Transaction Commit latency acceleration using Storage Class Memory in Windows Server 2016/SQL Server 2016 SP1
SQL Server 2016 SP1 adds a significant new performance feature, the ability to accelerate transaction commit times (latency) by up to 2-4X, when employing Storage Class Memory (NVDIMM-N nonvolatile storage). This scenario is also referred to as “persistent log buffer” as explained below.
This enhancement is especially valuable for workloads which require high frequency, low latency update transactions. These app patterns are common in the finance/trading industry as well as online betting and some process control applications.
One of the most significant performance bottlenecks for low latency OLTP transactions is writing to the transaction log. This is especially true when employing In-Memory OLTP tables which remove most other bottlenecks from high update rate applications. This feature works to remove that final bottleneck from the overall system, enabling stunning increases in overall speed. Previously, customers that needed these transaction speeds leveraged features such as delayed durability (grouping several transaction commits into a single write, which amortizes the IO overhead, but can put a small number of commits at risk if the write fails after the commit is acknowledged), or In-Memory OLTP with non-durable tables for applications where durability is not required, such as ASP Session state cache, or the midpoint in an ETL pipeline, where the data source can be recreated.
Results:
As a sample of the results obtained, in one simple end to end SQL example of an In-Memory OLTP application, we compared the results when the transaction log was located on NVMe SSD (the fastest class of non-memory storage), against the same configuration with the SCM persistent log buffer configured. Each configuration was run for 20 seconds to collect throughput information:
| Rows Updated | Updates per second | Avg. time per transaction (ms) | |
| Log on NVMe | 1,226,069 | 63,214 | 0.380 |
| Log on NVMe withSCM persistent log buffer | 2,509,273 | 125,417 | 0.191 |
As you can see, the persistent log buffer configuration was approximately 2X faster than putting the log on the fastest available storage. You can see the full video of this demo here:
https://channel9.msdn.com/Shows/Data-Exposed/SQL-Server-2016-and-Windows-Server-2016-SCM--FAST
How it works:
Storage Class Memory is surfaced by Windows Server 2016 as a disk device with special characteristics. When the filesystem is formatted as Direct Access Mode (DAX), the operating system allows byte-level access to this persistent memory.
SQL Server assembles transaction log records in a buffer, and flushes them out to durable media during commit processing. SQL will not complete the commit until the commit log record is durably stored on media. This hard flush can delay processing in very high transaction rate (low latency) systems.
With this new functionality, we use a region of memory which is mapped to a file on a DAX volume to hold that buffer. Since the memory hosted by the DAX volume is already persistent, we have no need to perform a separate flush, and can immediately continue with processing the next operation. Data is flushed from this buffer to more traditional storage in the background.
Example
The first diagram shows how traditional log processing works. Log records are copied into a buffer in memory until either the buffer is filled, or a commit record is encountered. When a commit record is encountered, the buffer must immediately be written to disk in the transaction log file, in order to complete the commit operation. This happens regardless of how full the log buffer is. If another commit comes in during the IO processing, it waits until the IO is complete.
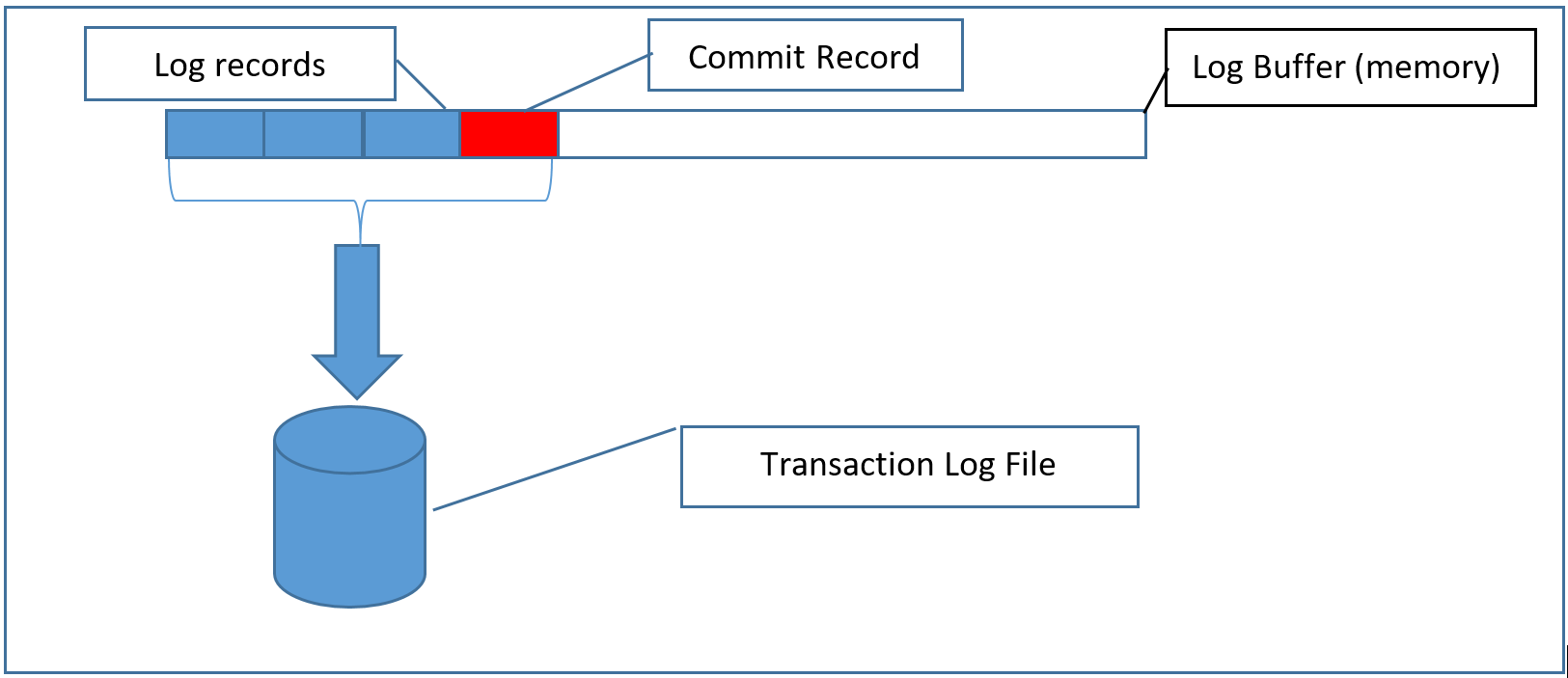
With this new feature, the log records are fully durable as soon as they are copied into the log buffer, so there is no need to write them to disk immediately. This means that you can collect potentially many commits into the same IO, which is the same as is done with Delayed Durability, but with the difference that there is no exposure to data loss. The log buffer is written to the transaction log when it fills up, just as it would if there didn’t happen to be any commit records in the stream before the buffer filled up.
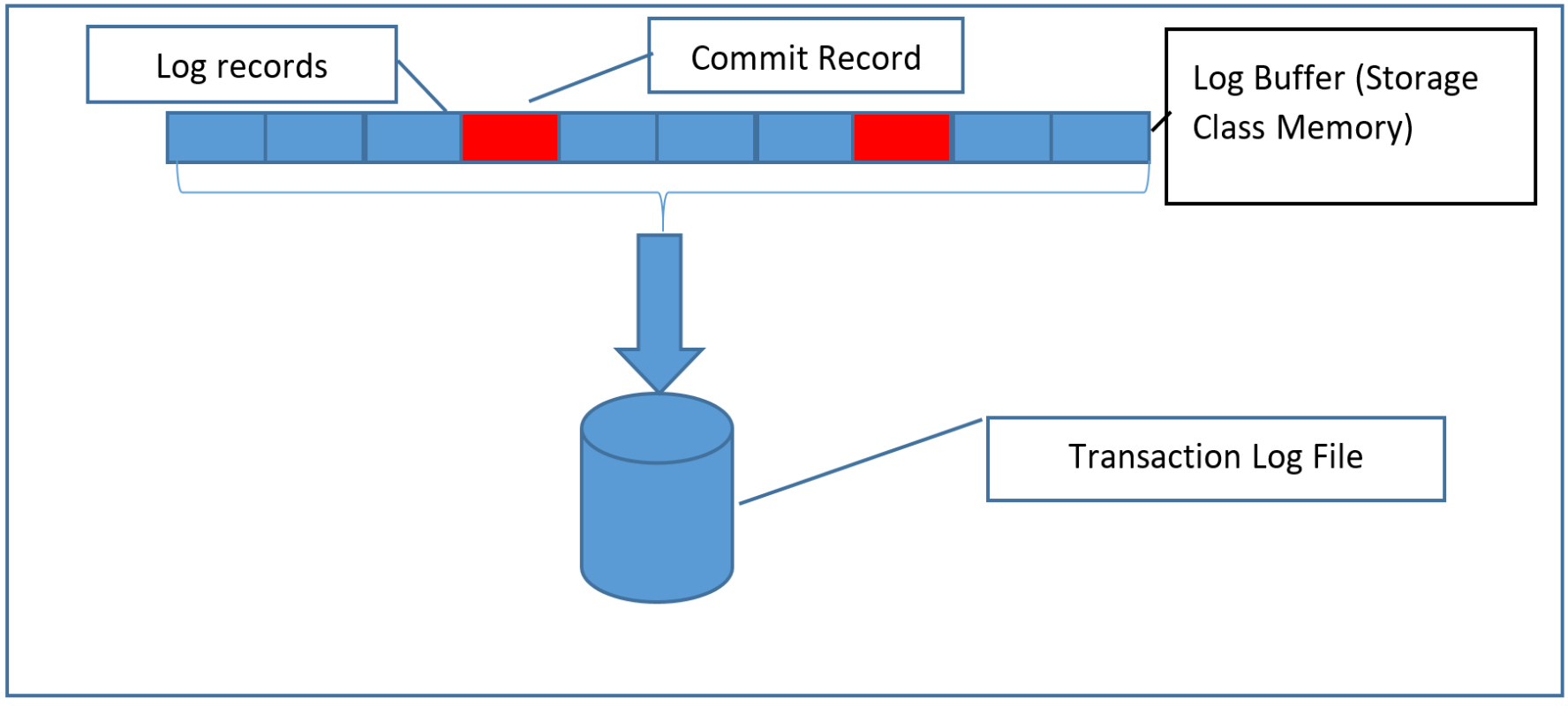
{kind=link}
{kind=link}
Setting it up:
First, the SCM must be setup and surfaced as a volume. The storage should automatically be surfaced as a volume in Windows, and can be identified using the Powershell command:
PS C:\Windows\system32> Get-PhysicalDisk | select bustype, healthstatus, size | sort bustype
BusType HealthStatus size
------- ------------ ----
NVMe Healthy 1600321314816
NVMe Healthy 1601183940608
RAID Healthy 960197124096
RAID Healthy 300000000000
RAID Healthy 960197124096
SATA Healthy 960197124096
SATA Healthy 500107862016
SATA Healthy 960197124096
SATA Healthy 500107862016
SCM Healthy 8580476928
SCM Healthy 8580464640
Disks that are Storage Class Memory are reported as BusType SCM.
You can then format the volume using the /dax option to the format command as documented here: https://technet.microsoft.com/windows-server-docs/management/windows-commands/format
You can verify that the SCM based volume was formatted for DAX access using the command:
PS C:\Windows\system32> fsutil fsinfo volumeinfo d:
Volume Name : DirectAccess (DAX) NVDIMM
Volume Serial Number : 0xc6a4c99a
Max Component Length : 255
File System Name : NTFS
Is ReadWrite
Supports Case-sensitive filenames
Preserves Case of filenames
Supports Unicode in filenames
Preserves & Enforces ACL's
Supports Disk Quotas
Supports Reparse Points
Supports Object Identifiers
Supports Named Streams
Supports Hard Links
Supports Extended Attributes
Supports Open By FileID
Supports USN Journal
Is DAX volume
PS C:\Windows\system32>
Once the SCM volume is properly set up and formatted as a DAX volume all that remains is to add a new log file to the database using the same syntax as any other log file, where the file resides on the DAX volume. The log file on the DAX volume will be sized at 20MB regardless of the size specified with the ADD FILE command:
ALTER DATABASE <MyDB> ADD LOG FILE (NAME = <DAXlog>, FILENAME = ‘<Filepath to DAX Log File>’, SIZE = 20 MB
Disabling the persistent log buffer feature
In order to disable the persistent log buffer feature, all that is required is to remove the log file from the DAX volume:
ALTER DATABASE <MyDB> SET SINGLE_USER ALTER DATABASE <MyDB> REMOVE FILE <DAXlog> ALTER DATABASE <MyDB> SET MULTI_USER
Any log records being kept in the log buffer will be written to disk, and at that point there is no unique data in the persistent log buffer, so it can be safely removed.
Interactions with other features and operations
Log file IO
The only impact on the log file IO is that we will tend to pack the log buffers fuller, so we will do fewer IOs to process the same amount of data, thus making the IO pattern more efficient.
Backup/Restore
Backup/Restore operates normally. If the target system does not have a DAX volume at the same path as the source system, the file will be created, but will not be used, since the SCM prerequisite isn’t met. That file can be safely removed.
If there is a DAX volume at the same path as the source system, the file will function in persistent log buffer mode on the restored database.
If the target system has a DAX volume at a different path than the source system, the database can be restored using the WITH MOVE option to locate the persistent log buffer file to the correct path on the target system.
Transparent Database Encryption (TDE)
Because this feature puts log records in durable media immediately from the processor, there is no opportunity to encrypt the data before it is on durable media. For this reason, TDE and this feature are mutually exclusive; you can enable this feature, or TDE, but not both together.
Always On Availability Groups
Because the Availability Group replication depends on the normal log writing semantics, we disable persistent log buffer functionality on the Primary, however it can be enabled on the secondary, which will speed up synchronization, as the secondary doesn’t need to wait for the log write in order to acknowledge the transaction.
To configure this in an Availability Group, you would create a persistent log buffer file on the primary in a location which is ideally a DAX volume on all replicas. If one or more replicas do not have a DAX volume, the feature will be ignored on those replicas.
Other Features
Other features (Replication, CDC, etc.) continue to function as normal with no impact from this feature.
More information on latency in SQL databases
https://channel9.msdn.com/Shows/Data-Exposed/Latency-and-Durability-with-SQL-Server-2016
Comments
- Anonymous
December 02, 2016
Great.Is this feature status GA or Preview ?and Can this feature reduce the NVMe SSD write count, for expand NVMe SSD life time for Endurance.- Anonymous
December 02, 2016
Hello Yoshihiro-san, SQL Server 2016 SP1 adds this support in full GA mode. - Anonymous
December 05, 2016
The comment has been removed
- Anonymous
- Anonymous
December 05, 2016
Kevin,Does this feature work on SQL Server 2016 Standard Edition, or is it EE-only? Also, do you know if the Edition of Windows Server 2016 matters or not? Thanks for this blog post and any additional info you can provide! - Anonymous
December 18, 2016
Isn't it this feature is highly depend on NVDIMM hardware? and as I know the maximum capacity for such memory is 8GB currently.and I read in some blog posts before, they mentioned you need to enable some trace flag T9921 to use this feature. Also it is very good in AlwaysOn AG environment only for secondary replica. I used RAMDisk softwares to represents the main memory as transaction log file volume, and I got over 33% transaction performance improvement.- Anonymous
January 05, 2017
Yes, it needs NVDIMM. However, it only uses 20MB of the NVDIMM capacity, so you don't need to provision much.With RTM you needed a trace flag to use this capability, and it was not production-ready.Starting with SP1 you can use it without trace flag, and it is production-ready and fully supported.
- Anonymous
- Anonymous
December 05, 2017
Great feature but too bad we can't fully exploit AlwaysON as HA solution. An old FCI on traditional storage has lower latency than an AlwaysON where primary replica log files are on traditional hardware...