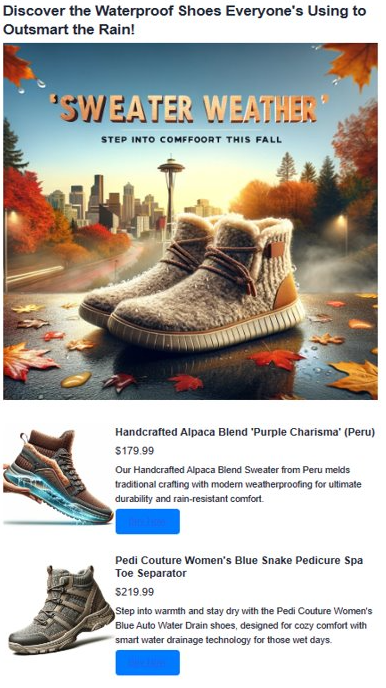
Geração de anúncios aprimorada por IA usando o Azure Cosmos DB for MongoDB vCore
Neste guia, mostramos como criar conteúdo publicitário dinâmico que se conecta com seu público, usando Heelie, que oferece assistência de IA personalizada. Com o Azure Cosmos DB for MongoDB vCore, usamos a funcionalidade de busca por similaridade vetorial para analisar semanticamente e combinar descrições de inventário com tópicos de anúncios. O processo é viabilizado pela geração de vetores para as descrições de inventário usando as incorporações da OpenAI, que aumentam significativamente a profundidade semântica. Esses vetores são armazenados e indexados no recurso Cosmos DB for MongoDB vCore. Quando geramos conteúdo para anúncios, vetorizamos o tópico de anúncio para encontrar os itens de inventário mais adequados. Em seguida, ocorre um processo de geração aumentada de recuperação (RAG), onde as principais correspondências são enviadas à OpenAI para elaborar um anúncio que chame atenção. A base de código completa do aplicativo está disponível em um repositório GitHub para consulta.
Recursos
- Busca por Similaridade Vetorial: usa a poderosa busca por similaridade vetorial do Azure Cosmos DB for MongoDB vCore para melhorar os recursos de pesquisa semântica, facilitando a localização de itens de inventário relevantes com base no conteúdo dos anúncios.
- Incorporações da OpenAI: usa as avançadas incorporações da OpenAI para gerar vetores para as descrições de inventário. Essa abordagem permite correspondências mais ricas e semanticamente detalhadas entre o inventário e o conteúdo do anúncio.
- Geração de conteúdo: emprega os modelos de linguagem avançada da OpenAI para gerar anúncios focados nas tendência e capazes de gerar engajamento. Esse método garante que o conteúdo seja relevante e cativante para o público-alvo.
Pré-requisitos
- OpenAI do Azure: vamos configurar o recurso do OpenAI do Azure. No mento, o acesso a este serviço só está disponível mediante solicitação. Você pode solicitar acesso ao Serviço OpenAI do Azure preenchendo o formulário em https://aka.ms/oai/access. Depois de ter acesso, siga estes passos:
- Crie um recurso do OpenAI do Azure seguindo este guia de início rápido.
- Implante um modelo
completionse umembeddings. - Anote os nomes dos pontos de extremidade, chaves e implantações.
- Recurso Cosmos DB for MongoDB vCore: vamos começar criando um recurso do Azure Cosmos DB for MongoDB vCore gratuitamente seguindo este guia de início rápido.
- Anote os detalhes da conexão.
- Ambiente Python (>= versão 3.9) com pacotes como
numpy,openai,pymongo,python-dotenv,azure-core,azure-cosmos,tenacityegradio. - Baixe o arquivo de dados e salve-o em uma pasta de dados designada.
Executar o script
Antes de partirmos para a etapa empolgante da geração de anúncios aprimorados por IA, precisamos configurar nosso ambiente. Isso inclui a instalação dos pacotes necessários para que nosso script funcione corretamente. Aqui está um guia passo a passo para preparar tudo.
1.1 Instalar os pacotes necessários
Primeiro, precisamos instalar alguns pacotes do Python. Abra seu terminal e execute o seguinte comando:
pip install numpy
pip install openai==1.2.3
pip install pymongo
pip install python-dotenv
pip install azure-core
pip install azure-cosmos
pip install tenacity
pip install gradio
pip show openai
1.2 Configurar os clientes OpenAI e Azure
Depois de instalar os pacotes necessários, a próxima etapa é configurar nossos clientes OpenAI e Azure para o script, o que é essencial para autenticar nossas solicitações à API OpenAI e aos serviços do Azure.
import json
import time
import openai
from dotenv import dotenv_values
from openai import AzureOpenAI
# Configure the API to use Azure as the provider
openai.api_type = "azure"
openai.api_key = "<AZURE_OPENAI_API_KEY>" # Replace with your actual Azure OpenAI API key
openai.api_base = "https://<OPENAI_ACCOUNT_NAME>.openai.azure.com/" # Replace with your OpenAI account name
openai.api_version = "2023-06-01-preview"
# Initialize the AzureOpenAI client with your API key, version, and endpoint
client = AzureOpenAI(
api_key=openai.api_key,
api_version=openai.api_version,
azure_endpoint=openai.api_base
)
Arquitetura da solução
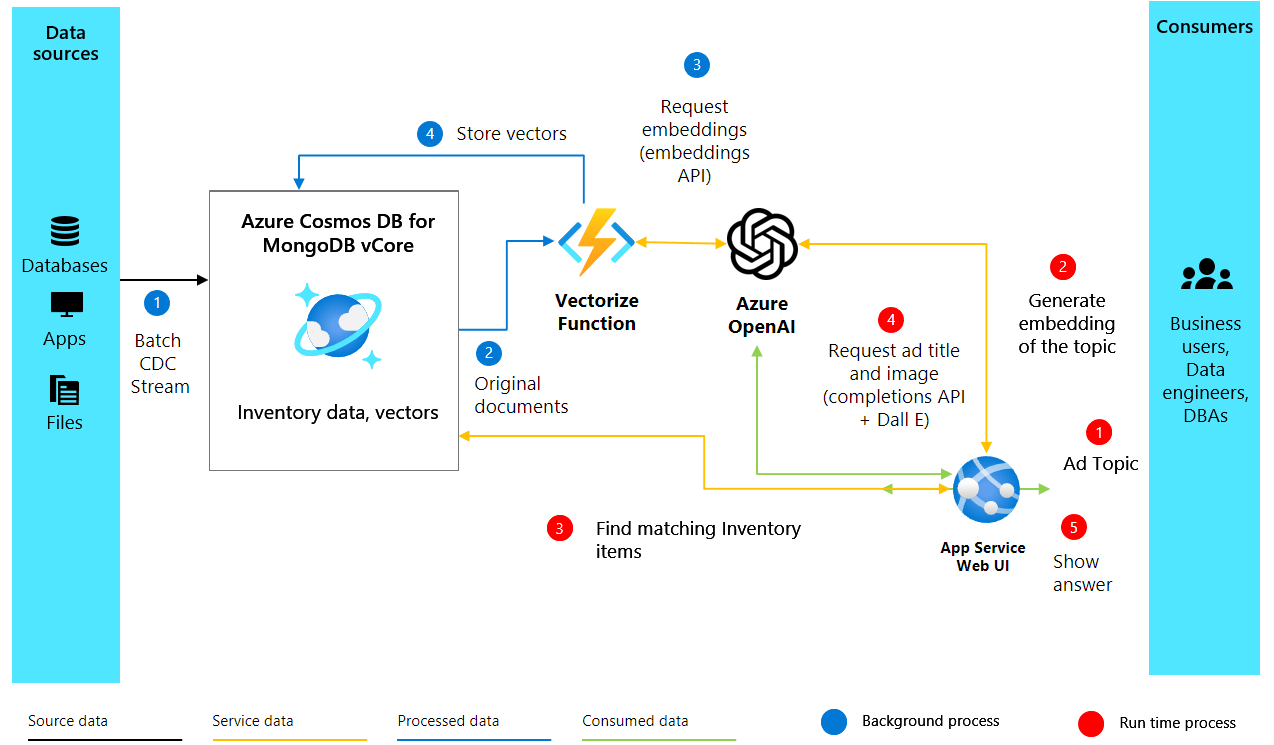
2. Criar incorporações e configurar o Cosmos DB
Depois de configurar nosso ambiente e o cliente OpenAI, passamos para a parte principal do nosso projeto de geração de anúncios aprimorados por IA. O código a seguir cria incorporações vetoriais a partir de descrições de texto de produtos e configura nosso banco de dados no Azure Cosmos DB for MongoDB vCore para armazenar e buscar essas incorporações.
2.1 Criar incorporações
Para produzir anúncios envolventes, primeiro precisamos entender os itens do nosso inventário. Fazemos isso criando incorporações vetoriais a partir das descrições dos itens, o que nos permite captar o significado semântico de uma forma que as máquinas possam entender e processar. Veja como você pode criar incorporações vetoriais para uma descrição de item usando o OpenAI do Azure:
import openai
def generate_embeddings(text):
try:
response = client.embeddings.create(
input=text, model="text-embedding-ada-002")
embeddings = response.data[0].embedding
return embeddings
except Exception as e:
print(f"An error occurred: {e}")
return None
embeddings = generate_embeddings("Shoes for San Francisco summer")
if embeddings is not None:
print(embeddings)
A função usa uma entrada de texto, como uma descrição de produto, e usa o método client.embeddings.create da API OpenAI para gerar uma incorporação vetorial para esse texto. Estamos usando o modelo text-embedding-ada-002 aqui, mas você pode escolher outros modelos com base nas suas necessidades. Se o processo for bem-sucedido, ele imprime as incorporações geradas; caso contrário, ele manipula as exceções imprimindo uma mensagem de erro.
3. Conectar e configurar o Cosmos DB for MongoDB vCore
Com nossas incorporações prontas, a próxima etapa é armazená-las e indexá-las em um banco de dados que dê suporte à busca por similaridade vetorial. O Azure Cosmos DB for MongoDB vCore é ideal para essa tarefa, pois foi desenvolvido especificamente para armazenar seus dados transacionais e realizar buscas em vetores em um só lugar.
3.1 Configurar a conexão
Para nos conectarmos ao Cosmos DB, usamos a biblioteca pymongo, que facilita a interação com o MongoDB. O snippet de código a seguir estabelece uma conexão com nossa instância do Cosmos DB for MongoDB vCore:
import pymongo
# Replace <USERNAME>, <PASSWORD>, and <VCORE_CLUSTER_NAME> with your actual credentials and cluster name
mongo_conn = "mongodb+srv://<USERNAME>:<PASSWORD>@<VCORE_CLUSTER_NAME>.mongocluster.cosmos.azure.com/?tls=true&authMechanism=SCRAM-SHA-256&retrywrites=false&maxIdleTimeMS=120000"
mongo_client = pymongo.MongoClient(mongo_conn)
Substitua <USERNAME>, <PASSWORD> e <VCORE_CLUSTER_NAME> pelo seu nome de usuário, senha e nome do cluster vCore do MongoDB, respectivamente.
4. Configurando o banco de dados e o índice vetorial no Cosmos DB
Depois de estabelecer uma conexão com o Azure Cosmos DB, as próximas etapas envolvem configurar o banco de dados e a coleção e, em seguida, criar um índice vetorial para permitir buscas eficientes de similaridade vetorial. Vamos seguir estas etapas.
4.1 Configurar o banco de dados e a coleção
Primeiro, criamos um banco de dados e uma coleção dentro da nossa instância do Cosmos DB. Veja como fazer isso:
DATABASE_NAME = "AdgenDatabase"
COLLECTION_NAME = "AdgenCollection"
mongo_client.drop_database(DATABASE_NAME)
db = mongo_client[DATABASE_NAME]
collection = db[COLLECTION_NAME]
if COLLECTION_NAME not in db.list_collection_names():
# Creates a unsharded collection that uses the DBs shared throughput
db.create_collection(COLLECTION_NAME)
print("Created collection '{}'.\n".format(COLLECTION_NAME))
else:
print("Using collection: '{}'.\n".format(COLLECTION_NAME))
4.2 Criar o índice vetorial
Para realizar buscas por similaridade vetorial eficientes em nossa coleção, precisamos criar um índice vetorial. O Cosmos DB oferece suporte a diferentes tipos de índices vetoriais e aqui discutiremos dois deles: IVF e HNSW.
IVF
IVF, que significa Inverted File Index (Índice de Arquivo Invertido), é o algoritmo de indexação vetorial padrão e funciona em todas as camadas de cluster. É uma abordagem aproximada de vizinhos mais próximos (ANN) que usa o clustering para acelerar a busca por vetores semelhantes em um conjunto de dados. Para criar um índice de IVF, use o seguinte comando:
db.command({
'createIndexes': COLLECTION_NAME,
'indexes': [
{
'name': 'vectorSearchIndex',
'key': {
"contentVector": "cosmosSearch"
},
'cosmosSearchOptions': {
'kind': 'vector-ivf',
'numLists': 1,
'similarity': 'COS',
'dimensions': 1536
}
}
]
});
Importante
Você só pode criar um índice por propriedade vetorial. Ou seja, você não pode criar mais de um índice que aponte para a mesma propriedade vetorial. Se você quiser mudar o tipo de índice (por exemplo, de IVF para HNSW), deverá excluir o índice existente antes de criar um novo.
HNSW
HNSW significa Mundo Pequeno Navegável Hierárquico, uma estrutura de dados baseada em grafo que particiona vetores em clusters e subclusters. Com o HNSW, você pode executar uma pesquisa de vizinho mais próximo rápida em velocidades mais altas com maior precisão. HNSW é um método aproximado (ANN). Veja como configurá-lo:
db.command(
{
"createIndexes": "ExampleCollection",
"indexes": [
{
"name": "VectorSearchIndex",
"key": {
"contentVector": "cosmosSearch"
},
"cosmosSearchOptions": {
"kind": "vector-hnsw",
"m": 16, # default value
"efConstruction": 64, # default value
"similarity": "COS",
"dimensions": 1536
}
}
]
}
)
Observação
A indexação HNSW só está disponível em camadas de cluster M40 e superiores.
5. Inserir dados na coleção
Agora, insira os dados de inventário à coleção recém criada, incluindo descrições e suas incorporações vetoriais correspondentes. Para inserir dados na nossa coleção, usamos o método insert_many() fornecido pela biblioteca pymongo. O método nos permite inserir diversos documentos na coleção de uma só vez. Nossos dados estão armazenados em um arquivo JSON, que carregaremos e inseriremos no banco de dados.
Baixe o arquivo shoes_with_vectors.json do repositório GitHub e armazene-o em um diretório data dentro da pasta do projeto.
data_file = open(file="./data/shoes_with_vectors.json", mode="r")
data = json.load(data_file)
data_file.close()
result = collection.insert_many(data)
print(f"Number of data points added: {len(result.inserted_ids)}")
6. Busca em vetores no Cosmos DB for MongoDB vCore
Com nossos dados carregados com sucesso, agora podemos aplicar o poder da busca em vetores para localizar os itens mais relevantes com base em uma consulta. O índice vetorial que criamos anteriormente nos permite realizar pesquisas semânticas em nosso conjunto de dados.
6.1 Realizar uma busca em vetores
Para realizar um busca em vetores, definimos uma função vector_search que usa uma consulta e o número de resultados desejados. A função gera um vetor para a consulta usando a função generate_embeddings que definimos antes e, em seguida, usa a funcionalidade $search do Cosmos DB para encontrar os itens que mais se aproximam com base nas incorporações vetoriais.
# Function to assist with vector search
def vector_search(query, num_results=3):
query_vector = generate_embeddings(query)
embeddings_list = []
pipeline = [
{
'$search': {
"cosmosSearch": {
"vector": query_vector,
"numLists": 1,
"path": "contentVector",
"k": num_results
},
"returnStoredSource": True }},
{'$project': { 'similarityScore': { '$meta': 'searchScore' }, 'document' : '$$ROOT' } }
]
results = collection.aggregate(pipeline)
return results
6.2 Executar consulta de busca em vetores
Por fim, executamos nossa função de busca em vetores com uma consulta específica e processamos os resultados para exibi-los:
query = "Shoes for Seattle sweater weather"
results = vector_search(query, 3)
print("\nResults:\n")
for result in results:
print(f"Similarity Score: {result['similarityScore']}")
print(f"Title: {result['document']['name']}")
print(f"Price: {result['document']['price']}")
print(f"Material: {result['document']['material']}")
print(f"Image: {result['document']['img_url']}")
print(f"Purchase: {result['document']['purchase_url']}\n")
7. Gerar conteúdo de anúncio com GPT-4 e DALL. E
Combinamos todos os componentes desenvolvidos para criar anúncios envolventes, empregando o GPT-4 da OpenAI para texto e o DALL·E 3 para imagens. Junto com os resultados da busca em vetores, eles compõem um anúncio completo. Também apresentamos Heelie, responsável por fornecer assistência inteligente e criar de slogans que promovem o engajamento nos anúncios. Por meio do código a seguir, você verá Heelie em ação, aprimorando nosso processo de criação de anúncios.
from openai import OpenAI
def generate_ad_title(ad_topic):
system_prompt = '''
You are Heelie, an intelligent assistant for generating witty and cativating tagline for online advertisement.
- The ad campaign taglines that you generate are short and typically under 100 characters.
'''
user_prompt = f'''Generate a catchy, witty, and short sentence (less than 100 characters)
for an advertisement for selling shoes for {ad_topic}'''
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_prompt},
]
response = client.chat.completions.create(
model="gpt-4",
messages=messages
)
return response.choices[0].message.content
def generate_ad_image(ad_topic):
daliClient = OpenAI(
api_key="<DALI_API_KEY>"
)
image_prompt = f'''
Generate a photorealistic image of an ad campaign for selling {ad_topic}.
The image should be clean, with the item being sold in the foreground with an easily identifiable landmark of the city in the background.
The image should also try to depict the weather of the location for the time of the year mentioned.
The image should not have any generated text overlay.
'''
response = daliClient.images.generate(
model="dall-e-3",
prompt= image_prompt,
size="1024x1024",
quality="standard",
n=1,
)
return response.data[0].url
def render_html_page(ad_topic):
# Find the matching shoes from the inventory
results = vector_search(ad_topic, 4)
ad_header = generate_ad_title(ad_topic)
ad_image_url = generate_ad_image(ad_topic)
with open('./data/ad-start.html', 'r', encoding='utf-8') as html_file:
html_content = html_file.read()
html_content += f'''<header>
<h1>{ad_header}</h1>
</header>'''
html_content += f'''
<section class="ad">
<img src="{ad_image_url}" alt="Base Ad Image" class="ad-image">
</section>'''
for result in results:
html_content += f'''
<section class="product">
<img src="{result['document']['img_url']}" alt="{result['document']['name']}" class="product-image">
<div class="product-details">
<h3 class="product-title" color="gray">{result['document']['name']}</h2>
<p class="product-price">{"$"+str(result['document']['price'])}</p>
<p class="product-description">{result['document']['description']}</p>
<a href="{result['document']['purchase_url']}" class="buy-now-button">Buy Now</a>
</div>
</section>
'''
html_content += '''</article>
</body>
</html>'''
return html_content
8. Juntando as peças
Para deixar nossa geração de anúncios mais interativa, utilizamos o Gradio, uma biblioteca Python que possibilita a criação de interfaces de usuário simplificadas para a web. Definimos uma interface do usuário que permite aos usuários inserir tópicos de anúncios e, em seguida, gera e mostra dinamicamente o anúncio resultante.
import gradio as gr
css = """
button { background-color: purple; color: red; }
<style>
</style>
"""
with gr.Blocks(css=css, theme=gr.themes.Default(spacing_size=gr.themes.sizes.spacing_sm, radius_size="none")) as demo:
subject = gr.Textbox(placeholder="Ad Keywords", label="Prompt for Heelie!!")
btn = gr.Button("Generate Ad")
output_html = gr.HTML(label="Generated Ad HTML")
btn.click(render_html_page, [subject], output_html)
btn = gr.Button("Copy HTML")
if __name__ == "__main__":
demo.launch()
Saída