Wyjaśnienie procesu fabryki danych
Przepływy pracy oparte na danych
Potoki (oparte na danych przepływy pracy) w usłudze Azure Data Factory zwykle wykonują następujące cztery kroki:
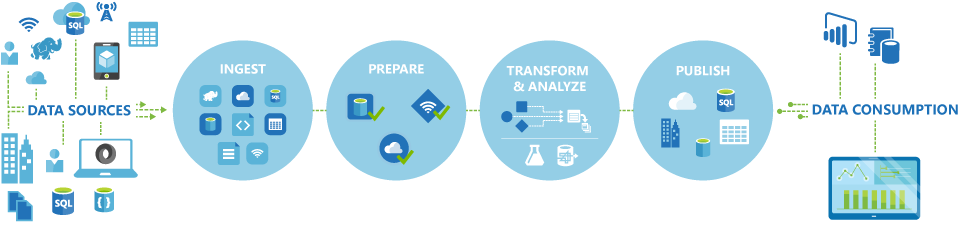
Łączenie i zbieranie
Pierwszym krokiem w tworzeniu systemu aranżacji jest zdefiniowanie i połączenie wszystkich wymaganych źródeł danych, takich jak bazy danych, udziały plików i usługi internetowe FTP. Następnym krokiem jest pozyskiwanie danych zgodnie z potrzebami do scentralizowanej lokalizacji na potrzeby późniejszego przetwarzania.
Przekształcanie i wzbogacanie
Usługi obliczeniowe, takie jak Databricks i Machine Learning, mogą służyć do przygotowywania lub tworzenia przekształconych danych zgodnie z konserwowanym i kontrolowanym harmonogramem w celu żywienia środowisk produkcyjnych przy użyciu oczyszczonych i przekształconych danych. W niektórych przypadkach można nawet rozszerzyć dane źródłowe o dodatkowe dane, aby ułatwić analizę, lub skonsolidować je za pomocą procesu normalizacji, który ma być używany w eksperymencie usługi Machine Learning jako przykład.
Publikowanie
Po uściśleniu danych pierwotnych w formie gotowej do działania biznesowego z fazy przekształcania i wzbogacania można załadować dane do usługi Azure Data Warehouse, Azure SQL Database, Azure Cosmos DB lub niezależnie od tego, do którego aparatu analitycznego mogą wskazywać użytkownicy biznesowi za pomocą narzędzi do analizy biznesowej
Monitor
Usługa Azure Data Factory ma wbudowaną obsługę monitorowania potoków za pośrednictwem usługi Azure Monitor, interfejsu API, programu PowerShell, dzienników usługi Azure Monitor i paneli kondycji w witrynie Azure Portal w celu monitorowania zaplanowanych działań i potoków pod kątem współczynników powodzenia i niepowodzeń.