Configurar investigações de atividade
Os aplicativos conteinerizados podem ser executados por longos períodos de tempo, resultando em estados desfeitos que talvez precisem ser reparados por meio da reinicialização do contêiner. As Instâncias de Contêiner do Azure dão suporte a investigações de atividade, permitindo que você configure seus contêineres dentro do grupo de contêineres para reiniciar caso funcionalidades críticas não estejam funcionando. A investigação de atividade se comporta como uma investigação de atividade de Kubernetes.
Este artigo explica como implantar um grupo de contêineres que inclui uma investigação de atividade, demonstrando a reinicialização automática de um contêiner não íntegro simulado.
As Instâncias de Contêiner do Azure também dão suporte a investigações de preparação, que podem ser configuradas para garantir que o tráfego chegue até um contêiner somente quando ele estiver pronto.
Implantação do YAML
Crie um arquivo liveness-probe.yaml com o snippet a seguir. Esse arquivo define um grupo de contêineres composto por um contêiner NGINX que eventualmente se tornará não íntegro.
apiVersion: 2019-12-01
location: eastus
name: livenesstest
properties:
containers:
- name: mycontainer
properties:
image: mcr.microsoft.com/oss/nginx/nginx:1.15.5-alpine
command:
- "/bin/sh"
- "-c"
- "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
ports: []
resources:
requests:
cpu: 1.0
memoryInGB: 1.5
livenessProbe:
exec:
command:
- "cat"
- "/tmp/healthy"
periodSeconds: 5
osType: Linux
restartPolicy: Always
tags: null
type: Microsoft.ContainerInstance/containerGroups
Execute o seguinte comando para implantar esse grupo de contêineres com a configuração YAML anterior:
az container create --resource-group myResourceGroup --name livenesstest -f liveness-probe.yaml
Comando Iniciar
A implantação inclui uma propriedade command que define um comando de início que é executado quando o contêiner começa a ser executado pela primeira vez. Essa propriedade aceita uma matriz de cadeias de caracteres. Esse comando simula o contêiner entrando em um estado não íntegro.
Primeiro, ele inicia uma sessão de bash e cria um arquivo chamado healthy dentro do diretório /tmp. Em seguida, ele fica suspenso por 30 segundos antes de excluir o arquivo; depois entra em um modo de suspensão de 10 minutos:
/bin/sh -c "touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600"
Comando de atividade
Essa implantação define um livenessProbe, que dá suporte a um comando de atividade exec que atua como a verificação de atividade. Se a saída desse comando for um valor diferente de zero, o contêiner será encerrado e reiniciado, sinalizando que não foi possível encontrar o arquivo healthy. Se a o comando for encerrado com êxito com o código de saída 0, nenhuma ação será executada.
A propriedade periodSeconds indica que o comando deve ser executado a cada cinco segundos.
Verificar a saída da atividade
Nos 30 primeiros segundos, o arquivo healthy criado pelo comando inicial existe. Quando o comando de atividade verificar a existência do arquivo healthy, o código de status retornará um zero, indicando sucesso. Portanto, nenhuma reinicialização será executada.
Depois de 30 segundos, o comando cat /tmp/healthy começará a falhar, provocando a falta de integridade e eventos de encerramento.
Esses eventos podem ser exibidos do Portal do Azure ou na CLI do Azure.
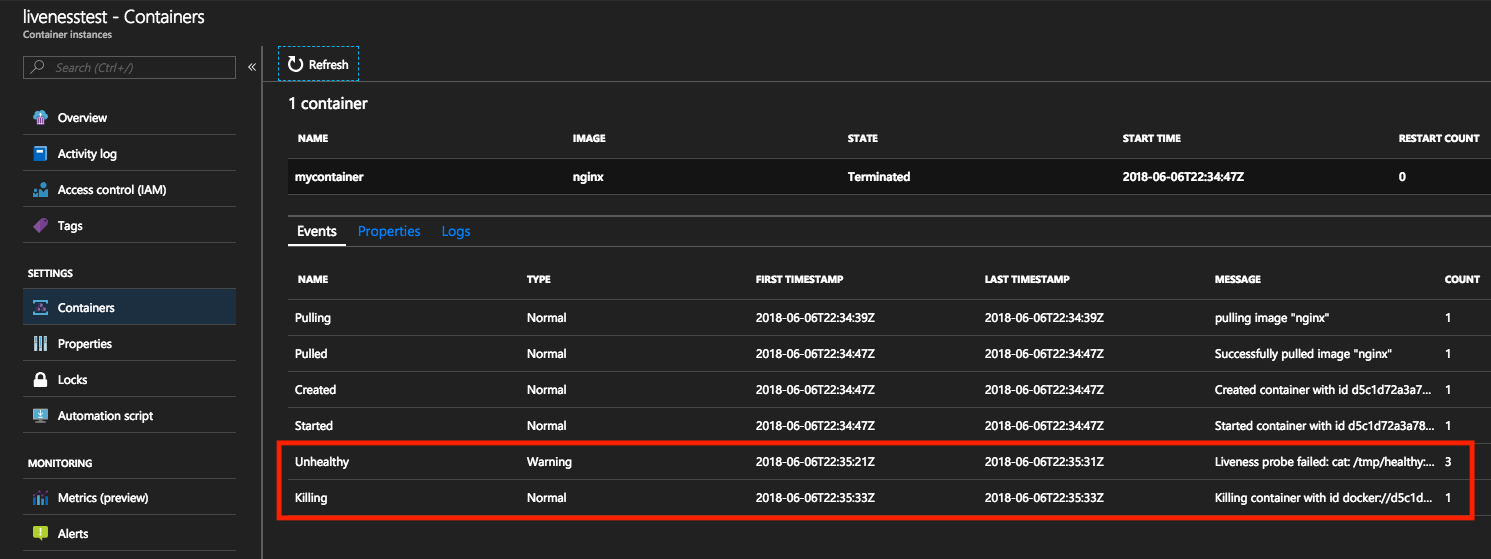
Ao exibir os eventos no portal do Azure, os eventos do tipo Unhealthy serão disparados após a falha do comando de atividade. O evento subsequente será do tipo Killing, indicando a exclusão do contêiner para que a reinicialização possa começar. A contagem de reinicialização para o contêiner aumentará sempre que esse evento ocorrer.
As reinicializações ocorrem in-loco, portanto, recursos como endereços IP públicos e conteúdo específico ao nó serão preservados.

Se investigação de atividade falhar continuamente e disparar muitas reinicializações, seu contêiner entrará em um atraso de recuo exponencial.
Políticas de investigação de atividade e reinicialização
As políticas de reinicialização substituem o comportamento de reinicialização acionado pelas investigações de atividade. Por exemplo, se você definir um restartPolicy = Never e uma investigação de atividade, o grupo de contêineres não reiniciará devido a uma falha de investigação de atividade. Em vez disso, o grupo de contêineres entrará em conformidade com a política de reinicialização do grupo de contêineres do Never.
Próximas etapas
Cenários com base em tarefas podem exigir que a investigação de atividade permita reinicializações automáticas se uma função pré-requisitada não estiver funcionando corretamente. Para obter mais informações sobre a execução de contêineres com base em tarefas, consulte Executar tarefas em contêineres nas Instâncias de Contêiner do Azure.