SQL Server: Como definir o tamanho máximo de colunas de tamanho variável?
1. Introdução
Participar dos fóruns de SQL Server é estar às vezes frente a perguntas inesperadas. Recentemente encontrei tópico em que era questionado se seria correto utilizar varchar(99) para declarar todas as colunas para armazenamento de string de tamanho variável, mesmo que a coluna fosse armazenar strings de tamanho máximo bem menores do que 99, citando caso de 10 caracteres.
2. O que diz a documentação?
Na documentação para o tipo de dados varchar(n) consta que “O tamanho do armazenamento é o tamanho real dos dados inseridos + 2 bytes”. Ou seja, se em determinada linha o tamanho do string a ser armazenado na coluna é de 12 bytes, independente da coluna ser declarada como varchar(20) ou varchar(8000) no banco de dados aquela informação ocupará 14 bytes no banco de dados. Considerando-se este aspecto, então a resposta à pergunta seria “pode declarar todas as colunas como varchar(99) que não há problema”.
3. O que faz o otimizador de consultas?
Quando o otimizador de consultas do SQL Server gera o plano de execução de consulta, e no mesmo ocorrem determinadas ações, é necessário estimar o quanto de memória deverá ser alocada previamente para a execução da consulta; para isso um dos parâmetros é o tamanho da linha. No caso de linhas em que há colunas de tamanho variável, o gerenciador não mantém informações sobre qual é o tamanho médio das informações gravadas na coluna e utiliza então valor arbitrário, definido a partir do tamanho máximo que a coluna permite. Por exemplo, no caso de uma coluna declarada como varchar(100), o otimizador de consultas considera a metade mais 2 bytes, 50 + 2, como o valor a ser utilizado no cálculo do tamanho estimado da linha, em memória.
Antes de continuar é necessário revisar o conceito de “concessão de memória” (grant memory, em inglês). Na introdução do artigo Understanding SQL server memory grant (vide item Referências, ao final) consta que “memory grant is a part of server memory used to store temporary row data while sorting and joining rows. (...) This reservation improves query reliability under server load, because a query with reserved memory is less likely to hit out-of-memory while running, and the server prevents one query from dominating entire server memory”.
4. Testando...
Supondo que no banco de dados testeDB exista tabela denominada Correspondencia e que nela constem as colunas Nome, Logradouro, Cidade e Estado com os seguintes tamanhos máximos: 60, 80, 40, 40 (respectivamente) caracteres. Para fins de testes, a mesma tabela será declarada com os valores definidos como máximo mas também com valor fixo de 100.
-- código #1
USE testDB;
CREATE TABLE Correspondencia_1 (
Id int primary key,
Nome varchar(60),
Idade int,
Logradouro varchar(80),
Cidade varchar(40),
Estado varchar(40)
);
CREATE TABLE Correspondencia_2 (
Id int primary key,
Nome varchar(100),
Idade int,
Logradouro varchar(100),
Cidade varchar(100),
Estado varchar(100)
);
Se formos considerar o tamanho máximo de cada coluna, cada linha da tabela Correspondencia_1 terá 228 bytes (4 + 60 + 4 + 80 + 40 + 40). Já para a tabela Correspondencia_2 cada linha terá 408 bytes (4 + 100 + 4 + 100 + 100 + 100). Observe que nesses cálculos não foram considerados header e outras informações de controle da linha.
As duas tabelas serão carregadas com informação semelhante, usando o seguinte código:
-- código #2
declare @max int, @rc int;
set @max = 10000;
set @rc = 1;
set nocount on;
-- carrega linha inicial
INSERT into Correspondencia_1 (Id, Nome, Idade, Logradouro, Cidade, Estado)
values (1, replicate('A', 60), 80, replicate('B', 80),
replicate('C', 40), replicate('D', 40));
-- repete a linha inicial até completar N linhas
while @rc * 2 <= @max
begin
INSERT into Correspondencia_1
(Id, Nome, Idade, Logradouro, Cidade, Estado)
SELECT Id + @rc, Nome, ((Id % 60)+1), Logradouro, Cidade, Estado
from Correspondencia_1;
set @rc = @rc * 2;
end;
-- último bloco
INSERT into Correspondencia_1
(Id, Nome, Idade, Logradouro, Cidade, Estado)
SELECT Id + @rc, Nome, Idade, Logradouro, Cidade, Estado
from Correspondencia_1
where (Id + @rc) <= @max;
-- carrega tabela Correspondencia_2
INSERT into Correspondencia_2
(Id, Nome, Idade, Logradouro, Cidade, Estado)
SELECT Id, Nome, Idade, Logradouro, Cidade, Estado
from Correspondencia_1;
Após carregadas as duas tabelas, o seguinte código é executado na tabela Correspondencia_1:
-- código #3
SELECT Estado, Cidade, Nome
from Correspondencia_1
order by Estado, Cidade;
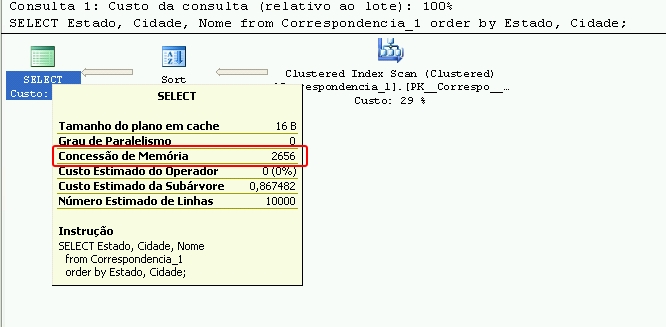
Ao analisar a imagem abaixo do plano de execução da consulta na tabela Correspondencia_1, observe qual é o valor de “Tamanho Estimado da Linha”.

E na figura abaixo qual é o valor de “Concessão de Memória”.
Após, ao executar o seguinte código, agora na tabela Correspondencia_2:
-- código #4
SELECT Estado, Cidade, Nome
from Correspondencia_2
order by Estado, Cidade;
observe no plano de execução abaixo qual é o valor de “Tamanho Estimado da Linha”:

e também qual é o valor de “Concessão de Memória”:

5. Conclusão
Compilando em um quadro as informações obtidas, temos
| Tabela
|
Tamanho Estimado de Linha | Concessão de Memória |
| Correspondencia_1 | 85 B | 2656 |
| Correspondencia_2 | 165 B | 4224 |
O mesmo conteúdo foi carregado nas duas tabelas mas os valores do quadro diferem, sendo confirmado que ao superestimar o tamanho das colunas há maior reserva de memória para a execução da consulta.
No caso dos códigos #3 e #4 o cálculo de Tamanho Estimado de Linha é simples: obtém-se o tamanho estimado das colunas que estão na lista de colunas:
- tabela Correspondencia_1: temos os tamanhos máximos de 40 (Estado), 40 (Cidade) e 60 (Nome). Obtendo-se a metade e somando 2 para cada coluna, temos (40 / 2 + 2) + (40 / 2 + 2) + (60 / 2 + 2) = 22 + 22 + 32 = 76 bytes
- tabela Correspondencia_2: temos os tamanhos máximos de 100 (Estado), 100 (Cidade) e 100 (Nome). Obtendo-se a metade e somando 2 para cada coluna, temos (100 / 2 + 2) + (100 / 2 + 2) + (100 / 2 + 2) = 52 + 52 + 52 = 156 bytes
A diferença entre os valores calculados acima e os exibidos nos planos de execução é de 9 bytes, que referem-se ao header e outros controles. A forma como o cálculo exato é realizado encontra-se no documento “Estimate the Size of a Clustered Index”.
6. Referências
Tópico que originou este artigo
Documentação relacionada ao assunto
- char e varchar
- Understanding SQL server memory grant (artigo de 2010)
- Estimate the Size of a Clustered Index
Artigo completo
- clique aqui para obter a versão completa deste artigo, em formato PDF