Este artigo descreve o processo de design, os princípios e as opções de tecnologia para usar o Azure Synapse e criar uma solução de data lakehouse segura. Nosso foco são as considerações de segurança e as decisões técnicas essenciais.
Apache®, Apache Spark® e o logotipo da chama são marcas registradas ou marcas comerciais da Apache Software Foundation nos Estados Unidos e/ou em outros países. O uso desta marca não implica aprovação por parte da Apache Software Foundation.
Arquitetura
O diagrama a seguir mostra a arquitetura da solução de data lakehouse. Ela foi projetada para controlar as interações entre os serviços de modo a mitigar as ameaças à segurança. As soluções irão variar, dependendo dos requisitos funcionais e de segurança.

Baixe um Arquivo Visio dessa arquitetura.
Fluxo de dados
O fluxo de dados para a solução é mostrado no diagrama a seguir:

- Os dados são carregados a partir da fonte dos dados para a zona de destino dos dados, seja para o Armazenamento de Blobs do Azure ou para um compartilhamento de arquivos fornecido pelos Arquivos do Azure. Os dados são carregados por um programa ou sistema de upload em lote. Os dados sendo transmitidos são capturados e armazenados no Armazenamento de Blobs usando o recurso Capturar dos Hubs de Eventos do Azure. Podem existir várias fontes de dados. Por exemplo, várias fábricas diferentes podem carregar os dados de suas operações. Para obter informações sobre como proteger o acesso ao Armazenamento de Blobs, compartilhamentos de arquivos e outros recursos de armazenamento, confira as Recomendações de segurança para o Armazenamento de Blobs e Como planejar uma implantação dos Arquivos do Azure.
- A chegada do arquivo de dados é o sinal para o Azure Data Factory começar a processar os dados e armazená-los no data lake na zona de dados principal. Carregar dados na zona de dados principal do Azure Data Lake protege contra a exfiltração de dados.
- O Azure Data Lake armazena os dados brutos que são obtidos de diversas fontes. É protegido por regras de firewall e redes virtuais. Além disso, bloqueia todas as tentativas de conexão provenientes da internet pública.
- A chegada de dados no data lake dispara o pipeline do Azure Synapse, ou um gatilho cronometrado executa o trabalho de processamento de dados. O Apache Spark no Azure Synapse é ativado e executa um trabalho ou notebook do Spark. Além disso, orquestra o fluxo do processo de dados no data lakehouse. Os pipelines do Azure Synapse convertem dados da Zona Bronze para a Zona Prata e, em seguida, para a Zona Ouro.
- Um trabalho ou notebook do Spark executa o trabalho de processamento de dados. A curadoria de dados ou um trabalho de treinamento de machine learning também podem ser executados no Spark. Os dados estruturados na Zona Ouro são armazenados no formatoDelta Lake.
- Um pool de SQL sem servidor cria tabelas externas que usam os dados armazenados no Delta Lake. O pool de SQL sem servidor fornece um mecanismo de consulta SQL poderoso e eficiente e pode ser compatível com contas de usuário do SQL tradicionais ou contas de usuário do Microsoft Entra.
- O Power BI se conecta ao pool de SQL sem servidor para visualizar os dados. O Power BI cria relatórios ou painéis de controle usando os dados no data lakehouse.
- Analistas ou cientistas de dados podem entrar no Azure Synapse Studio para:
- Aprimorar ainda mais os dados.
- Analisar para obter insights de negócios.
- Treinar o modelo de machine learning.
- Os aplicativos de negócios se conectam a um pool de SQL sem servidor e usam os dados para dar suporte a outros requisitos de operações de negócios.
- O Azure Pipelines executa o processo de CI/CD, que compila, testa e implanta a solução automaticamente. O recurso foi projetado para minimizar a intervenção humana durante o processo de implantação.
Componentes
Veja a seguir os principais componentes dessa solução de data lakehouse:
- Azure Synapse
- Arquivos do Azure
- Hubs de Eventos
- Armazenamento de Blobs
- Armazenamento do Azure Data Lake
- Azure DevOps
- Power BI
- Data Factory
- Azure Bastion
- Azure Monitor
- Microsoft Defender para Nuvem
- Azure Key Vault
Alternativas
- Se precisar processar dados em tempo real, você pode, em vez de armazenar arquivos individuais na zona de destino dos dados, usar o Fluxo Estruturado do Apache para receber o fluxo de dados dos Hubs de Eventos e processá-lo.
- Se os dados tiverem uma estrutura complexa e exigirem consultas SQL complexas, pense em armazená-los em um pool de SQL dedicado em vez de um pool de SQL sem servidor.
- Se os dados contiverem muitas estruturas de dados hierárquicas — por exemplo, tiverem uma estrutura JSON grande — talvez você prefira armazená-los no Azure Synapse Data Explorer.
Detalhes do cenário
O Azure Synapse Analytics é uma plataforma de dados versátil que dá suporte ao armazenamento de dados corporativo, análise de dados em tempo real, pipelines, processamento de dados de séries temporais, aprendizado de máquina e governança de dados. Para dar suporte a esses recursos, a plataforma integra várias tecnologias diferentes, como, por exemplo:
- Data warehouse corporativo
- Pools de SQL sem servidor
- Apache Spark
- Pipelines
- Data Explorer
- Recursos de machine learning
- Governança de dados unificada do Microsoft Purview
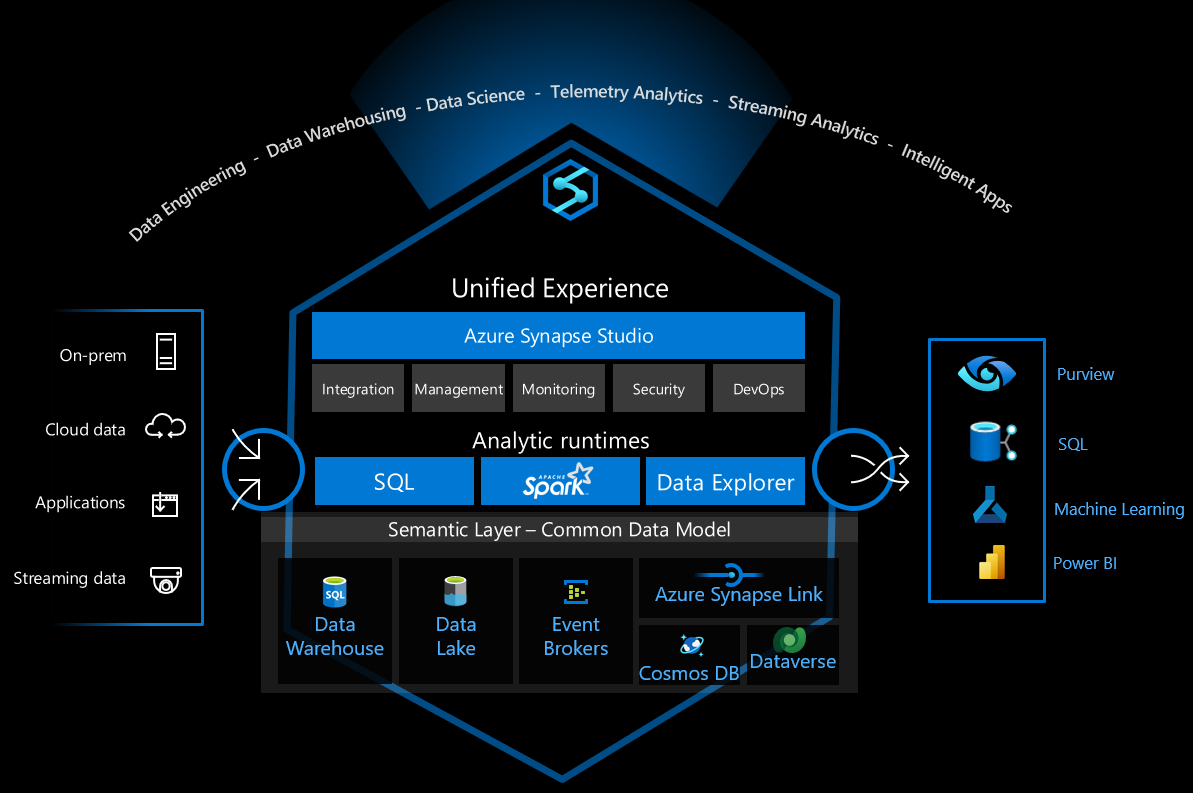
Esses recursos abrem muitas possibilidades, mas existem muitas opções técnicas a serem feitas para configurar a infraestrutura com segurança para um uso seguro.
Este artigo descreve o processo de design, os princípios e as opções de tecnologia para usar o Azure Synapse e criar uma solução de data lakehouse segura. Nosso foco são as considerações de segurança e as decisões técnicas essenciais. A solução usa os seguintes serviços do Azure:
- Azure Synapse
- Pools de SQL sem servidor do Azure Synapse
- Apache Spark no Azure Synapse Analytics
- Pipelines do Azure Synapse
- Azure Data Lake
- Azure DevOps.
O objetivo é fornecer diretrizes sobre a criação de uma plataforma de data lakehouse segura e econômica para uso corporativo e fazer com que as tecnologias funcionem juntas de forma integrada e segura.
Possíveis casos de uso
Um data lakehouse é uma arquitetura de gerenciamento de dados moderna que combina as características de eficiência econômica, dimensionamento e flexibilidade de um data lake aos recursos de gerenciamento de dados e transações de um data warehouse. Um data lakehouse pode lidar com uma grande quantidade de dados e dar suporte a cenários de business intelligence e machine learning. Pode também processar dados de diversas estruturas e fontes de dados. Para obter mais informações, confira O que é o Lakehouse do Databricks?
Abaixo temos alguns casos de uso comuns para a solução que descrevemos aqui:
- Análise da telemetria da Internet das Coisas (IoT)
- Automação de fábricas inteligentes (para a fabricação)
- Acompanhamento de atividades e comportamento do consumidor (para o varejo)
- Gerenciamento de eventos e incidentes de segurança
- Monitoramento de logs de aplicativos e do comportamento de um aplicativo
- Processamento e análise de negócios de dados semiestruturados
Design de alto nível
Essa solução se concentra nas práticas de design e implementação de segurança na arquitetura. Pool de SQL sem servidor, Apache Spark no Azure Synapse, pipelines do Azure Synapse, Data Lake Storage e Power BI são os principais serviços usados para implementar o padrão do data lakehouse.
Aqui temos a arquitetura do design da solução de alto nível:

Escolha o foco de segurança
Iniciamos o design de segurança usando a Ferramenta de Modelagem de Ameaças. A ferramenta nos ajudou a:
- Nos comunicarmos com os stakeholders do sistema com relação aos possíveis riscos.
- Definir o limite de confiança no sistema.
Com base nos resultados da modelagem de ameaças, selecionamos as seguintes áreas de segurança como nossas principais prioridades:
- Controle de Acesso e Identidade
- Proteção de rede
- Segurança de DevOps
Projetamos os recursos de segurança e as alterações de infraestrutura para proteger o sistema ao mitigarmos os principais riscos de segurança identificados para essas prioridades principais.
Para obter detalhes sobre o que deve ser verificado e levado em conta, confira:
- Segurança no Cloud Adoption Framework da Microsoft para o Azure
- Controle de acesso
- Proteção de ativos
- Segurança de inovações
Plano de proteção de ativos e rede
Um dos mais importantes princípios de segurança no Cloud Adoption Framework é o princípio de Confiança Zero: ao projetar a segurança para qualquer componente ou sistema, reduza o risco de os invasores expandirem seu acesso ao supor que outros recursos na organização estejam comprometidos.
Com base no resultado da modelagem de ameaças, a solução adota a recomendação de implantação por microssegmentação na confiança zero e define diversos limites de segurança. A Rede Virtual do Azure e a proteção contra exfiltração de dados do Azure Synapse são as principais tecnologias usadas para implementar o limite de segurança de modo a proteger ativos de dados e componentes críticos.
Devido ao fato de o Azure Synapse ser composto por várias tecnologias diferentes, precisamos fazer o seguinte:
Identificar os componentes do Synapse e os serviços relacionados que são usados no projeto.
O Azure Synapse é uma plataforma de dados versátil que pode lidar com muitas necessidades de processamento de dados diferentes. Primeiro, precisamos decidir quais componentes do Azure Synapse são usados no projeto para que possamos planejar como protegê-los. Também precisamos determinar quais outros serviços se comunicam com esses componentes do Azure Synapse.
Os principais componentes da arquitetura do data lakehouse são:
- SQL sem servidor do Azure Synapse
- Apache Spark no Azure Synapse
- Pipelines do Azure Synapse
- Data Lake Storage
- Azure DevOps
Definir os comportamentos de comunicação legal entre os componentes.
Precisamos definir os comportamentos de comunicação permitidos entre os componentes. Por exemplo, queremos que o mecanismo do Spark se comunique diretamente com a instância de SQL dedicada ou que se comunique por meio de um proxy, como o pipeline de Integração de Dados do Azure Synapse ou o Data Lake Storage?
Com base no princípio de Confiança Zero, a comunicação será bloqueada se não houver uma necessidade de negócios envolvendo a interação. Por exemplo, iremos impedir que um mecanismo do Spark que esteja em um locatário desconhecido se comunique diretamente com o Data Lake Storage.
Escolher a solução de segurança adequada para implementar os comportamentos de comunicação definidos.
No Azure, várias tecnologias de segurança podem implementar os comportamentos de comunicação de serviço definidos. Por exemplo, no Data Lake Storage você pode usar uma lista de permissões de endereços IP para controlar o acesso a um data lake, mas pode também escolher quais redes virtuais, serviços do Azure e instâncias de recursos são permitidos. Cada método de proteção fornece uma proteção de segurança diferente. Escolha com base nas suas necessidades de negócios e nas limitações ambientais. A configuração usada nessa solução é descrita na próxima seção.
Implementar a detecção de ameaças e defesas avançadas para recursos críticos.
No caso de recursos críticos, é melhor implementar a detecção de ameaças e defesas avançadas. Os serviços ajudam a identificar ameaças e disparar alertas, para que o sistema possa notificar usuários sobre violações de segurança.
Pense em adotar as seguintes técnicas para proteger melhor suas redes e ativos:
Implantar redes de perímetro para fornecer zonas de segurança aos pipelines de dados
Quando uma carga de trabalho de pipeline de dados requerer acesso a dados externos e à zona de destino de dados, será melhor implementar uma rede de perímetro e separá-la com um pipeline do tipo extrair, transformar e carregar (ETL).
Habilitar o Defender para Nuvem para todas as contas de armazenamento
O Defender para Nuvem dispara alertas de segurança ao detectar tentativas incomuns e possivelmente prejudiciais de acesso ou exploração de contas de armazenamento. Para obter mais informações, confira Configurar o Microsoft Defender para Armazenamento.
Bloquear uma conta de armazenamento para evitar exclusões ou alterações de configuração mal-intencionadas
Para obter mais informações, consulte aplicar um bloqueio de Azure Resource Manager a uma conta de armazenamento.
Arquitetura com proteção de rede e de ativos
A tabela a seguir descreve os comportamentos de comunicação definidos e as tecnologias de segurança escolhidas para essa solução. As escolhas foram baseadas nos métodos discutidos no Plano de proteção de rede e de ativos.
| De (Cliente) | Para (Service) | Comportamento | Configuração | Observações | |
|---|---|---|---|---|---|
| Internet | Data Lake Storage | Negar tudo | Regra de firewall: negar por padrão | Padrão: "Negar" | Regra de firewall: Negar por Padrão |
| Pipeline do Azure Synapse/Spark | Data Lake Storage | Permitir (instância) | Rede virtual: ponto de extremidade privado gerenciado (Data Lake Storage) | ||
| SQL do Synapse | Data Lake Storage | Permitir (instância) | Regra de firewall: instâncias de recurso (SQL do Synapse) | O SQL do Synapse precisa acessar o Data Lake Storage usando identidades gerenciadas | |
| Agente do Azure Pipelines | Data Lake Storage | Permitir (instância) | Regra de firewall: redes virtuais selecionadas Ponto de extremidade de serviço: armazenamento |
Para ignorar testes de integração: "AzureServices" (regra de firewall) |
|
| Internet | Workspace do Synapse | Negar tudo | Regra de Firewall | ||
| Agente do Azure Pipelines | Workspace do Synapse | Permitir (instância) | Rede virtual: ponto de extremidade privado | Requer três pontos de extremidade privados (Desenvolvimento, SQL sem servidor e SQL dedicado) | |
| Rede virtual gerenciada do Synapse | Internet ou locatário não autorizado do Azure | Negar tudo | Rede virtual: proteção contra exfiltração de dados do Synapse | ||
| Pipeline do Synapse/Spark | Key Vault | Permitir (instância) | Rede virtual: ponto de extremidade privado gerenciado (Key Vault) | Padrão: "Negar" | |
| Agente do Azure Pipelines | Key Vault | Permitir (instância) | Regra de firewall: redes virtuais selecionadas * Ignorar ponto de extremidade de |
serviço — Key Vault: "AzureServices" (regra de firewall) | |
| Funções do Azure | SQL sem servidor do Synapse | Permitir (instância) | Rede virtual: ponto de extremidade privado (SQL sem servidor do Synapse) | ||
| Pipeline do Synapse/Spark | Azure Monitor | Permitir (instância) | Rede virtual: ponto de extremidade privado (Azure Monitor) |
Por exemplo, dentro do plano queremos fazer o seguinte:
- Criar um workspace do Azure Synapse com uma rede virtual gerenciada.
- Proteger a saída de dados dos workspaces do Azure Synapse usando a Proteção contra exfiltração de dados dos workspaces do Azure Synapse.
- Gerenciar a lista de locatários aprovados do Microsoft Entra para o workspace do Azure Synapse.
- Configurar regras de rede para permitir o tráfego para a conta de Armazenamento de redes virtuais selecionadas, somente acesso, e desabilitar o acesso à rede pública.
- Usar Pontos de Extremidade Privados Gerenciados para conectar ao data lake uma rede virtual que seja gerenciada pelo Azure Synapse.
- Usar aInstância do Recurso para conectar o SQL do Azure Synapse ao data lake com segurança.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, um conjunto de princípios orientadores que você pode usar para aprimorar a qualidade de uma carga de trabalho. Para obter mais informações, confira Microsoft Azure Well-Architected Framework.
Segurança
Para obter informações sobre o pilar de segurança da Well-Architected Framework, confira Segurança.
Identidade e controle de acesso
O sistema tem vários componentes. Cada um deles requer uma configuração de gerenciamento de acesso e identidade (IAM) diferente. Essas configurações precisam colaborar entre si para fornecer uma experiência de usuário simplificada. Portanto, quando implementamos o controle de identidade e acesso usamos as diretrizes de design a seguir.
Escolha uma solução de identidade para diferentes camadas de controle de acesso
- O sistema tem quatro soluções de identidade diferentes.
- Conta SQL (SQL Server)
- Entidade de serviço (Microsoft Entra ID)
- Identidade gerenciada (Microsoft Entra ID)
- Conta de usuário (Microsoft Entra ID)
- O sistema tem quatro camadas de controle de acesso diferentes.
- Camada de acesso do aplicativo: escolha a solução de identidade para as Funções de AP.
- Camada de acesso à Tabela/BD do Azure Synapse: escolha a solução de identidade para as funções nos bancos de dados.
- Camada de acesso do Azure Synapse a recursos externos: escolha a solução de identidade para acessar recursos externos.
- Camada de acesso do Data Lake Storage: escolha a solução de identidade para controlar o acesso aos arquivos no armazenamento.

Uma parte crucial do controle de identidade e acesso é escolher a solução de identidade certa para cada camada de controle de acesso. Os princípios de design de segurança da Azure Well-Architected Framework sugerem usar controles nativos e impulsionar a simplicidade. Portanto, essa solução usa a conta de usuário do usuário final do Microsoft Entra no aplicativo e as camadas de acesso do BD do Azure Synapse. Ela usa as soluções de IAM nativas do fabricante original e fornece um controle de acesso refinado. A camada de acesso a recursos externos do Azure Synapse e a camada de acesso do Data Lake usam a identidade gerenciada no Azure Synapse para simplificar o processo de autorização.
- O sistema tem quatro soluções de identidade diferentes.
Considere usar o acesso de privilégio mínimo
Um princípio orientador da Confiança Zero sugere fornecer um acesso just-in-time e just-enough aos recursos críticos. Confira o Privileged Identity Management (PIM) do Microsoft Entra para aprimorar sua a segurança no futuro.
Proteja o serviço vinculado
Os serviços vinculados definem as informações de conexão que são necessárias para que um serviço se conecte a recursos externos. É importante proteger as configurações de serviços vinculados.
- Crie um serviço vinculado do Azure Data Lake com um Link Privado.
- Use a identidade gerenciada como o método de autenticação nos serviços vinculados.
- Use o Azure Key Vault para proteger as credenciais de acesso ao serviço vinculado.

Avaliação de pontuação de segurança e detecção de ameaças
Para entender o status de segurança do sistema, a solução usa o Microsoft Defender para Nuvem para avaliar a segurança da infraestrutura e detectar problemas de segurança. O Microsoft Defender para Nuvem é uma ferramenta para gerenciamento de postura de segurança e proteção contra ameaças. A ferramenta pode proteger as cargas de trabalho em execução no Azure, híbridas e em outras plataformas de nuvem.

O plano gratuito do Defender para Nuvem é habilitado automaticamente em todas as suas assinaturas do Azure quando você visita as páginas do Defender para Nuvem no portal do Azure pela primeira vez. Recomendamos fortemente que você o habilite para obter sua avaliação da postura de segurança na Nuvem e nossas sugestões. O Microsoft Defender para Nuvem fornecerá sua pontuação de segurança e algumas diretrizes sobre como reforçar a segurança para suas assinaturas.
Se a solução precisar de recursos avançados de gerenciamento de segurança e detecção de ameaças, como detecção e alerta de atividades suspeitas, você poderá habilitar a proteção da carga de trabalho de nuvem individualmente para recursos diferentes.
Otimização de custo
Para obter informações sobre o pilar de otimização de custos da Well-Architected Framework, confira Otimização de custos.
Um dos principais benefícios da solução de data lakehouse é sua arquitetura dimensionável e economicamente viável. A maioria dos componentes da solução usa uma cobrança baseada em consumo e será dimensionada automaticamente. Nessa solução, todos os dados são armazenados no Data Lake Storage. Você só pagará para armazenar os dados se não executar nenhuma consulta nem processar nenhum dado.
O preço dessa solução depende do uso dos seguintes recursos essenciais:
- SQL Sem Servidor do Azure Synapse: usa a cobrança baseada em consumo, você paga apenas pelo que usar.
- Apache Spark no Azure Synapse: usa a cobrança baseada em consumo, você paga apenas pelo que usar.
- Pipelines do Azure Synapse: usam a cobrança baseada em consumo, você paga apenas pelo que usar.
- Azure Data Lakes: usam a cobrança baseada em consumo, você paga apenas pelo que usar.
- Power BI: o custo é baseado no tipo de licença que você comprar.
- Link Privado: usa a cobrança baseada em consumo, você paga apenas pelo que usar.
Diferentes soluções de proteção de segurança adotam modos de custo diferentes. Você deve escolher a solução de segurança com base nas suas necessidades de negócios e nos custos da solução.
Você pode usar a Calculadora de Preços do Azure para estimar o custo da solução.
Excelência operacional
Para obter informações sobre o pilar de excelência operacional da Well-Architected Framework, confira Excelência operacional.
Use um agente de pipeline auto-hospedado habilitado para rede virtual para os serviços de CI/CD
O agente de pipeline do Azure DevOps padrão não é compatível com a comunicação por rede virtual porque usa um intervalo de endereços IP muito amplo. Essa solução implementa um agente auto-hospedado do Azure DevOps na rede virtual para que os processos de DevOps possam se comunicar com tranquilidade com os outros serviços da solução. As cadeias de conexão e os segredos para executar os serviços de CI/CD são armazenados em um cofre de chaves independente. Durante o processo de implantação, o agente auto-hospedado acessa o cofre de chaves na zona de dados principal para atualizar os segredos e as configurações dos recursos. Para obter mais informações, confira o documento Usar cofres de chaves separados. Essa solução também usa conjuntos de dimensionamento de VM para garantir que o mecanismo de DevOps possa se ampliado e reduzido automaticamente com base na carga de trabalho.

Implemente a verificação de segurança da infraestrutura e os testes de fumaça de segurança no pipeline de CI/CD
Uma ferramenta de análise estática para verificar os arquivos da infraestrutura como código (IaC) pode ajudar a detectar e evitar configurações incorretas que podem causar problemas de segurança ou conformidade. Os testes de fumaça de segurança garantem que as medidas vitais de segurança do sistema sejam habilitadas com sucesso, protegendo contra falhas de implantação.
- Use uma ferramenta de análise estática para verificar modelos de infraestrutura como código (IaC) de modo a detectar e evitar configurações incorretas que podem causar problemas de segurança ou conformidade. Use ferramentas como o Checkov ou o Terrascan para detectar e evitar riscos de segurança.
- Certifique-se de que o pipeline de CD lide com as falhas de implantação corretamente. Qualquer falha de implantação relacionada aos recursos de segurança deve ser tratada como uma falha crítica. O pipeline deve repetir a ação com falha ou interromper a implantação.
- Valide as medidas de segurança no pipeline de implantação executando os testes de fumaça de segurança. Os testes de fumaça de segurança, como validar o status de configuração de recursos implantados ou casos de teste que examinam cenários críticos de segurança, podem garantir que o design de segurança esteja funcionando conforme o esperado.
Colaboradores
Esse artigo é mantido pela Microsoft. Ele foi originalmente escrito pelos colaboradores a seguir.
Autor principal:
- Herman Wu | Engenheiro de Software Sênior
Outros colaboradores:
- Ian Chen | Líder e Engenheiro de Software Principal
- Jose Contreras | Engenheiro de Software Principal
- Roy Chan | Gerente e Engenheiro de Software Principal
Próximas etapas
- Documentação do produto do Azure
- Outros artigos
- O que é o Azure Synapse Analytics?
- Pool de SQL sem servidor no Azure Synapse Analytics
- Apache Spark no Azure Synapse Analytics
- Pipelines e atividades no Azure Data Factory e no Azure Synapse Analytics
- O que é Azure Synapse Data Explorer? (Visualização)
- Funcionalidades do Machine Learning no Azure Synapse Analytics
- O que é o Microsoft Purview?
- O Azure Synapse Analytics e o Azure Purview funcionam melhor juntos
- Introdução ao Azure Data Lake Storage Gen2
- O que é o Azure Data Factory?
- Série de postagens de blog sobre Padrões de Dados Atuais: Data Lakehouse
- O que é o Microsoft Defender para Nuvem?
- O Data Lakehouse, o Data Warehouse e uma arquitetura de Plataforma de Dados Moderna
- Boas práticas para organizar o lakehouse e workspaces do Azure Synapse
- Como entender os Pontos de Extremidade Privados do Azure Synapse
- Azure Synapse Analytics: novos insights sobre Segurança de Dados
- Linha de base de segurança do Azure para o pool de SQL dedicado do Azure Synapse (antigo SQL DW)
- Curso Básico de Segurança de Rede na Nuvem: Pontos de Extremidade de Serviço do Azure x Pontos de Extremidade Privados
- Como configurar o controle de acesso para o workspace do Azure Synapse
- Conectar-se ao Azure Synapse Studio usando Hubs de Link Privado do Azure
- Como implantar seus Artefatos de Workspace do Azure Synapse em um workspace de REDE VIRTUAL Gerenciada do Azure Synapse
- Integração e distribuição contínuas para um workspace do Azure Synapse Analytics
- Classificação de segurança no Microsoft Defender para Nuvem
- Melhores práticas para usar o Azure Key Vault
- Cenário da Adatum Corporation para gerenciamento e análise de dados no Azure