Ramificação e encadeamento de atividades em um pipeline de Data Factory
APLICA-SE A: Azure Data Factory
Azure Data Factory  Azure Synapse Analytics
Azure Synapse Analytics
Dica
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange desde movimentação de dados até ciência de dados, análise em tempo real, business intelligence e relatórios. Saiba como iniciar uma avaliação gratuita!
Neste tutorial, você deve criar um pipeline de Data Factory que apresente alguns dos recursos de fluxo de controle. Esse pipeline copia um contêiner no Armazenamento de Blobs do Azure para outro contêiner na mesma conta de armazenamento. Se a atividade de cópia for bem-sucedida, o pipeline enviará detalhes da operação de cópia bem-sucedida em um email. Essas informações podem incluir a quantidade de dados gravados. Se a atividade de cópia falhar, o pipeline enviará detalhes da falha de cópia (por exemplo, a mensagem de erro) em um email. Ao longo do tutorial, você verá como passar parâmetros.
Este gráfico fornece uma visão geral do cenário:
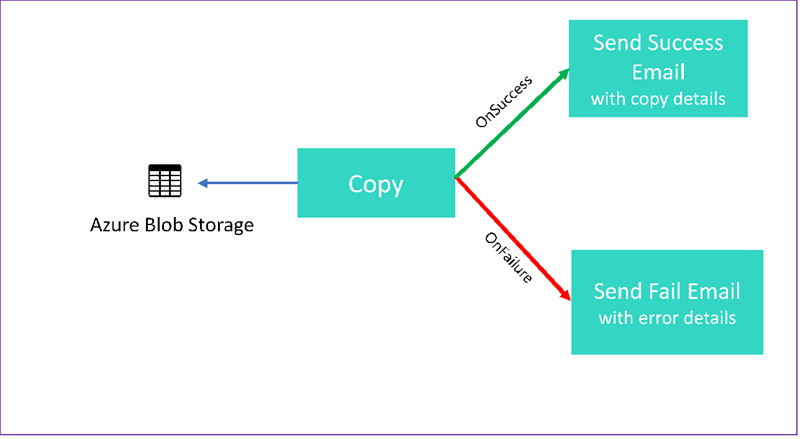
O tutorial mostra como executar as seguintes tarefas:
- Criar uma data factory
- Criar um serviço vinculado do Armazenamento do Azure
- Criar um conjunto de dados do Blob do Azure
- Criar um pipeline que contém uma atividade de cópia e uma atividade da Web
- Enviar saídas de atividades para as atividades subsequentes
- Usar passagem de parâmetros e variáveis do sistema
- Iniciar uma execução de pipeline
- Monitorar as execuções de pipeline e de atividade
Este tutorial usa o .NET SDK. Você pode usar outros mecanismos para interagir com o Azure Data Factory. Para obter guias de início rápido do Data Factory, confira os Guias de início rápido de cinco minutos.
Se você não tiver uma assinatura do Azure, crie uma conta gratuita antes de começar.
Pré-requisitos
- Conta de Armazenamento do Azure. Você usa o Armazenamento de Blobs como um armazenamento de dados de origem. Se você não tiver uma conta de armazenamento do Azure, consulte o artigo Criar uma conta de armazenamento.
- Gerenciador de Armazenamento do Azure. Para instalar essa ferramenta, confira o Gerenciador de Armazenamento do Azure.
- Banco de Dados SQL do Azure. Você usa o banco de dados como um armazenamento de dados de coletor. Se você não tiver um banco de dados no Banco de Dados SQL do Azure, confira Criar um banco de dados no Banco de Dados SQL do Azure.
- Visual Studio. Este artigo usa o Visual Studio 2019.
- SDK do .NET do Azure. Baixar e instalar o SDK do .NET do Azure.
Para obter uma lista de regiões do Azure nas quais o Data Factory está atualmente disponível, confira Produtos disponíveis por região. Os armazenamentos de dados e as computações podem estar em outras regiões. Os repositórios incluem o Armazenamento do Azure e o Banco de Dados SQL do Azure. As computações incluem o HDInsight, que Data Factory usa.
Crie um aplicativo conforme descrito em Criar um aplicativo do Microsoft Entra. Seguindo as instruções no mesmo artigo, atribua o aplicativo à função Colaborador. Você precisará de vários valores para as partes posteriores deste tutorial, como tais como ID do Aplicativo (cliente) e ID do Diretório (locatário) .
Criar uma tabela de blob
Abra um editor de texto. Copie o texto a seguir e salve-o localmente como um arquivo input.txt.
Ethel|Berg Tamika|WalshAbra o Gerenciador de Armazenamento do Azure. Expanda sua conta de armazenamento. Clique com o botão direito do mouse em Contêineres de Blob e selecione Criar Contêiner de Blob.
Nomeie o novo contêiner adfv2branch e selecione Upload para adicionar o arquivo input.txt ao contêiner.
Criar um projeto do Visual Studio
Criar um aplicativo de console do .NET em C#:
- Inicie o Visual Studio e selecione Criar um projeto.
- Em Criar um novo projeto, escolha Aplicativo de Console (.NET Framework) para C# e, em seguida, selecione Avançar.
- Nomeie o projeto ADFv2BranchTutorial.
- Selecione .NET versão 4.5.2 ou superior e, em seguida, selecione Criar.
Instalar os pacotes NuGet
Selecione Ferramentas>Gerenciador de Pacotes NuGet>Console do Gerenciador de Pacotes.
No Console do Gerenciador de Pacotes, execute os comandos a seguir para instalar os pacotes. Veja o pacote NuGet Microsoft.Azure.Management.DataFactory para obter detalhes.
Install-Package Microsoft.Azure.Management.DataFactory Install-Package Microsoft.Azure.Management.ResourceManager -IncludePrerelease Install-Package Microsoft.IdentityModel.Clients.ActiveDirectory
Criar um cliente data factory
Abra Program.cs e adicione as seguintes instruções:
using System; using System.Collections.Generic; using System.Linq; using Microsoft.Rest; using Microsoft.Azure.Management.ResourceManager; using Microsoft.Azure.Management.DataFactory; using Microsoft.Azure.Management.DataFactory.Models; using Microsoft.IdentityModel.Clients.ActiveDirectory;Adicione essas variáveis estáticas à classe
Program. Substitua os espaços reservados por seus próprios valores.// Set variables static string tenantID = "<tenant ID>"; static string applicationId = "<application ID>"; static string authenticationKey = "<Authentication key for your application>"; static string subscriptionId = "<Azure subscription ID>"; static string resourceGroup = "<Azure resource group name>"; static string region = "East US"; static string dataFactoryName = "<Data factory name>"; // Specify the source Azure Blob information static string storageAccount = "<Azure Storage account name>"; static string storageKey = "<Azure Storage account key>"; // confirm that you have the input.txt file placed in th input folder of the adfv2branch container. static string inputBlobPath = "adfv2branch/input"; static string inputBlobName = "input.txt"; static string outputBlobPath = "adfv2branch/output"; static string emailReceiver = "<specify email address of the receiver>"; static string storageLinkedServiceName = "AzureStorageLinkedService"; static string blobSourceDatasetName = "SourceStorageDataset"; static string blobSinkDatasetName = "SinkStorageDataset"; static string pipelineName = "Adfv2TutorialBranchCopy"; static string copyBlobActivity = "CopyBlobtoBlob"; static string sendFailEmailActivity = "SendFailEmailActivity"; static string sendSuccessEmailActivity = "SendSuccessEmailActivity";Adicione o seguinte código ao
Mainmétodo. Esse código cria uma instância da classeDataFactoryManagementClient. Você usa esse objeto para criar o Data Factory, o serviço vinculado, os conjuntos de dados e o pipeline. Você também pode usar esse objeto para monitorar os detalhes da execução de pipeline.// Authenticate and create a data factory management client var context = new AuthenticationContext("https://login.windows.net/" + tenantID); ClientCredential cc = new ClientCredential(applicationId, authenticationKey); AuthenticationResult result = context.AcquireTokenAsync("https://management.azure.com/", cc).Result; ServiceClientCredentials cred = new TokenCredentials(result.AccessToken); var client = new DataFactoryManagementClient(cred) { SubscriptionId = subscriptionId };
Criar uma data factory
Adicione um método
CreateOrUpdateDataFactoryao arquivo Program.cs:static Factory CreateOrUpdateDataFactory(DataFactoryManagementClient client) { Console.WriteLine("Creating data factory " + dataFactoryName + "..."); Factory resource = new Factory { Location = region }; Console.WriteLine(SafeJsonConvert.SerializeObject(resource, client.SerializationSettings)); Factory response; { response = client.Factories.CreateOrUpdate(resourceGroup, dataFactoryName, resource); } while (client.Factories.Get(resourceGroup, dataFactoryName).ProvisioningState == "PendingCreation") { System.Threading.Thread.Sleep(1000); } return response; }Adicione o código a seguir, que cria um Data Factory, ao método
Main:Factory df = CreateOrUpdateDataFactory(client);
Criar um serviço vinculado do Armazenamento do Azure
Adicione um método
StorageLinkedServiceDefinitionao arquivo Program.cs:static LinkedServiceResource StorageLinkedServiceDefinition(DataFactoryManagementClient client) { Console.WriteLine("Creating linked service " + storageLinkedServiceName + "..."); AzureStorageLinkedService storageLinkedService = new AzureStorageLinkedService { ConnectionString = new SecureString("DefaultEndpointsProtocol=https;AccountName=" + storageAccount + ";AccountKey=" + storageKey) }; Console.WriteLine(SafeJsonConvert.SerializeObject(storageLinkedService, client.SerializationSettings)); LinkedServiceResource linkedService = new LinkedServiceResource(storageLinkedService, name:storageLinkedServiceName); return linkedService; }Adicione a linha a seguir, que cria um serviço vinculado do Armazenamento do Azure, ao método
Main:client.LinkedServices.CreateOrUpdate(resourceGroup, dataFactoryName, storageLinkedServiceName, StorageLinkedServiceDefinition(client));
Para obter mais detalhes e informações sobre propriedades compatíveis, confira Propriedades do serviço vinculado.
Criar conjuntos de dados
Nesta seção, você criará dois conjuntos de dados: um para a origem e o outro para o coletor.
Criar um conjunto de dados para um Blob do Azure de origem
Adicione um método que cria um conjunto de dados de Blob do Azure. Para obter mais detalhes e informações sobre propriedades compatíveis, confira Propriedades do conjunto de dados de Blob do Azure.
Adicione um método SourceBlobDatasetDefinition ao arquivo Program.cs:
static DatasetResource SourceBlobDatasetDefinition(DataFactoryManagementClient client)
{
Console.WriteLine("Creating dataset " + blobSourceDatasetName + "...");
AzureBlobDataset blobDataset = new AzureBlobDataset
{
FolderPath = new Expression { Value = "@pipeline().parameters.sourceBlobContainer" },
FileName = inputBlobName,
LinkedServiceName = new LinkedServiceReference
{
ReferenceName = storageLinkedServiceName
}
};
Console.WriteLine(SafeJsonConvert.SerializeObject(blobDataset, client.SerializationSettings));
DatasetResource dataset = new DatasetResource(blobDataset, name:blobSourceDatasetName);
return dataset;
}
Você define um conjunto de dados que representa os dados de origem no Blob do Azure. Esse conjunto de dados de Blob refere-se ao serviço vinculado do Armazenamento do Azure compatível na etapa anterior. O conjunto de conjuntos de blob descreve a localização do blob do qual copiar: FolderPath e FileName.
Observe o uso de parâmetros para FolderPath. sourceBlobContainer é o nome do parâmetro e a expressão é substituída pelos valores passados na execução de pipeline. A sintaxe para definir os parâmetros é @pipeline().parameters.<parameterName>
Criar um conjunto de dados para um Blob do Azure de coletor
Adicione um método
SourceBlobDatasetDefinitionao arquivo Program.cs:static DatasetResource SinkBlobDatasetDefinition(DataFactoryManagementClient client) { Console.WriteLine("Creating dataset " + blobSinkDatasetName + "..."); AzureBlobDataset blobDataset = new AzureBlobDataset { FolderPath = new Expression { Value = "@pipeline().parameters.sinkBlobContainer" }, LinkedServiceName = new LinkedServiceReference { ReferenceName = storageLinkedServiceName } }; Console.WriteLine(SafeJsonConvert.SerializeObject(blobDataset, client.SerializationSettings)); DatasetResource dataset = new DatasetResource(blobDataset, name: blobSinkDatasetName); return dataset; }Adicione o código a seguir, que cria o conjunto de dados de origem e também o de coletor do Blob do Azure, ao método
Main.client.Datasets.CreateOrUpdate(resourceGroup, dataFactoryName, blobSourceDatasetName, SourceBlobDatasetDefinition(client)); client.Datasets.CreateOrUpdate(resourceGroup, dataFactoryName, blobSinkDatasetName, SinkBlobDatasetDefinition(client));
Crie uma classe C#: EmailRequest
Em seu projeto do C#, crie uma classe denominada EmailRequest. Essa classe define quais propriedades o pipeline envia no corpo da solicitação ao enviar um email. Neste tutorial, o pipeline envia as quatro propriedades do pipeline para o email:
- Message. Corpo do email. Para uma cópia bem-sucedida, essa propriedade contém a quantidade de dados gravados. Para uma cópia com falha, esta propriedade conterá os detalhes do erro.
- Nome do Data Factory. Nome do Data Factory.
- Nome do pipeline. Nome do pipeline.
- Receptor. Parâmetro que passa. Essa propriedade especifica o destinatário do email.
class EmailRequest
{
[Newtonsoft.Json.JsonProperty(PropertyName = "message")]
public string message;
[Newtonsoft.Json.JsonProperty(PropertyName = "dataFactoryName")]
public string dataFactoryName;
[Newtonsoft.Json.JsonProperty(PropertyName = "pipelineName")]
public string pipelineName;
[Newtonsoft.Json.JsonProperty(PropertyName = "receiver")]
public string receiver;
public EmailRequest(string input, string df, string pipeline, string receiverName)
{
message = input;
dataFactoryName = df;
pipelineName = pipeline;
receiver = receiverName;
}
}
Criar pontos de extremidade do fluxo de trabalho de email
Para disparar o envio de um email, você deve usar os Aplicativos Lógicos do Azure para definir o fluxo de trabalho. Para obter mais informações, confira Criar um fluxo de trabalho do aplicativo lógico de Consumo de exemplo.
Fluxo de trabalho de email de êxito
No Portal do Azure, crie um fluxo de trabalho do aplicativo lógico chamado CopySuccessEmail. Adicione o gatilho de Solicitação chamado Quando uma solicitação HTTP é recebida. No gatilho Solicitação, preencha a caixa Esquema JSON do Corpo da Solicitação com o seguinte JSON:
{
"properties": {
"dataFactoryName": {
"type": "string"
},
"message": {
"type": "string"
},
"pipelineName": {
"type": "string"
},
"receiver": {
"type": "string"
}
},
"type": "object"
}
O fluxo de trabalho terá aparência semelhante à do exemplo a seguir:
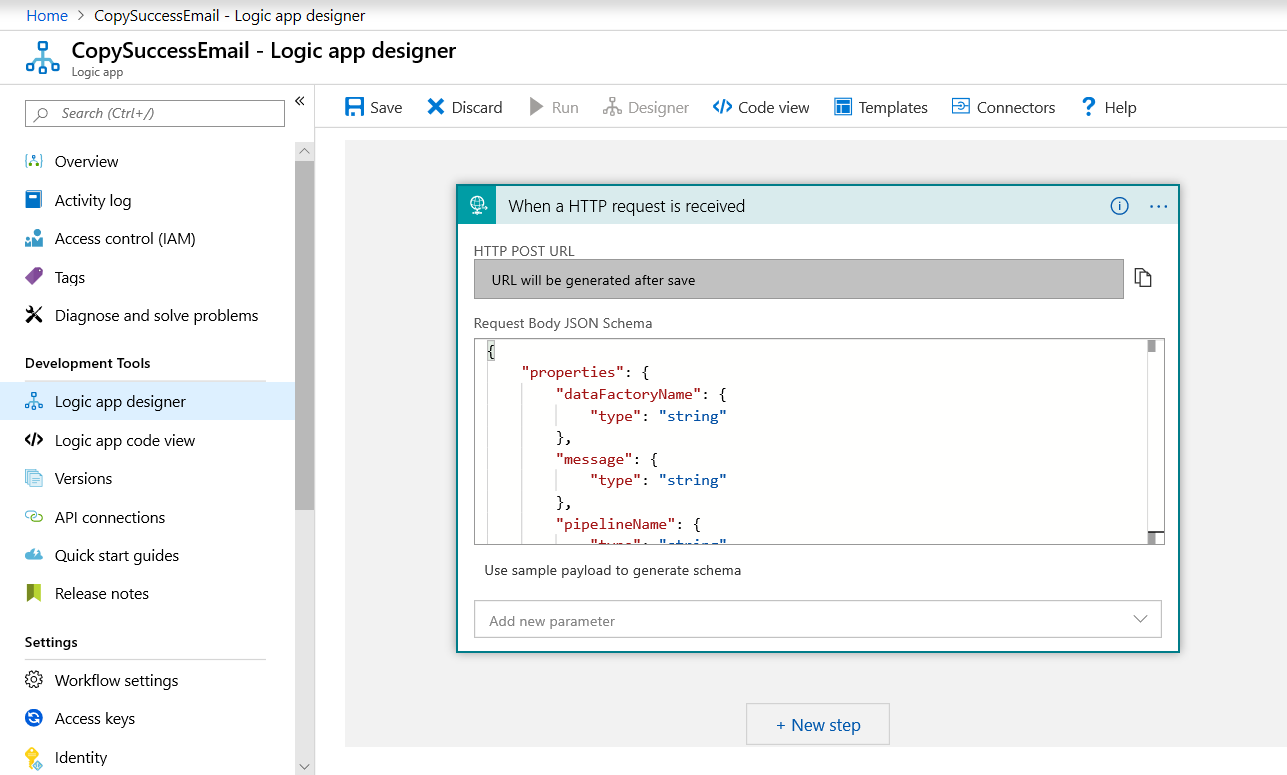
Esse conteúdo JSON se alinha com a classe EmailRequest que você criou na seção anterior.
Adicione a ação do Office 365 Outlook chamada Enviar um email. Para essa ação, personalize o modo como você deseja formatar o email, usando as propriedades passadas no esquema JSON do Corpo da solicitação. Aqui está um exemplo:
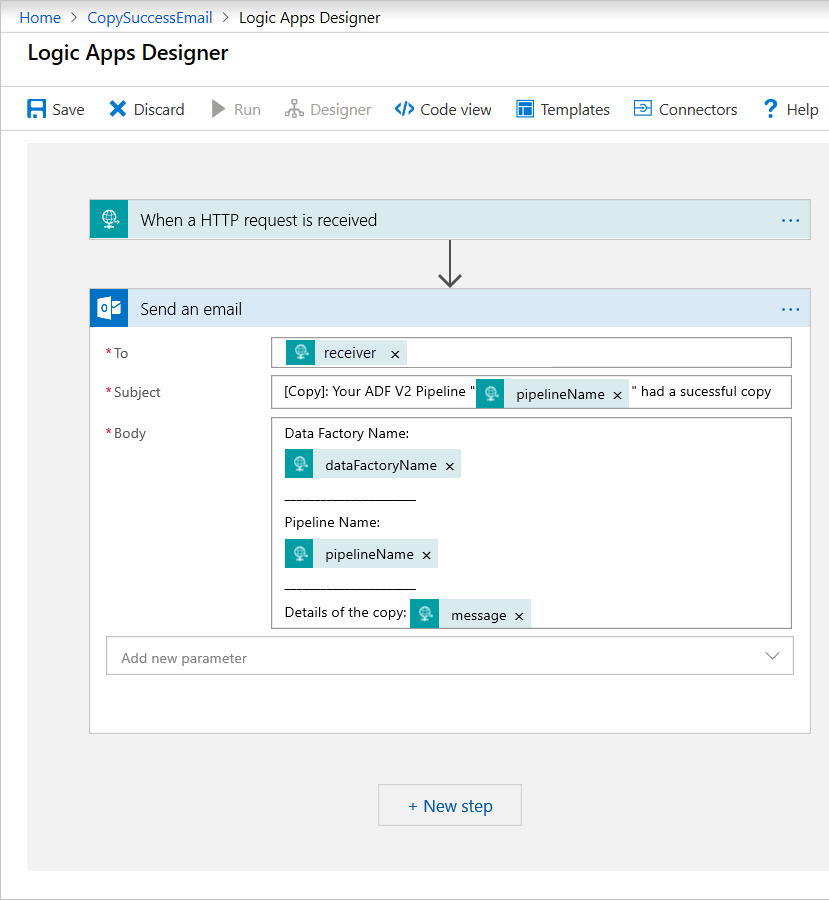
Depois de salvar o fluxo de trabalho, copie e salve o valor da URL HTTP POST do gatilho.
Fluxo de trabalho de email de falha
Clone o fluxo de trabalho do aplicativo lógico CopySuccessEmail em um novo fluxo de trabalho chamado CopyFailEmail. No gatilho Solicitação, o esquema JSON do Corpo da Solicitação é o mesmo. Altere o formato do seu email como o Subject para ajustá-lo, tornando-o um email de falha. Veja um exemplo:
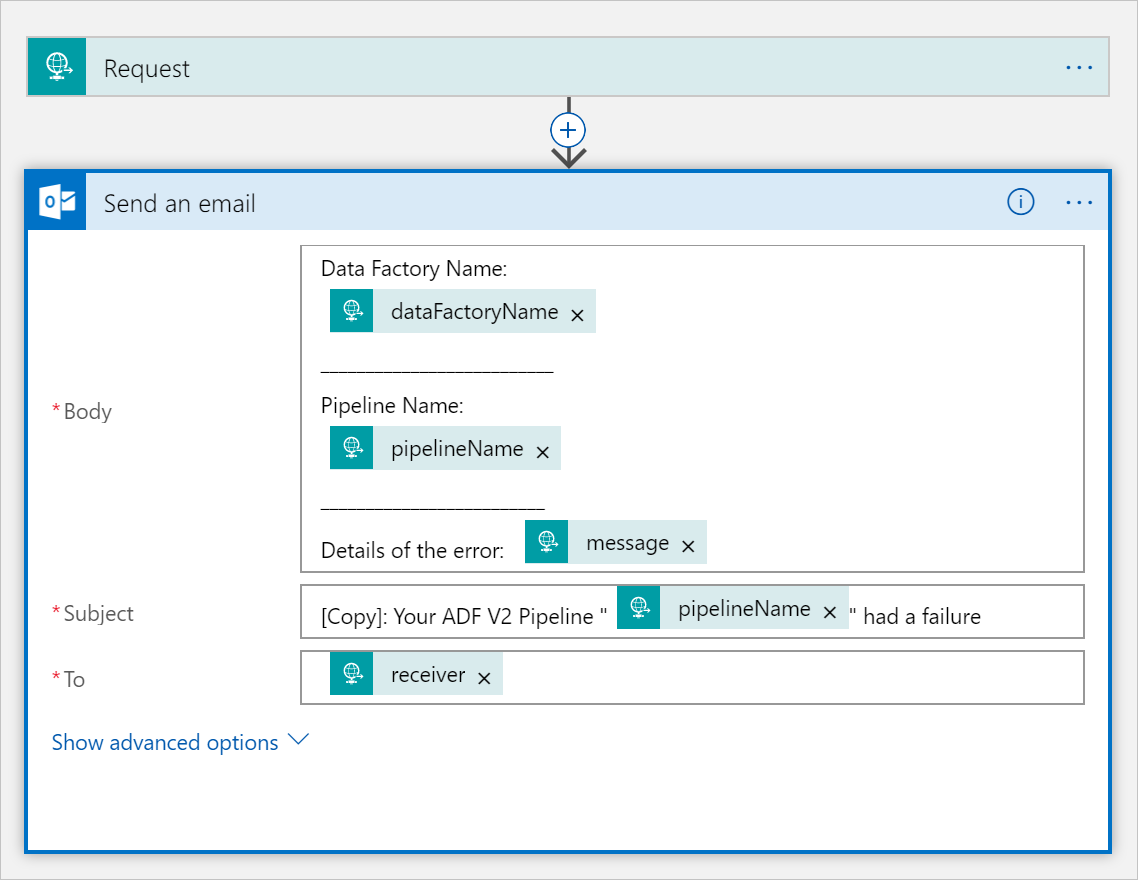
Depois de salvar o fluxo de trabalho, copie e salve o valor da URL HTTP POST do gatilho.
Agora você deve ter duas URLs de fluxo de trabalho, tais como os exemplos a seguir:
//Success Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
//Fail Request Url
https://prodxxx.eastus.logic.azure.com:443/workflows/000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=000000
Criar um pipeline
Volte ao seu projeto no Visual Studio. Agora, adicionaremos o código que cria um pipeline com uma atividade de cópia e a propriedade DependsOn. Neste tutorial, o pipeline contém uma atividade, que é de cópia e usa o conjunto de dados de Blob como uma origem e outro conjunto de dados de Blob como um coletor. Se a atividade de cópia tiver êxito/falhar, ele chamará tarefas de email diferentes.
Nesse pipeline, você deve usar os seguintes recursos:
- Parâmetros
- Atividade da Web
- Dependência de atividade
- Usando a saída de uma atividade como uma entrada para outra atividade
Adicione esse método ao projeto. As seções a seguir fornecem mais detalhes.
static PipelineResource PipelineDefinition(DataFactoryManagementClient client) { Console.WriteLine("Creating pipeline " + pipelineName + "..."); PipelineResource resource = new PipelineResource { Parameters = new Dictionary<string, ParameterSpecification> { { "sourceBlobContainer", new ParameterSpecification { Type = ParameterType.String } }, { "sinkBlobContainer", new ParameterSpecification { Type = ParameterType.String } }, { "receiver", new ParameterSpecification { Type = ParameterType.String } } }, Activities = new List<Activity> { new CopyActivity { Name = copyBlobActivity, Inputs = new List<DatasetReference> { new DatasetReference { ReferenceName = blobSourceDatasetName } }, Outputs = new List<DatasetReference> { new DatasetReference { ReferenceName = blobSinkDatasetName } }, Source = new BlobSource { }, Sink = new BlobSink { } }, new WebActivity { Name = sendSuccessEmailActivity, Method = WebActivityMethod.POST, Url = "https://prodxxx.eastus.logic.azure.com:443/workflows/00000000000000000000000000000000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=0000000000000000000000000000000000000000000000", Body = new EmailRequest("@{activity('CopyBlobtoBlob').output.dataWritten}", "@{pipeline().DataFactory}", "@{pipeline().Pipeline}", "@pipeline().parameters.receiver"), DependsOn = new List<ActivityDependency> { new ActivityDependency { Activity = copyBlobActivity, DependencyConditions = new List<String> { "Succeeded" } } } }, new WebActivity { Name = sendFailEmailActivity, Method =WebActivityMethod.POST, Url = "https://prodxxx.eastus.logic.azure.com:443/workflows/000000000000000000000000000000000/triggers/manual/paths/invoke?api-version=2016-10-01&sp=%2Ftriggers%2Fmanual%2Frun&sv=1.0&sig=0000000000000000000000000000000000000000000", Body = new EmailRequest("@{activity('CopyBlobtoBlob').error.message}", "@{pipeline().DataFactory}", "@{pipeline().Pipeline}", "@pipeline().parameters.receiver"), DependsOn = new List<ActivityDependency> { new ActivityDependency { Activity = copyBlobActivity, DependencyConditions = new List<String> { "Failed" } } } } } }; Console.WriteLine(SafeJsonConvert.SerializeObject(resource, client.SerializationSettings)); return resource; }Adicione o código a seguir, que cria o pipeline, ao método
Main:client.Pipelines.CreateOrUpdate(resourceGroup, dataFactoryName, pipelineName, PipelineDefinition(client));
Parâmetros
A primeira seção do nosso código de pipeline define parâmetros.
sourceBlobContainer. O conjunto de dados de blob de origem consome esse parâmetro no pipeline.sinkBlobContainer. O conjunto de dados de blob de coletor consome esse parâmetro no pipeline.receiver. As duas atividades da Web no pipeline que enviam emails de êxito ou de falha para o receptor usam esse parâmetro.
Parameters = new Dictionary<string, ParameterSpecification>
{
{ "sourceBlobContainer", new ParameterSpecification { Type = ParameterType.String } },
{ "sinkBlobContainer", new ParameterSpecification { Type = ParameterType.String } },
{ "receiver", new ParameterSpecification { Type = ParameterType.String } }
},
Atividade da Web
A atividade da Web permite uma chamada para qualquer ponto de extremidade REST. Para obter mais informações sobre a atividade, confira o artigo Atividade da Web no Azure Data Factory. Esse pipeline usa uma atividade de Web para chamar o fluxo de trabalho de email de Aplicativos Lógicos. Você cria duas atividades da Web: um que chama o fluxo de trabalho CopySuccessEmail e outro que chama o CopyFailWorkFlow.
new WebActivity
{
Name = sendCopyEmailActivity,
Method = WebActivityMethod.POST,
Url = "https://prodxxx.eastus.logic.azure.com:443/workflows/12345",
Body = new EmailRequest("@{activity('CopyBlobtoBlob').output.dataWritten}", "@{pipeline().DataFactory}", "@{pipeline().Pipeline}", "@pipeline().parameters.receiver"),
DependsOn = new List<ActivityDependency>
{
new ActivityDependency
{
Activity = copyBlobActivity,
DependencyConditions = new List<String> { "Succeeded" }
}
}
}
Na propriedade Url, cole os pontos de extremidade da URL POST HTTP dos seus fluxos de trabalho de Aplicativos Lógicos. Na propriedade Body, crie uma instância da classe EmailRequest. A solicitação de email contém as seguintes propriedades:
- Message. Passa o valor de
@{activity('CopyBlobtoBlob').output.dataWritten. Acessa uma propriedade da atividade de cópia anterior e passa o valor dedataWritten. Em caso de falha, passe a saída de erro em vez de@{activity('CopyBlobtoBlob').error.message. - Nome do Data Factory. Passa o valor de
@{pipeline().DataFactory}Essa variável de sistema permite que você acesse o nome do Data Factory correspondente. Para obter uma lista das variáveis de sistema, confira Variáveis de Sistema. - Nome do pipeline. Passa o valor de
@{pipeline().Pipeline}. Essa variável de sistema permite que você acesse o nome do pipeline correspondente. - Receptor. Passa o valor de
"@pipeline().parameters.receiver". Acessa os parâmetros de pipeline.
Esse código cria uma nova Dependência de Atividade que depende da atividade de cópia anterior.
Criar uma execução de pipeline
Adicione o código a seguir, que dispara uma execução de pipeline, ao método Main.
// Create a pipeline run
Console.WriteLine("Creating pipeline run...");
Dictionary<string, object> arguments = new Dictionary<string, object>
{
{ "sourceBlobContainer", inputBlobPath },
{ "sinkBlobContainer", outputBlobPath },
{ "receiver", emailReceiver }
};
CreateRunResponse runResponse = client.Pipelines.CreateRunWithHttpMessagesAsync(resourceGroup, dataFactoryName, pipelineName, arguments).Result.Body;
Console.WriteLine("Pipeline run ID: " + runResponse.RunId);
Classe Main
O método Main final deve ter esta aparência.
// Authenticate and create a data factory management client
var context = new AuthenticationContext("https://login.windows.net/" + tenantID);
ClientCredential cc = new ClientCredential(applicationId, authenticationKey);
AuthenticationResult result = context.AcquireTokenAsync("https://management.azure.com/", cc).Result;
ServiceClientCredentials cred = new TokenCredentials(result.AccessToken);
var client = new DataFactoryManagementClient(cred) { SubscriptionId = subscriptionId };
Factory df = CreateOrUpdateDataFactory(client);
client.LinkedServices.CreateOrUpdate(resourceGroup, dataFactoryName, storageLinkedServiceName, StorageLinkedServiceDefinition(client));
client.Datasets.CreateOrUpdate(resourceGroup, dataFactoryName, blobSourceDatasetName, SourceBlobDatasetDefinition(client));
client.Datasets.CreateOrUpdate(resourceGroup, dataFactoryName, blobSinkDatasetName, SinkBlobDatasetDefinition(client));
client.Pipelines.CreateOrUpdate(resourceGroup, dataFactoryName, pipelineName, PipelineDefinition(client));
Console.WriteLine("Creating pipeline run...");
Dictionary<string, object> arguments = new Dictionary<string, object>
{
{ "sourceBlobContainer", inputBlobPath },
{ "sinkBlobContainer", outputBlobPath },
{ "receiver", emailReceiver }
};
CreateRunResponse runResponse = client.Pipelines.CreateRunWithHttpMessagesAsync(resourceGroup, dataFactoryName, pipelineName, arguments).Result.Body;
Console.WriteLine("Pipeline run ID: " + runResponse.RunId);
Compile e executar o programa para disparar uma execução de pipeline!
Monitorar uma execução de pipeline
Adicione o seguinte código ao método
Main:// Monitor the pipeline run Console.WriteLine("Checking pipeline run status..."); PipelineRun pipelineRun; while (true) { pipelineRun = client.PipelineRuns.Get(resourceGroup, dataFactoryName, runResponse.RunId); Console.WriteLine("Status: " + pipelineRun.Status); if (pipelineRun.Status == "InProgress") System.Threading.Thread.Sleep(15000); else break; }Esse código verifica continuamente o status da execução do pipeline até que ele termine de copiar os dados.
Adicione o código a seguir ao método
Mainpara recuperar os detalhes de execução da atividade de cópia, por exemplo, o tamanho dos dados lidos/gravados:// Check the copy activity run details Console.WriteLine("Checking copy activity run details..."); List<ActivityRun> activityRuns = client.ActivityRuns.ListByPipelineRun( resourceGroup, dataFactoryName, runResponse.RunId, DateTime.UtcNow.AddMinutes(-10), DateTime.UtcNow.AddMinutes(10)).ToList(); if (pipelineRun.Status == "Succeeded") { Console.WriteLine(activityRuns.First().Output); //SaveToJson(SafeJsonConvert.SerializeObject(activityRuns.First().Output, client.SerializationSettings), "ActivityRunResult.json", folderForJsons); } else Console.WriteLine(activityRuns.First().Error); Console.WriteLine("\nPress any key to exit..."); Console.ReadKey();
Executar o código
Compile e inicie o aplicativo, então verifique a execução do pipeline.
O aplicativo exibe o progresso de criação do Data Factory, do serviço vinculado, dos conjuntos de dados, do pipeline e da execução de pipeline. Em seguida, ele verifica o status da execução de pipeline. Aguarde até ver os detalhes de execução da atividade de cópia com o tamanho dos dados lidos/gravados. Em seguida, use ferramentas como o Gerenciador de Armazenamento do Azure para verificar se o blob foi copiado de inputBlobPath para outputBlobPath conforme você especificou nas variáveis.
A saída deve ser semelhante ao exemplo a seguir:
Creating data factory DFTutorialTest...
{
"location": "East US"
}
Creating linked service AzureStorageLinkedService...
{
"type": "AzureStorage",
"typeProperties": {
"connectionString": "DefaultEndpointsProtocol=https;AccountName=***;AccountKey=***"
}
}
Creating dataset SourceStorageDataset...
{
"type": "AzureBlob",
"typeProperties": {
"folderPath": {
"type": "Expression",
"value": "@pipeline().parameters.sourceBlobContainer"
},
"fileName": "input.txt"
},
"linkedServiceName": {
"type": "LinkedServiceReference",
"referenceName": "AzureStorageLinkedService"
}
}
Creating dataset SinkStorageDataset...
{
"type": "AzureBlob",
"typeProperties": {
"folderPath": {
"type": "Expression",
"value": "@pipeline().parameters.sinkBlobContainer"
}
},
"linkedServiceName": {
"type": "LinkedServiceReference",
"referenceName": "AzureStorageLinkedService"
}
}
Creating pipeline Adfv2TutorialBranchCopy...
{
"properties": {
"activities": [
{
"type": "Copy",
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "BlobSink"
}
},
"inputs": [
{
"type": "DatasetReference",
"referenceName": "SourceStorageDataset"
}
],
"outputs": [
{
"type": "DatasetReference",
"referenceName": "SinkStorageDataset"
}
],
"name": "CopyBlobtoBlob"
},
{
"type": "WebActivity",
"typeProperties": {
"method": "POST",
"url": "https://xxxx.eastus.logic.azure.com:443/workflows/... ",
"body": {
"message": "@{activity('CopyBlobtoBlob').output.dataWritten}",
"dataFactoryName": "@{pipeline().DataFactory}",
"pipelineName": "@{pipeline().Pipeline}",
"receiver": "@pipeline().parameters.receiver"
}
},
"name": "SendSuccessEmailActivity",
"dependsOn": [
{
"activity": "CopyBlobtoBlob",
"dependencyConditions": [
"Succeeded"
]
}
]
},
{
"type": "WebActivity",
"typeProperties": {
"method": "POST",
"url": "https://xxx.eastus.logic.azure.com:443/workflows/... ",
"body": {
"message": "@{activity('CopyBlobtoBlob').error.message}",
"dataFactoryName": "@{pipeline().DataFactory}",
"pipelineName": "@{pipeline().Pipeline}",
"receiver": "@pipeline().parameters.receiver"
}
},
"name": "SendFailEmailActivity",
"dependsOn": [
{
"activity": "CopyBlobtoBlob",
"dependencyConditions": [
"Failed"
]
}
]
}
],
"parameters": {
"sourceBlobContainer": {
"type": "String"
},
"sinkBlobContainer": {
"type": "String"
},
"receiver": {
"type": "String"
}
}
}
}
Creating pipeline run...
Pipeline run ID: 00000000-0000-0000-0000-0000000000000
Checking pipeline run status...
Status: InProgress
Status: InProgress
Status: Succeeded
Checking copy activity run details...
{
"dataRead": 20,
"dataWritten": 20,
"copyDuration": 4,
"throughput": 0.01,
"errors": [],
"effectiveIntegrationRuntime": "DefaultIntegrationRuntime (East US)"
}
{}
Press any key to exit...
Conteúdo relacionado
Neste tutorial, você executou as seguintes tarefas:
- Criar uma data factory
- Criar um serviço vinculado do Armazenamento do Azure
- Criar um conjunto de dados do Blob do Azure
- Criar um pipeline que contém uma atividade de cópia e uma atividade da Web
- Enviar saídas de atividades para as atividades subsequentes
- Usar passagem de parâmetros e variáveis do sistema
- Iniciar uma execução de pipeline
- Monitorar as execuções de pipeline e de atividade
Agora você pode seguir para a seção Conceitos para obter mais informações sobre o Azure Data Factory.