Transformação de coluna derivada no fluxo de dados de mapeamento
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Os fluxos de dados estão disponíveis nos pipelines do Azure Data Factory e do Azure Synapse. Este artigo se aplica ao fluxo de dados de mapeamento. Se você for iniciante nas transformações, veja o artigo introdutório Transformar dados usando um fluxo de dados de mapeamento.
Use a transformação de coluna derivada para gerar novas colunas no fluxo de dados ou modificar os campos existentes.
Criar e atualizar colunas
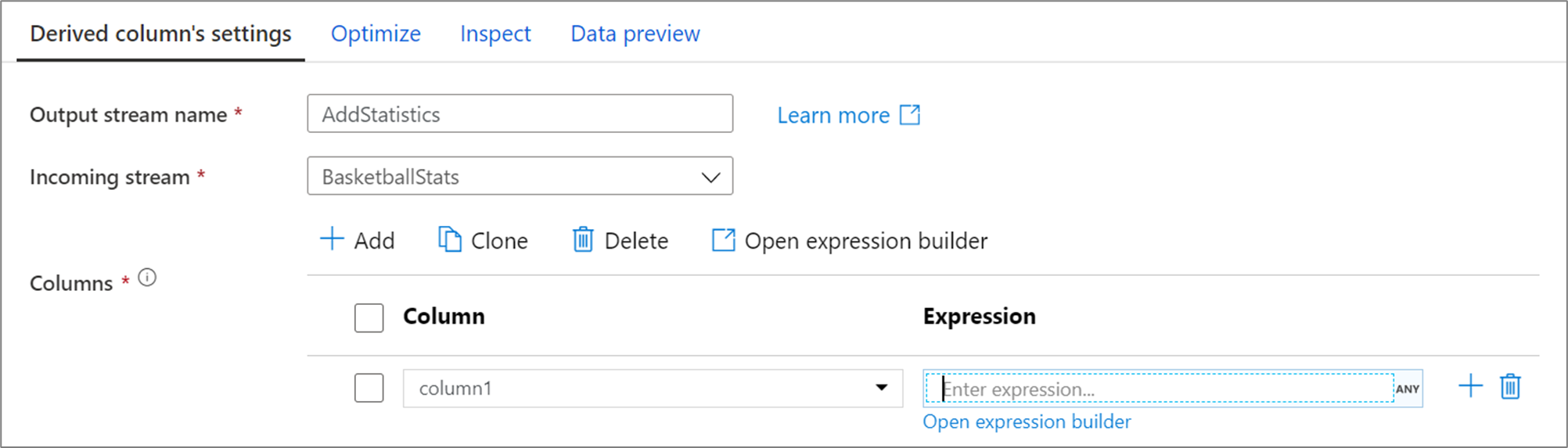
Ao criar uma coluna derivada, você pode gerar uma nova coluna ou atualizar uma existente. Na caixa de texto Coluna, insira a coluna que você está criando. Para substituir uma coluna existente em seu esquema, você pode usar a lista suspensa coluna. Para criar a expressão da coluna derivada, clique na caixa de texto Inserir expressão. Você pode começar a digitar sua expressão ou abrir o construtor de expressões para construir sua lógica.
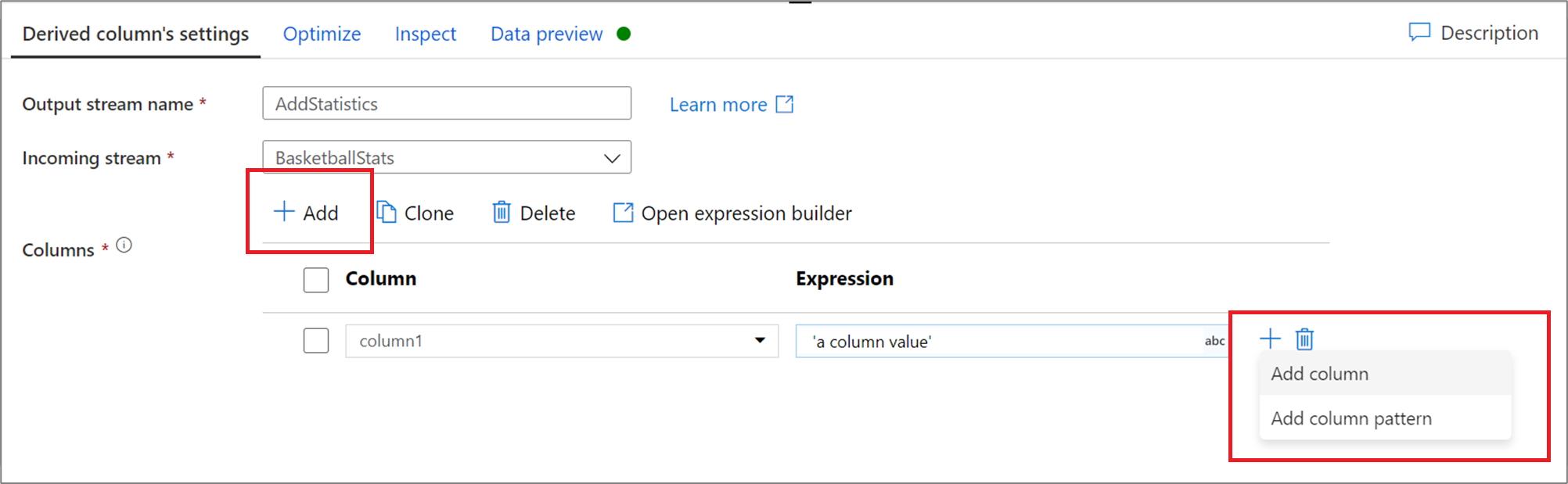
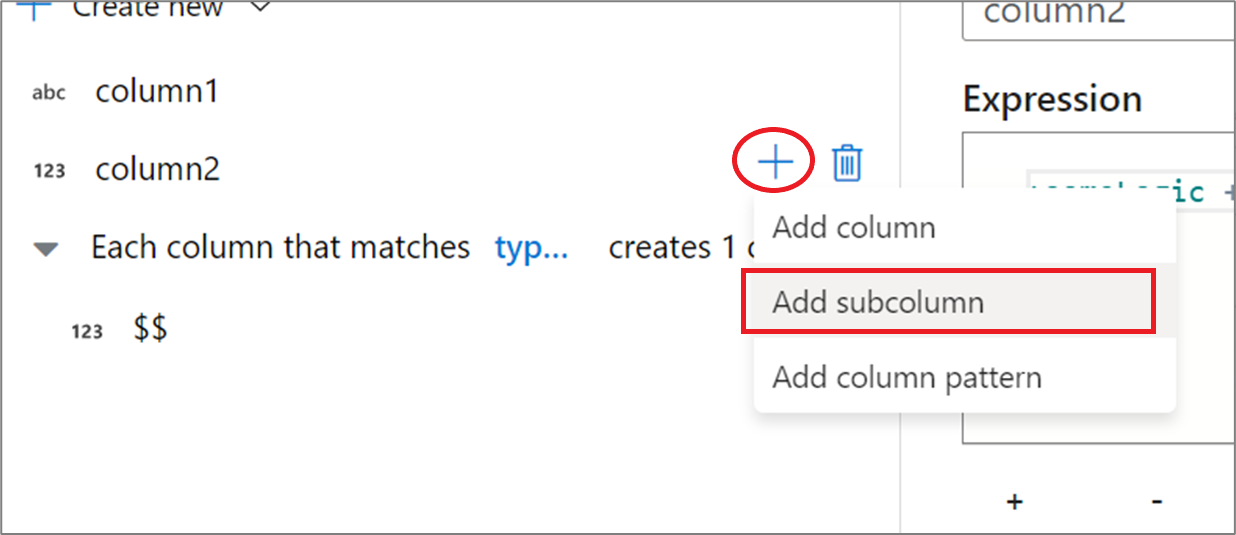
Para adicionar mais colunas derivadas, clique em Adicionar acima da lista de colunas ou no ícone de a mais ao lado de uma coluna derivada existente. Escolha Adicionar coluna ou Adicionar padrão de coluna.
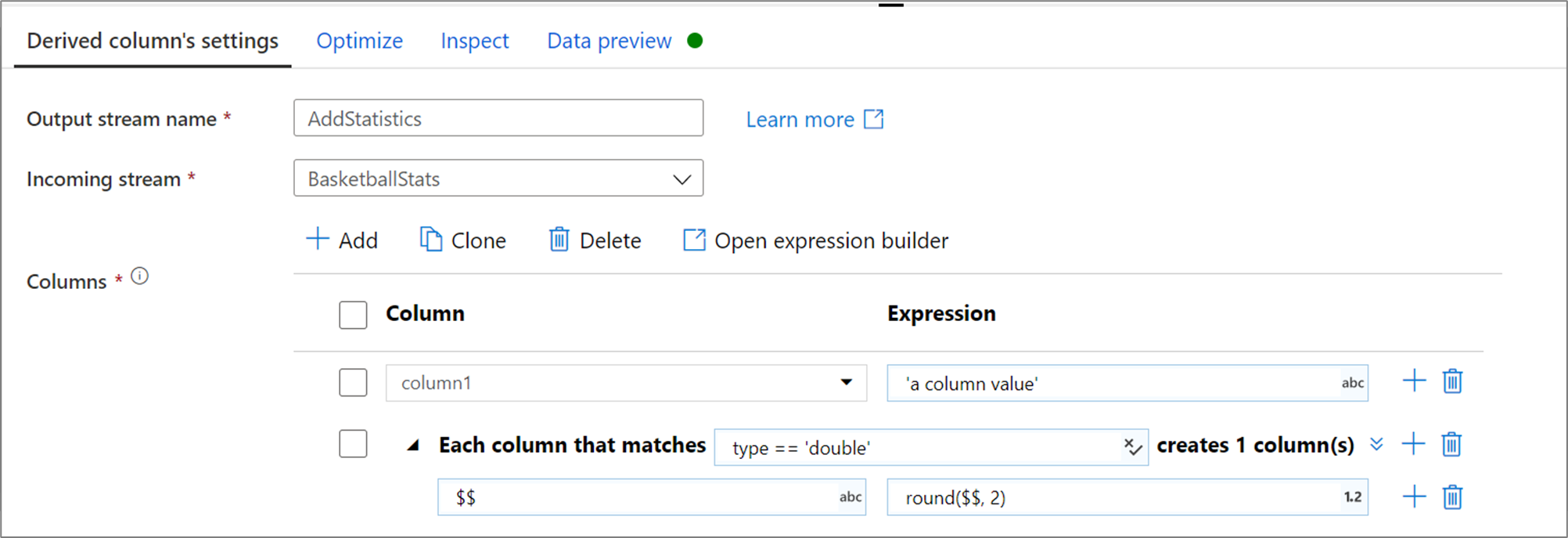
Padrões de coluna
Nos casos em que o esquema não está definido explicitamente ou se você deseja atualizar um conjunto de colunas em massa, você irá querer criar a coluna padrões. Os padrões de coluna permitem que você relacione as colunas usando regras com base nos metadados da coluna e crie colunas derivadas para cada coluna correspondente. Para obter mais informações, saiba como criar padrões de coluna na transformação de coluna derivada.
Criando esquemas usando o construtor de expressões
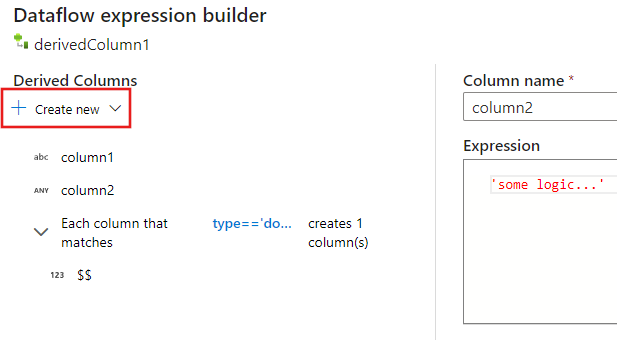
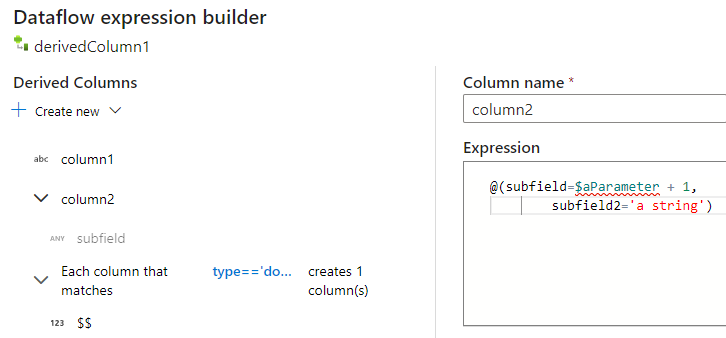
Ao usar o construtor de expressões de fluxo de dados de mapeamento, você pode criar, editar e gerenciar suas colunas derivadas na seção Colunas Derivadas. Todas as colunas que são criadas ou alteradas na transformação são listadas. Escolha interativamente qual coluna ou padrão você está editando ao clicar no nome da coluna. Para adicionar uma coluna adicional, selecione Criar novo e escolha se deseja adicionar uma única coluna ou um padrão.
Ao trabalhar com colunas complexas, você pode criar subcolunas. Para fazer isso, clique no ícone de mais ao lado de qualquer coluna e selecione Adicionar subcoluna. Para obter mais informações sobre como processar tipos complexos no fluxo de dados, confira Tratamento de JSON no fluxo de dados de mapeamento.
Para obter mais informações sobre como processar tipos complexos no fluxo de dados, confira Tratamento de JSON no fluxo de dados de mapeamento.
Script de fluxo de dados
Sintaxe
<incomingStream>
derive(
<columnName1> = <expression1>,
<columnName2> = <expression2>,
each(
match(matchExpression),
<metadataColumn1> = <metadataExpression1>,
<metadataColumn2> = <metadataExpression2>
)
) ~> <deriveTransformationName>
Exemplo
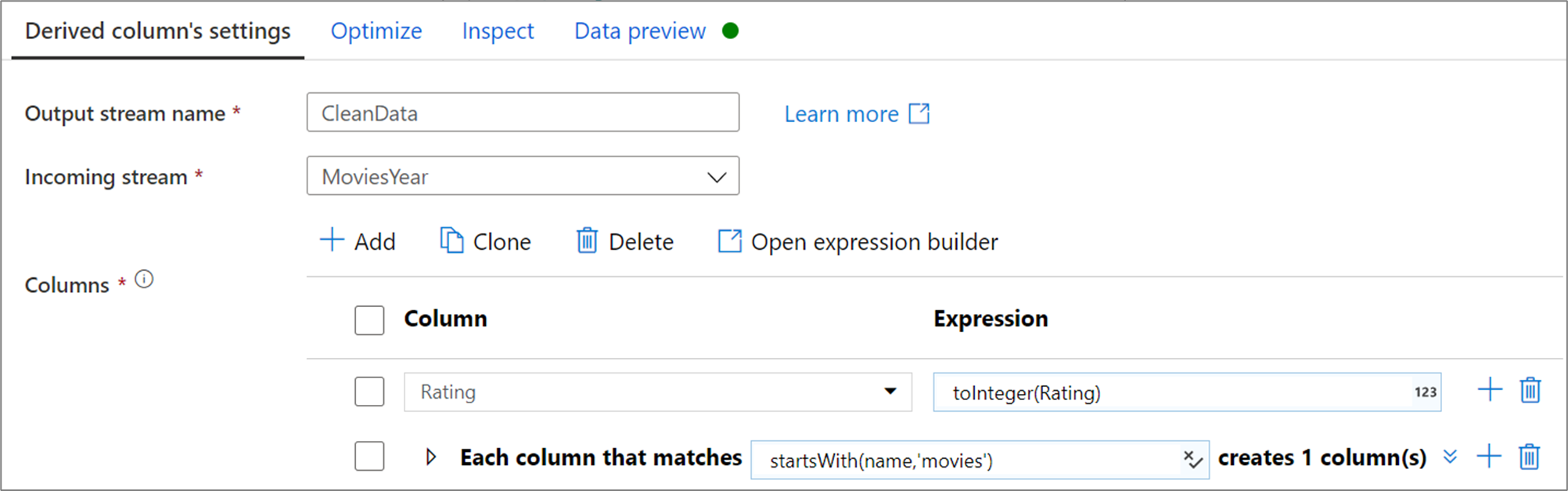
O exemplo abaixo é uma coluna derivada chamada CleanData que usa um fluxo de entrada MoviesYear e cria duas colunas derivadas. A primeira coluna derivada substitui a coluna Rating pelo valor da classificação como um tipo inteiro. A segunda coluna derivada é um padrão que faz a correspondência de cada coluna cujo nome começa com 'movies'. Para cada coluna correspondente, ele cria uma coluna movie que é igual ao valor da coluna correspondente prefixada com 'movie_'.
Na interface do usuário, essa transformação é semelhante à imagem abaixo:
O script de fluxo de dados para essa transformação está no trecho de código abaixo:
MoviesYear derive(
Rating = toInteger(Rating),
each(
match(startsWith(name,'movies')),
'movie' = 'movie_' + toString($$)
)
) ~> CleanData
Conteúdo relacionado
- Saiba mais sobre a linguagem de expressão do fluxo de dados de mapeamento.