Executar um Databricks Notebook com a atividade Databricks Notebook no Azure Data Factory
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Neste tutorial, você usa o portal do Azure para criar um pipeline do Azure Data Factory que executa um Databricks Notebook em cluster de trabalhos Databricks. Ele também passa parâmetros do Azure Data Factory para o Databricks Notebook durante a execução.
Neste tutorial, você realizará os seguintes procedimentos:
Criar um data factory.
Criar um pipeline que usa a atividade Databricks Notebook.
Dispare uma execução de pipeline.
Monitorar a execução de pipeline.
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Para ver uma introdução de 11 minutos e uma demonstração desse recurso, assista ao seguinte vídeo:
Pré-requisitos
- Workspace do Azure Databricks. Criar um workspace no Databricks ou usar um existente. Você pode criar um notebook do Python no workspace do Azure Databricks. Em seguida, execute o notebook e passe parâmetros para ele usando o Azure Data Factory.
Criar uma data factory
Iniciar o navegador da Web Microsoft Edge ou Google Chrome. Atualmente, a interface do usuário do Data Factory tem suporte apenas nos navegadores da Web Microsoft Edge e Google Chrome.
Selecione Criar um recurso no menu do portal do Azure, depois Integração e, por fim, Data Factory.
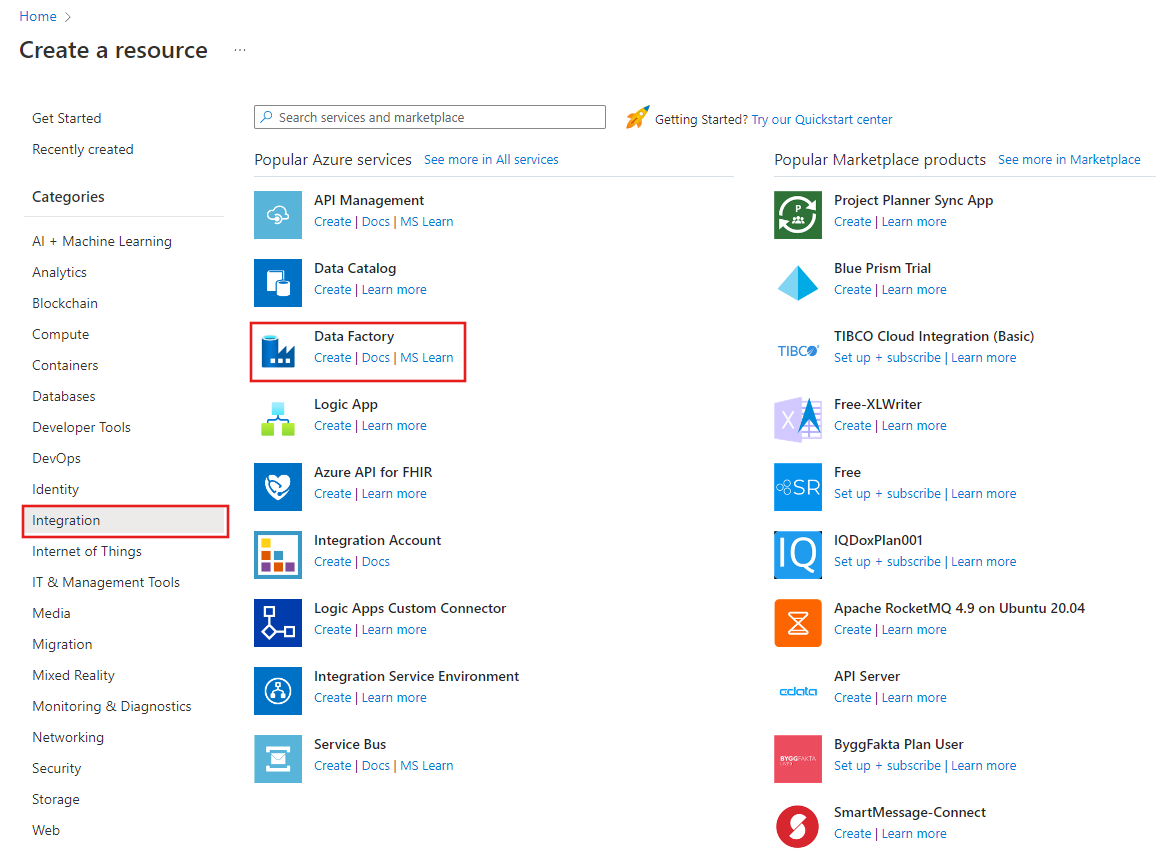
Na página Criar Data Factory, na guia Informações Básicas, selecione sua Assinatura do Azure na qual deseja criar o data factory.
Em Grupo de Recursos, use uma das seguintes etapas:
Selecione um grupo de recursos existente na lista suspensa.
Escolha Criar e insira o nome de um grupo de recursos.
Para saber mais sobre grupos de recursos, consulte Usando grupos de recursos para gerenciar recursos do Azure.
Em Região, selecione a localização para o data factory.
A lista mostra somente os locais aos quais o Data Factory dá suporte e em que os metadados do Azure Data Factory serão armazenados. Os armazenamentos de dados associados (como o Armazenamento do Azure e o Banco de Dados SQL do Azure) e os serviços de computação (como o Azure HDInsight) usados pelo Data Factory podem ser executados em outras regiões.
Em Nome, insira ADFTutorialDataFactory.
O nome do Azure Data Factory deve ser globalmente exclusivo. Se o erro a seguir for exibido, altere o nome do data factory (por exemplo, use <seunome>ADFTutorialDataFactory). Para ver as regras de nomenclatura para artefatos do Data Factory consulte o artigo Data Factory - regras de nomenclatura.
Para Versão, selecione V2.
Selecione Avançar: Configuração do Git e marque a caixa de seleção Configurar o Git mais tarde.
Selecione Examinar + criar e escolha Criar depois que a validação for aprovada.
Após a conclusão da criação, selecione Ir para o recurso para navegar até a página do Data Factory. Selecione o bloco Abrir Azure Data Factory Studio para iniciar o aplicativo da interface do usuário do Azure Data Factory em outra guia do navegador.

Criar serviços vinculados
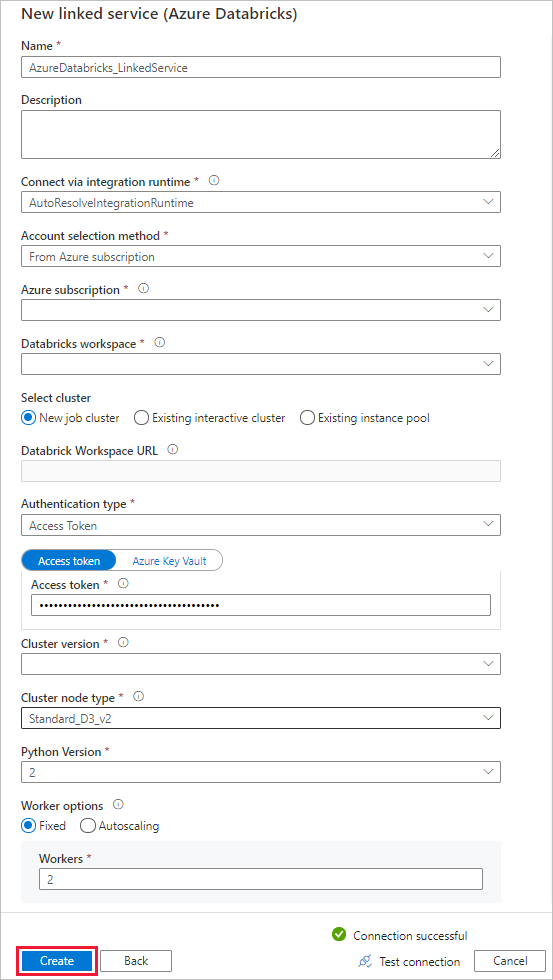
Nesta seção, você cria um serviço vinculado Databricks. Esse serviço vinculado contém as informações de conexão para o cluster Databricks:
Criar um serviço vinculado do Azure Databricks
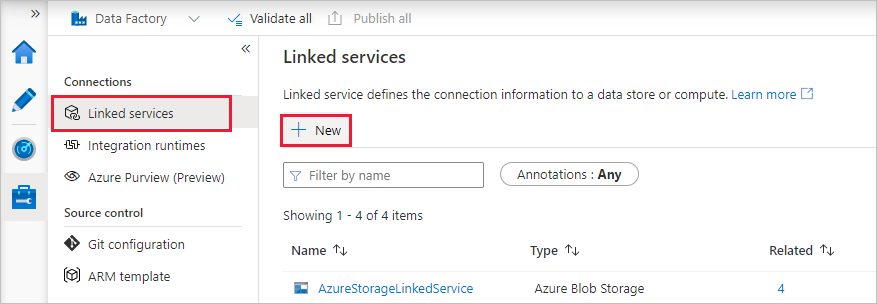
Na home page, alterne para a guia Gerenciar no painel esquerdo.
Selecione Serviços vinculados em Conexões e escolha + Novo.
Na janela Novo serviço vinculado, selecione Computação>Azure Databricks e Continuar.

Na janela Novo serviço vinculado, execute as seguintes etapas:
Para Nome, insira AzureDatabricks_LinkedService.
Escolha o workspace do Databricks adequado em que você executará o notebook.
Em Selecionar cluster, escolha Novo cluster de trabalho.
Em URL do Workspace do Databrick, as informações serão preenchidas automaticamente.
Para Tipo de autenticação, se você selecionar Token de Acesso, gere-o no local de trabalho do Azure Databricks. Você pode encontrar as etapas aqui. Para Identidade de serviço gerenciado e Identidade Gerenciada Atribuída pelo Usuário, conceda a função colaborador a ambas as identidades no menu Controle de acesso do recurso do Azure Databricks.
Em Versão do cluster, selecione a versão que deseja usar.
Para o Tipo de nó de cluster, selecione Standard_D3_v2 na categoria Uso Geral (HD) para este tutorial.
Para Trabalhos, insira 2.
Selecione Criar.
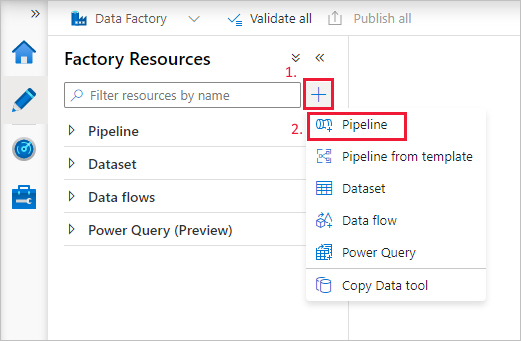
Criar um pipeline
Selecione o botão + (adição) e escolha Pipeline no menu.
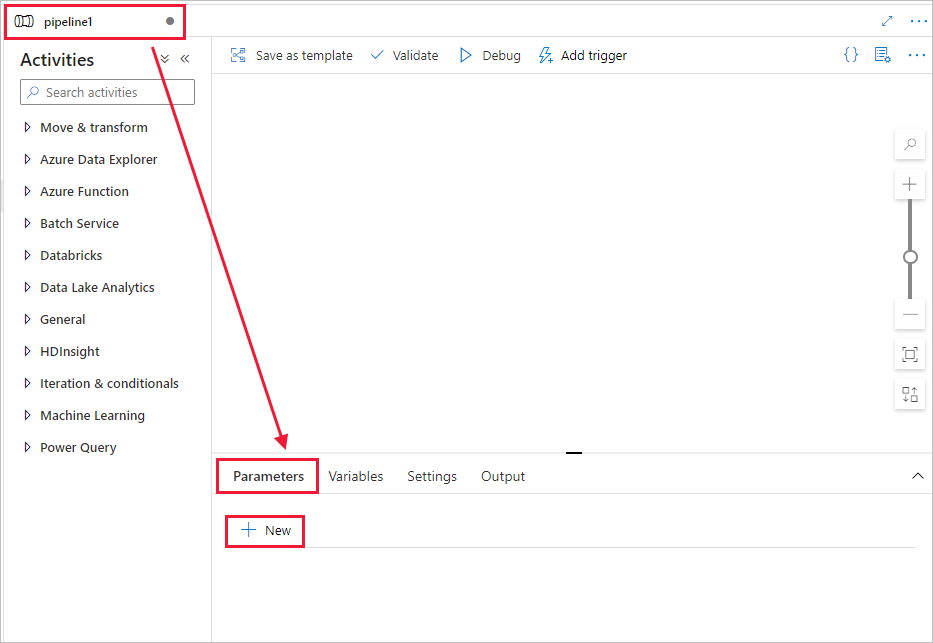
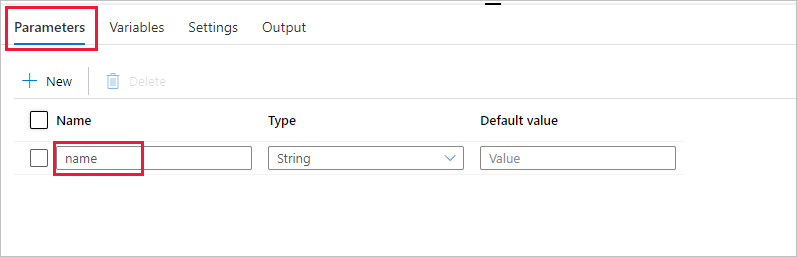
Crie um parâmetro a ser usado no Pipeline. Mais tarde, você passará esse parâmetro para a atividade do Databricks Notebook. No pipeline vazio, selecione a guia Parâmetros, escolha + Novo e chame-a de 'name'.
Na caixa de ferramentas Atividades, expanda Databricks. Arraste a atividade Notebook da caixa de ferramentas Atividades para a superfície do designer do pipeline.
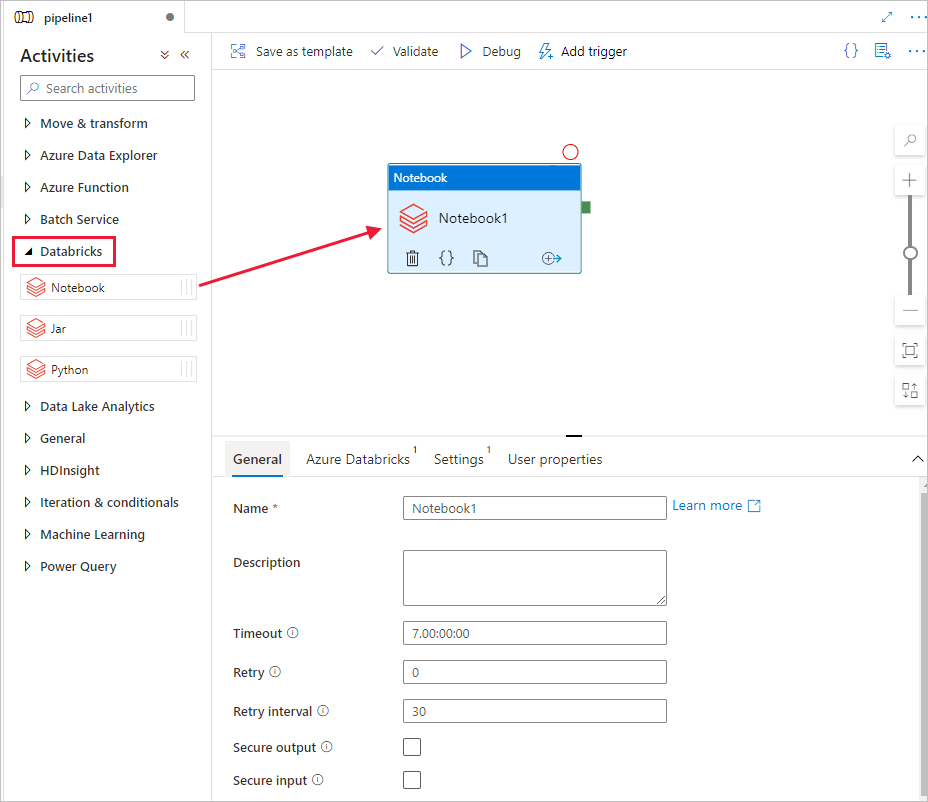
Nas propriedades da atividade Notebook do Databricks, na parte inferior, execute as seguintes etapas:
Alterne para a guia Azure Databricks.
Selecione AzureDatabricks_LinkedService (criado no procedimento anterior).
Alterne para a guia Configurações .
Navegue para selecionar um caminho de Notebook do Databricks. Vamos criar um notebook e especificar o caminho aqui. Siga as próximas etapas para obter o Caminho do Notebook.
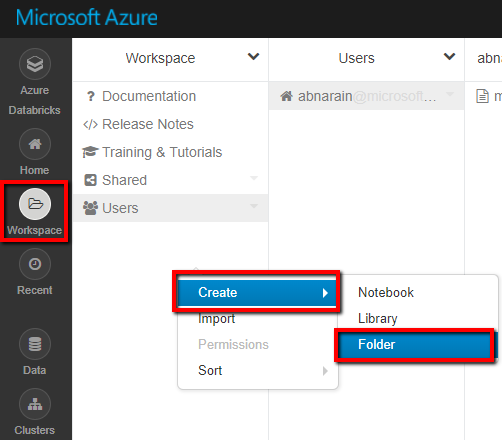
Inicie o workspace do Azure Databricks.
Crie uma Nova Pasta no local de trabalho e chame-a de adftutorial.
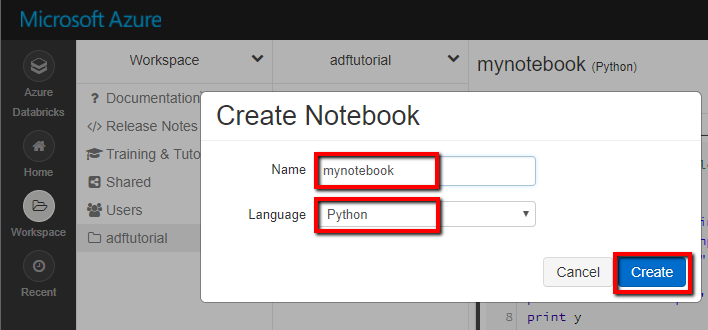
Captura de tela que mostra como criar um notebook. (Python), vamos chamá-lo de mynotebook na pasta adftutorial e clicar em Criar.

No notebook recém-criado, “mynotebook”, adicione o seguinte código:
# Creating widgets for leveraging parameters, and printing the parameters dbutils.widgets.text("input", "","") y = dbutils.widgets.get("input") print ("Param -\'input':") print (y)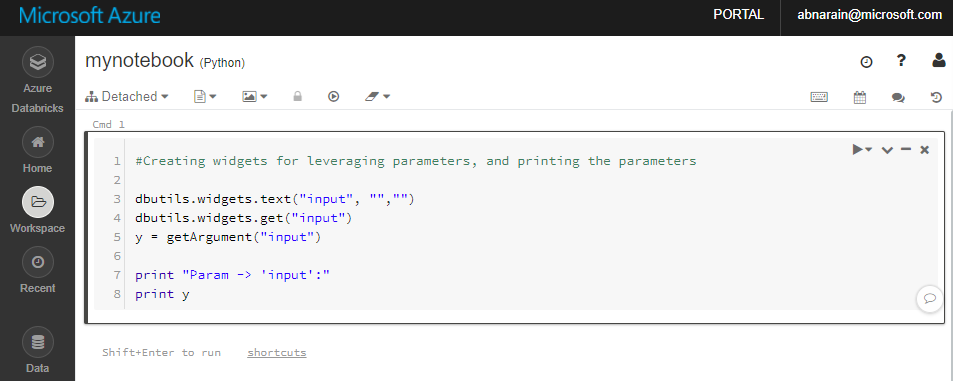
O Caminho do Notebook, nesse caso, é /adftutorial/mynotebook.
Volte para a ferramenta de criação de IU do Data Factory. Navegue até a guia Configurações na atividade Notebook1.
a. Adicione um parâmetro à atividade de Notebook. Use o mesmo parâmetro que você adicionou anteriormente ao Pipeline.
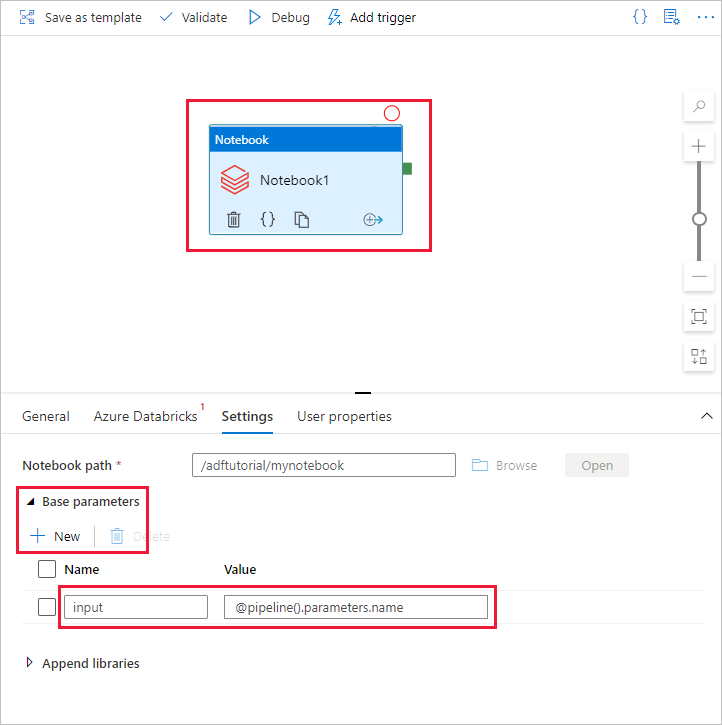
b. Nomear o parâmetro como input e fornecer o valor como expressão @pipeline().parameters.name.
Para validar o pipeline, selecione o botão Validar na barra de ferramentas. Para fechar a janela de validação, selecione o botão Fechar.
Selecione Publicar tudo. A IU de Data Factory publica entidades (serviços vinculados e pipeline) para o serviço Azure Data Factory.
Disparar uma execução de pipeline
Selecione Adicionar gatilho na barra de ferramentas e escolha Disparar agora.
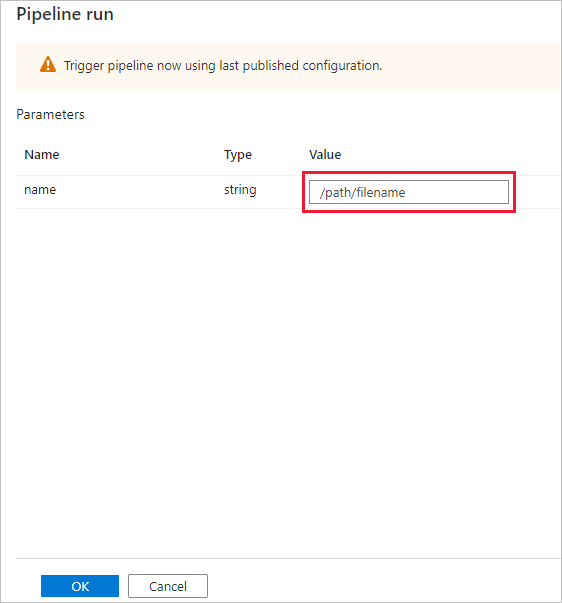
A caixa de diálogo Execução de pipeline solicitará o parâmetro name. Use /path/filename como o parâmetro aqui. Selecione OK.
Monitorar a execução de pipeline
Alterne para a guia Monitorar. Verifique se o pipeline está sendo executado. Leva aproximadamente 5 a 8 minutos para criar um cluster de trabalho do Databricks onde o notebook é executado.
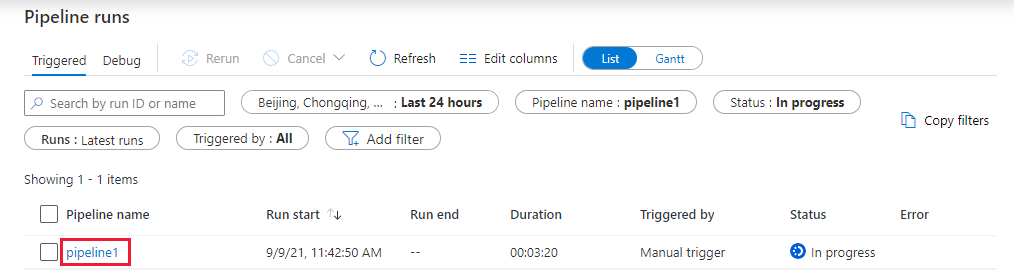
Selecione Atualizar periodicamente para verificar o status da execução do pipeline.
Para ver as execuções de atividades associadas à execução de pipeline, selecione o link pipeline1 na coluna Nome do pipeline.
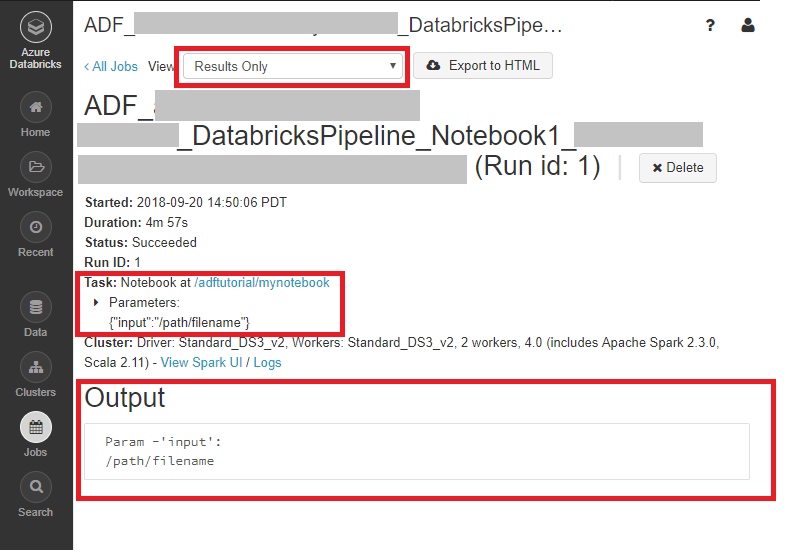
Na página Execuções de atividades, selecione Saída na coluna Nome da atividade para ver a saída de cada atividade. Encontre o link para os logs do Databricks no painel Saída para obter logs do Spark mais detalhados.
Volte à exibição das execuções de pipelines selecionando o link Todas as execuções de pipelines no menu estrutural no canto superior.
Verificar a saída
Você pode fazer logon no workspace do Azure Databricks; vá para Clusters e veja o status do trabalho como execução pendente, em execução ou concluído.
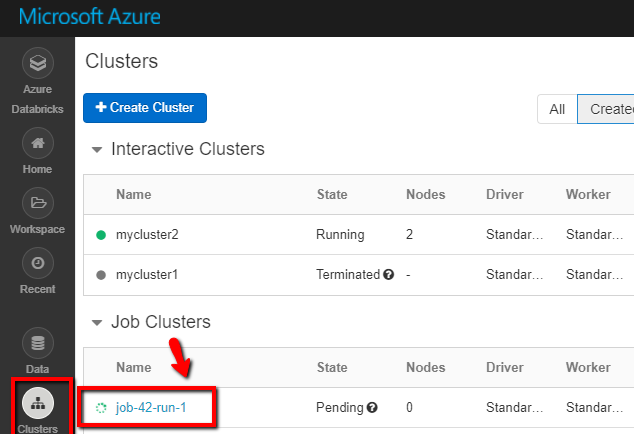
Você pode clicar no nome do trabalho e navegar para ver mais detalhes. Ao executar com êxito, você pode validar os parâmetros passados e a saída do Notebook Python.
Conteúdo relacionado
O pipeline neste exemplo dispara uma atividade do Databricks Notebook e passa um parâmetro para ele. Você aprendeu a:
Criar um data factory.
Criar um pipeline que usa uma atividade do Databricks Notebook.
Dispare uma execução de pipeline.
Monitorar a execução de pipeline.