Otimização de coletores
Quando os fluxos de dados são gravados em coletores, todo particionamento personalizado ocorrerá imediatamente antes da gravação. Como para a origem, na maioria dos casos, é recomendável que você continue a Usar o particionamento atual como a opção de partição selecionada. Os dados particionados gravam muito mais rápido do que os não particionados, mesmo que seu destino não seja particionado. Confira abaixo as considerações individuais para vários tipos de coletor.
Coletores do Banco de Dados SQL do Azure
Com o Banco de Dados SQL do Azure, o particionamento padrão deve funcionar na maioria dos casos. Há uma chance de que seu coletor tenha partições demais para o seu Banco de dados SQL tratar. Se isso estiver acontecendo, reduza o número de partições emitidas pelo coletor do Banco de Dados SQL.
Melhor prática para excluir linhas no coletor com base em linhas ausentes na origem
Confira este vídeo de como usar fluxos de dados com saídas, alterações de linhas e transformações de coletor para alcançar este padrão comum:
Impacto do tratamento de linhas de erro no desempenho
Ao habilitar o tratamento de linhas de erro ("continuar se houver erro") na transformação do coletor, o serviço executará uma etapa adicional antes de gravar as linhas compatíveis na tabela de destino. Essa etapa adicional sofre uma pequena penalidade de desempenho, que pode estar em uma faixa de 5% adicionada para esta etapa com uma pequena ocorrência de desempenho adicional também adicionada, se você definir a opção para gravar também as linhas incompatíveis em um arquivo de log.
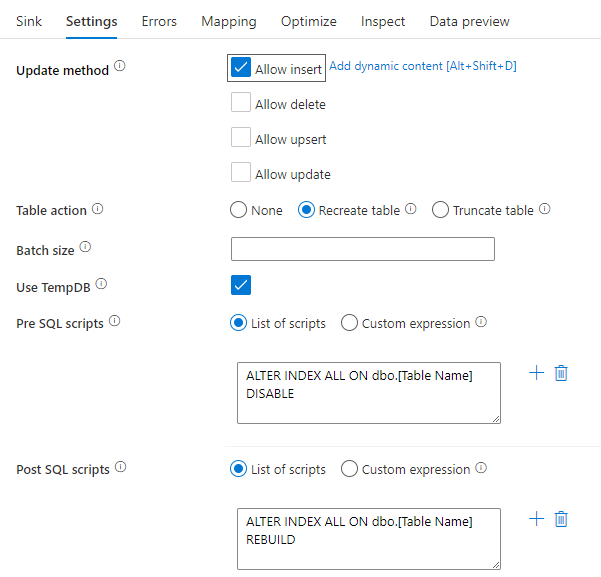
Desabilitar índices usando um script SQL
Desabilitar índices antes de um carregamento no Banco de Dados SQL pode melhorar muito o desempenho da gravação na tabela. Execute o comando abaixo antes de gravar no coletor SQL.
ALTER INDEX ALL ON dbo.[Table Name] DISABLE
Após a conclusão da gravação, recompile os índices usando o seguinte comando:
ALTER INDEX ALL ON dbo.[Table Name] REBUILD
Ambos podem ser realizados nativamente usando scripts anteriores e posteriores do SQL dentro de um Banco de Dados SQL do Azure ou coletor do Synapse em fluxos de dados de mapeamento.
Aviso
Ao desabilitar índices, o fluxo de dados assume efetivamente o controle de um banco de dados, sendo improvável que as consultas sejam bem-sucedidas no momento. Como resultado, muitos trabalhos de ETL são disparados no meio da noite para evitar esse conflito. Para obter mais informações, consulte as restrições de desabilitar os índices SQL
Escalar verticalmente seu banco de dados
Agende um redimensionamento do Banco de Dados SQL do Azure e do DW da origem e do coletor antes de executar o pipeline para aumentar a taxa de transferência e minimizar a limitação do Azure depois de atingir os limites de DTU. Depois que a execução do pipeline for concluída, redimensione os bancos de dados de volta à sua taxa de execução normal.
Coletores do Azure Synapse Analytics
Ao gravar no Azure Synapse Analytics, verifique se Habilitar preparo está definido como true. Isso permite que o serviço faça a gravação usando o Comando COPY do SQL, que carrega os dados em massa com eficiência. Você precisará referenciar um Azure Data Lake Storage gen2 ou uma conta de Armazenamento de Blobs do Azure para preparar os dados ao usar Preparo.
Além de Preparo, as mesmas práticas recomendadas se aplicam ao Azure Synapse Analytics como Banco de Dados SQL do Azure.
Coletores baseados em arquivo
Embora os fluxos de dados ofereçam suporte a uma variedade de tipos de arquivo, o formato Parquet nativo do Spark é recomendado para obter tempos ideais de leitura e gravação.
Se os dados forem distribuídos uniformemente, Usar o particionamento atual será a opção de particionamento mais rápida para gravar arquivos.
Opções de nome de arquivo
Ao gravar arquivos, você pode escolher nomear as opções de impacto no desempenho de cada um.
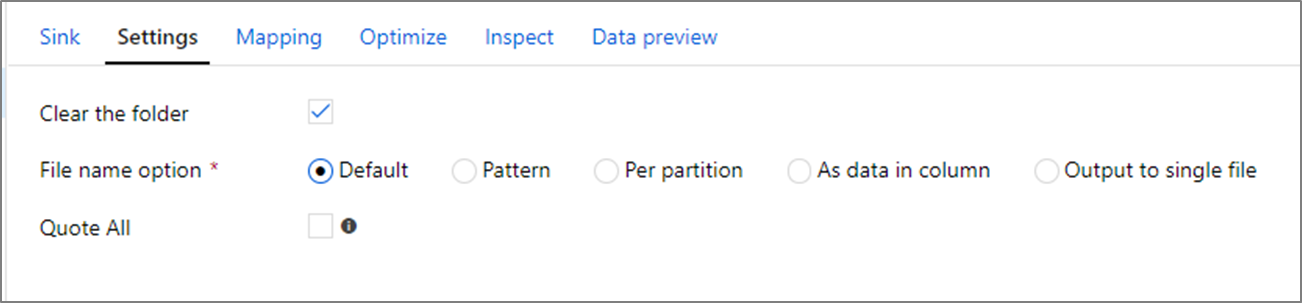
Selecionar a opção Padrão grava mais rápido. Cada partição será igual a um arquivo com o nome padrão do Spark. Isso será útil se você estiver fazendo apenas a leitura da pasta de dados.
Definir um Padrão de nomenclatura renomeará cada arquivo de partição com um nome mais amigável. Essa operação ocorre após a gravação, sendo um pouco mais lenta do que a escolha padrão.
A escolha Por partição permite nomear cada partição manualmente.
Se uma coluna corresponder ao modo como você deseja gerar os dados, será possível selecionar Nomear arquivo como dados de coluna. Isso reorganiza os dados e pode afetar o desempenho, caso as colunas não sejam distribuídas uniformemente.
Se uma coluna corresponder ao modo como você deseja gerar os nomes da pasta, será possível selecionar Nomear pasta como dados de coluna.
A saída para um único arquivo combina todos os dados em uma única partição. Isso leva a um tempo longo de gravação, especialmente para grandes conjuntos de dados. Essa opção é extremamente não recomendado, a menos que haja um motivo comercial explícito para usá-la.
Coletores do Azure Cosmos DB
Ao gravar no Azure Cosmos DB, alterar a taxa de transferência e o tamanho do lote durante a execução do fluxo de dados pode melhorar o desempenho. Essas alterações só entram em vigor durante a execução da atividade de fluxo de dados, e retornam às configurações da coleção original após a conclusão.
Tamanho do lote: normalmente, a partir do tamanho do lote padrão é suficiente. Para ajustar esse valor, calcule o tamanho de objeto aproximado dos dados e verifique se o * tamanho do lote do objeto é menor que 2 MB. Se for, você pode aumentar o tamanho do lote para ter melhor taxa de transferência.
Taxa de transferência: defina uma configuração de taxa de transferência mais alta para permitir que os documentos sejam gravados mais rapidamente no Azure Cosmos DB. Tenha em mente os custos de RU mais elevados com base em uma configuração de taxa de transferência alta.
Orçamento de taxa de transferência de gravação: use um valor menor do que o total de RUs por minuto. Se você tiver um fluxo de dados com um número alto de partições do Spark, definir um orçamento da taxa de transferência permitirá um equilíbrio maior entre essas partições.
Conteúdo relacionado
- Visão geral do desempenho do fluxo de dados
- Otimização de fontes
- Otimização de transformações
- Uso de fluxos de dados nos pipelines
Consulte outros artigos sobre Fluxo de Dados relacionados ao desempenho: