Rozwiązywanie problemów z niską wydajnością SQL Server spowodowaną przez problemy z we/wy
Dotyczy: SQL Server
Ten artykuł zawiera wskazówki dotyczące problemów z we/wy, które powodują niską wydajność programu SQL Server i jak rozwiązywać problemy.
Definiowanie niskiej wydajności we/wy
Liczniki monitora wydajności służą do określania niskiej wydajności operacji we/wy. Te liczniki mierzą, jak szybko podsystem we/wy obsługuje każde żądanie we/wy średnio pod względem czasu zegara. Określone liczniki monitora wydajności, które mierzą opóźnienie we/wy w systemie Windows, to Avg Disk sec/ Read, Avg. Disk sec/Writei (skumulowane zarówno odczyty, jak i Avg. Disk sec/Transfer zapisy).
W programie SQL Server elementy działają w taki sam sposób. Często sprawdzasz, czy program SQL Server zgłasza jakiekolwiek wąskie gardła we/wy mierzone w czasie zegara (w milisekundach). Program SQL Server wysyła żądania we/wy do systemu operacyjnego, wywołując funkcje Win32, takie jak WriteFile(), ReadFile(), WriteFileGather()i ReadFileScatter(). Po opublikowaniu żądania we/wy program SQL Server razy wysyła żądanie i zgłasza czas trwania żądania przy użyciu typów oczekiwania. Program SQL Server używa typów oczekiwania, aby wskazać oczekiwania we/wy w różnych miejscach produktu. Oczekiwania związane z we/wy są następujące:
Jeśli te oczekiwania stale przekraczają 10–15 milisekund, we/wy jest uznawane za wąskie gardło.
Uwaga 16.
Aby zapewnić kontekst i perspektywę, w świecie rozwiązywania problemów z programem SQL Server arkusz CSS firmy Microsoft zaobserwował przypadki, w których żądanie we/wy przejęło jedną sekundę i nawet 15 sekund na system we/wy transferu wymaga optymalizacji. Z drugiej strony, arkusz CSS firmy Microsoft widział systemy, w których przepływność jest poniżej jednej milisekundy/transferu. Dzięki dzisiejszej technologii SSD/NVMe anonsowany zakres szybkości przepływności w dziesiątkach mikrosekund na transfer. W związku z tym wartość 10–15 milisekund/transferu jest bardzo przybliżonym progiem wybranym na podstawie zbiorowego doświadczenia między inżynierami systemu Windows i programu SQL Server na przestrzeni lat. Zwykle gdy liczby wykraczają poza ten przybliżony próg, użytkownicy programu SQL Server zaczynają widzieć opóźnienia w obciążeniach i zgłaszać je. Ostatecznie oczekiwana przepływność podsystemu we/wy jest definiowana przez producenta, model, konfigurację, obciążenie i potencjalnie wiele innych czynników.
Metodologia
Wykres blokowy na końcu tego artykułu opisuje metodologię używaną przez arkusze CSS firmy Microsoft do podejścia do powolnych problemów we/wy z programem SQL Server. Nie jest to wyczerpujące lub wyłączne podejście, ale okazało się przydatne w izolowaniu problemu i jego rozwiązaniu.
Aby rozwiązać ten problem, możesz wybrać jedną z następujących dwóch opcji:
Opcja 1. Wykonywanie kroków bezpośrednio w notesie za pośrednictwem programu Azure Data Studio
Uwaga 16.
Przed podjęciem próby otwarcia tego notesu upewnij się, że program Azure Data Studio jest zainstalowany na komputerze lokalnym. Aby go zainstalować, przejdź do artykułu Dowiedz się, jak zainstalować program Azure Data Studio.
Opcja 2. Wykonaj kroki ręcznie
Metodologia została opisana w następujących krokach:
Krok 1. Czy program SQL Server zgłasza powolne we/wy?
Program SQL Server może zgłaszać opóźnienie we/wy na kilka sposobów:
- Typy oczekiwania we/wy
- DMV
sys.dm_io_virtual_file_stats - Dziennik błędów lub dziennik zdarzeń aplikacji
Typy oczekiwania we/wy
Ustal, czy występują opóźnienia we/wy zgłaszane przez typy oczekiwania programu SQL Server. Wartości PAGEIOLATCH_*, WRITELOGi i ASYNC_IO_COMPLETION kilku innych mniej typowych typów oczekiwania powinny pozostać poniżej 10–15 milisekund na żądanie we/wy. Jeśli te wartości są bardziej spójne, istnieje problem z wydajnością we/wy i wymaga dalszego zbadania. Poniższe zapytanie może pomóc zebrać te informacje diagnostyczne w systemie:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
Statystyki plików w sys.dm_io_virtual_file_stats
Aby wyświetlić opóźnienie na poziomie pliku bazy danych zgodnie z raportem w programie SQL Server, uruchom następujące zapytanie:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
Przyjrzyj się kolumnom AvgLatency i, LatencyAssessment aby zrozumieć szczegóły opóźnienia.
Błąd 833 zgłoszony w dzienniku błędów lub dzienniku zdarzeń aplikacji
W niektórych przypadkach w dzienniku błędów może wystąpić błąd 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) . Dzienniki błędów programu SQL Server można sprawdzić w systemie, uruchamiając następujące polecenie programu PowerShell:
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
Aby uzyskać więcej informacji na temat tego błędu, zobacz sekcję MSSQLSERVER_833 .
Krok 2. Czy liczniki wydajności wskazują opóźnienie we/wy?
Jeśli program SQL Server zgłasza opóźnienie we/wy, zapoznaj się z licznikami systemu operacyjnego. Możesz określić, czy występuje problem z we/wy, sprawdzając licznik Avg Disk Sec/Transferopóźnień. Poniższy fragment kodu wskazuje jeden ze sposobów zbierania tych informacji za pomocą programu PowerShell. Zbiera liczniki na wszystkich woluminach dysków: "_total". Zmień na określony wolumin dysku (na przykład "D:"). Aby znaleźć woluminy hostowania plików bazy danych, uruchom następujące zapytanie w programie SQL Server:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
Zbierz Avg Disk Sec/Transfer metryki na wybranym woluminie:
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
Jeśli wartości tego licznika są stale powyżej 10–15 milisekund, należy dokładniej przyjrzeć się problemowi. Okazjonalne skoki nie są liczone w większości przypadków, ale pamiętaj, aby dokładnie sprawdzić czas trwania skoku. Jeśli skok trwał co najmniej jedną minutę, jest to więcej płaskowyż niż skok.
Jeśli liczniki monitora wydajności nie zgłaszają opóźnienia, ale program SQL Server, problem dotyczy programu SQL Server i Menedżera partycji, czyli sterowników filtrów. Menedżer partycji to warstwa we/wy, w której system operacyjny zbiera liczniki wydajności . Aby rozwiązać problemy z opóźnieniem, upewnij się, że występują odpowiednie wykluczenia sterowników filtrów i rozwiąż problemy ze sterownikiem filtru. Sterowniki filtrów są używane przez programy, takie jak oprogramowanie antywirusowe, rozwiązania do tworzenia kopii zapasowych, szyfrowanie, kompresja itd. Za pomocą tego polecenia można wyświetlić listę sterowników filtrów w systemach i woluminach, do których dołączają. Następnie możesz wyszukać nazwy sterowników i dostawców oprogramowania w artykule Przydzielone wysokości filtru .
fltmc instances
Aby uzyskać więcej informacji, zobacz Jak wybrać oprogramowanie antywirusowe do uruchamiania na komputerach z uruchomionym programem SQL Server.
Unikaj używania systemu szyfrowania plików (EFS) i kompresji systemu plików, ponieważ powodują one asynchroniczne operacje we/wy, aby stały się synchroniczne i w związku z tym wolniejsze. Aby uzyskać więcej informacji, zobacz asynchroniczny dysk we/wy jest wyświetlany jako synchroniczny w systemie Windows .
Krok 3. Czy podsystem we/wy jest przeciążony poza pojemnością?
Jeśli program SQL Server i system operacyjny wskazują, że podsystem we/wy jest powolny, sprawdź, czy przyczyną jest przeciążenie systemu poza pojemnością. Możesz sprawdzić pojemność, przeglądając liczniki we/wy Disk Bytes/Sec, Disk Read Bytes/Seclub Disk Write Bytes/Sec. Upewnij się, że zapoznaj się z administratorem systemu lub dostawcą sprzętu pod kątem oczekiwanych specyfikacji przepływności dla sieci SAN (lub innego podsystemu we/wy). Na przykład można wypchnąć nie więcej niż 200 MB/s operacji we/wy za pośrednictwem karty HBA 2 GB/s lub dedykowanego portu 2 GB/s na przełączniku SIECI SAN. Oczekiwana pojemność przepływności zdefiniowana przez producenta sprzętu definiuje sposób wykonywania tego działania.
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
Krok 4. Czy program SQL Server napędza duże działanie we/wy?
Jeśli podsystem we/wy jest przeciążony poza pojemnością, sprawdź, czy program SQL Server jest winowajcą, patrząc na Buffer Manager: Page Reads/Sec (najbardziej typową winowajcę) i Page Writes/Sec (o wiele mniej typową) dla konkretnego wystąpienia. Jeśli program SQL Server jest głównym sterownikiem we/wy i woluminem we/wy wykracza poza to, co system może obsłużyć, skontaktuj się z zespołami deweloperów aplikacji lub dostawcą aplikacji, aby:
- Dostrajanie zapytań, na przykład: lepsze indeksy, statystyki aktualizacji, ponowne zapisywanie zapytań i przeprojektowanie bazy danych.
- Zwiększ maksymalną pamięć serwera lub dodaj więcej pamięci RAM w systemie. Więcej pamięci RAM będzie buforować więcej stron danych lub indeksów bez częstego ponownego odczytywania z dysku, co zmniejszy aktywność operacji we/wy. Zwiększona ilość pamięci może również zmniejszyć
Lazy Writes/secwartość , która jest napędzana przez opróżnianie modułu zapisywania z opóźnieniem, gdy często trzeba przechowywać więcej stron bazy danych w ograniczonej dostępnej pamięci. - Jeśli okaże się, że zapisy stron są źródłem dużego działania we/wy, sprawdź
Buffer Manager: Checkpoint pages/sec, czy jest to spowodowane ogromnymi opróżnieniami stron wymaganymi do spełnienia wymagań konfiguracji interwału odzyskiwania. Możesz użyć pośrednich punktów kontrolnych, aby wyrównać liczbę operacji we/wy w czasie lub zwiększyć przepływność operacji we/wy sprzętu.
Przyczyny
Ogólnie rzecz biorąc, następujące problemy są ogólnymi przyczynami, dla których zapytania programu SQL Server cierpią z powodu opóźnień we/wy:
Problemy sprzętowe:
Błędna konfiguracja sieci SAN (przełącznik,, HBA, magazyn)
Przekroczono pojemność we/wy (niezrównoważone w całej sieci SAN, a nie tylko magazyn zaplecza)
Problemy ze sterownikami lub oprogramowaniem układowym
Dostawcy sprzętu i/lub administratorzy systemu muszą być zaangażowani na tym etapie.
Problemy z zapytaniami: program SQL Server saturuje woluminy dysków przy użyciu żądań we/wy i wypycha podsystem we/wy poza pojemność, co powoduje wysokie szybkości transferu we/wy. W takim przypadku rozwiązaniem jest znalezienie zapytań, które powodują dużą liczbę odczytów logicznych (lub zapisów), a następnie dostrojenie tych zapytań w celu zminimalizowania operacji we/wy dysku przy użyciu odpowiednich indeksów jest pierwszym krokiem do tego. Ponadto zachowaj zaktualizowane statystyki, ponieważ udostępniają optymalizatorowi zapytań wystarczające informacje, aby wybrać najlepszy plan. Ponadto niepoprawny projekt bazy danych i projekt zapytań mogą prowadzić do zwiększenia liczby problemów z we/wy. W związku z tym przeprojektowanie zapytań i czasami tabel może pomóc w ulepszaniu operacji we/wy.
Sterowniki filtrów: Odpowiedź we/wy programu SQL Server może mieć poważny wpływ, jeśli sterowniki filtrów systemu plików przetwarzają duży ruch we/wy. Zaleca się prawidłowe wykluczenia plików ze skanowania antywirusowego i poprawnego projektowania sterowników filtrów przez dostawców oprogramowania, aby zapobiec wpływowi na wydajność operacji we/wy.
Inne aplikacje: Inna aplikacja na tej samej maszynie z programem SQL Server może saturacji ścieżki we/wy z nadmiernymi żądaniami odczytu lub zapisu. Taka sytuacja może spowodować wypchnięcie podsystemu we/wy poza limity pojemności i spowodować spowolnienie we/wy dla programu SQL Server. Zidentyfikuj aplikację i dostosuj ją lub przenieś w innym miejscu, aby wyeliminować jej wpływ na stos we/wy.
Graficzna reprezentacja metodologii
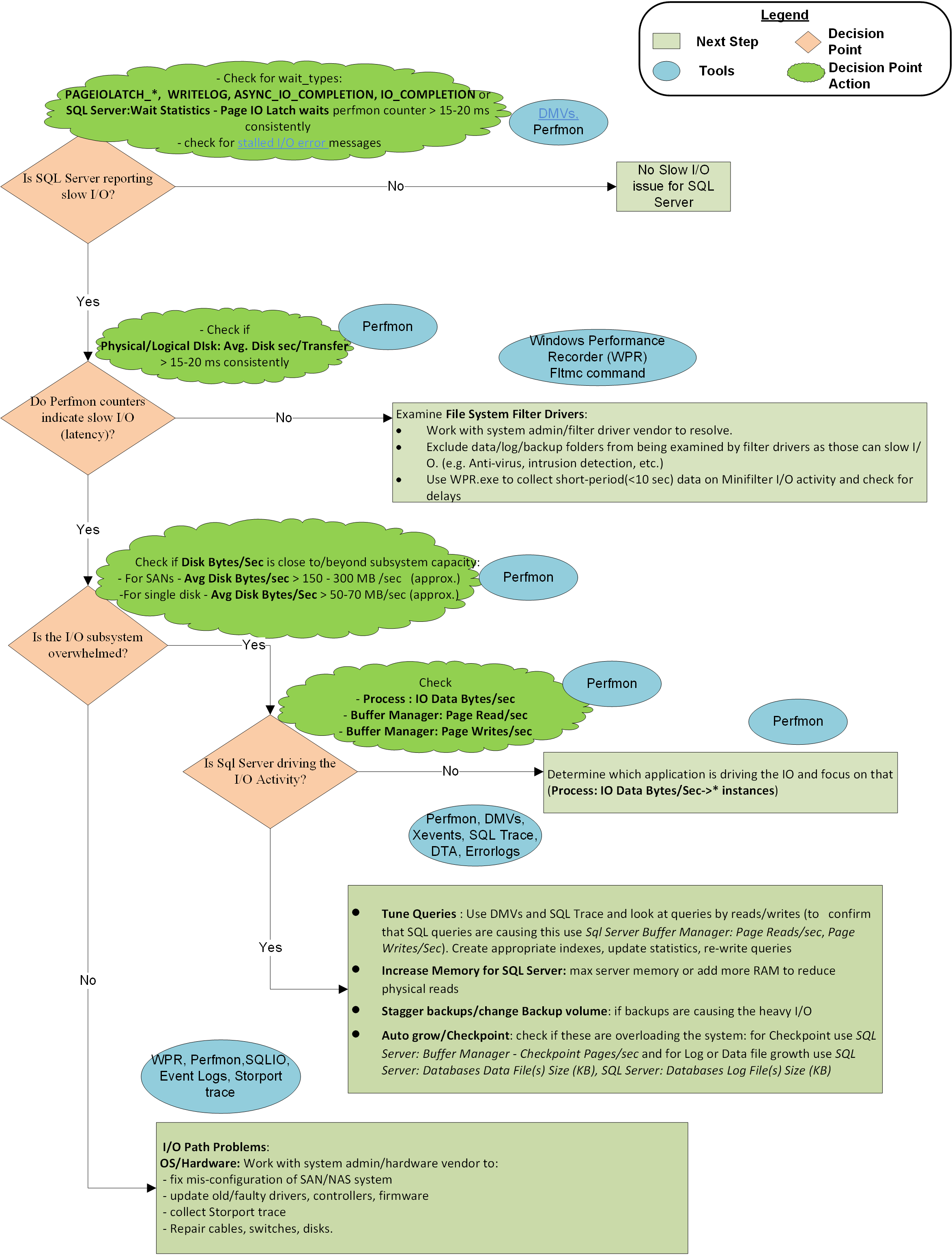
Informacje o typach oczekiwania związanych z we/wy
Poniżej przedstawiono opisy typowych typów oczekiwania obserwowanych w programie SQL Server w przypadku zgłaszania problemów z we/wy dysku.
PAGEIOLATCH_EX
Występuje, gdy zadanie czeka na zatrzasku dla strony danych lub indeksu (bufor) w żądaniu we/wy. Żądanie zatrzaszania jest w trybie wyłącznym. Tryb wyłączny jest używany, gdy bufor jest zapisywany na dysku. Długie oczekiwania mogą wskazywać na problemy z podsystemem dysków.
PAGEIOLATCH_SH
Występuje, gdy zadanie czeka na zatrzasku dla strony danych lub indeksu (bufor) w żądaniu we/wy. Żądanie zatrzaszania jest w trybie udostępnionym. Tryb udostępniony jest używany, gdy bufor jest odczytywany z dysku. Długie oczekiwania mogą wskazywać na problemy z podsystemem dysków.
PAGEIOLATCH_UP
Występuje, gdy zadanie czeka na zatrzask buforu w żądaniu we/wy. Żądanie zatrzaszania jest w trybie aktualizacji. Długie oczekiwania mogą wskazywać na problemy z podsystemem dysków.
WRITELOG
Występuje, gdy zadanie oczekuje na ukończenie dziennika transakcji. Opróżnienie występuje, gdy Menedżer dzienników zapisuje jego tymczasową zawartość na dysku. Typowe operacje, które powodują opróżnienia dzienników, to zatwierdzenia transakcji i punkty kontrolne.
Typowe przyczyny długich WRITELOG oczekiwań są następujące:
Opóźnienie dysku dziennika transakcji: jest to najczęstsza przyczyna
WRITELOGoczekiwania. Ogólnie rzecz biorąc, zaleca się przechowywanie danych i plików dziennika na oddzielnych woluminach. Zapisy dziennika transakcji są zapisami sekwencyjnymi podczas odczytywania lub zapisywania danych z pliku danych jest losowe. Mieszanie plików danych i dzienników na jednym woluminie dysku (zwłaszcza konwencjonalnych obracających się dysków) spowoduje nadmierne przesunięcie głowy dysku.Zbyt wiele plików VFS: zbyt wiele plików dziennika wirtualnego może powodować
WRITELOGoczekiwania. Zbyt wiele VDF może powodować inne typy problemów, takich jak długie odzyskiwanie.Zbyt wiele małych transakcji: podczas gdy duże transakcje mogą prowadzić do blokowania, zbyt wiele małych transakcji może prowadzić do innego zestawu problemów. Jeśli transakcja nie zostanie jawnie rozpoczęta, żadne operacje wstawiania, usuwania lub aktualizacji spowodują transakcję (wywołamy tę automatyczną transakcję). Jeśli zrobisz 1000 wstawień w pętli, zostanie wygenerowanych 1000 transakcji. Każda transakcja w tym przykładzie musi zatwierdzić, co powoduje opróżnienie dziennika transakcji i opróżnienie 1000 transakcji. Jeśli to możliwe, pogrupuj pojedynczą aktualizację, usuń lub wstaw do większej transakcji, aby zmniejszyć liczbę opróżnień dziennika transakcji i zwiększyć wydajność. Ta operacja może prowadzić do mniejszej liczby
WRITELOGoczekiwań.Problemy z planowaniem powodują, że wątki składnika zapisywania dzienników nie będą wystarczająco szybko zaplanowane: przed programem SQL Server 2016 pojedynczy wątek składnika zapisywania dzienników wykonał wszystkie zapisy dziennika. Jeśli wystąpiły problemy z planowaniem wątków (na przykład wysokie użycie procesora CPU), zarówno wątek modułu zapisywania dziennika, jak i opróżnienia dziennika mogą zostać opóźnione. W programie SQL Server 2016 dodano do czterech wątków modułu zapisywania dzienników w celu zwiększenia przepływności zapisywania dzienników. Zobacz SQL 2016 — działa po prostu szybciej: wiele procesów zapisywania dzienników. W programie SQL Server 2019 dodano maksymalnie osiem wątków modułu zapisywania dzienników, co zwiększa przepływność. Ponadto w programie SQL Server 2019 każdy zwykły wątek roboczy może wykonywać operacje zapisu dziennika bezpośrednio zamiast publikować w wątku modułu zapisywania dzienników. W przypadku tych ulepszeń
WRITELOGoczekiwania rzadko będą wyzwalane przez problemy z planowaniem.
ASYNC_IO_COMPLETION
Występuje w przypadku wystąpienia niektórych z następujących działań we/wy:
- Dostawca operacji wstawiania zbiorczego ("Wstaw zbiorczo") używa tego typu oczekiwania podczas wykonywania operacji we/wy.
- Odczytywanie pliku Cofnij w usłudze LogShipping i kierowanie asynchronicznego we/wy na potrzeby wysyłania dziennika.
- Odczytywanie rzeczywistych danych z plików danych podczas tworzenia kopii zapasowej danych.
IO_COMPLETION
Występuje podczas oczekiwania na ukończenie operacji we/wy. Ten typ oczekiwania zwykle obejmuje operacje we/wy niezwiązane ze stronami danych (). Oto kilka przykładów:
- Odczytywanie i zapisywanie wyników sortowania/skrótu z/do dysku podczas rozlania (sprawdź wydajność magazynu bazy danych tempdb ).
- Odczytywanie i zapisywanie chętnych na dysku (sprawdź magazyn tempdb ).
- Odczytywanie bloków dziennika z dziennika transakcji (podczas każdej operacji, która powoduje odczyt dziennika z dysku — na przykład odzyskiwanie).
- Odczytywanie strony z dysku, gdy baza danych nie jest jeszcze skonfigurowana.
- Kopiowanie stron do migawki bazy danych (kopiowanie na zapis).
- Zamykanie pliku bazy danych i pliku nieskompresji.
BACKUPIO
Występuje, gdy zadanie tworzenia kopii zapasowej oczekuje na dane lub oczekuje na bufor do przechowywania danych. Ten typ nie jest typowy, z wyjątkiem sytuacji, gdy zadanie czeka na instalację taśmy.