Executar aplicativo de N camadas em várias regiões do Hub de Pilha do Azure para ter alta disponibilidade
Essa arquitetura de referência mostra um conjunto de práticas comprovadas para execução em um aplicativo de N camadas em várias regiões do Azure Stack Hub, a fim de obter disponibilidade e uma infraestrutura de recuperação de desastre robusta. Neste documento, o Gerenciador de Tráfego é usado para obter alta disponibilidade, no entanto, se o Gerenciador de Tráfego não for uma opção preferencial em seu ambiente, um par de balanceadores de carga altamente disponíveis também poderá ser substituído.
Observação
Observe que o Gerenciador de Tráfego usado na arquitetura abaixo precisa ser configurado no Azure e os pontos de extremidade usados para configurar o perfil do Gerenciador de Tráfego precisam ser IPs roteáveis publicamente.
Arquitetura
Essa arquitetura baseia-se naquela mostrada em Aplicativo de N camadas com o SQL Server.
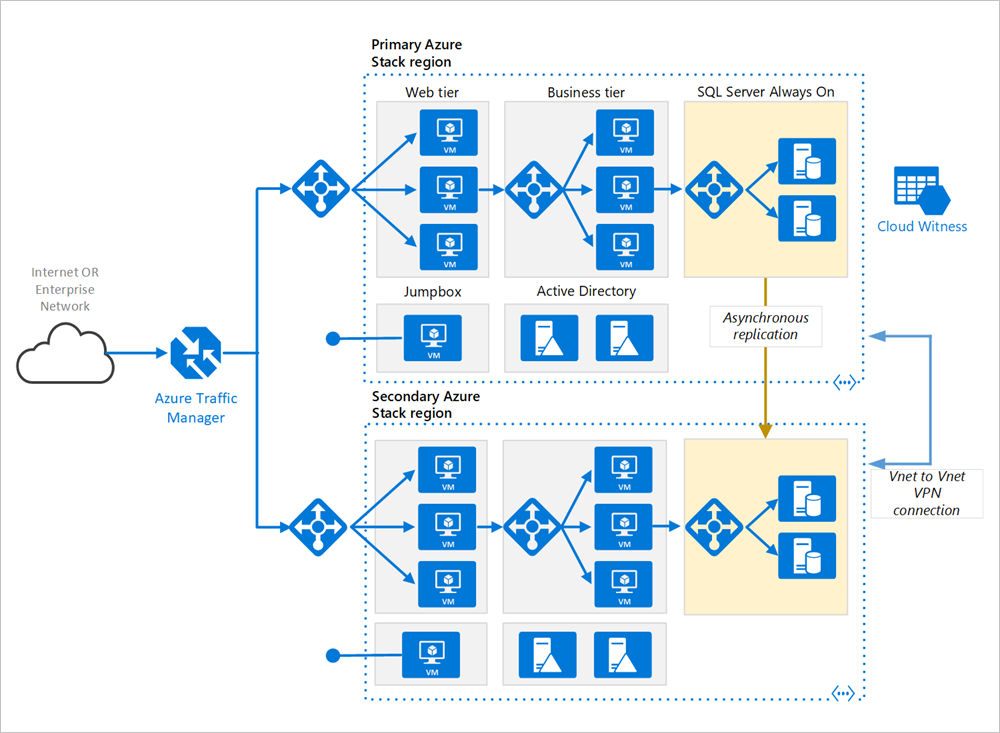
Regiões primárias e secundárias. Use duas regiões para obter alta disponibilidade. Uma delas é a região primária. A outra região destina-se ao failover.
Gerenciador de Tráfego do Microsoft Azure. O Gerenciador de Tráfego roteia as solicitações de entrada para uma das regiões. Durante as operações normais, ele roteia as solicitações para a região primária. Se essa região ficar indisponível, o Gerenciador de Tráfego fará failover para a região secundária. Para obter mais informações, consulte a Configuração do Gerenciador de Tráfego.
Grupos de recursos. Crie grupos de recursos separados para a região primária, a região secundária. Isso oferece flexibilidade para gerenciar cada região como uma única coleção de recursos. Por exemplo, você poderia reimplantar uma região sem interromper a outra. Vincule os grupos de recursos para ser possível executar uma consulta para listar todos os recursos para o aplicativo.
Redes virtuais. Crie uma rede virtual separada para cada região. Verifique se que os espaços de endereço não se sobrepõem.
Grupo de Disponibilidade Always On do SQL Server. Se você utilizar o SQL Server, recomendamos usar os Grupos de Disponibilidade Always On para ter alta disponibilidade. Crie um único grupo de disponibilidade que inclui instâncias do SQL Server em ambas as regiões.
Conexão VPN VNET para VNET. Como o Emparelhamento de VNET ainda não está disponível no Azure Stack Hub, use a conexão DE VPN VNET para VNET para conectar os dois VNETs. Consulte VNET para VNET no Azure Stack Hub para obter mais informações.
Recomendações
Uma arquitetura de várias regiões pode fornecer uma disponibilidade maior que a implantação em uma única região. Se uma interrupção regional afetar a região primária, você poderá usar o Gerenciador de Tráfego para fazer failover para a região secundária. Essa arquitetura também poderá ajudar a se um subsistema individual do aplicativo falhar.
Há várias abordagens gerais para alcançar alta disponibilidade em várias regiões:
Ativo/passivo com espera ativa. O tráfego vai para uma região, enquanto a outra aguarda em espera ativa. A espera ativa significa que as VMs na região secundária são alocadas e ficam em execução a todo momentos.
Ativo/passivo com espera a frio. O tráfego vai para uma região, enquanto a outra aguarda em espera passiva. A espera passiva significa que as VMs na região secundária não são alocadas até serem necessárias para failover. Essa abordagem custa menos para ser executada, mas geralmente leva mais tempo para ficar online durante uma falha.
Ativo/ativo. Ambas as regiões ficam ativas e a carga das solicitações é balanceada entre elas. Se uma região ficar indisponível, ela será retirada da rotação.
Essa arquitetura de referência se concentra em ativo/passivo com espera ativa, usando o Gerenciador de Tráfego para o failover. Você pode implantar um pequeno número de VMs para espera ativa e, em seguida, escalar horizontalmente conforme necessário.
Configuração do Gerenciador de Tráfego
Considere os seguintes pontos ao configurar o Gerenciador de Tráfego:
Roteamento. O Gerenciador de Tráfego dá suporte a vários algoritmos de roteamento. Para o cenário descrito neste artigo, use roteamento prioritário (anteriormente chamado de roteamento de failover). Com essa configuração, o Gerenciador de Tráfego envia todas as solicitações para a região primária, a menos que ela fique inacessível. Nesse ponto, ele automaticamente faz failover para a região secundária. Consulte Configurar o método de roteamento de failover.
Investigação de integridade. O Gerenciador de Tráfego usa uma investigação HTTP (ou HTTPS) para monitorar a disponibilidade de cada região. A investigação verifica uma resposta HTTP 200 para um caminho de URL especificado. Como uma prática recomendada, crie um ponto de extremidade que relata a integridade geral do aplicativo e use esse ponto de extremidade para a investigação de integridade. Caso contrário, a investigação pode relatar um ponto de extremidade íntegro quando partes essenciais do aplicativo estão falhando na verdade. Para obter mais informações, consulte Padrão de monitoramento de ponto de extremidade de integridade.
Quando o Gerenciador de Tráfego faz failover, há um período em que os clientes não podem acessar o aplicativo. A duração é afetada pelos seguintes fatores:
A investigação de integridade precisa detectar que a região primária ficou inacessível.
Os servidores DNS precisam atualizar os registros DNS armazenados em cache para o endereço IP, dependendo da TTL (vida útil) DNS. A TTL padrão é 300 segundos (5 minutos), mas você pode configurar esse valor ao criar o perfil do Gerenciador de Tráfego.
Para saber mais, consulte Sobre o monitoramento do Gerenciador de Tráfego.
Em caso de falha do Gerenciador de Tráfego, é recomendável executar um failback manual em vez de implementar um failback automático. Caso contrário, você pode criar uma situação em que o aplicativo fica alternando entre as regiões. Verifique se todos os subsistemas de aplicativo estão íntegros antes de realizar o failback.
Observe que o Gerenciador de Tráfego realiza failback automaticamente por padrão. Para evitar isso, diminua manualmente a prioridade da região primária após um evento de failover. Por exemplo, suponha que a região primária tem prioridade 1 e a secundária tem prioridade 2. Após um failover, defina a região primária para a prioridade 3, para impedir o failback automático. Quando estiver pronto para alternar, volte, atualize a prioridade para 1.
O seguinte comando da CLI do Azure atualiza a prioridade:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
Outra abordagem é desabilitar temporariamente o ponto de extremidade até que você esteja pronto para realizar failback:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
Dependendo da causa de um failover, será necessário reimplantar os recursos dentro de uma região. Antes de fazer o failback, execute um teste de prontidão operacional. O teste deverá verificar o seguinte:
As VMs estão configuradas corretamente. (Todo o software necessário está instalado, o IIS está em execução e assim por diante.)
Os subsistemas de aplicativos estão íntegros.
Testes funcionais. (Por exemplo, a camada de banco de dados pode ser acessada da camada da Web.)
Configurar Grupos de Disponibilidade Always On do SQL Server
Antes do Windows Server 2016, os Grupos de Disponibilidade Always On do SQL Server exigiam um controlador de domínio e todos os nós no grupo de disponibilidade precisavam estar no mesmo domínio do AD (Active Directory).
Para configurar o grupo de disponibilidade:
No mínimo, coloque dois controladores de domínio em cada região.
Forneça um endereço IP estático para cada controlador de domínio.
Crie VPN para habilitar a comunicação entre duas redes virtuais.
Para cada rede virtual, adicione os endereços IP dos controladores de domínio (de ambas as regiões) à lista de servidores DNS. Você pode usar o comando da CLI a seguir. Para obter mais informações, consulte alterar servidores DNS.
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"Crie um cluster WSFC (Clustering de Failover do Windows Server) que inclui as instâncias do SQL Server em ambas as regiões.
Crie um único Grupo de Disponibilidade Always On do SQL Server que inclui instâncias do SQL Server em ambas as regiões primária e secundária. Consulte Estendendo o Grupo de Disponibilidade Always On para o Datacenter Remoto do Azure (PowerShell) para ver as etapas.
Coloque a réplica primária na região primária.
Coloque uma ou mais réplicas secundárias na região primária. Configure-as para usar a confirmação síncrona com failover automático.
Coloque uma ou mais réplicas secundárias na região secundária. Configure-as para usar a confirmação assíncrona, por motivos de desempenho. (Caso contrário, todas as transações de T-SQL precisarão aguardar uma viagem de ida e volta pela rede para a região secundária.)
Observação
As réplicas de confirmação assíncronas não dão suporte ao failover automático.
Considerações sobre disponibilidade
Com um aplicativo complexo de N camadas, pode não ser necessário replicar o aplicativo inteiro na região secundária. Em vez disso, você pode replicar apenas um subsistema crítico que é necessário para dar suporte à continuidade de negócios.
O Gerenciador de Tráfego é um possível ponto de falha no sistema. Se o serviço do Gerenciador de Tráfego falhar, os clientes não poderão acessar seu aplicativo durante o tempo de inatividade. Examine o SLA do Gerenciador de Tráfego e determine se usar apenas o Gerenciador de Tráfego atende aos seus requisitos de negócios para alta disponibilidade. Caso contrário, considere adicionar outra solução de gerenciamento de tráfego como um failback. Se o serviço do Gerenciador de Tráfego do Azure falhar, altere os registros CNAME no DNS para apontar para outro serviço de gerenciamento de tráfego. (Esta etapa deve ser executada manualmente e seu aplicativo estará indisponível até que as alterações de DNS sejam propagadas.)
Para o cluster do SQL Server, há dois cenários de failover a serem considerados:
Todas as réplicas de banco de dados do SQL Server na região primária falham. Isso pode acontecer durante uma interrupção regional, por exemplo. Nesse caso, você deve fazer failover do grupo de disponibilidade manualmente, mesmo que o Gerenciador de Tráfego faça failover automaticamente no front-end. Siga as etapas em Executar um Failover Manual Forçado de um Grupo de Disponibilidade do SQL Server, que descreve como executar um failover forçado usando o SQL Server Management Studio, o Transact-SQL ou o PowerShell no SQL Server 2016.
Aviso
Com o failover forçado, há um risco de perda de dados. Depois que a região principal estiver novamente online, crie um instantâneo do banco de dados e usar tablediff para encontrar as diferenças.
O Gerenciador de Tráfego faz failover para a região secundária, mas a réplica primária do Banco de Dados do SQL Server ainda está disponível. A camada de front-end pode falhar sem afetar as VMs do SQL Server, por exemplo. Nesse caso, o tráfego da Internet é roteado para a região secundária e essa região ainda pode se conectar à réplica primária. No entanto, haverá aumento da latência, pois as conexões do SQL Server ocorrem entre regiões. Nessa situação, você deve executar um failover manual da seguinte maneira:
Alterne temporariamente uma réplica de banco de dados do SQL Server na região secundária para confirmação síncrona. Isso garante que não haja perda de dados durante o failover.
Failover para essa réplica.
Após realizar o failback para a região primária, restaure a configuração de confirmação assíncrona.
Considerações sobre capacidade de gerenciamento
Quando você atualizar a implantação, atualize uma região de cada vez para reduzir a chance de uma falha global devido a uma configuração incorreta ou um erro no aplicativo.
Teste a resiliência do sistema a falhas. Aqui estão alguns cenários comuns de falha para testar:
Desligamento de instâncias de VM.
Recursos de pressão, como CPU e memória.
Desconectar/atraso de rede.
Falha de processos.
Expiração de certificados.
Simular falhas de hardware.
Desligamento do serviço DNS nos controladores de domínio.
Meça o tempo de recuperação e verifique se ele cumpre seus requisitos de negócios. Teste também combinações dos modos de falha.
Próximas etapas
- Para saber mais sobre os padrões de nuvem do Azure, confira Padrões de Design de Nuvem.