Tutorial: Detectar e analisar anomalias usando os recursos de aprendizado de máquina da KQL no Azure Monitor
A KQL (Linguagem de Consulta Kusto) inclui operadores de aprendizado de máquina, funções e plug-ins para análise de séries temporais, detecção de anomalias, previsão e análise de causa raiz. Use esses recursos da KQL para realizar análises de dados avançadas no Azure Monitor sem a sobrecarga de exportar dados para ferramentas externas de aprendizado de máquina.
Neste tutorial, você aprenderá como:
- Criar uma série temporal
- Identificar anomalias em uma série temporal
- Ajustar as configurações de detecção de anomalias para refinar os resultados
- Analisar a causa raiz de anomalias
Observação
Este tutorial fornece links para um ambiente de demonstração do Log Analytics no qual é possível executar os exemplos de consulta KQL. Os dados no ambiente de demonstração são dinâmicos, portanto, os resultados da consulta não são iguais aos resultados da consulta mostrados neste artigo. No entanto, é possível implementar as mesmas entidades de segurança e consultas KQL no seu próprio ambiente e em todas as ferramentas do Azure Monitor que usam KQL.
Pré-requisitos
- Uma conta do Azure com uma assinatura ativa. Crie uma conta gratuitamente.
- Um workspace com dados de log.
Permissões necessárias
Você deve ter permissões Microsoft.OperationalInsights/workspaces/query/*/read para os workspaces do Log Analytics que você consulta, conforme fornecido pela função interna Leitor do Log Analytics, por exemplo.
Criar uma série temporal
Use o operador make-series da KQL para criar uma série temporal.
Crie uma série temporal com base nos logs da tabela de uso, que contém informações sobre a quantidade de dados ingerida por cada tabela em um workspace a cada hora, incluindo dados faturáveis e não faturáveis.
Esta consulta usa make-series para traçar a quantidade total de dados faturáveis ingeridos por cada tabela no workspace todos os dias, nos últimos 21 dias:
Clique para executar a consulta
let starttime = 21d; // The start date of the time series, counting back from the current date
let endtime = 0d; // The end date of the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Include only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| render timechart // Renders results in a timechart
No gráfico resultante, é possível ver claramente algumas anomalias, por exemplo, nos tipos de dados AzureDiagnostics e SecurityEvent:
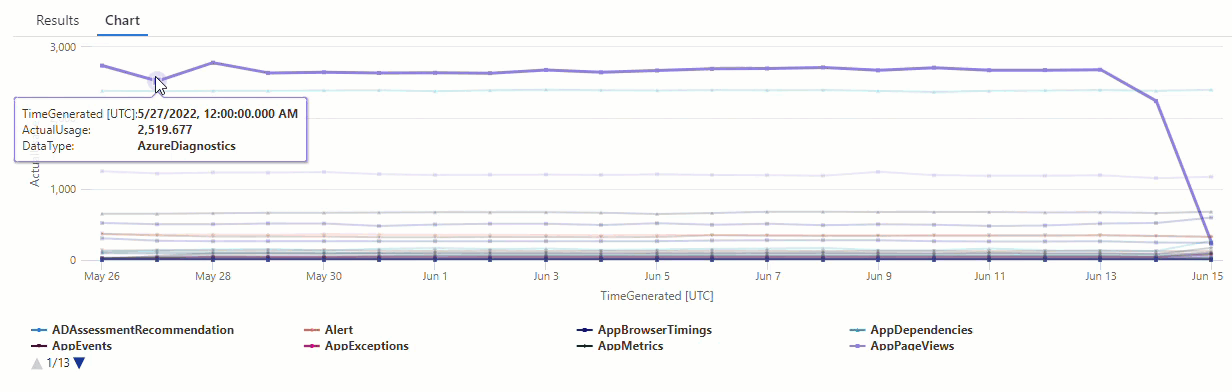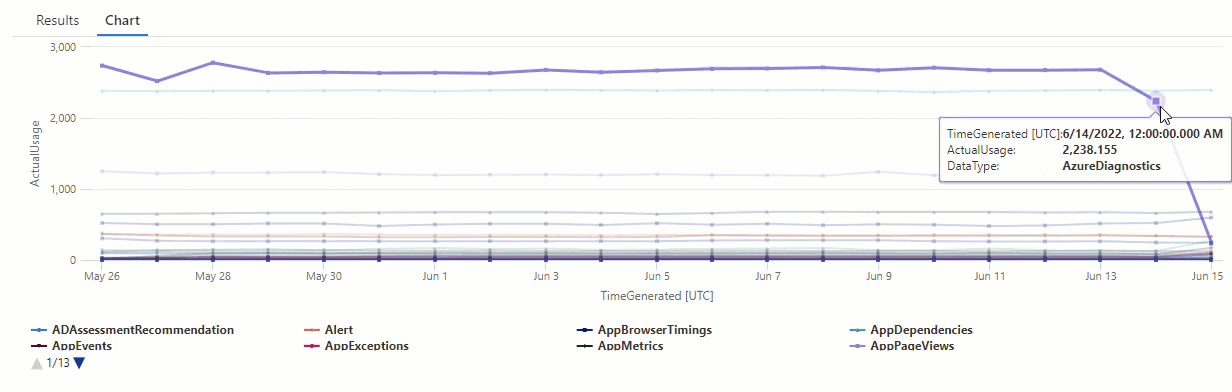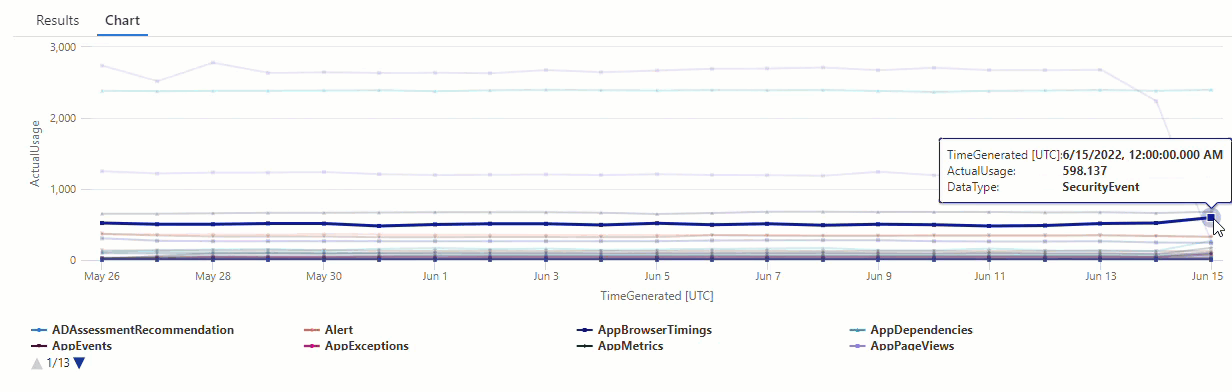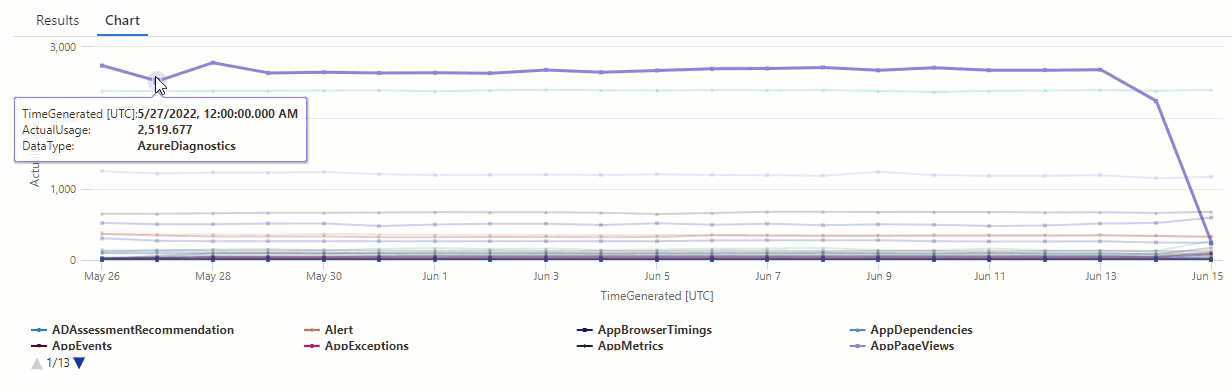
Em seguida, use uma função KQL para listar todas as anomalias em uma série temporal.
Observação
Para saber mais sobre a sintaxe e o uso de make-series, confira Operador make-series.
Encontrar anomalias em uma série temporal
A função series_decompose_anomalies() recebe uma série de valores como entrada e extrai as anomalias.
Forneça o conjunto de resultados da consulta de série temporal como entrada para a função series_decompose_anomalies():
Clique para executar a consulta
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage) // Scores and extracts anomalies based on the output of make-series
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Essa consulta retorna todas as anomalias de uso de todas as tabelas nas últimas três semanas:

Nos resultados da consulta, é possível ver que a função:
- Calcula um uso diário esperado para cada tabela.
- Compara o uso diário real com o uso esperado.
- Atribui uma pontuação de anomalia a cada ponto de dados, indicando a extensão do desvio entre o uso real e o esperado.
- Identifica anomalias positivas (
1) e negativas (-1) em cada tabela.
Observação
Para saber mais sobre a sintaxe e o uso de series_decompose_anomalies(), confira series_decompose_anomalies().
Ajustar as configurações de detecção de anomalias para refinar os resultados
É uma boa prática revisar os resultados da consulta inicial e fazer ajustes nela, se necessário. Os valores discrepantes nos dados de entrada podem afetar o aprendizado da função e exigir ajustes nas configurações de detecção de anomalias da função para obter resultados mais precisos.
Filtre os resultados da consulta series_decompose_anomalies() em busca de anomalias no tipo de dados AzureDiagnostics:

Os resultados mostram duas anomalias em 14 e 15 de junho. Compare esses resultados com o gráfico de nossa primeira consulta make-series, em que é possível ver outras anomalias em 27 e 28 de maio:

A diferença nos resultados ocorre porque a função series_decompose_anomalies() pontua anomalias em relação ao valor de uso esperado, que a função calcula com base no intervalo completo de valores na série de entrada.
Para obter resultados mais refinados da função, exclua o uso em 15 de junho (que é um valor discrepante em comparação com os outros da série) do processo de aprendizado da função.
A sintaxe da funçãoseries_decompose_anomalies() é:
series_decompose_anomalies (Series[Threshold,Seasonality,Trend,Test_points,AD_method,Seasonality_threshold])
O Test_points especifica o número de pontos no final da série para excluir do processo de aprendizagem (regressão).
Para excluir o último ponto de dados, defina Test_points como 1:
Clique para executar a consulta
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let timeframe = 1d; // How often to sample data
Usage // The table we’re analyzing
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Time range for the query, beginning at 12:00 AM of the first day and ending at 12:00 AM of the last day in the time range
| where IsBillable == "true" // Includes only billable data in the result set
| make-series ActualUsage=sum(Quantity) default = 0 on TimeGenerated from startofday(ago(starttime)) to startofday(ago(endtime)) step timeframe by DataType // Creates the time series, listed by data type
| extend(Anomalies, AnomalyScore, ExpectedUsage) = series_decompose_anomalies(ActualUsage,1.5,-1,'avg',1) // Scores and extracts anomalies based on the output of make-series, excluding the last value in the series - the Threshold, Seasonality, and Trend input values are the default values for the function
| mv-expand ActualUsage to typeof(double), TimeGenerated to typeof(datetime), Anomalies to typeof(double),AnomalyScore to typeof(double), ExpectedUsage to typeof(long) // Expands the array created by series_decompose_anomalies()
| where Anomalies != 0 // Returns all positive and negative deviations from expected usage
| project TimeGenerated,ActualUsage,ExpectedUsage,AnomalyScore,Anomalies,DataType // Defines which columns to return
| sort by abs(AnomalyScore) desc // Sorts results by anomaly score in descending ordering
Filtre os resultados para o tipo de dados AzureDiagnostics:

Todas as anomalias no gráfico da primeira consulta make-series agora aparecem no conjunto de resultados.
Analisar a causa raiz de anomalias
Comparar valores esperados com valores anormais ajuda você a entender a causa das diferenças entre os dois conjuntos.
O plug-in diffpatterns() da KQL compara dois conjuntos de dados da mesma estrutura e encontra padrões que caracterizam as diferenças entre eles.
Esta consulta compara o uso de AzureDiagnostics em 15 de junho, o valor atípico extremo no exemplo, com o uso da tabela em outros dias:
Clique para executar a consulta
let starttime = 21d; // Start date for the time series, counting back from the current date
let endtime = 0d; // End date for the time series, counting back from the current date
let anomalyDate = datetime_add('day',-1, make_datetime(startofday(ago(endtime)))); // Start of day of the anomaly date, which is the last full day in the time range in our example (you can replace this with a specific hard-coded anomaly date)
AzureDiagnostics
| extend AnomalyDate = iff(startofday(TimeGenerated) == anomalyDate, "AnomalyDate", "OtherDates") // Adds calculated column called AnomalyDate, which splits the result set into two data sets – AnomalyDate and OtherDates
| where TimeGenerated between (startofday(ago(starttime))..startofday(ago(endtime))) // Defines the time range for the query
| project AnomalyDate, Resource // Defines which columns to return
| evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate") // Compares usage on the anomaly date with the regular usage pattern
A consulta identifica que cada entrada na tabela ocorreu em AnomalyDate (15 de junho) ou OtherDates. O plug-in diffpatterns() divide esses conjuntos de dados, chamados A (OtherDates no exemplo) e B (AnomalyDate no exemplo), e retorna alguns padrões que contribuem para as diferenças nos dois conjuntos:

Observando os resultados da consulta, é possível ver as seguintes diferenças:
- Há 24.892.147 instâncias de ingestão do recurso CH1-GEARAMAAKS em todos os outros dias no intervalo de tempo da consulta e nenhuma ingestão de dados desse recurso em 15 de junho. Os dados do recurso CH1-GEARAMAAKS representam 73,36% da ingestão total em outros dias no intervalo de tempo da consulta e 0% da ingestão total em 15 de junho.
- Há 2.168.448 instâncias de ingestão do recurso NSG-TESTSQLMI519 em todos os outros dias no intervalo de tempo de consulta e 110.544 instâncias de ingestão desse recurso em 15 de junho. Os dados do recurso NSG-TESTSQLMI519 representam 6,39% da ingestão total em outros dias no intervalo de tempo da consulta e 25,61% da ingestão em 15 de junho.
Observe que, em média, há 108.422 instâncias de ingestão do recurso NSG-TESTSQLMI519 durante os 20 dias que compõem o período de outros dias (divida 2.168.448 por 20). Portanto, a ingestão do recurso NSG-TESTSQLMI519 em 15 de junho não é significativamente diferente daquela em outros dias. No entanto, como não há ingestão de CH1-GEARAMAAKS em 15 de junho, a ingestão de NSG-TESTSQLMI519 representa uma porcentagem significativamente maior da ingestão total na data da anomalia em comparação com outros dias.
A coluna PercentDiffAB mostra a diferença de ponto percentual absoluto entre A e B (|PercentA - PercentB|), que é a principal medida da diferença entre os dois conjuntos. Por padrão, o plug-in diffpatterns() retorna uma diferença de mais de 5% entre os dois conjuntos de dados, mas é possível ajustar esse limite. Por exemplo, para retornar somente diferenças de 20% ou mais entre os dois conjuntos de dados, é possível definir | evaluate diffpatterns(AnomalyDate, "OtherDates", "AnomalyDate", "~", 0.20) na consulta acima. A consulta agora retorna somente um resultado:

Observação
Para saber mais sobre a sintaxe e o uso de diffpatterns(), confira Plug-in de padrões de diferença.
Próximas etapas
Saiba mais sobre: