Estratégias de desenvolvimento e implantação de banco de dados (VB)
por Scott Mitchell
Ao implantar um aplicativo controlado por dados pela primeira vez, você pode copiar cegamente o banco de dados no ambiente de desenvolvimento para o ambiente de produção. Mas executar uma cópia cega em implantações subsequentes substituirá todos os dados inseridos no banco de dados de produção. Em vez disso, a implantação de um banco de dados envolve a aplicação das alterações feitas no banco de dados de desenvolvimento desde a última implantação no banco de dados de produção. Este tutorial examina esses desafios e oferece várias estratégias para ajudar a narrar e aplicar as alterações feitas no banco de dados desde a última implantação.
Introdução
Conforme discutido nos tutoriais anteriores, a implantação de um aplicativo ASP.NET envolve a cópia do conteúdo pertinente do ambiente de desenvolvimento para o ambiente de produção. A implantação não é um evento único, mas sim algo que acontece sempre que uma nova versão do software é lançada ou quando bugs ou preocupações de segurança foram identificados e resolvidos. Ao copiar ASP.NET páginas, imagens, arquivos JavaScript e outros arquivos desse tipo para o ambiente de produção, você não precisa se preocupar com a forma como esses arquivos foram alterados desde a última implantação. Você pode copiar cegamente o arquivo para produção, substituindo o conteúdo existente. Infelizmente, essa simplicidade não se estende à implantação do banco de dados.
Ao implantar um aplicativo controlado por dados pela primeira vez, você pode copiar cegamente o banco de dados no ambiente de desenvolvimento para o ambiente de produção. Mas executar uma cópia cega em implantações subsequentes substituirá todos os dados inseridos no banco de dados de produção. Em vez disso, a implantação de um banco de dados envolve a aplicação das alterações feitas no banco de dados de desenvolvimento desde a última implantação no banco de dados de produção. Este tutorial examina esses desafios e oferece várias estratégias para ajudar a narrar e aplicar as alterações feitas no banco de dados desde a última implantação.
Os desafios da implantação de um banco de dados
Antes que um aplicativo controlado por dados seja implantado pela primeira vez, há apenas um banco de dados, ou seja, o banco de dados no ambiente de desenvolvimento, e é por isso que, ao implantar um aplicativo controlado por dados pela primeira vez, você pode copiar cegamente o banco de dados no ambiente de desenvolvimento para o ambiente de produção. Mas depois que o aplicativo tiver sido implantado, há duas cópias do banco de dados: uma em desenvolvimento e outra em produção.
Entre implantações, os bancos de dados de desenvolvimento e produção podem ficar fora de sincronia. Embora o esquema do banco de dados de produção permaneça inalterado, o esquema do banco de dados de desenvolvimento pode mudar conforme novos recursos são adicionados. Você pode adicionar ou remover colunas, tabelas, exibições ou procedimentos armazenados. Também pode haver dados importantes que são adicionados ao banco de dados de desenvolvimento. Muitos aplicativos controlados por dados incluem tabelas de pesquisa preenchidas com dados embutidos em código específicos do aplicativo que não são editáveis pelo usuário. Por exemplo, um site de leilões pode ter uma lista suspensa com opções que descrevem a condição do item que está sendo leiloado: Novo, Como Novo, Bom e Justo. Em vez de codificar essas opções diretamente na lista suspensa, geralmente é melhor colocá-las em uma tabela de banco de dados. Se, durante o desenvolvimento, uma nova condição chamada Poor for adicionada à tabela, ao implantar o aplicativo, esse mesmo registro precisará ser adicionado à tabela de pesquisa no banco de dados de produção.
O ideal é que a implantação do banco de dados envolva a cópia do banco de dados do desenvolvimento para a produção. Mas tenha em mente que, depois de implantar o aplicativo e retomar o desenvolvimento, o banco de dados de produção está sendo preenchido com dados reais de usuários reais. Portanto, se você simplesmente copiasse o banco de dados do desenvolvimento para a produção na próxima implantação, substituiria o banco de dados de produção e perderia seus dados existentes. O resultado líquido é que a implantação do banco de dados se resume à aplicação das alterações feitas no banco de dados de desenvolvimento desde a última implantação.
Como a implantação de um banco de dados envolve a aplicação das alterações no esquema e, possivelmente, os dados desde a última implantação, um histórico de alterações deve ser mantido (ou determinado no momento da implantação) para que essas alterações possam ser aplicadas na produção. Há uma variedade de técnicas para gerenciar e aplicar alterações ao modelo de dados.
Definindo a linha de base
Para manter as alterações no banco de dados do aplicativo, você precisa ter algum estado inicial, uma linha de base à qual as alterações são aplicadas. Em um extremo, o estado inicial pode ser um banco de dados vazio sem tabelas, exibições ou procedimentos armazenados. Essa linha de base resulta em um log de alterações grande porque deve incluir a criação de todas as tabelas, exibições e procedimentos armazenados do banco de dados, juntamente com as alterações feitas após a implantação inicial. Na outra extremidade do espectro, você pode definir a linha de base como a versão do banco de dados que é inicialmente implantada no ambiente de produção. Essa opção resulta em um log de alterações muito menor porque inclui apenas as alterações feitas no banco de dados após a primeira implantação. Esta é a abordagem que eu prefiro. E, claro, você pode escolher uma abordagem mais intermediária, definindo a linha de base como um ponto entre a criação inicial do banco de dados e quando o banco de dados é implantado pela primeira vez.
Depois de escolher uma linha de base, considere gerar um script SQL que pode ser executado para recriar a versão de linha de base. Esse script possibilita recriar rapidamente a versão de linha de base do banco de dados. Essa funcionalidade é especialmente útil em projetos maiores, em que pode haver vários desenvolvedores trabalhando no projeto ou ambientes adicionais, como teste ou preparo, que precisam de sua própria cópia do banco de dados.
Há uma variedade de ferramentas à sua disposição para gerar um script SQL da versão de linha de base. No SSMS (SQL Server Management Studio), clique com o botão direito do mouse no banco de dados, acesse o submenu Tarefas e escolha a opção Gerar Scripts. Isso inicia o Assistente de Script, que você pode instruir a gerar um arquivo que contém os comandos SQL para criar os objetos do banco de dados. Outra opção é o Assistente de Publicação de Banco de Dados, que pode gerar os comandos SQL para não apenas criar o esquema de banco de dados, mas também os dados nas tabelas de banco de dados. O Assistente de Publicação de Banco de Dados foi examinado detalhadamente no tutorial Implantando um banco de dados. Independentemente da ferramenta que você usa, no final você deve ter um arquivo de script que pode ser usado para recriar a versão de linha de base do banco de dados, caso surja a necessidade.
Documentando as alterações de banco de dados em prosa
A maneira mais simples de manter um log de alterações no modelo de dados durante a fase de desenvolvimento é registrar as alterações em prosa. Por exemplo, se durante o desenvolvimento de um aplicativo já implantado você adicionar uma nova coluna à Employees tabela, remover uma coluna da Orders tabela e adicionar uma nova tabela (ProductCategories), manterá um arquivo de texto ou o documento do Microsoft Word com o seguinte histórico:
| Alterar Data | Detalhes da Alteração |
|---|---|
| 2009-02-03: | Coluna adicionada DepartmentID (int, NOT NULL) à Employees tabela. Adicionada uma restrição de chave estrangeira de Departments.DepartmentID a Employees.DepartmentID. |
| 2009-02-05: | TotalWeight Coluna removida da Orders tabela. Dados já capturados em registros associados OrderDetails . |
| 2009-02-12: | A tabela foi criada ProductCategories . Há três colunas: (, , ), (, ) e Active (bit, NOT NULL). NOT NULLnvarchar(50)CategoryNameNOT NULLIDENTITYintProductCategoryID Adicionada uma restrição de chave primária a ProductCategoryIDe um valor padrão de 1 a Active. |
Há várias desvantagens nessa abordagem. Para começar, não há nenhuma esperança para a automação. Sempre que essas alterações precisarem ser aplicadas a um banco de dados, como quando o aplicativo for implantado, um desenvolvedor deverá implementar manualmente cada alteração, uma de cada vez. Além disso, se você precisar reconstruir uma versão específica do banco de dados da linha de base usando o log de alterações, isso levará cada vez mais tempo à medida que o tamanho do log cresce. Outra desvantagem para esse método é que a clareza e o nível de detalhes de cada entrada de log de alterações são deixados para a pessoa que está gravando a alteração. Em uma equipe com vários desenvolvedores, alguns podem tornar entradas mais detalhadas, mais legíveis ou mais precisas do que outras. Além disso, erros de digitação e outros erros de entrada de dados relacionados a humanos são possíveis.
O principal benefício de documentar as alterações de banco de dados em prosa é a simplicidade. Você não precisa de familiaridade com a sintaxe SQL para criar e alterar objetos de banco de dados. Em vez disso, você pode registrar as alterações em prosa e implementá-las por meio SQL Server Management Studio interface gráfica do usuário.
Manter seu log de alterações em prosa é, reconhecidamente, não muito sofisticado e não funcionará bem com determinados projetos, como os que são grandes no escopo, têm alterações frequentes no modelo de dados ou envolvem vários desenvolvedores. Mas vi essa abordagem funcionar muito bem em projetos pequenos de um homem só que têm apenas alterações ocasionais no modelo de dados e em que o desenvolvedor individual não tem uma forte experiência na sintaxe SQL para criar e alterar objetos de banco de dados.
Observação
Embora as informações no log de alterações sejam, tecnicamente, necessárias apenas até o tempo de implantação, recomendo manter um histórico de alterações. Mas, em vez de manter um único arquivo de log de alterações cada vez maior, considere ter um arquivo de log de alterações diferente para cada versão do banco de dados. Normalmente, você desejará fazer a versão do banco de dados sempre que ele for implantado. Mantendo um log de logs de alteração, você pode, começando na linha de base, recriar qualquer versão do banco de dados executando os scripts de log de alterações a partir da versão 1 e continuando até chegar à versão necessária para recriar.
Gravando as instruções de alteração do SQL
A principal desvantagem de manter o log de alterações em prosa é a falta de automação. Idealmente, implementar as alterações de banco de dados no banco de dados de produção no momento da implantação seria tão fácil quanto clicar em um botão para executar um script em vez de ter que executar manualmente uma lista de instruções. Essa automação é possível mantendo um log de alterações que contém os comandos SQL usados para alterar o modelo de dados.
A sintaxe SQL inclui várias instruções para criar e modificar vários objetos de banco de dados. Por exemplo, a instrução CREATE TABLE, quando executada, cria uma nova tabela com as colunas e restrições especificadas. A instrução ALTER TABLE modifica uma tabela existente, adicionando, removendo ou modificando suas colunas ou restrições. Também há instruções para criar, modificar e remover índices, exibições, funções definidas pelo usuário, procedimentos armazenados, gatilhos e outros objetos de banco de dados.
Retornando ao nosso exemplo anterior, imagem que durante o desenvolvimento de um aplicativo já implantado você adiciona uma nova coluna à Employees tabela, remove uma coluna da Orders tabela e adiciona uma nova tabela (ProductCategories). Essas ações resultariam em um arquivo de log de alterações com os seguintes comandos SQL:
-- Add the DepartmentID column
ALTER TABLE [Employees] ADD [DepartmentID]
int NOT NULL
-- Add a foreign key constraint between Departments.DepartmentID and Employees.DepartmentID
ALTER TABLE [Employees] ADD
CONSTRAINT [FK_Departments_DepartmentID]
FOREIGN
KEY ([DepartmentID])
REFERENCES
[Departments] ([DepartmentID])
-- Remove TotalWeight column from Orders
ALTER TABLE [Orders] DROP COLUMN
[TotalWeight]
-- Create the ProductCategories table
CREATE TABLE [ProductCategories]
(
[ProductCategoryID]
int IDENTITY(1,1) NOT NULL,
[CategoryName]
nvarchar(50) NOT NULL,
[Active]
bit NOT NULL CONSTRAINT [DF_ProductCategories_Active] DEFAULT
((1)),
CONSTRAINT
[PK_ProductCategories] PRIMARY KEY CLUSTERED ( [ProductCategoryID])
)
Efetuar push dessas alterações no banco de dados de produção no momento da implantação é uma operação de um clique: abra SQL Server Management Studio, conecte-se ao banco de dados de produção, abra uma janela Nova Consulta, cole o conteúdo do log de alterações e clique em Executar para executar o script.
Usando uma ferramenta de comparação para sincronizar os modelos de dados
Documentar alterações de banco de dados em prosa é fácil, mas implementar as alterações exige que um desenvolvedor faça cada alteração no banco de dados de produção uma de cada vez; documentar a alteração dos comandos SQL torna a implementação dessas alterações no banco de dados de produção tão fácil e rápida quanto clicar em um botão, mas requer o aprendizado e o domínio das instruções SQL e da sintaxe para criar e alterar objetos de banco de dados. As ferramentas de comparação de banco de dados aproveitam o melhor de ambas as abordagens e descartam o pior.
Uma ferramenta de comparação de banco de dados compara o esquema ou os dados de dois bancos de dados e exibe um relatório de resumo mostrando como os bancos de dados diferem. Em seguida, com o clique de um botão, você pode gerar os comandos SQL para sincronizar um ou mais objetos de banco de dados. Em poucas palavras, você pode usar uma ferramenta de comparação de banco de dados para comparar os bancos de dados de desenvolvimento e produção em tempo de implantação, gerando um arquivo que contém os comandos SQL que, quando executados, aplicarão as alterações ao esquema do banco de dados de produção para que ele espelhasse o esquema do banco de dados de desenvolvimento.
Há uma variedade de ferramentas de comparação de banco de dados de terceiros oferecidas por muitos fornecedores diferentes. Um desses exemplos é a Comparação de SQL, por Red Gate Software. Vamos percorrer o processo de usar a Comparação de SQL para comparar e sincronizar os esquemas de bancos de dados de desenvolvimento e produção.
Observação
No momento da redação, a versão atual do SQL Compare era a versão 7.1, com a Edição Standard custando US$ 395. Você pode acompanhar baixando uma avaliação gratuita de 14 dias.
Quando a Comparação de SQL inicia a caixa de diálogo Projetos de Comparação é aberta, mostrando os projetos de Comparação de SQL salvos. Criar um novo projeto. Isso inicia o assistente de Configuração do Projeto, que solicita informações sobre os bancos de dados a serem comparados (consulte a Figura 1). Insira as informações para os bancos de dados do ambiente de desenvolvimento e produção.
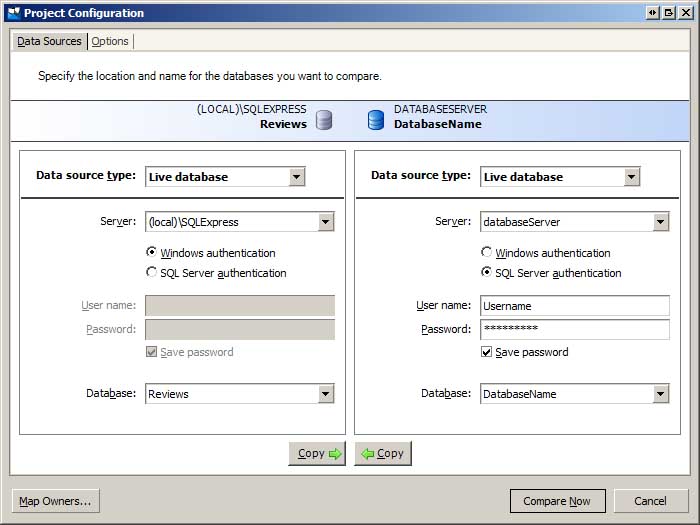
Figura 1: Comparar os bancos de dados de desenvolvimento e produção (clique para exibir a imagem em tamanho real)
{kind=link}
Observação
Se o App_Data banco de dados do ambiente de desenvolvimento for um arquivo de banco de dados do SQL Express Edition na pasta do seu site, você precisará registrar o banco de dados no servidor de banco de dados SQL Server Express para selecioná-lo na caixa de diálogo mostrada na Figura 1. A maneira mais fácil de fazer isso é abrir SQL Server Management Studio (SSMS), conectar-se ao servidor de banco de dados SQL Server Express e anexar o banco de dados. Se você não tiver o SSMS instalado em seu computador, poderá baixar e instalar o SQL Server Management Studio gratuito.
Além de selecionar os bancos de dados a serem comparados, você também pode especificar uma variedade de configurações de comparação na guia Opções. Uma opção que talvez você queira ativar é a "Ignorar nomes de restrição e índice". Lembre-se de que, no tutorial anterior, adicionamos os objetos de banco de dados dos serviços de aplicativo aos bancos de dados de desenvolvimento e produção. Se você usou a aspnet_regsql.exe ferramenta para criar esses objetos no banco de dados de produção, verá que a chave primária e os nomes de restrição exclusivos diferem entre os bancos de dados de desenvolvimento e produção. Consequentemente, a Comparação de SQL sinalizará todas as tabelas de serviços de aplicativo como diferentes. Você pode deixar a opção "Ignorar nomes de restrição e índice" desmarcada e sincronizar os nomes de restrição ou instruir o SQL Compare a ignorar essas diferenças.
Depois de selecionar os bancos de dados a serem comparados (e examinar as opções de comparação), clique no botão Comparar Agora para iniciar a comparação. Nos próximos segundos, a Comparação de SQL examina os esquemas dos dois bancos de dados e gera um relatório de como eles diferem. Fiz algumas modificações propositalmente no banco de dados de desenvolvimento para mostrar como essas discrepâncias são observadas na interface de Comparação de SQL. Como mostra a Figura 2, adiciono uma BirthDate coluna à Authors tabela, removi a ISBN coluna da Books tabela e adicionamos uma nova tabela, Ratings, que destina-se a permitir que os usuários que visitam o site classifiquem os livros revisados.
Observação
As alterações no modelo de dados feitas neste tutorial foram feitas para ilustrar o uso de uma ferramenta de comparação de banco de dados. Você não encontrará essas alterações no banco de dados em tutoriais futuros.
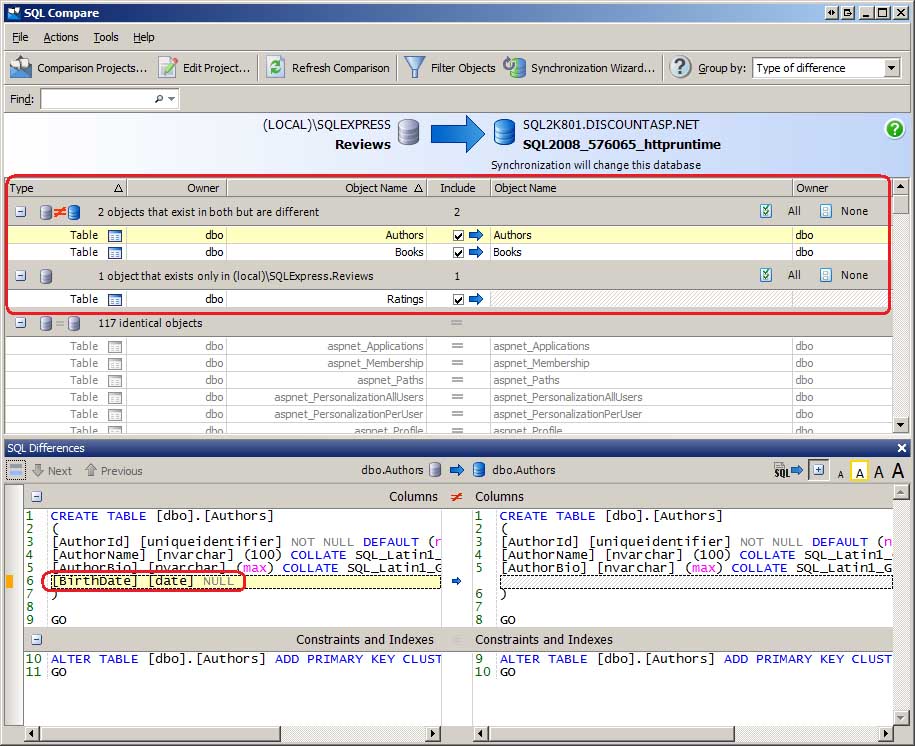
Figura 2: Comparação de SQL Listas as diferenças entre os bancos de dados de desenvolvimento e produção (clique para exibir a imagem em tamanho real)
{kind=link}
A Comparação de SQL divide os objetos de banco de dados em grupos, mostrando rapidamente quais objetos existem em ambos os bancos de dados, mas são diferentes, quais objetos existem em um banco de dados, mas não no outro, e quais objetos são idênticos. Como você pode ver, há dois objetos que existem em ambos os bancos de dados, mas são diferentes: a Authors tabela, que tinha uma coluna adicionada, e a Books tabela, que teve uma removida. Há um objeto que existe apenas no banco de dados de desenvolvimento, ou seja, a tabela recém-criada Ratings . E há 117 objetos idênticos em ambos os bancos de dados.
Selecionar um objeto de banco de dados exibe a janela Diferenças de SQL, que mostra como esses objetos diferem. A janela Diferenças de SQL, exibida na parte inferior da Figura 2, destaca que a Authors tabela no banco de dados de desenvolvimento tem a BirthDate coluna , que não é encontrada na Authors tabela no banco de dados de produção.
Depois de examinar as diferenças e selecionar quais objetos você deseja sincronizar, a próxima etapa é gerar os comandos SQL necessários para atualizar o esquema do banco de dados de produção para corresponder ao banco de dados de desenvolvimento. Isso é feito por meio do Assistente de Sincronização. O Assistente de Sincronização confirma quais objetos sincronizar e resume o plano de ação (consulte a Figura 3). Você pode sincronizar os bancos de dados imediatamente ou gerar um script com os comandos SQL que podem ser executados no seu lazer.
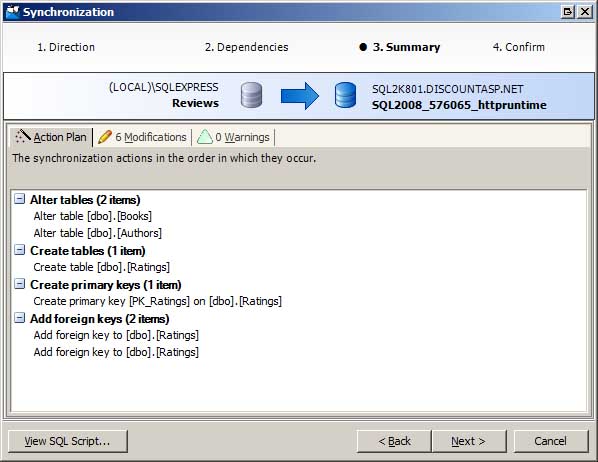
Figura 3: Usar o Assistente de Sincronização para sincronizar os esquemas de bancos de dados (clique para exibir a imagem em tamanho real)
{kind=link}
Ferramentas de comparação de banco de dados, como o SqL Compare do Red Gate Software, facilitam a aplicação das alterações ao esquema de banco de dados de desenvolvimento ao banco de dados de produção como ponto e clique.
Observação
A Comparação de SQL compara e sincroniza dois esquemas de bancos de dados. Infelizmente, ele não compara e sincroniza os dados em duas tabelas de bancos de dados. O Red Gate Software oferece um produto chamado SQL Data Compare que compara e sincroniza os dados entre dois bancos de dados, mas é um produto separado da Comparação de SQL e custa mais US$ 395.
Colocar o aplicativo offline durante a implantação
Como vimos ao longo desses tutoriais, a implantação é um processo que envolve várias etapas: copiar as páginas ASP.NET, master páginas, arquivos CSS, arquivos JavaScript, imagens e outros conteúdos necessários do ambiente de desenvolvimento para o ambiente de produção; copiar as informações de configuração específicas do ambiente de produção, se necessário, e aplicar as alterações ao modelo de dados desde a última implantação. Dependendo do número de arquivos e da complexidade das alterações do banco de dados, essas etapas podem levar de alguns segundos a vários minutos para serem concluídas. Durante essa janela, o aplicativo Web está em fluxo e os usuários que visitam o site podem enfrentar erros ou comportamento inesperado.
Ao implantar um site, é melhor colocar o aplicativo Web "offline" até que a implantação seja concluída. Colocar o aplicativo offline (e trazê-lo de volta depois que o processo de implantação for concluído) é tão fácil quanto carregar um arquivo e excluí-lo. A partir do ASP.NET 2.0, a simples presença de um arquivo chamado app_offline.htm no diretório raiz do aplicativo coloca o site inteiro "offline". Qualquer solicitação a uma página de ASP.NET nesse site é respondida automaticamente com o conteúdo do app_offline.htm arquivo. Depois que esse arquivo é removido, o aplicativo volta a ficar online.
Colocar um aplicativo offline durante a implantação é tão simples quanto carregar um app_offline.htm arquivo no diretório raiz do ambiente de produção antes de iniciar o processo de implantação e, em seguida, excluí-lo (ou renomeá-lo para outra coisa) depois que a implantação for concluída. Para obter mais informações sobre essa técnica, consulte o artigo de John Peterson, Tomando um aplicativo ASP.NET offline.
Resumo
A main desafio na implantação de um aplicativo controlado por dados gira em torno da implantação do banco de dados. Como há duas versões do banco de dados – uma no ambiente de desenvolvimento e outra no ambiente de produção – esses dois esquemas de bancos de dados podem ficar fora de sincronia à medida que novos recursos são adicionados no desenvolvimento. Além disso, como o banco de dados de produção está sendo preenchido com dados reais de usuários reais, você não pode substituir o banco de dados de produção pelo banco de dados de desenvolvimento modificado como você pode ao implantar os arquivos que compõem o aplicativo (as páginas ASP.NET, arquivos de imagem e assim por diante). Em vez disso, a implantação de um banco de dados envolve a implementação do conjunto preciso de alterações feitas no banco de dados de desenvolvimento no banco de dados de produção desde a última implantação.
Este tutorial analisou três técnicas para manter e aplicar um log de alterações de banco de dados. A abordagem mais simples é registrar as alterações em prosa. Embora essa tática torne a implementação dessas alterações no banco de dados de produção um processo manual, ela não requer conhecimento dos comandos SQL para criar e alterar objetos de banco de dados. Uma abordagem mais sofisticada e muito mais palatável em projetos ou projetos maiores com vários desenvolvedores é registrar as alterações como uma série de comandos SQL. Isso acelera muito a distribuição dessas alterações no banco de dados de destino. A melhor das duas abordagens pode ser obtida usando uma ferramenta de comparação de banco de dados, como a Comparação de SQL do Red Gate Software.
Este tutorial conclui nosso foco na implantação de um aplicativo controlado por dados. O próximo conjunto de tutoriais analisa como responder a erros no ambiente de produção. Veremos como exibir uma página de erro amigável em vez da Tela Amarela da Morte. E veremos como registrar os detalhes do erro e como alertá-lo quando esses erros ocorrerem.
Programação feliz!