Como ingerir dados históricos no Azure Data Explorer
Um cenário comum ao integrar ao Azure Data Explorer é ingerir dados históricos, às vezes chamados de aterramento. O processo envolve a ingestão de dados de um sistema de armazenamento existente em uma tabela, que é uma coleção de extensões.
Recomendamos ingerir dados históricos usando a propriedade de assimilação creationTime para definir a hora de criação das extensões para a hora em que os dados foram criados. Usar o tempo de criação como critério de particionamento de ingestão pode envelhecer seus dados de acordo com suas políticas de cache e retenção e tornar os filtros de tempo mais eficientes.
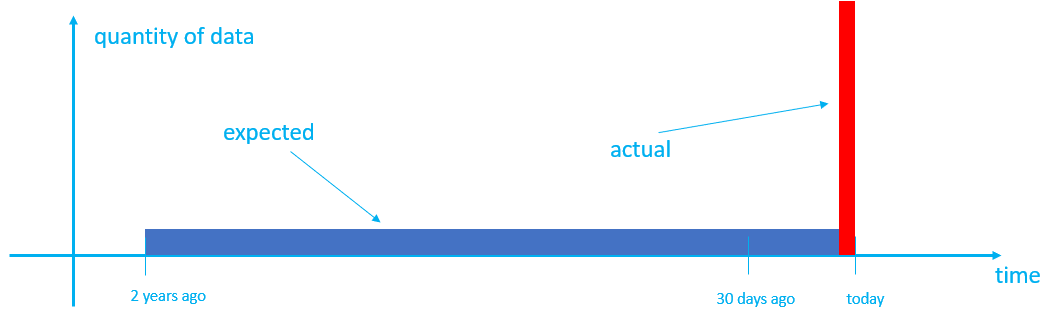
Por padrão, o tempo de criação das extensões é definido como o momento em que os dados são ingeridos, o que pode não produzir o comportamento esperado. Por exemplo, suponha que você tenha uma tabela com um período de cache de 30 dias e um período de retenção de dois anos. No fluxo normal, os dados ingeridos à medida que são produzidos são armazenados em cache por 30 dias e, em seguida, movidos para o armazenamento frio. Após dois anos, com base no tempo de criação, os dados mais antigos são removidos um dia de cada vez. No entanto, se você assimilar dois anos de dados históricos em que, por padrão, os dados são marcados com a hora de criação como a hora em que os dados são assimilados. Isso pode não produzir o resultado desejado porque:
- Todos os dados chegam ao cache e permanecem lá por 30 dias, usando mais cache do que o previsto.
- Os dados mais antigos não são removidos um dia de cada vez; portanto, os dados são retidos no cluster por mais tempo do que o necessário e, após dois anos, são todos removidos de uma só vez.
- Os dados, anteriormente agrupados por data no sistema de origem, agora podem ser agrupados em lotes na mesma medida, levando a consultas ineficientes.
Neste artigo, você aprenderá a particionar dados históricos:
Usando a propriedade de ingestão durante a
creationTimeingestão (recomendado)Sempre que possível, ingira dados históricos usando a
creationTimepropriedade ingestion, que permite definir a hora de criação das extensões extraindo-as do arquivo ou do caminho do blob. Se a estrutura de pastas não usar um padrão de data de criação, recomendamos que você reestruture o arquivo ou o caminho do blob para refletir a hora da criação. Usando esse método, os dados são ingeridos na tabela com a hora de criação correta e os períodos de cache e retenção são aplicados corretamente.Observação
Por padrão, as extensões são particionadas por hora de criação (ingestão) e, na maioria dos casos, não há necessidade de definir uma política de particionamento de dados.
Usando uma política de particionamento após a ingestão
Se você não puder usar a
creationTimepropriedade de ingestão, por exemplo, se estiver ingerindo dados usando o conector do Azure Cosmos DB em que não é possível controlar o tempo de criação ou se não puder reestruturar sua estrutura de pastas, poderá reparticionar a ingestão de postagem da tabela para obter o mesmo efeito usando a política de particionamento. No entanto, esse método pode exigir algumas tentativas e erros para otimizar as propriedades da política e é menos eficiente do que usar acreationTimepropriedade de ingestão. Recomendamos esse método apenas quando o uso dacreationTimepropriedade de ingestão não é possível.
Pré-requisitos
- Uma conta Microsoft ou uma identidade de usuário do Microsoft Entra. Uma assinatura do Azure não é necessária.
- Um cluster e um banco de dados do Azure Data Explorer. Criar um cluster e um banco de dados.
- Uma conta de armazenamento.
- Para obter o método recomendado de usar a propriedade de assimilação durante a
creationTimeassimilação, instale o LightIngest.
Ingerir dados históricos
É altamente recomendável particionar dados históricos usando a propriedade de ingestão durante a creationTime ingestão. No entanto, se você não puder usar esse método, poderá reparticionar a ingestão de postagem da tabela usando uma política de particionamento.
O LightIngest pode ser útil para carregar dados históricos de um sistema de armazenamento existente para o Azure Data Explorer. Embora você possa criar seu próprio comando usando a lista de argumentos de linha de comando, este artigo mostra como gerar automaticamente esse comando por meio de um assistente de ingestão. Além de criar o comando, você pode usar esse processo para criar uma nova tabela e o mapeamento de esquema. Essa ferramenta infere o mapeamento de esquema do seu conjunto de dados.
Destino
Na interface do usuário da Web do Azure Data Explorer, no menu à esquerda, selecione Consulta.
Clique com o botão direito do mouse no banco de dados no qual você deseja ingerir os dados e selecione LightIngest.
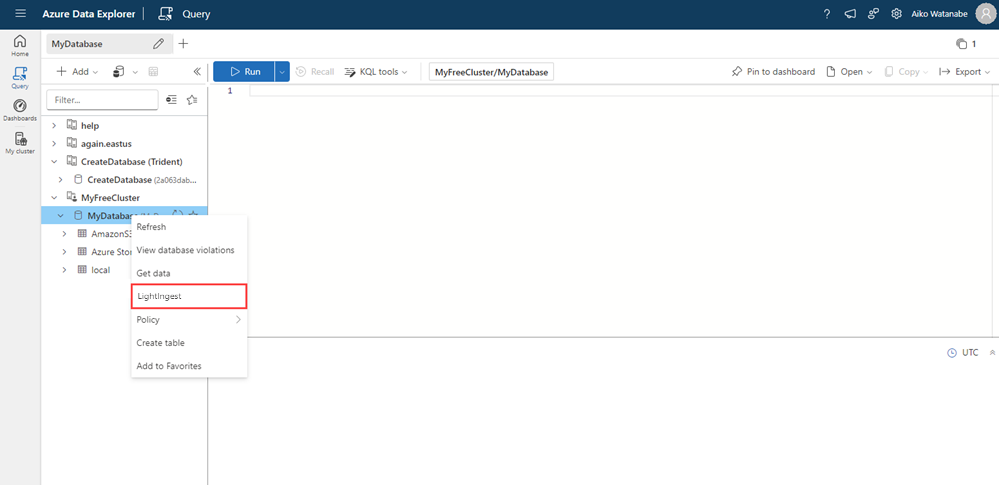
A janela Ingestão de dados é aberta com a guia Destino selecionada. Os campos Cluster e Banco de dados são populados automaticamente.
Selecione uma tabela de destino. Se você quiser ingerir dados em uma nova tabela, selecione Nova tabela e insira um nome de tabela.
Observação
Os nomes de tabelas podem ter até 1024 caracteres, incluindo espaços, caracteres alfanuméricos, hifens e sublinhados. Não há suporte para caracteres especiais.
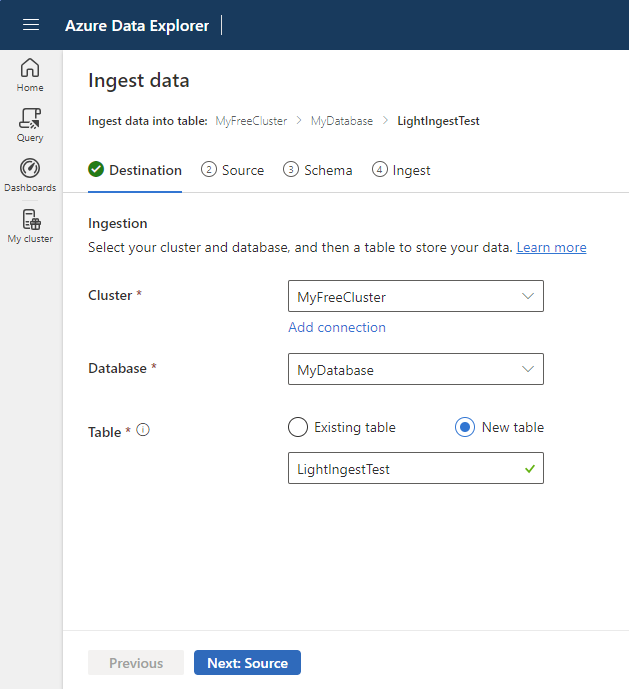
Selecione Avançar: origem.

Fonte
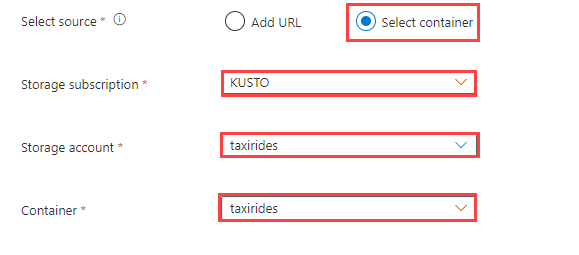
Em Selecionar origem, selecione Adicionar URL ou Selecionar contêiner.
Ao adicionar uma URL, em Link para a origem, especifique a chave da conta ou a URL SAS para um contêiner. Você pode criar a URL SAS manualmente ou automaticamente.
Ao selecionar um contêiner em sua conta de armazenamento, selecione sua assinatura de armazenamento, conta de armazenamento e contêiner nos menus suspensos.
Observação
A ingestão dá suporte para um tamanho do arquivo máximo de 6 GB. A recomendação é ingerir arquivos entre 100 MB e 1 GB.
Selecione Configurações avançadas para definir configurações adicionais para o processo de assimilação usando o LightIngest.
No painel Configuração avançada, defina as configurações do LightIngest de acordo com a tabela a seguir.
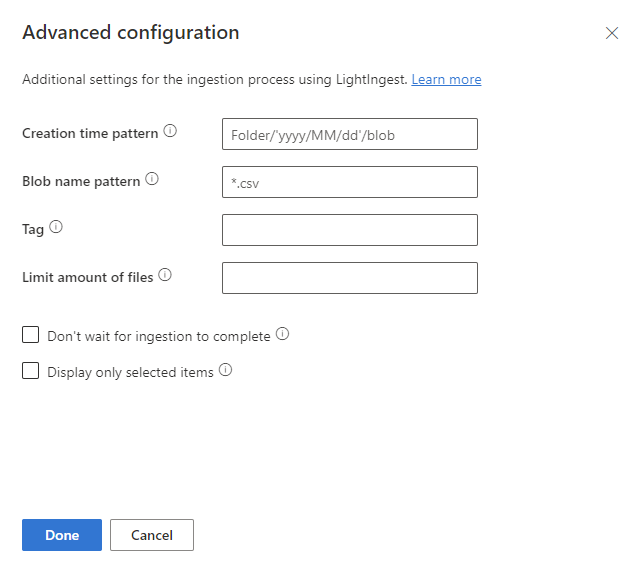
Propriedade Descrição Padrão de tempo de criação Especifique para substituir a propriedade de tempo de ingestão da extensão criada por um padrão, por exemplo, para aplicar uma data com base na estrutura de pastas do contêiner. Confira também Padrão de tempo de criação. Padrão de nome do blob Especifique o padrão usado para identificar os arquivos a serem ingeridos. Faça a ingestão de todos os arquivos que correspondam ao padrão de nome de blob no contêiner determinado. Dá suporte a curingas. Recomendamos colocar aspas duplas. Marca Uma marca atribuída aos dados ingeridos. A marca pode ser qualquer cadeia de caracteres. Limitar a quantidade de arquivos Especifique o número de arquivos que podem ser ingeridos. Ingere os primeiros narquivos que correspondem ao padrão de nome de blob, até o número especificado.Não espere a conclusão da ingestão Se definido, colocará os blobs em fila para ingestão sem monitorar o processo de ingestão. Se não estiver definido, o LightIngest continuará sondando o status de ingestão até que a ingestão seja concluída. Exibir apenas os itens selecionados Liste os arquivos no contêiner, mas não os ingira. Selecione Concluído para retornar à guia Origem .
Opcionalmente, selecione Filtros de arquivo para filtrar os dados para ingerir apenas arquivos em um caminho de pasta específico ou com uma extensão de arquivo específica.
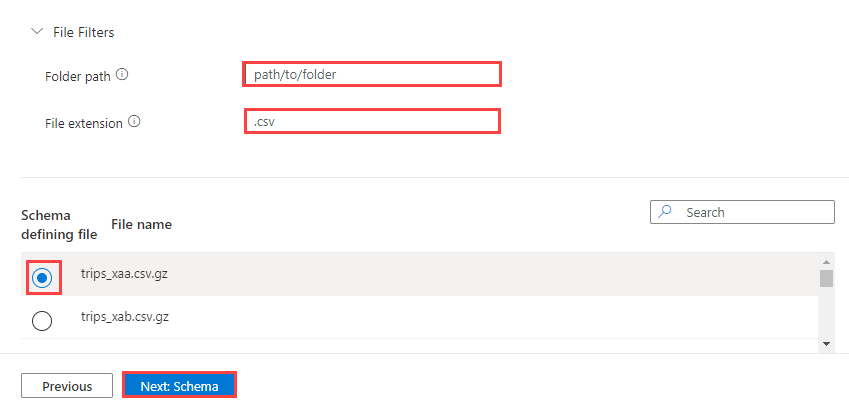
Por padrão, um dos arquivos no contêiner é selecionado aleatoriamente e usado para gerar o esquema para a tabela.
Opcionalmente, em Arquivo de definição de esquema, você pode especificar o arquivo a ser usado.
Selecione Avançar: esquema para ver e editar a configuração da coluna da tabela.
Esquema
A guia de esquema fornece uma visualização dos dados.
Para gerar o comando LightIngest, selecione Avançar: Iniciar Ingestão.
Se desejar:
- Altere o formato de dados inferido automaticamente selecionando o formato desejado no menu suspenso.
- Altere o nome do mapeamento inferido automaticamente. Você pode usar caracteres alfanuméricos e sublinhados. Não há suporte para espaços, caracteres especiais nem hifens.
- Ao usar uma tabela existente, você pode Manter o esquema da tabela atual, se o esquema da tabela corresponder ao formato selecionado.
- Selecione Visualizador de comando para ver e copiar os comandos automáticos gerados com base nas entradas.
- Editar colunas. Em Visualização parcial de dados, selecione os menus suspensos de coluna para alterar vários aspectos da tabela.
As alterações que você pode fazer em uma tabela dependem dos seguintes parâmetros:
- O tipo de tabela é novo ou existente
- O tipo de mapeamento é novo ou existente
| Tipo de tabela | Tipo de mapeamento | Ajustes disponíveis |
|---|---|---|
| Nova tabela | Novo mapeamento | Alterar tipo de dados, Renomear coluna, Nova coluna, Excluir coluna, Atualizar coluna, Classificar em ordem crescente, Classificar em ordem decrescente |
| Tabela existente | Novo mapeamento | Nova coluna (na qual você pode alterar o tipo de dados, renomear e atualizar), Atualizar coluna, Classificar em ordem crescente, Classificar em ordem decrescente |
| Mapeamento existente | Classificar em ordem crescente, Classificar em ordem decrescente |
Observação
Ao adicionar uma nova coluna ou atualizar uma coluna, você pode alterar as transformações de mapeamento. Para obter mais informações, confira Transformações de mapeamento
Ingeste
Depois que a tabela, o mapeamento e o comando LightIngest estiverem marcados com marcas de seleção verdes, selecione o ícone de cópia no canto superior direito da caixa de comando Gerado para copiar o comando LightIngest gerado.

Observação
Se necessário, você pode baixar a ferramenta LightIngest selecionando Baixar LightIngest.
Para concluir o processo de assimilação, você deve executar LightIngest usando o comando copiado.
