Failover e aplicação de patches para o Redis Gerenciado do Azure (versão prévia)
Para criar aplicativos cliente resilientes e bem-sucedidos, é crítico entender o failover no serviço do Redis Gerenciado do Azure (versão prévia). Um failover pode fazer parte das operações de gerenciamento planejadas ou ser causado por falhas de hardware ou rede não planejadas. Um uso comum do failover de cache vem quando o serviço de gerenciamento aplica um patch aos binários do Redis Gerenciado do Azure.
Neste artigo, você encontrará estas informações:
- O que é um failover?
- Como o failover ocorre durante a aplicação de patch.
- Como criar um aplicativo cliente resiliente.
O que é um failover?
Vamos começar com uma visão geral do failover para o Redis Gerenciado do Azure.
Um resumo rápido da arquitetura de cache
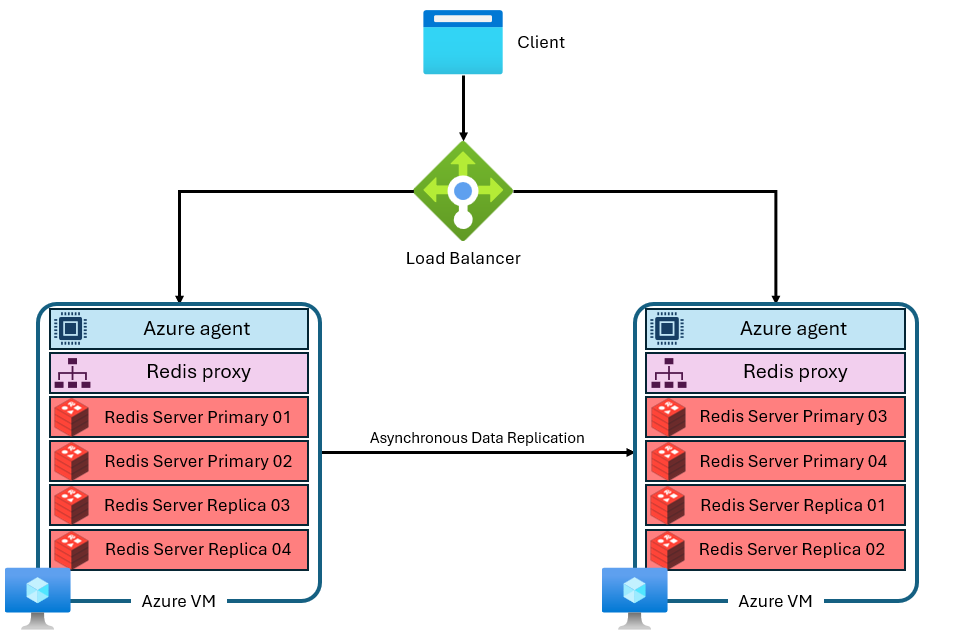
Um cache é construído com várias máquinas virtuais com endereços IP privados e separados. Cada máquina virtual (ou “nó”) executa vários processos de servidor Redis (chamados de “fragmentos”) em paralelo. Vários fragmentos permitem uma utilização mais eficiente de vCPUs em cada máquina virtual e maior desempenho. Nem todos os fragmentos principais do Redis estão na mesma VM/nó. Em vez disso, os fragmentos primários e de réplica são distribuídos entre ambos os nós. Como os fragmentos primários usam mais recursos de CPU do que fragmentos de réplica, essa abordagem permite que mais fragmentos primários sejam executados em paralelo. Cada nó tem um proxy de alto desempenho processo para gerenciar os fragmentos, lidar com o gerenciamento de conexões e disparar a autorrecuperação. Um fragmento pode estar inativo enquanto os outros permanecem disponíveis.
Detalhes detalhados da Arquitetura Redis Gerenciado do Azure podem ser encontrados aqui.
Explicação de um failover
Um failover ocorre quando um ou mais fragmentos de réplica se promovem para se tornarem fragmentos primários e os fragmentos primários antigos fecham conexões existentes. Um failover pode ser planejado ou não planejado.
Um failover planejado ocorre durante dois horários diferentes:
- Atualizações do sistema, como a adoção de patch do Redis ou atualizações do sistema operacional.
- Operações de gerenciamento, como dimensionamento e reinicialização.
Como os nós recebem aviso antecipado da atualização, eles podem trocar funções de maneira cooperativa e atualizar rapidamente o balanceador de carga da alteração. Um failover planejado normalmente termina em menos de 1 segundo.
Um failover não planejado pode ocorrer devido a falhas de hardware, falha de rede ou outras falhas inesperadas em um ou mais nós no cluster. Os fragmentos de réplica nos nós restantes se promoverão como primários para manter a disponibilidade, mas o processo leva mais tempo. Um shard de réplica deve primeiro detectar que seu shard primário não está disponível antes de iniciar o processo de failover. Para evitar um failover desnecessário, o shard de réplica também deve verificar se essa falha não planejada não é transitória ou local. Esse atraso na detecção significa que um failover não planejado normalmente termina dentro de 10 a 15 segundos.
Como a aplicação de patch ocorre?
O serviço de Redis Gerenciado do Azure para Redis atualiza regularmente seu cache com os recursos e as correções mais recentes da plataforma. Para aplicar patch a um cache, o serviço segue estas etapas:
- O serviço cria novas VMs atualizadas para substituir todas as VMs que estão sendo corrigidas.
- Em seguida, ele promove uma das novas VMs como líder de cluster.
- Um por um, todos os nós que estão sendo corrigidos são removidos do cluster. Todos os fragmentos nessas VMs serão rebaixados e migrados para uma das novas VMs.
- Por fim, todas as VMs que foram substituídas são excluídas.
A aplicação de patch é feita separadamente a cada fragmento de um cache clusterizado, sem fechar conexões com outro fragmento.
Vários caches no mesmo grupo de recursos e região também recebem patch um por vez. Os caches que estão em diferentes grupos de recursos ou regiões diferentes podem receber patch simultaneamente.
Como a sincronização de dados completa ocorre antes que o processo se repita, é improvável que ocorra para o seu cache. Você pode se proteger ainda mais contra a perda de dados exportando dados e habilitando a persistência.
Carga de cache adicional
Sempre que ocorrer um failover, os caches precisarão replicar dados de um nó para outro. Essa replicação causa algum aumento de carga na memória do servidor e na CPU. Se a instância de cache já estiver muito carregada, os aplicativos cliente poderão ter maior latência. Em casos extremos, os aplicativos cliente poderão receber exceções de tempo limite.
Como um failover afeta meu aplicativo cliente?
Os aplicativos cliente podem receber alguns erros do Redis Gereciado do Azure. O número de erros vistos por um aplicativo cliente depende de quantas operações estavam pendentes na conexão no momento do failover. Qualquer conexão roteada por meio do nó que fechou suas conexões apresentará erros.
Muitas bibliotecas de cliente podem mostrar diferentes tipos de erros quando as conexões são interrompidas, incluindo:
- Exceções de tempo limite
- Exceções de conexão
- Exceções de soquete
O número e o tipo de exceções dependem de que ponto no caminho do código a solicitação está quando o cache fecha suas conexões. Por exemplo, uma operação que envia uma solicitação, mas não recebeu uma resposta quando o failover ocorre, pode obter uma exceção de tempo limite. Novas solicitações no objeto de conexão fechado recebem exceções de conexão até que a reconexão ocorra com êxito.
A maioria das bibliotecas de cliente tenta se reconectar ao cache se elas estão configuradas para fazer isso. No entanto, bugs imprevistos ocasionalmente podem colocar os objetos de biblioteca em um estado irrecuperável. Se os erros persistirem por mais tempo do que uma quantidade de tempo pré-configurada, o objeto de conexão deverá ser recriado. No Microsoft.NET e em outras linguagens orientadas a objeto, é possível recriar a conexão sem reiniciar o aplicativo usando um padrão ForceReconnect.
Quais são as atualizações incluídas na manutenção?
A manutenção inclui estas atualizações:
- Atualizações do Servidor Redis: qualquer atualização ou patch dos binários do servidor Redis.
- Atualizações da VM (máquina virtual): todas as atualizações da máquina virtual que hospeda o serviço do Redis. As atualizações de VM incluem a aplicação de patch de componentes de software no ambiente de hospedagem para atualizar componentes de rede ou desativação.
A manutenção aparece na integridade do serviço no portal do Azure antes de um patch?
Não, a manutenção não aparece em integridade do serviço, no portal ou em qualquer outro local.
Alterações de configuração de rede do cliente
Determinadas alterações de configuração de rede do lado do cliente podem disparar erros de Nenhuma conexão disponível. Essas alterações podem incluir:
- Trocar o endereço IP virtual de um aplicativo cliente entre slots de produção e de preparo.
- Dimensionar o tamanho ou o número de instâncias do seu aplicativo.
Essas alterações podem causar um problema de conectividade que geralmente dura menos de um minuto. Seu aplicativo cliente provavelmente perde a conexão com outros recursos de rede externos, mas também com o serviço de Redis Gerenciado do Azure.
Resiliência de compilação
Você não pode evitar os failovers por completo. Em vez disso, projete seus aplicativos cliente para serem resilientes contra quebras de conexão e solicitações com falha. A maioria das bibliotecas de cliente se reconecta automaticamente ao ponto de extremidade em cache, mas poucas delas tentam repetir as solicitações com falha. Dependendo do cenário de aplicativo, pode fazer sentido usar a lógica de repetição com o backoff.
Como fazer tornar meu aplicativo resiliente?
Confira esses padrões de design para criar clientes resilientes, especialmente os padrões de disjuntor e de nova tentativa:
- Padrões de confiabilidade – Padrões de Design de Nuvem
- Diretrizes de nova tentativa para serviços do Azure – Melhores práticas para aplicativos de nuvem
- Implementar repetição com retirada exponencial