody dystrybucji zależnej od aplikacji.
Uprawnienia
Użytkownicy z dostępem do tabeli zewnętrznej automatycznie uzyskują dostęp do bazowych tabel zdalnych w ramach poświadczeń podanych w definicji zewnętrznego źródła danych. Unikaj niepożądanego podniesienia uprawnień za pośrednictwem poświadczeń zewnętrznego źródła danych. Użyj funkcji GRANT lub REVOKE dla tabeli zewnętrznej tak, jakby była to zwykła tabela. Po zdefiniowaniu zewnętrznego źródła danych i tabel zewnętrznych można teraz używać pełnego języka T-SQL w tabelach zewnętrznych.
Obsługa błędów
Podczas wykonywania instrukcji CREATE EXTERNAL TABLE, jeśli próba nawiązania połączenia zakończy się niepowodzeniem, instrukcja zakończy się niepowodzeniem, a tabela zewnętrzna nie zostanie utworzona. Wykonanie polecenia może potrwać co najmniej minutę, ponieważ usługa SQL Database ponawia próbę nawiązania połączenia, zanim ostatecznie zakończy się niepowodzeniem zapytania.
Uwagi
W scenariuszach zapytań ad hoc, takich jak SELECT FROM EXTERNAL TABLE, usługa SQL Database przechowuje wiersze pobierane z zewnętrznego źródła danych w tabeli tymczasowej. Po zakończeniu zapytania usługa SQL Database usuwa i usuwa tabelę tymczasową. Żadne trwałe dane nie są przechowywane w tabelach SQL.
Z kolei w scenariuszu importowania, takim jak SELECT INTO FROM EXTERNAL TABLE, usługa SQL Database przechowuje wiersze pobierane z zewnętrznego źródła danych jako trwałe dane w tabeli SQL. Nowa tabela jest tworzona podczas wykonywania zapytania, gdy usługa SQL Database pobiera dane zewnętrzne.
Można utworzyć wiele tabel zewnętrznych odwołujących się do tych samych lub różnych zewnętrznych źródeł danych.
Można utworzyć wiele tabel zewnętrznych, które odwołują się do różnych zewnętrznych źródeł danych.
Ograniczenia
semantyka izolacji: dostęp do danych za pośrednictwem tabeli zewnętrznej nie jest zgodny z semantyka izolacji w programie SQL Server. Oznacza to, że wykonywanie zapytań względem tabeli zewnętrznej nie powoduje nałożenia żadnej izolacji blokady ani migawki. W związku z tym zwracanie danych może ulec zmianie, jeśli dane w zewnętrznym źródle danych się zmieniają. To samo zapytanie może zwracać różne wyniki przy każdym uruchomieniu względem tabeli zewnętrznej. Podobnie zapytanie może zakończyć się niepowodzeniem, jeśli dane zewnętrzne zostaną przeniesione lub usunięte.
Konstrukcje i operacje nie są obsługiwane:
- Ograniczenie DOMYŚLNE w kolumnach tabeli zewnętrznej.
- Operacje języka manipulowania danymi (DML) usuwania, wstawiania i aktualizowania.
- dynamiczne maskowanie danych w kolumnach tabeli zewnętrznej.
- Kursory nie są obsługiwane w przypadku tabel zewnętrznych w usłudze Azure SQL Database.
Tylko predykaty literału: tylko predykaty literału zdefiniowane w zapytaniu mogą być wypychane do zewnętrznego źródła danych. Jest to w przeciwieństwie do serwerów połączonych i uzyskiwania dostępu do miejsc, w których predykaty określone podczas wykonywania zapytania mogą być używane, czyli w przypadku użycia z zagnieżdżonym pętlą w planie zapytania. Często prowadzi to do skopiowania całej tabeli zewnętrznej lokalnie, a następnie sprzężenia.
W poniższym przykładzie, jeśli
External.Ordersjest tabelą zewnętrzną, aCustomerjest tabelą lokalną, zapytanie kopiuje całą tabelę zewnętrzną lokalnie, ponieważ wymagana predykat nie jest znana w czasie kompilacji.SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );Brak równoległości: użycie tabel zewnętrznych uniemożliwia użycie równoległości w planie zapytania.
Wykonywane jako zapytanie zdalne: Tabele zewnętrzne są implementowane jako zapytanie zdalne, więc szacowana liczba zwracanych wierszy wynosi zazwyczaj 1000. Istnieją inne reguły oparte na typie predykatu używanego do filtrowania tabeli zewnętrznej. Są to oszacowania oparte na regułach, a nie oszacowania na podstawie rzeczywistych danych w tabeli zewnętrznej. Optymalizator nie uzyskuje dostępu do zdalnego źródła danych w celu uzyskania dokładniejszego oszacowania.
Nieobsługiwane w przypadku prywatnego punktu końcowego: zapytania tabeli zewnętrznej nie są obsługiwane, gdy połączenie z tabelą zdalną jest prywatnym punktem końcowym.
Ograniczenia typu danych
W tabelach zewnętrznych polyBase nie można używać następujących typów danych:
- geografii
- geometria
- hierarchyid
- obrazu
- tekst
- ntext
- xml
- Dowolny typ zdefiniowany przez użytkownika
Blokowania
Blokada udostępniona obiektu SCHEMARESOLUTION.
Przykłady
A. Tworzenie tabeli zewnętrznej dla usługi Azure SQL Database
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
( [CustomerID] [int] NOT NULL,
[CustomerName] [varchar](50) NOT NULL,
[Company] [varchar](50) NOT NULL)
WITH
( DATA_SOURCE = MyElasticDBQueryDataSrc)
B. Tworzenie tabeli zewnętrznej dla podzielonego na fragmenty źródła danych
W tym przykładzie ponownie mapuje zdalny widok DMV na tabelę zewnętrzną przy użyciu klauzul SCHEMA_NAME i OBJECT_NAME.
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]([session_id] smallint NOT NULL,
[request_id] int NOT NULL,
[start_time] datetime NOT NULL,
[status] nvarchar(30) NOT NULL,
[command] nvarchar(32) NOT NULL,
[sql_handle] varbinary(64),
[statement_start_offset] int,
[statement_end_offset] int,
[cpu_time] int NOT NULL)
WITH
(
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION=ROUND_ROBIN
);
Następne kroki
Dowiedz się więcej o tabelach zewnętrznych w usłudze Azure SQL Database w następujących artykułach:
* Azure Synapse
Analiza *
Omówienie: Azure Synapse Analytics
Użyj tabeli zewnętrznej, aby:
- Dedykowane pule SQL mogą wykonywać zapytania, importować i przechowywać dane z usług Hadoop, Azure Blob Storage i Azure Data Lake Storage Gen1 i Gen2.
- Bezserwerowe pule SQL mogą wykonywać zapytania, importować i przechowywać dane z usługi Azure Blob Storage, Azure Data Lake Storage Gen1 i Gen2. Bezserwerowe nie obsługuje
TYPE=Hadoop.
Zobacz również CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Aby uzyskać więcej wskazówek i przykładów dotyczących używania tabel zewnętrznych w usłudze Azure Synapse, zobacz
Składnia
-
dedykowanej puli SQL
- bezserwerowej puli SQL
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
Argumenty
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Jedna do trzech części nazwy tabeli do utworzenia. W przypadku tabeli zewnętrznej tylko metadane tabeli wraz z podstawowymi statystykami dotyczącymi pliku lub folderu, do którego odwołuje się usługa Azure Data Lake, Hadoop lub Azure Blob Storage. Podczas tworzenia tabel zewnętrznych nie są przenoszone ani przechowywane żadne rzeczywiste dane.
Ważny
Aby uzyskać najlepszą wydajność, jeśli sterownik zewnętrznego źródła danych obsługuje trzyczęściową nazwę, zdecydowanie zaleca się podanie trzyczęściowej nazwy.
<column_definition> [ ,...n ]
FUNKCJA CREATE EXTERNAL TABLE obsługuje możliwość konfigurowania nazwy kolumny, typu danych, wartości null i sortowania. Nie można użyć domyślnego ograniczenia w tabelach zewnętrznych.
Nuta
Typy danych tekst, ntexti xml nie są obsługiwane typy danych dla kolumn w tabelach zewnętrznych dla usługi Synapse Analytics.
- Podczas odczytywania plików rozdzielonych definicje kolumn, w tym typy danych i liczba kolumn, muszą być zgodne z danymi w plikach zewnętrznych. Jeśli wystąpi niezgodność, wiersze pliku zostaną odrzucone podczas wykonywania zapytań dotyczących rzeczywistych danych.
- Podczas odczytywania z plików Parquet można określić tylko kolumny, które chcesz odczytać i pominąć resztę.
LOCATION = 'folder_or_filepath'
Określa folder lub ścieżkę pliku i nazwę pliku dla rzeczywistych danych w usłudze Azure Data Lake, Hadoop lub Azure Blob Storage. Lokalizacja rozpoczyna się od folderu głównego. Folder główny to lokalizacja danych określona w zewnętrznym źródle danych. Instrukcja CREATE EXTERNAL TABLE AS SELECT tworzy ścieżkę i folder, jeśli nie istnieje.
CREATE EXTERNAL TABLE nie tworzy ścieżki i folderu.
Jeśli określisz lokalizację jako folder, zapytanie polyBase wybrane z tabeli zewnętrznej pobierze pliki z folderu i wszystkich jego podfolderów. Podobnie jak w usłudze Hadoop technologia PolyBase nie zwraca ukrytych folderów. Nie zwraca również plików, dla których nazwa pliku zaczyna się podkreśleniu (_) ani kropką (.).
Jeśli LOCATION='/webdata/'poniższego przykładu, zapytanie PolyBase zwróci wiersze z mydata.txt i mydata2.txt. Nie zwróci mydata3.txt, ponieważ znajduje się w podfolderze ukrytego folderu. I nie zwróci _hidden.txt, ponieważ jest to ukryty plik.
W przeciwieństwie do tabel zewnętrznych usługi Hadoop natywne tabele zewnętrzne nie zwracają podfolderów, chyba że określisz /** na końcu ścieżki. W tym przykładzie, jeśli LOCATION='/webdata/', zapytanie bezserwerowej puli SQL zwróci wiersze z mydata.txt. Nie zwróci mydata2.txt i mydata3.txt, ponieważ znajdują się one w podfolderze. Tabele usługi Hadoop będą zwracać wszystkie pliki w dowolnym podfolderze.
Zarówno usługa Hadoop, jak i natywne tabele zewnętrzne pomijają pliki z nazwami rozpoczynającymi się podkreśleniem (_) lub kropką (.).
DATA_SOURCE = external_data_source_name
Określa nazwę zewnętrznego źródła danych, które zawiera lokalizację danych zewnętrznych. Ta lokalizacja znajduje się w usłudze Azure Data Lake. Aby utworzyć zewnętrzne źródło danych, użyj CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Określa nazwę obiektu formatu pliku zewnętrznego, który przechowuje typ pliku i metodę kompresji dla danych zewnętrznych. Aby utworzyć format pliku zewnętrznego, użyj CREATE EXTERNAL FILE FORMAT.
TABLE_OPTIONS
Określa zestaw opcji opisujących sposób odczytywania plików bazowych. Obecnie jedyną dostępną opcją jest {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}, która nakazuje tabeli zewnętrznej ignorowanie aktualizacji w plikach bazowych, nawet jeśli może to spowodować niespójne operacje odczytu. Tej opcji należy używać tylko w specjalnych przypadkach, w których często dołączane pliki. Ta opcja jest dostępna w bezserwerowej puli SQL dla formatu CSV.
Opcje ODRZUĆ
Opcje odrzucania są dostępne w wersji zapoznawczej dla bezserwerowych pul SQL w usłudze Azure Synapse Analytics.
Tej opcji można używać tylko z zewnętrznymi źródłami danych, gdzie TYPE = HADOOP.
Można określić parametry odrzucenia, które określają, jak technologia PolyBase będzie obsługiwać zanieczyszczonych rekordów pobieranych z zewnętrznego źródła danych. Rekord danych jest uznawany za "zanieczyszczony", jeśli rzeczywiste typy danych lub liczba kolumn nie są zgodne z definicjami kolumn tabeli zewnętrznej.
Jeśli nie określisz ani nie zmienisz wartości odrzucania, program PolyBase używa wartości domyślnych. Te informacje o parametrach odrzucania są przechowywane jako dodatkowe metadane podczas tworzenia tabeli zewnętrznej za pomocą instrukcji CREATE EXTERNAL TABLE. Gdy przyszła instrukcja SELECT lub SELECT INTO wybierze dane z tabeli zewnętrznej, program PolyBase użyje opcji odrzucenia, aby określić liczbę lub procent wierszy, które mogą zostać odrzucone, zanim rzeczywiste zapytanie zakończy się niepowodzeniem. Zapytanie zwróci (częściowe) wyniki do momentu przekroczenia progu odrzucenia. Następnie kończy się niepowodzeniem z odpowiednim komunikatem o błędzie.
Opcja formatowania PARSER_VERSION jest obsługiwana tylko w bezserwerowych pulach SQL.
REJECT_TYPE = wartość | procent
Wyjaśnia, czy opcja REJECT_VALUE jest określona jako wartość literału, czy wartość procentowa.
wartości
REJECT_VALUE jest wartością literału, a nie wartością procentową. Zapytanie PolyBase zakończy się niepowodzeniem, gdy liczba odrzuconych wierszy przekroczy reject_value.
Jeśli na przykład REJECT_VALUE = 5 i REJECT_TYPE = wartość, zapytanie SELECT programu PolyBase zakończy się niepowodzeniem po odrzuceniu pięciu wierszy.
procent
REJECT_VALUE jest wartością procentową, a nie wartością literału. Zapytanie PolyBase zakończy się niepowodzeniem, gdy wartość procentowa wierszy, które zakończyły się niepowodzeniem, przekroczy reject_value. Procent wierszy, które zakończyły się niepowodzeniem, jest obliczany w odstępach czasu.
REJECT_VALUE = reject_value
Określa wartość lub procent wierszy, które można odrzucić przed niepowodzeniem zapytania.
- W przypadku REJECT_TYPE = wartość reject_value musi być liczbą całkowitą z zakresu od 0 do 2147 483 647.
- Dla REJECT_TYPE = procent, reject_value musi być zmiennoprzecinkowy z zakresu od 0 do 100. Wartość procentowa jest ważna tylko w przypadku dedykowanych pul SQL, w których
TYPE=HADOOP.
Zapytanie zakończy się niepowodzeniem, gdy liczba odrzuconych wierszy przekroczy reject_value. Jeśli na przykład REJECT_VALUE = 5 i REJECT_TYPE = wartość, zapytanie SELECT zakończy się niepowodzeniem po odrzuceniu pięciu wierszy.
REJECT_SAMPLE_VALUE = reject_sample_value
Ten atrybut jest wymagany podczas określania REJECT_TYPE = procent. Określa liczbę wierszy do pobrania przed ponownym obliczeniu wartości procentowej odrzuconych wierszy przez program PolyBase.
Parametr reject_sample_value musi być liczbą całkowitą z zakresu od 0 do 2 147 483 647.
Jeśli na przykład REJECT_SAMPLE_VALUE = 1000, program PolyBase obliczy procent nieudanych wierszy po próbie zaimportowania 1000 wierszy z pliku danych zewnętrznych. Jeśli procent nieudanych wierszy jest mniejszy niż reject_value, program PolyBase próbuje pobrać kolejne 1000 wierszy. Po podjęciu próby zaimportowania kolejnych 1000 wierszy w dalszym ciągu oblicza procent nieudanych wierszy.
Nuta
Ponieważ program PolyBase oblicza procent wierszy, które zakończyły się niepowodzeniem w odstępach czasu, rzeczywisty procent wierszy, które zakończyły się niepowodzeniem, może przekroczyć reject_value.
Przykład:
W tym przykładzie pokazano, jak trzy opcje ODRZUć współdziałają ze sobą. Jeśli na przykład REJECT_TYPE = procent, REJECT_VALUE = 30 i REJECT_SAMPLE_VALUE = 100, może wystąpić następujący scenariusz:
- Program PolyBase próbuje pobrać pierwsze 100 wierszy; 25 nie powiodło się i 75 powiodło się.
- Procent nieudanych wierszy jest obliczany jako 25%, który jest mniejszy niż wartość odrzucenia 30%. W związku z tym technologia PolyBase kontynuuje pobieranie danych z zewnętrznego źródła danych.
- Program PolyBase próbuje załadować kolejne 100 wierszy; tym razem 25 wierszy powiedzie się, a 75 wierszy zakończy się niepowodzeniem.
- Procent nieudanych wierszy jest ponownie obliczany jako 50%. Wartość procentowa nieudanych wierszy przekroczyła 30% wartość odrzucania.
- Zapytanie PolyBase kończy się niepowodzeniem z 50% odrzuconymi wierszami po próbie zwrócenia pierwszych 200 wierszy. Zwróć uwagę, że pasujące wiersze zostały zwrócone przed przekroczeniem progu odrzucenia przez zapytanie PolyBase.
REJECTED_ROW_LOCATION = lokalizacji katalogu
Określa katalog w zewnętrznym źródle danych, że odrzucone wiersze i odpowiedni plik błędu należy zapisać.
Jeśli określona ścieżka nie istnieje, zostanie utworzona. Zostanie utworzony katalog podrzędny o nazwie _rejectedrows. Znak _ gwarantuje, że katalog zostanie uniknięty dla innego przetwarzania danych, chyba że jawnie nazwany w parametrze location.
- W bezserwerowych pulach SQL ścieżka jest
YearMonthDay_HourMinuteSecond_StatementID. Możesz użyćstatementID, aby skorelować folder z zapytaniem, które je wygenerowało. - W dedykowanych pulach SQL utworzona ścieżka jest oparta na czasie przesyłania obciążenia w formacie
YearMonthDay -HourMinuteSecond, na przykład20180330-173205.
W tym folderze są zapisywane dwa typy plików, plik _reason i plik danych.
Aby uzyskać więcej informacji, zobacz CREATE EXTERNAL DATA SOURCE.
Pliki przyczyn i pliki danych mają identyfikator queryID skojarzony z instrukcją CTAS. Ponieważ dane i przyczyna znajdują się w oddzielnych plikach, odpowiadające im pliki mają pasujący sufiks.
W bezserwerowych pulach SQL plik error.json zawiera tablicę JSON z napotkanymi błędami związanymi z odrzuconymi wierszami. Każdy element reprezentujący błąd zawiera następujące atrybuty:
| Atrybut | Opis |
|---|---|
| Błąd | Przyczyna odrzucenia wiersza. |
| Szereg | Odrzucona liczba porządkowa wierszy w pliku. |
| Kolumna | Odrzucony numer porządkowy kolumny. |
| Wartość | Odrzucona wartość kolumny. Jeśli wartość jest większa niż 100 znaków, wyświetlane są tylko pierwsze 100 znaków. |
| Plik | Ścieżka do pliku, do którego należy wiersz. |
Uprawnienia
Wymaga następujących uprawnień użytkownika:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ZMIENIĆ DOWOLNY FORMAT PLIKU ZEWNĘTRZNEgo
Nuta
Uprawnienia KONTROLI BAZY DANYCH są wymagane do utworzenia tylko KLUCZA GŁÓWNEGO, POŚWIADCZEŃ O ZAKRESIE BAZY DANYCH i ZEWNĘTRZNEGO ŹRÓDŁA DANYCH
Należy pamiętać, że identyfikator logowania tworzący zewnętrzne źródło danych musi mieć uprawnienia do odczytu i zapisu w zewnętrznym źródle danych znajdującym się w usłudze Hadoop lub Azure Blob Storage.
Ważny
Uprawnienie ALTER ANY EXTERNAL DATA SOURCE przyznaje każdemu podmiotowi zabezpieczeń możliwość tworzenia i modyfikowania dowolnego zewnętrznego obiektu źródła danych, a w związku z tym przyznaje również możliwość dostępu do wszystkich poświadczeń w zakresie bazy danych. To uprawnienie musi być uznawane za wysoce uprzywilejowane i dlatego musi zostać przyznane tylko zaufanym podmiotom zabezpieczeń w systemie.
Obsługa błędów
Podczas wykonywania instrukcji CREATE EXTERNAL TABLE program PolyBase próbuje nawiązać połączenie z zewnętrznym źródłem danych. Jeśli próba nawiązania połączenia nie powiedzie się, instrukcja zakończy się niepowodzeniem, a tabela zewnętrzna nie zostanie utworzona. Wykonanie polecenia może potrwać co najmniej minutę, ponieważ program PolyBase ponawia próbę połączenia, zanim ostatecznie zakończy się niepowodzeniem zapytania.
Uwagi
W scenariuszach zapytań ad hoc, takich jak SELECT FROM EXTERNAL TABLE, polyBase przechowuje wiersze pobierane z zewnętrznego źródła danych w tabeli tymczasowej. Po zakończeniu wykonywania zapytania program PolyBase usuwa i usuwa tabelę tymczasową. Żadne trwałe dane nie są przechowywane w tabelach SQL.
Z kolei w scenariuszu importowania, takim jak SELECT INTO FROM EXTERNAL TABLE, program PolyBase przechowuje wiersze pobierane z zewnętrznego źródła danych jako trwałe dane w tabeli SQL. Nowa tabela jest tworzona podczas wykonywania zapytania, gdy program PolyBase pobiera dane zewnętrzne.
Technologia PolyBase może wypchnąć niektóre obliczenia zapytań do usługi Hadoop, aby zwiększyć wydajność zapytań. Ta akcja jest nazywana wypychanym predykatem. Aby ją włączyć, określ opcję lokalizacji menedżera zasobów usługi Hadoop w CREATE EXTERNAL DATA SOURCE.
Można utworzyć wiele tabel zewnętrznych odwołujących się do tych samych lub różnych zewnętrznych źródeł danych.
Zwróć uwagę na dane źródłowe przy użyciu sortowania UTF-8. W przypadku wszystkich danych źródłowych korzystających z sortowania UTF-8 należy ręcznie podać sortowanie inne niż UTF-8 każdej kolumny UTF-8 w instrukcji CREATE EXTERNAL TABLE. Dzieje się tak, ponieważ obsługa protokołu UTF-8 nie jest rozszerzana na tabele zewnętrzne. Podczas próby utworzenia tabeli zewnętrznej z sortowaniem UTF-8 zostanie wyświetlony komunikat o błędzie Unsupported collation. Jeśli sortowanie bazy danych tabeli zewnętrznej jest sortowaniem UTF-8, tworzenie tabeli zewnętrznej zakończy się niepowodzeniem, chyba że zostanie podane jawne sortowanie kolumn innych niż UTF-8, na przykład [UTF8_column] varchar(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL,.
Bezserwerowe i dedykowane pule SQL w usłudze Azure Synapse Analytics używają różnych baz kodu na potrzeby wirtualizacji danych. Bezserwerowe pule SQL obsługują natywną technologię wirtualizacji danych. Dedykowane pule SQL obsługują wirtualizację danych natywną i polyBase. Wirtualizacja danych programu PolyBase jest używana podczas tworzenia zewnętrznego źródła danych za pomocą TYPE=HADOOP.
Ograniczenia i ograniczenia
Ponieważ dane tabeli zewnętrznej nie są objęte bezpośrednią kontrolą zarządzania usługą Azure Synapse, można je zmienić lub usunąć w dowolnym momencie przez proces zewnętrzny. W związku z tym wyniki zapytania względem tabeli zewnętrznej nie mają gwarancji, że są deterministyczne. To samo zapytanie może zwracać różne wyniki przy każdym uruchomieniu względem tabeli zewnętrznej. Podobnie zapytanie może zakończyć się niepowodzeniem, jeśli dane zewnętrzne zostaną przeniesione lub usunięte.
Można utworzyć wiele tabel zewnętrznych, które odwołują się do różnych zewnętrznych źródeł danych.
Tylko te instrukcje języka definicji danych (DDL) są dozwolone w tabelach zewnętrznych:
- CREATE TABLE i DROP TABLE
- TWORZENIE STATYSTYK I USUWANIE STATYSTYK
- TWORZENIE WIDOKU I UPUSZCZANIA WIDOKU
Konstrukcje i operacje nie są obsługiwane:
- Ograniczenie DOMYŚLNE w kolumnach tabeli zewnętrznej
- Operacje języka manipulowania danymi (DML) usuwania, wstawiania i aktualizowania
- dynamiczne maskowanie danych w kolumnach tabeli zewnętrznej
Ograniczenia zapytań
Zaleca się, aby nie przekraczać więcej niż 30 000 plików na folder. W przypadku przywołowania zbyt wielu plików może wystąpić wyjątek braku pamięci maszyny wirtualnej Java (JVM), a wydajność może ulec pogorszeniu.
Ograniczenia szerokości tabeli
Program PolyBase w usłudze Azure Data Warehouse ma limit szerokości wiersza wynoszący 1 MB na podstawie maksymalnego rozmiaru pojedynczego prawidłowego wiersza według definicji tabeli. Jeśli suma schematu kolumny jest większa niż 1 MB, program PolyBase nie może wykonywać zapytań dotyczących danych.
Ograniczenia typu danych
W tabelach zewnętrznych polyBase nie można używać następujących typów danych:
- geografii
- geometria
- hierarchyid
- obrazu
- tekst
- ntext
- xml
- Dowolny typ zdefiniowany przez użytkownika
Blokowania
Blokada udostępniona obiektu SCHEMARESOLUTION.
Przykłady
A. Importowanie danych z usługi ADLS Gen 2 do usługi Azure Synapse Analytics
Przykłady dla usługi Gen ADLS Gen 1 można znaleźć w temacie
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>' ;
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH
(
FORMAT_TYPE = DELIMITEDTEXT
, FORMAT_OPTIONS ( FIELD_TERMINATOR = '|'
, STRING_DELIMITER = ''
, DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff'
, USE_TYPE_DEFAULT = FALSE
)
);
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
( [ProductKey] [int] NOT NULL,
[ProductLabel] nvarchar NULL,
[ProductName] nvarchar NULL )
WITH
(
LOCATION='/DimProduct/' ,
DATA_SOURCE = AzureDataLakeStore ,
FILE_FORMAT = TextFileFormat ,
REJECT_TYPE = VALUE ,
REJECT_VALUE = 0
);
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey] ) )
AS SELECT * FROM
[dbo].[DimProduct_external] ;
B. Importowanie danych z parquet do usługi Azure Synapse Analytics
Poniższy przykład tworzy tabelę zewnętrzną. Następnie zwraca pierwszy wiersz:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime varchar(20),
stateName varchar(100),
countyName varchar(100),
population int,
race varchar(50),
sex varchar(10),
minAge int,
maxAge int
)
WITH (
LOCATION = '/parquet/',
DATA_SOURCE = population_ds,
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 * FROM census_external_table;
Następne kroki
Dowiedz się więcej o tabelach zewnętrznych i powiązanych pojęciach w następujących artykułach:
Azure Synapse
analizy
* Analiza
System platformy (PDW) *
Omówienie: System platformy analizy
Użyj tabeli zewnętrznej, aby:
- Wykonywanie zapytań o dane usługi Hadoop lub Azure Blob Storage przy użyciu instrukcji Transact-SQL.
- Zaimportuj i zapisz dane z usługi Hadoop lub Azure Blob Storage do systemu platformy analizy.
Zobacz również CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Składnia
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = value | percentage,
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
}
Argumenty
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Jedna do trzech części nazwy tabeli do utworzenia. W przypadku tabeli zewnętrznej system platformy analizy przechowuje tylko metadane tabeli wraz z podstawowymi statystykami dotyczącymi pliku lub folderu, do którego odwołuje się usługa Hadoop lub Azure Blob Storage. Żadne rzeczywiste dane nie są przenoszone ani przechowywane w systemie platformy analizy.
Ważny
Aby uzyskać najlepszą wydajność, jeśli sterownik zewnętrznego źródła danych obsługuje trzyczęściową nazwę, zdecydowanie zaleca się podanie trzyczęściowej nazwy.
<column_definition> [ ,...n ]
FUNKCJA CREATE EXTERNAL TABLE obsługuje możliwość konfigurowania nazwy kolumny, typu danych, wartości null i sortowania. Nie można użyć domyślnego ograniczenia w tabelach zewnętrznych.
Definicje kolumn, w tym typy danych i liczba kolumn, muszą być zgodne z danymi w plikach zewnętrznych. Jeśli wystąpi niezgodność, wiersze pliku zostaną odrzucone podczas wykonywania zapytań dotyczących rzeczywistych danych.
LOCATION = 'folder_or_filepath'
Określa folder lub ścieżkę pliku i nazwę pliku dla rzeczywistych danych w usłudze Hadoop lub Azure Blob Storage. Lokalizacja rozpoczyna się od folderu głównego. Folder główny to lokalizacja danych określona w zewnętrznym źródle danych.
W systemie platformy analizy CREATE EXTERNAL TABLE AS SELECT instrukcja SELECT tworzy ścieżkę i folder, jeśli nie istnieje.
CREATE EXTERNAL TABLE nie tworzy ścieżki i folderu.
Jeśli określisz lokalizację jako folder, zapytanie polyBase wybrane z tabeli zewnętrznej pobierze pliki z folderu i wszystkich jego podfolderów. Podobnie jak w usłudze Hadoop technologia PolyBase nie zwraca ukrytych folderów. Nie zwraca również plików, dla których nazwa pliku zaczyna się podkreśleniu (_) ani kropką (.).
Jeśli LOCATION='/webdata/'poniższego przykładu, zapytanie PolyBase zwróci wiersze z mydata.txt i mydata2.txt. Nie zwróci mydata3.txt, ponieważ znajduje się w podfolderze ukrytego folderu. I nie zwróci _hidden.txt, ponieważ jest to ukryty plik.
Aby zmienić wartość domyślną i tylko odczytywać z folderu głównego, ustaw atrybut <polybase.recursive.traversal> na wartość "false" w pliku konfiguracji core-site.xml. Ten plik znajduje się w <SqlBinRoot>\PolyBase\Hadoop\Conf\ w katalogu głównym bin programu SQL Server. Na przykład C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\.
DATA_SOURCE = external_data_source_name
Określa nazwę zewnętrznego źródła danych, które zawiera lokalizację danych zewnętrznych. Ta lokalizacja jest usługą Hadoop lub Azure Blob Storage. Aby utworzyć zewnętrzne źródło danych, użyj CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Określa nazwę obiektu formatu pliku zewnętrznego, który przechowuje typ pliku i metodę kompresji dla danych zewnętrznych. Aby utworzyć format pliku zewnętrznego, użyj CREATE EXTERNAL FILE FORMAT.
Opcje odrzucania
Tej opcji można używać tylko z zewnętrznymi źródłami danych, gdzie TYPE = HADOOP.
Można określić parametry odrzucenia, które określają, jak technologia PolyBase będzie obsługiwać zanieczyszczonych rekordów pobieranych z zewnętrznego źródła danych. Rekord danych jest uznawany za "zanieczyszczony", jeśli rzeczywiste typy danych lub liczba kolumn nie są zgodne z definicjami kolumn tabeli zewnętrznej.
Jeśli nie określisz ani nie zmienisz wartości odrzucania, program PolyBase używa wartości domyślnych. Te informacje o parametrach odrzucania są przechowywane jako dodatkowe metadane podczas tworzenia tabeli zewnętrznej za pomocą instrukcji CREATE EXTERNAL TABLE. Gdy przyszła instrukcja SELECT lub SELECT INTO wybierze dane z tabeli zewnętrznej, program PolyBase użyje opcji odrzucenia, aby określić liczbę lub procent wierszy, które mogą zostać odrzucone, zanim rzeczywiste zapytanie zakończy się niepowodzeniem. Zapytanie zwróci (częściowe) wyniki do momentu przekroczenia progu odrzucenia. Następnie kończy się niepowodzeniem z odpowiednim komunikatem o błędzie.
REJECT_TYPE = wartość | procent
Wyjaśnia, czy opcja REJECT_VALUE jest określona jako wartość literału, czy wartość procentowa.
wartości
REJECT_VALUE jest wartością literału, a nie wartością procentową. Zapytanie PolyBase zakończy się niepowodzeniem, gdy liczba odrzuconych wierszy przekroczy reject_value.
Jeśli na przykład REJECT_VALUE = 5 i REJECT_TYPE = wartość, zapytanie SELECT programu PolyBase zakończy się niepowodzeniem po odrzuceniu pięciu wierszy.
procent
REJECT_VALUE jest wartością procentową, a nie wartością literału. Zapytanie PolyBase zakończy się niepowodzeniem, gdy wartość procentowa wierszy, które zakończyły się niepowodzeniem, przekroczy reject_value. Procent wierszy, które zakończyły się niepowodzeniem, jest obliczany w odstępach czasu.
REJECT_VALUE = reject_value
Określa wartość lub procent wierszy, które można odrzucić przed niepowodzeniem zapytania.
W przypadku REJECT_TYPE = wartość reject_value musi być liczbą całkowitą z zakresu od 0 do 2147 483 647.
Dla REJECT_TYPE = procent, reject_value musi być zmiennoprzecinkowy z zakresu od 0 do 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Ten atrybut jest wymagany podczas określania REJECT_TYPE = procent. Określa liczbę wierszy do pobrania przed ponownym obliczeniu wartości procentowej odrzuconych wierszy przez program PolyBase.
Parametr reject_sample_value musi być liczbą całkowitą z zakresu od 0 do 2 147 483 647.
Jeśli na przykład REJECT_SAMPLE_VALUE = 1000, program PolyBase obliczy procent nieudanych wierszy po próbie zaimportowania 1000 wierszy z pliku danych zewnętrznych. Jeśli procent nieudanych wierszy jest mniejszy niż reject_value, program PolyBase próbuje pobrać kolejne 1000 wierszy. Po podjęciu próby zaimportowania kolejnych 1000 wierszy w dalszym ciągu oblicza procent nieudanych wierszy.
Nuta
Ponieważ program PolyBase oblicza procent wierszy, które zakończyły się niepowodzeniem w odstępach czasu, rzeczywisty procent wierszy, które zakończyły się niepowodzeniem, może przekroczyć reject_value.
Przykład:
W tym przykładzie pokazano, jak trzy opcje ODRZUć współdziałają ze sobą. Jeśli na przykład REJECT_TYPE = procent, REJECT_VALUE = 30 i REJECT_SAMPLE_VALUE = 100, może wystąpić następujący scenariusz:
- Program PolyBase próbuje pobrać pierwsze 100 wierszy; 25 nie powiodło się i 75 powiodło się.
- Procent nieudanych wierszy jest obliczany jako 25%, który jest mniejszy niż wartość odrzucenia 30%. W związku z tym technologia PolyBase będzie kontynuować pobieranie danych z zewnętrznego źródła danych.
- Program PolyBase próbuje załadować kolejne 100 wierszy; tym razem 25 wierszy powiedzie się, a 75 wierszy zakończy się niepowodzeniem.
- Procent nieudanych wierszy jest ponownie obliczany jako 50%. Wartość procentowa nieudanych wierszy przekroczyła 30% wartość odrzucania.
- Zapytanie PolyBase kończy się niepowodzeniem z 50% odrzuconymi wierszami po próbie zwrócenia pierwszych 200 wierszy. Zwróć uwagę, że pasujące wiersze zostały zwrócone przed przekroczeniem progu odrzucenia przez zapytanie PolyBase.
Uprawnienia
Wymaga następujących uprawnień użytkownika:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ZMIENIĆ DOWOLNY FORMAT PLIKU ZEWNĘTRZNEgo
- CONTROL DATABASE
Należy pamiętać, że identyfikator logowania tworzący zewnętrzne źródło danych musi mieć uprawnienia do odczytu i zapisu w zewnętrznym źródle danych znajdującym się w usłudze Hadoop lub Azure Blob Storage.
Ważny
Uprawnienie ALTER ANY EXTERNAL DATA SOURCE przyznaje każdemu podmiotowi zabezpieczeń możliwość tworzenia i modyfikowania dowolnego zewnętrznego obiektu źródła danych, a w związku z tym przyznaje również możliwość dostępu do wszystkich poświadczeń w zakresie bazy danych. To uprawnienie musi być uznawane za wysoce uprzywilejowane i dlatego musi zostać przyznane tylko zaufanym podmiotom zabezpieczeń w systemie.
Obsługa błędów
Podczas wykonywania instrukcji CREATE EXTERNAL TABLE program PolyBase próbuje nawiązać połączenie z zewnętrznym źródłem danych. Jeśli próba nawiązania połączenia zakończy się niepowodzeniem, instrukcja zakończy się niepowodzeniem, a tabela zewnętrzna nie zostanie utworzona. Wykonanie polecenia może potrwać co najmniej minutę, ponieważ program PolyBase ponawia próbę połączenia, zanim ostatecznie zakończy się niepowodzeniem zapytania.
Uwagi
W scenariuszach zapytań ad hoc, takich jak SELECT FROM EXTERNAL TABLE, polyBase przechowuje wiersze pobierane z zewnętrznego źródła danych w tabeli tymczasowej. Po zakończeniu wykonywania zapytania program PolyBase usuwa i usuwa tabelę tymczasową. Żadne trwałe dane nie są przechowywane w tabelach SQL.
Z kolei w scenariuszu importowania, takim jak SELECT INTO FROM EXTERNAL TABLE, program PolyBase przechowuje wiersze pobierane z zewnętrznego źródła danych jako trwałe dane w tabeli SQL. Nowa tabela jest tworzona podczas wykonywania zapytania, gdy program PolyBase pobiera dane zewnętrzne.
Technologia PolyBase może wypchnąć niektóre obliczenia zapytań do usługi Hadoop, aby zwiększyć wydajność zapytań. Ta akcja jest nazywana wypychanym predykatem. Aby ją włączyć, określ opcję lokalizacji menedżera zasobów usługi Hadoop w CREATE EXTERNAL DATA SOURCE.
Można utworzyć wiele tabel zewnętrznych odwołujących się do tych samych lub różnych zewnętrznych źródeł danych.
Ograniczenia i ograniczenia
Ponieważ dane tabeli zewnętrznej nie są objęte bezpośrednią kontrolą zarządzania urządzeniem, można je zmienić lub usunąć w dowolnym momencie przez proces zewnętrzny. W związku z tym wyniki zapytania względem tabeli zewnętrznej nie mają gwarancji, że są deterministyczne. To samo zapytanie może zwracać różne wyniki przy każdym uruchomieniu względem tabeli zewnętrznej. Podobnie zapytanie może zakończyć się niepowodzeniem, jeśli dane zewnętrzne zostaną przeniesione lub usunięte.
Można utworzyć wiele tabel zewnętrznych, które odwołują się do różnych zewnętrznych źródeł danych. Jeśli jednocześnie uruchamiasz zapytania względem różnych źródeł danych usługi Hadoop, każde źródło usługi Hadoop musi używać tego samego ustawienia konfiguracji serwera "hadoop connectivity". Na przykład nie można jednocześnie uruchomić zapytania względem klastra usługi Cloudera Hadoop i klastra Hortonworks Hadoop, ponieważ używają one różnych ustawień konfiguracji. Aby zapoznać się z ustawieniami konfiguracji i obsługiwanymi kombinacjami, zobacz Konfiguracja łączności programu PolyBase.
Tylko te instrukcje języka definicji danych (DDL) są dozwolone w tabelach zewnętrznych:
- CREATE TABLE i DROP TABLE
- TWORZENIE STATYSTYK I USUWANIE STATYSTYK
- TWORZENIE WIDOKU I UPUSZCZANIA WIDOKU
Konstrukcje i operacje nie są obsługiwane:
- Ograniczenie DOMYŚLNE w kolumnach tabeli zewnętrznej
- Operacje języka manipulowania danymi (DML) usuwania, wstawiania i aktualizowania
- dynamiczne maskowanie danych w kolumnach tabeli zewnętrznej
Ograniczenia zapytań
Program PolyBase może używać maksymalnie 33 000 plików na folder podczas uruchamiania 32 współbieżnych zapytań programu PolyBase. Ta maksymalna liczba obejmuje zarówno pliki, jak i podfoldery w każdym folderze HDFS. Jeśli stopień współbieżności jest mniejszy niż 32, użytkownik może uruchamiać zapytania PolyBase względem folderów w systemie plików HDFS zawierających więcej niż 33 000 plików. Zalecamy, aby ścieżki plików zewnętrznych były krótkie i nie używać więcej niż 30 000 plików na folder HDFS. W przypadku przywołowania zbyt wielu plików może wystąpić wyjątek braku pamięci maszyny wirtualnej Java (JVM).
Ograniczenia szerokości tabeli
Program PolyBase w programie SQL Server 2016 ma limit szerokości wiersza wynoszący 32 KB na podstawie maksymalnego rozmiaru pojedynczego prawidłowego wiersza według definicji tabeli. Jeśli suma schematu kolumny jest większa niż 32 KB, program PolyBase nie może wykonywać zapytań dotyczących danych.
W usłudze Azure Synapse Analytics to ograniczenie zostało podniesione do 1 MB.
Ograniczenia typu danych
W tabelach zewnętrznych polyBase nie można używać następujących typów danych:
- geografii
- geometria
- hierarchyid
- obrazu
- tekst
- ntext
- xml
- Dowolny typ zdefiniowany przez użytkownika
Blokowania
Blokada udostępniona obiektu SCHEMARESOLUTION.
Bezpieczeństwo
Pliki danych dla tabeli zewnętrznej są przechowywane w usłudze Hadoop lub Azure Blob Storage. Te pliki danych są tworzone i zarządzane przez własne procesy. Twoim zadaniem jest zarządzanie zabezpieczeniami danych zewnętrznych.
Przykłady
A. Dołączanie danych systemu plików HDFS przy użyciu danych systemu platformy analizy
SELECT cs.user_ip FROM ClickStream cs
JOIN [User] u ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. Importowanie danych wierszy z systemu plików HDFS do rozproszonej tabeli systemu platformy analizy
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = HASH (url) )
AS SELECT url, event_date, user_ip FROM ClickStream;
C. Importowanie danych wierszy z systemu plików HDFS do zreplikowanej tabeli systemu platformy analizy
CREATE TABLE ClickStream_PDW
WITH ( DISTRIBUTION = REPLICATE )
AS SELECT url, event_date, user_ip
FROM ClickStream;
Następne kroki
Dowiedz się więcej o tabelach zewnętrznych w usłudze Analytics Platform System w następujących artykułach:
* Azure SQL Managed Instance *
Azure Synapse
analizy
Omówienie: Azure SQL Managed Instance
Tworzy tabelę danych zewnętrznych w usłudze Azure SQL Managed Instance. Aby uzyskać pełne informacje, zobacz Wirtualizacja danych za pomocą usługi Azure SQL Managed Instance.
Wirtualizacja danych w usłudze Azure SQL Managed Instance zapewnia dostęp do danych zewnętrznych w różnych formatach plików w usłudze Azure Data Lake Storage Gen2 lub Azure Blob Storage oraz do wykonywania zapytań za pomocą instrukcji języka T-SQL, nawet łączenia danych z lokalnie przechowywanymi danymi relacyjnymi przy użyciu sprzężeń.
Zobacz również CREATE EXTERNAL DATA SOURCE and DROP EXTERNAL TABLE.
Składnia
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
)
[;]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumenty
{ database_name.schema_name.table_name | schema_name.table_name | table_name }
Jedna do trzech części nazwy tabeli do utworzenia. W przypadku tabeli zewnętrznej tylko metadane tabeli wraz z podstawowymi statystykami dotyczącymi pliku lub folderu, do którego odwołuje się usługa Azure Data Lake lub Azure Blob Storage. Podczas tworzenia tabel zewnętrznych nie są przenoszone ani przechowywane żadne rzeczywiste dane.
Ważny
Aby uzyskać najlepszą wydajność, jeśli sterownik zewnętrznego źródła danych obsługuje trzyczęściową nazwę, zdecydowanie zaleca się podanie trzyczęściowej nazwy.
<column_definition> [ ,...n ]
FUNKCJA CREATE EXTERNAL TABLE obsługuje możliwość konfigurowania nazwy kolumny, typu danych, wartości null i sortowania. Nie można użyć domyślnego ograniczenia w tabelach zewnętrznych.
Definicje kolumn, w tym typy danych i liczba kolumn, muszą być zgodne z danymi w plikach zewnętrznych. Jeśli występuje niezgodność, wiersze pliku są odrzucane podczas wykonywania zapytań dotyczących rzeczywistych danych.
LOCATION = 'folder_or_filepath'
Określa folder lub ścieżkę pliku i nazwę pliku dla rzeczywistych danych w usłudze Azure Data Lake lub Azure Blob Storage. Lokalizacja rozpoczyna się od folderu głównego. Folder główny to lokalizacja danych określona w zewnętrznym źródle danych.
CREATE EXTERNAL TABLE nie tworzy ścieżki i folderu.
Jeśli określisz lokalizację jako folder, zapytanie z usługi Azure SQL Managed Instance wybrane z tabeli zewnętrznej pobierze pliki z folderu, ale nie wszystkie jego podfoldery.
Usługa Azure SQL Managed Instance nie może odnaleźć plików w podfolderach lub folderach ukrytych. Nie zwraca również plików, dla których nazwa pliku zaczyna się podkreśleniu (_) ani kropką (.).
Jeśli LOCATION='/webdata/'na poniższej ilustracji, zapytanie zwróci wiersze z mydata.txt. Nie zwróci mydata2.txt, ponieważ znajduje się w podfolderze, nie zwróci mydata3.txt, ponieważ znajduje się w ukrytym folderze i nie zwróci _hidden.txt, ponieważ jest to ukryty plik.
DATA_SOURCE = external_data_source_name
Określa nazwę zewnętrznego źródła danych, które zawiera lokalizację danych zewnętrznych. Ta lokalizacja znajduje się w usłudze Azure Data Lake. Aby utworzyć zewnętrzne źródło danych, użyj CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Określa nazwę obiektu formatu pliku zewnętrznego, który przechowuje typ pliku i metodę kompresji dla danych zewnętrznych. Aby utworzyć format pliku zewnętrznego, użyj CREATE EXTERNAL FILE FORMAT.
Uprawnienia
Wymaga następujących uprawnień użytkownika:
- CREATE TABLE
- ALTER ANY SCHEMA
- ALTER ANY EXTERNAL DATA SOURCE
- ZMIENIĆ DOWOLNY FORMAT PLIKU ZEWNĘTRZNEgo
Nuta
Uprawnienia KONTROLI BAZY DANYCH są wymagane do utworzenia tylko KLUCZA GŁÓWNEGO, POŚWIADCZEŃ O ZAKRESIE BAZY DANYCH i ZEWNĘTRZNEGO ŹRÓDŁA DANYCH
Należy pamiętać, że identyfikator logowania tworzący zewnętrzne źródło danych musi mieć uprawnienia do odczytu i zapisu w zewnętrznym źródle danych znajdującym się w usłudze Hadoop lub Azure Blob Storage.
Ważny
Uprawnienie ALTER ANY EXTERNAL DATA SOURCE przyznaje każdemu podmiotowi zabezpieczeń możliwość tworzenia i modyfikowania dowolnego zewnętrznego obiektu źródła danych, a w związku z tym przyznaje również możliwość dostępu do wszystkich poświadczeń w zakresie bazy danych. To uprawnienie musi być uznawane za wysoce uprzywilejowane i dlatego musi zostać przyznane tylko zaufanym podmiotom zabezpieczeń w systemie.
Uwagi
W scenariuszach zapytań ad hoc, takich jak SELECT FROM EXTERNAL TABLE, wiersze pobierane z zewnętrznego źródła danych są przechowywane w tabeli tymczasowej. Po zakończeniu zapytania wiersze zostaną usunięte, a tabela tymczasowa zostanie usunięta. Żadne trwałe dane nie są przechowywane w tabelach SQL.
Natomiast w scenariuszu importowania, takim jak SELECT INTO FROM EXTERNAL TABLE, wiersze pobierane z zewnętrznego źródła danych są przechowywane jako trwałe dane w tabeli SQL. Nowa tabela jest tworzona podczas wykonywania zapytania podczas pobierania danych zewnętrznych.
Obecnie wirtualizacja danych w usłudze Azure SQL Managed Instance jest tylko do odczytu.
Można utworzyć wiele tabel zewnętrznych odwołujących się do tych samych lub różnych zewnętrznych źródeł danych.
Ograniczenia i ograniczenia
Ponieważ dane tabeli zewnętrznej nie są objęte bezpośrednią kontrolą zarządzania usługą Azure SQL Managed Instance, można je zmienić lub usunąć w dowolnym momencie przez proces zewnętrzny. W związku z tym wyniki zapytania względem tabeli zewnętrznej nie mają gwarancji, że są deterministyczne. To samo zapytanie może zwracać różne wyniki przy każdym uruchomieniu względem tabeli zewnętrznej. Podobnie zapytanie może zakończyć się niepowodzeniem, jeśli dane zewnętrzne zostaną przeniesione lub usunięte.
Można utworzyć wiele tabel zewnętrznych, które odwołują się do różnych zewnętrznych źródeł danych.
Tylko te instrukcje języka definicji danych (DDL) są dozwolone w tabelach zewnętrznych:
- CREATE TABLE i DROP TABLE
- TWORZENIE STATYSTYK I USUWANIE STATYSTYK
- TWORZENIE WIDOKU I UPUSZCZANIA WIDOKU
Konstrukcje i operacje nie są obsługiwane:
- Ograniczenie DOMYŚLNE w kolumnach tabeli zewnętrznej
- Operacje języka manipulowania danymi (DML) usuwania, wstawiania i aktualizowania
Ograniczenia szerokości tabeli
Limit szerokości wiersza wynoszący 1 MB zależy od maksymalnego rozmiaru pojedynczego prawidłowego wiersza według definicji tabeli. Jeśli suma schematu kolumny jest większa niż 1 MB, zapytania wirtualizacji danych zakończy się niepowodzeniem.
Ograniczenia typu danych
Następujące typy danych nie mogą być używane w tabelach zewnętrznych w usłudze Azure SQL Managed Instance:
- geografii
- geometria
- hierarchyid
- obrazu
- tekst
- ntext
- xml
- json
- Dowolny typ zdefiniowany przez użytkownika
Blokowania
Blokada udostępniona obiektu SCHEMARESOLUTION.
Przykłady
A. Wykonywanie zapytań względem danych zewnętrznych z usługi Azure SQL Managed Instance przy użyciu tabeli zewnętrznej
Aby uzyskać więcej przykładów, zobacz Tworzenie zewnętrznego źródła danych lub zobacz Wirtualizacja danych za pomocą usługi Azure SQL Managed Instance.
Utwórz klucz główny bazy danych, jeśli nie istnieje.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<Strong Password>' GOUtwórz poświadczenie o zakresie bazy danych przy użyciu tokenu SAS. Możesz również użyć tożsamości zarządzanej.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>' ; --Removing leading '?' GOUtwórz zewnętrzne źródło danych przy użyciu poświadczeń.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] ) GOUtwórz format PLIKU ZEWNĘTRZNEgo i tabelę zewnętrzną, aby wykonywać zapytania dotyczące danych tak, jakby były to tabela lokalna.
-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE=PARQUET ) GO --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides( vendorID VARCHAR(100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR(8000), doLocationId VARCHAR(8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR(8000), paymentType VARCHAR(8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR(8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( LOCATION = 'yellow/puYear=*/puMonth=*/*.parquet', DATA_SOURCE = NYCTaxiExternalDataSource, FILE_FORMAT = MyFileFormat ); GO --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides; GO
Następne kroki
Dowiedz się więcej o tabelach zewnętrznych i powiązanych pojęciach w następujących artykułach: