Modelo de documento de ID da Informação de Documentos
Esse conteúdo se aplica a: ![]() v4.0 (GA) | Versões anteriores:
v4.0 (GA) | Versões anteriores: ![]() v3.1 (GA)
v3.1 (GA) ![]() v3.0 (GA)
v3.0 (GA) ![]() v2.1 (GA)
v2.1 (GA)
::: moniker-end
Esse conteúdo se aplica a: ![]() v2.1 | Última versão:
v2.1 | Última versão: ![]() v4.0 (GA)
v4.0 (GA)
O modelo de Documento de identidade (ID) da Informação de Documentos combina recursos avançados de OCR (Reconhecimento Óptico de Caracteres) com modelos de aprendizado profundo para analisar e extrair informações chave dos documentos de identidade. A API analisa documentos de identidade (incluindo os mostrados a seguir) e retorna uma representação de dados JSON estruturada.
| Region | Tipos de documento |
|---|---|
| No mundo inteiro | Passaporte |
| Estados Unidos | Carteira de Habilitação, Cartão de Identificação, Permissão de Residência (Green card), Previdência Social, ID Militar |
| Europa | Carteira de Habilitação, Cartão de Identificação, Permissão de Residência |
| Índia | Carteira de Habilitação, Cartão PAN, Cartão Aadhaar |
| Canadá | Carteira de Habilitação, Cartão de Identificação, Permissão de Residência (Maple card) |
| Austrália | Carteira de Habilitação, Cartão de Fotos, ID de passagem de chave (incluindo versão digital) |
A Informação de Documentos do Azure pode analisar e extrair informações de documentos de ID (identificação) emitidos pelo governo usando um modelo de IDs predefinidas. Ele combina nossas funcionalidades avançadas de OCR (Reconhecimento Óptico de Caracteres) com funcionalidades de reconhecimento de ID para extrair informações importantes de passaportes internacionais e carteiras de motorista dos EUA (de todos os 50 estados e da capital). A API de IDs extrai as principais informações desses documentos de identidade, como nome, sobrenome, data de nascimento, número do documento, entre outros. Essa API está disponível na Informação de Documentos versão 2.1 como um serviço de nuvem.
Processamento de documentos de identidade
O processamento de documento de identificação envolve a extração de dados de documentos de identificação, de forma manual ou usando tecnologia baseada em OCR. O processamento de documentos de ID é uma etapa importante em qualquer operação de negócios que exija prova de identidade. Os exemplos incluem a verificação do cliente em bancos e outras instituições financeiras, pedido de hipoteca, visitas médicas, processamento de declaração, setor hoteleiro e muito mais. Os indivíduos fornecem alguma prova de identidade por meio de carteiras de habilitação, passaportes e outros documentos semelhantes para que a empresa possa verificá-los com eficiência antes de fornecer os serviços e benefícios.
Exemplo de Carteira de motorista dos Estados Unidos processada com o Estúdio da Informação de Documentos
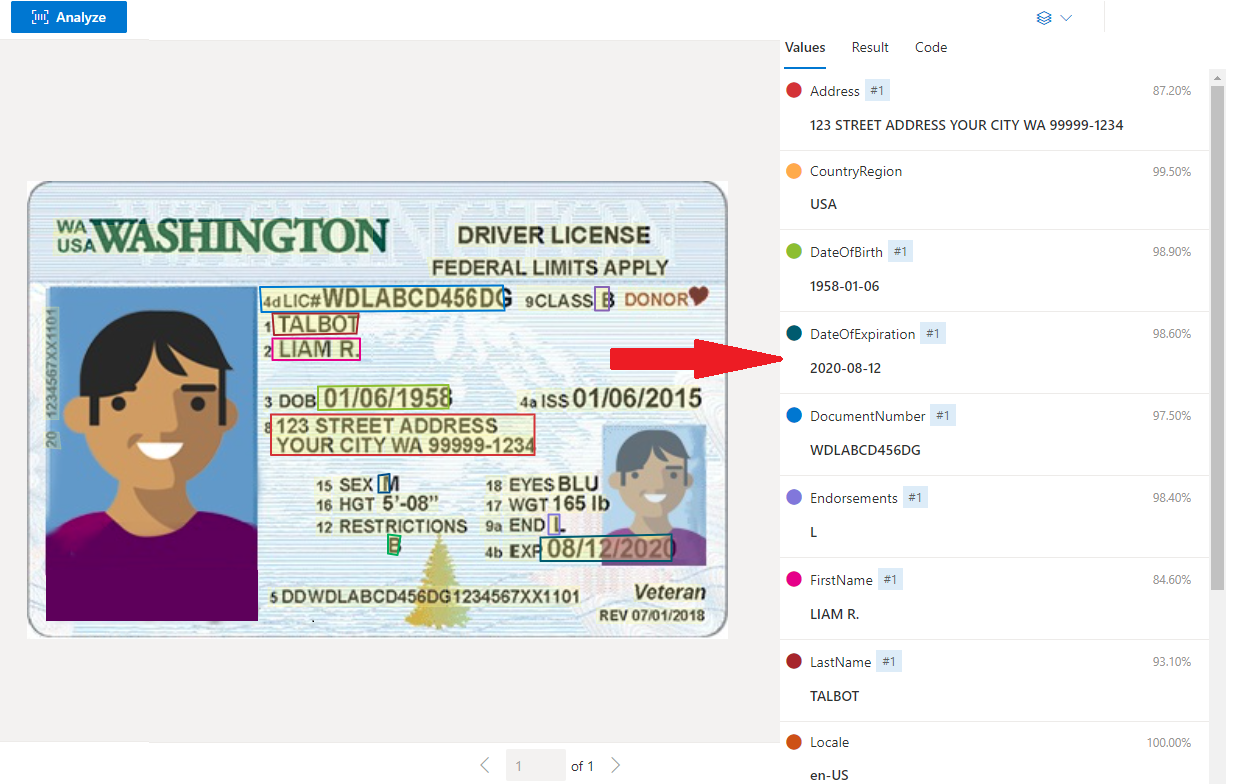
Extração de dados
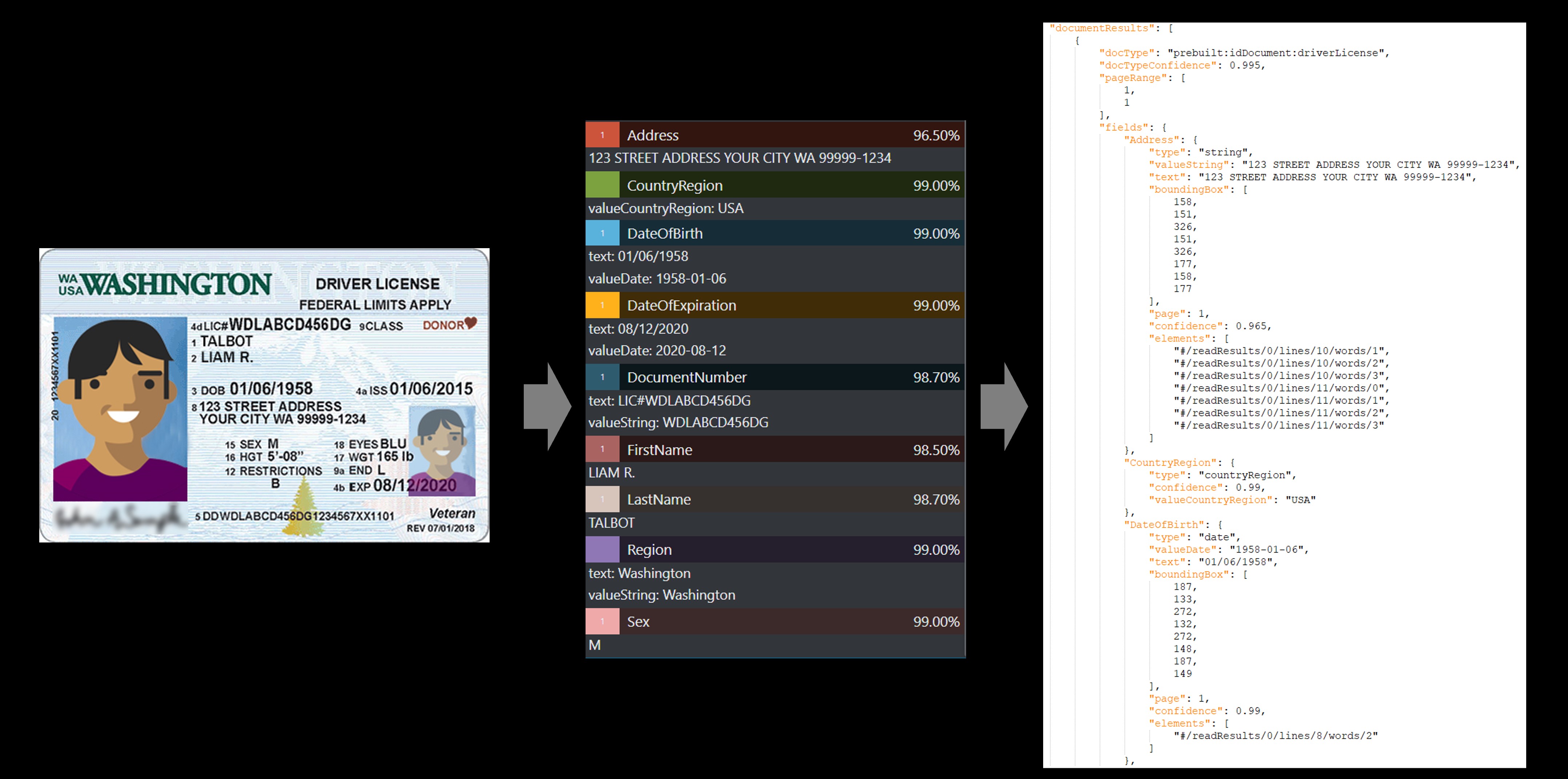
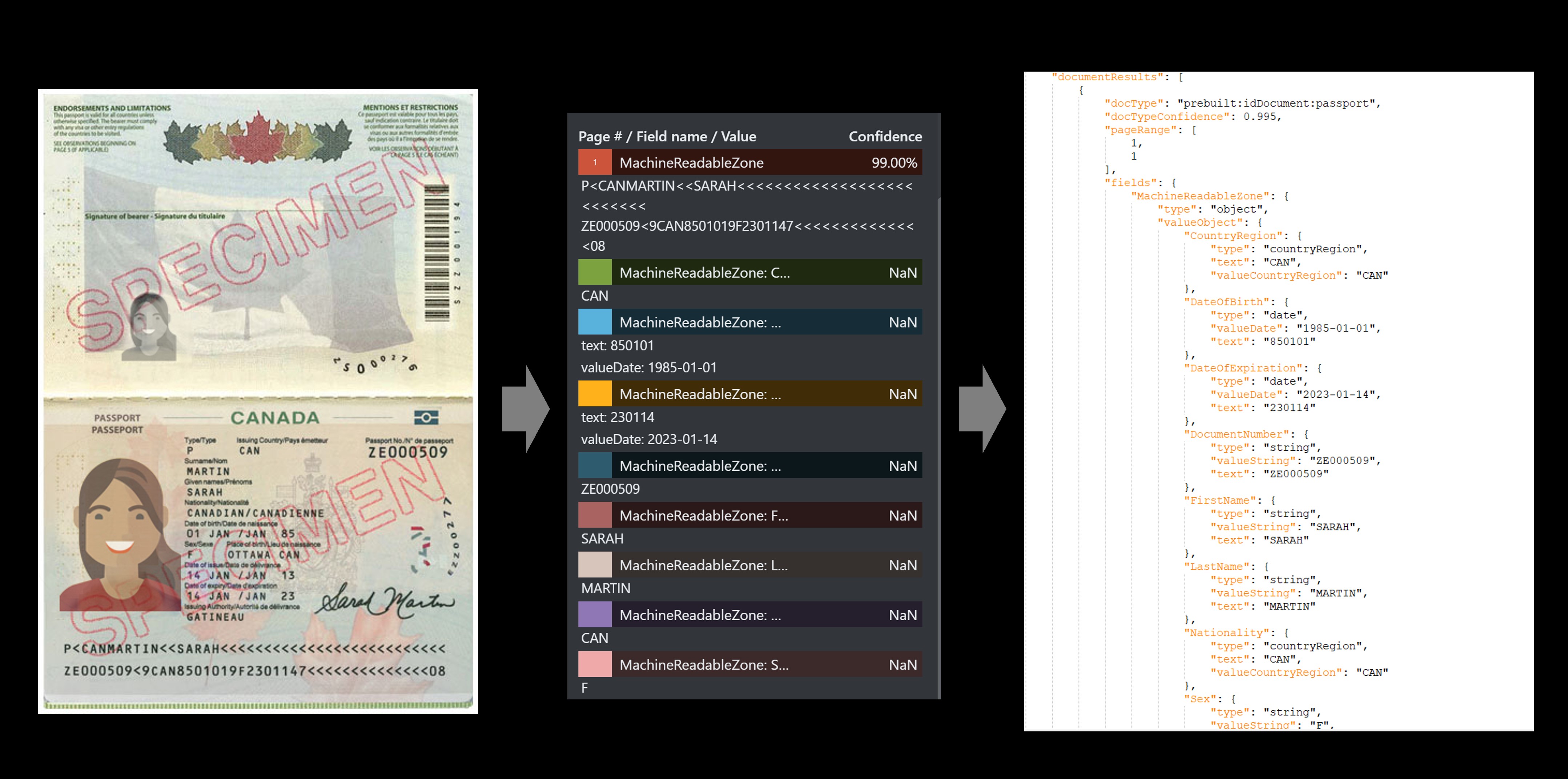
O serviço de IDs predefinidas extrai valores importantes de passaportes internacionais e carteiras de motorista dos EUA e retorna essas informações em uma resposta JSON estruturada e organizada.
Exemplo de carteira de motorista
Exemplo de passaporte
Opções de desenvolvimento
A Informação de Documentos v4.0: 2024-11-30 (GA) oferece suporte às seguintes ferramentas, aplicativos e bibliotecas:
| Recurso | Recursos | ID do Modelo |
|---|---|---|
| Modelo de documento de identificação | • Estúdio da Informação de Documentos • API REST • SDK do C# • SDK do Python • SDK do Java • SDK do JavaScript |
prebuilt-idDocument |
A Informação de Documentos v3.1 dá suporte às seguintes ferramentas, aplicativos e bibliotecas:
| Recurso | Recursos | ID do Modelo |
|---|---|---|
| Modelo de documento de identificação | • Estúdio da Informação de Documentos • API REST • SDK do C# • SDK do Python • SDK do Java • SDK do JavaScript |
prebuilt-idDocument |
A Informação de Documentos v3.0 dá suporte às seguintes ferramentas, aplicativos e bibliotecas:
| Recurso | Recursos | ID do Modelo |
|---|---|---|
| Modelo de documento de identificação | • Estúdio da Informação de Documentos • API REST • SDK do C# • SDK do Python • SDK do Java • SDK do JavaScript |
prebuilt-idDocument |
O Document Intelligence v2.1 dá suporte às seguintes ferramentas, aplicativos e bibliotecas:
| Recurso | Recursos |
|---|---|
| Modelo de documento de identificação | ● Ferramenta de rotulagem da Informação de Documentos • API REST • SDK da biblioteca de clientes • Contêiner do Docker da Informação de Documentos |
Requisitos de entrada
Formatos de arquivo com suporte:
Modelar PDF Image,: JPEG/JPG,PNG,BMP,TIFF,HEIFMicrosoft Office:
Word (DOCX), Excel (XLSX), PowerPoint (PPTX), HTMLLer ✔ ✔ ✔ Layout ✔ ✔ ✔ Documento geral ✔ ✔ Predefinida ✔ ✔ Extração personalizada ✔ ✔ Classificação personalizada ✔ ✔ ✔ Para ter melhores resultados, forneça uma foto clara ou uma digitalização de alta qualidade por documento.
Para PDF e TIFF, até 2.000 páginas podem ser processadas (com uma assinatura de camada gratuita, apenas as duas primeiras páginas são processadas).
O tamanho do arquivo para análise de documentos é de 500 MB para a camada paga (S0) e
4MB para a camada gratuita (F0).As dimensões da imagem devem estar entre 50 x 50 pixels e 10.000 x 10.000 pixels.
Se os PDFs estiverem com bloqueio de senha, você deverá remover o bloqueio antes do envio.
A altura mínima do texto a ser extraído é de 12 pixels para uma imagem de 1.024 x 768 pixels. Essa dimensão corresponde a aproximadamente
8pontos de texto a 150 pontos por polegada (DPI).Para treinamento de modelo personalizado, o número máximo de páginas para dados de treinamento é 500 para o modelo de modelo personalizado e 50.000 para o modelo neural personalizado.
Para o treinamento do modelo de extração personalizado, o tamanho total dos dados de treinamento é de 50 MB para o modelo de modelo e
1GB para o modelo neural.Para o treinamento de modelo de classificação personalizado, o tamanho total dos dados de treinamento é de
1GB, com um máximo de 10.000 páginas. Para 2024-11-30 (GA), o tamanho total dos dados de treinamento é2GB com um máximo de 10.000 páginas.
Formatos de arquivo com suporte: JPEG, PNG, PDF e TIFF.
Número de páginas com suporte para arquivos PDF e TIFF: até duas mil páginas ou apenas as duas primeiras páginas para assinantes da camada Gratuita.
Tamanho do arquivo com suporte: inferior a 50 MB no total; mínimo de pixels: 50 x 50 px; máximo de pixels: 10.000 x 10.000 px.
Extração de dados de modelo de documentação de ID
Extrair dados, inclusive nome, data de nascimento e data de validade, de documentos de identificação. Você precisa dos seguintes recursos:
Uma assinatura do Azure — você pode criar uma gratuitamente.
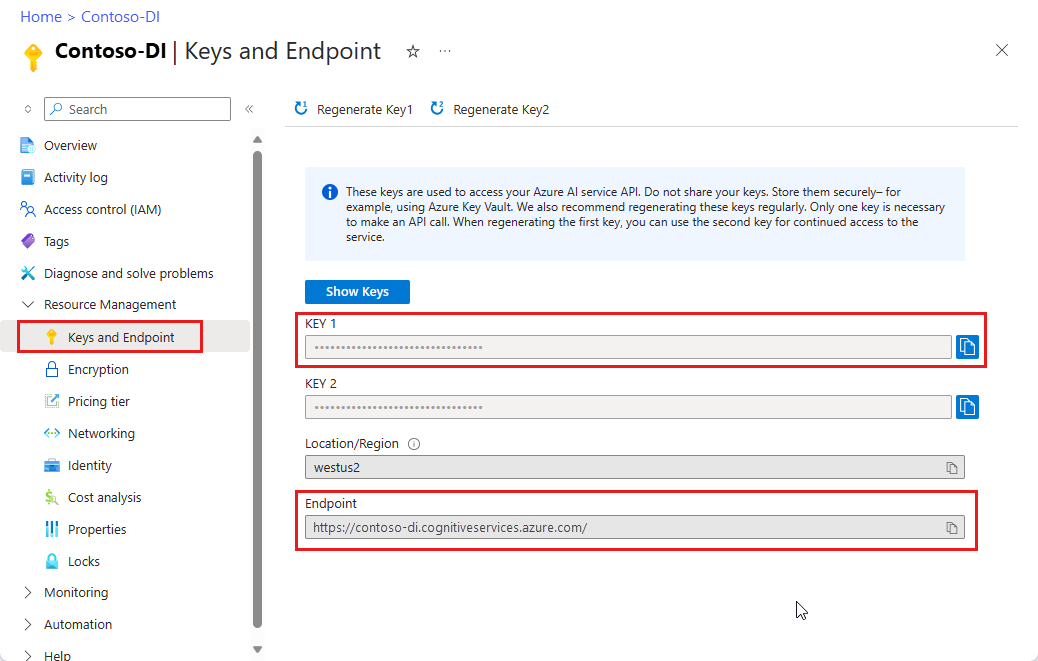
Uma instância da Informação de Documentos no portal do Azure. Você pode usar o tipo de preço gratuito (
F0) para experimentar o serviço. Depois que o recurso for implantado, selecione Ir para o recurso para obter a chave e o ponto de extremidade.
Observação
O Estúdio da Informação de Documentos está disponível com APIs v3.1 e v3.0 e versões posteriores.
Na página inicial do Estúdio da Informação de Documentos, selecione documentos de identidade.
Você pode analisar o documento de amostra ou carregar seus próprios arquivos.
Selecione o botão Executar análise e, se necessário, configure as opções Analisar :

Ferramenta de Rotulagem de Amostra da Informação de Documentos
Navegue até a Ferramenta de Exemplo da Informação de Documentos.
Na página inicial da ferramenta de exemplos, selecione o bloco Usar modelo predefinido para obter dados.
Selecione o Tipo de Formulário que deseja analisar no menu suspenso.
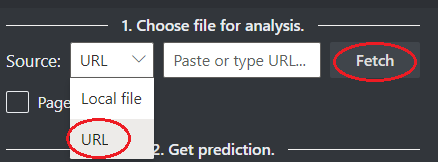
Escolha um URL para o arquivo que você gostaria de analisar, usando as opções abaixo:
No campo Origem , selecione URL no menu suspenso, cole a URL selecionada e selecione o botão Buscar.
No campo Ponto de extremidade do serviço Informação de Documentos, cole o ponto de extremidade obtido com a assinatura da Informação de Documentos.
No campo chave, cole a chave obtida do recurso Informação de Documentos.

Selecione Executar análise. A ferramenta de etiquetagem de exemplo da Informação de Documentos chama a API predefinida para Analisar Layout e analisará o documento.
Veja os resultados: confira os pares chave-valor extraídos, os itens de linha, o texto realçado extraído e as tabelas detectadas.
Baixe o arquivo de saída JSON para exibir os resultados detalhados.
- O nó "readResults" contém cada linha de texto com seu respectivo posicionamento de retângulo delimitador na página.
- O nó "selectionMarks" mostra cada marca de seleção (caixa de seleção, marca de opção) e indica se o status é marcado ou não marcado.
- A seção "pageResults" inclui as tabelas extraídas. Para cada tabela, a Informação de Documentos extrai o índice de texto, de linha e de coluna, abrangência de linha e coluna, caixa delimitadora e muito mais.
- O campo "documentResults" contém as informações de pares chave/valor e as informações de itens de linha para as partes mais relevantes do documento.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Observação
A ferramenta de Rotulagem de Exemplo não é compatível com o formato de arquivo BMP. Essa é uma limitação da ferramenta, não do Serviço de Inteligência de Documentos.
Extrações de campo
Para campos de extração de documentos com suporte, consulte a página de esquema de modelo de documento de ID em nosso repositório de exemplo do GitHub.
Tipos de documento compatíveis
Atualmente, o modelo de documento de ID dá suporte a carteiras de motorista dos EUA e à página biográfica de extração de passaportes internacionais (excluindo vistos e outros documentos de viagem).
Campos extraídos
| Nome | Tipo | Descrição | Valor |
|---|---|---|---|
| País | country | O código do país em conformidade com o padrão ISO 3166 | "EUA" |
| DateOfBirth | date | Nascimento no formato DD-MM-AAAA | "01-01-1980" |
| DateOfExpiration | date | Data de validade no formato DD-MM-AAAA | "05-05-2019" |
| DocumentNumber | string | Números relevantes do passaporte, da carteira de motorista etc. | "340020013" |
| Nome | string | O primeiro nome e nome do meio extraídos, se aplicável | "JENNIFER" |
| LastName | string | Sobrenome extraído | "BROOKS" |
| Nacionalidade | country | O código do país em conformidade com o padrão ISO 3166 | "EUA" |
| Gênero | gender | Os possíveis valores extraídos incluem: "M" "F" "X" | "F" |
| MachineReadableZone | objeto | MRZ extraído do passaporte, incluindo duas linhas de 44 caracteres cada |
"P<USABROOKS<<JENNIFER<<<<<<<<<<<<<<<<<<<<<<< 3400200135USA8001014F1905054710000307<715816" |
| DocumentType | string | Tipo de documento, como passaporte e carteira de motorista | "passaporte" |
| Endereço | string | Endereço extraído (somente da carteira de motorista) | "ENDEREÇO Nº 123 SUA CIDADE WA 99999-1234" |
| Região | string | Informações extraídas, como região, estado, província etc. (somente da carteira de motorista) | "Washington" |
Guia de migração
- Siga nosso Guia de migração da Informação de Documentos v3.1 para saber como usar a versão v3.0 em seus aplicativos e fluxos de trabalho.
Próximas etapas
Experimente processar seus próprios formulários e documentos com o Estúdio da Informação de Documentos.
Execute um início rápido do serviço Informação de Documentos e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.
Tente processar seus próprios formulários e documentos com a ferramenta Rotulagem de Amostra da Informação de Documentos.
Execute um início rápido do serviço Informação de Documentos e comece a criar um aplicativo de processamento de documentos na linguagem de desenvolvimento de sua escolha.