Exibir métricas de computação
Este artigo explica como usar a ferramenta de métricas de computação nativa na interface do usuário do Azure Databricks para coletar métricas-chave de hardware e do Spark. A interface do usuário de métricas está disponível para computação para todos os fins e para trabalhos.
Observação
A computação sem servidor para notebooks e trabalhos usa insights de consulta em vez da interface do usuário de métricas. Para obter mais informações sobre métricas de computação sem servidor, consulte Exibir insights de consulta.
As métricas estão disponíveis quase em tempo real com um atraso normal de menos de um minuto. As métricas são armazenadas no armazenamento gerenciado pelo Azure Databricks, não no armazenamento do cliente.
Como essas novas métricas são diferentes do Ganglia?
A nova IU de métricas de computação tem uma visão mais abrangente do uso de recursos do seu cluster, incluindo o consumo do Spark e processos internos do Databricks. Por outro lado, a IU do Ganglia mede apenas o consumo do contêiner Spark. Essa diferença pode resultar em discrepâncias nos valores métricos entre as duas interfaces.
Acessar a interface do usuário das métricas de computação
Para exibir a interface do usuário das métricas de computação:
- Clique em Computação na barra lateral.
- Clique no recurso de computação para o qual você deseja exibir as métricas.
- Clique na guia métricas.
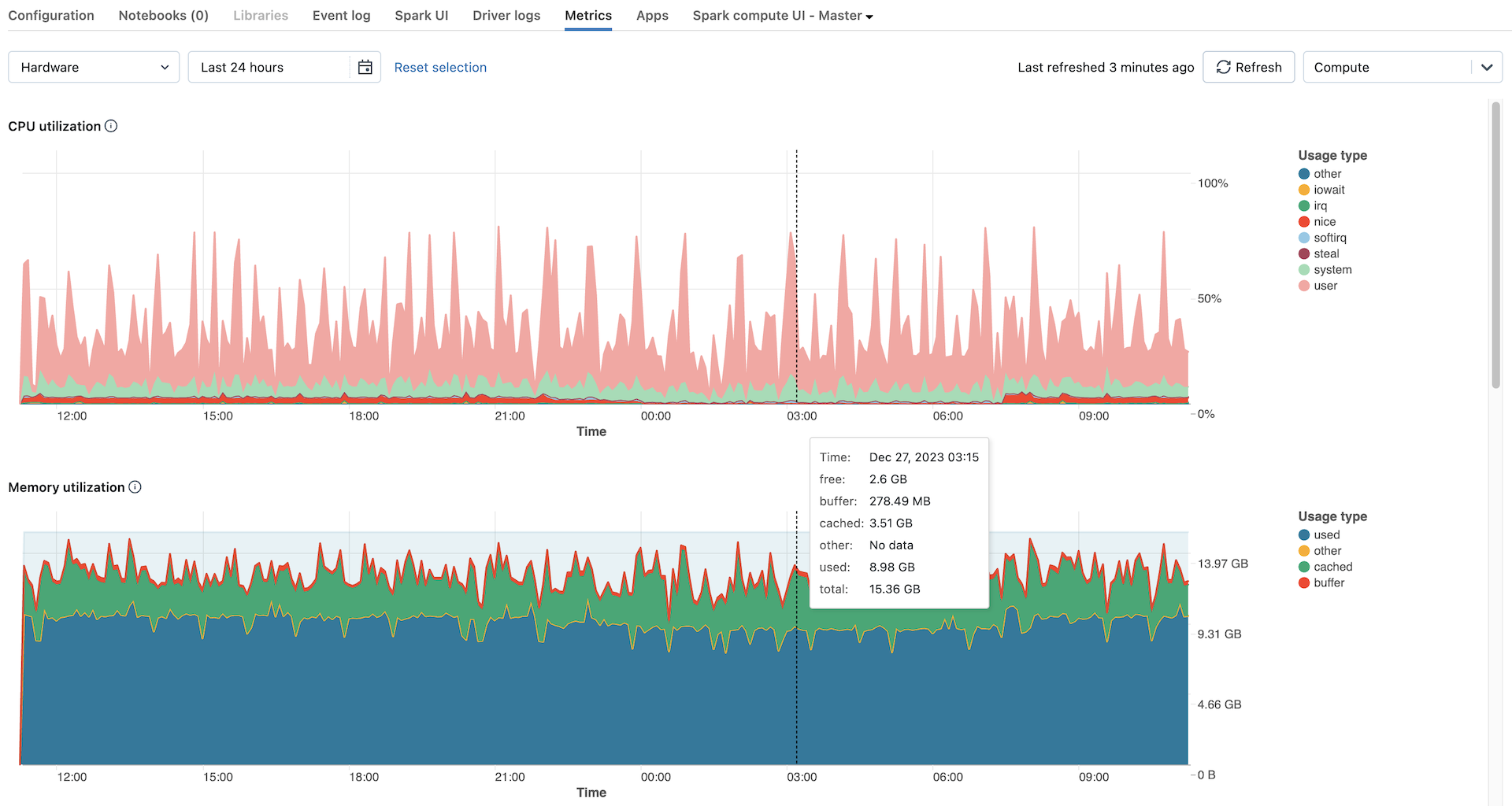
As métricas de hardware são mostradas por padrão. Para visualizar as métricas do Spark, clique no menu suspenso denominado Hardware e selecione Spark. Você também pode selecionar GPU se a instância estiver habilitada para GPU.
Filtrar métricas por período de tempo
Você pode exibir métricas históricas selecionando um intervalo de tempo usando o filtro seletor de data. As métricas são coletadas a cada minuto, para que você possa filtrar por qualquer intervalo de dia, hora ou minuto dos últimos 30 dias. Clique no ícone de calendário para selecionar entre intervalos de dados predefinidos ou clique dentro da caixa de texto para definir valores personalizados.
Observação
Os intervalos de tempo exibidos nos gráficos se ajustam com base no período de tempo que você está exibindo. A maioria das métricas são médias com base no intervalo de tempo que você está exibindo no momento.
Você também pode obter as métricas mais recentes clicando no botão Atualizar.
Exibir métricas no nível do nó
Você pode visualizar métricas de nós individuais clicando no menu suspenso Computação e selecionando o nó cujas métricas deseja visualizar. As métricas de GPU só estão disponíveis no nível de nó individual. As métricas do Spark não estão disponíveis para nós individuais.
Observação
Se você não selecionar um nó específico, será calculada a média do resultado de todos os nós de um cluster (incluindo o driver).
Gráficos de métricas de hardware
Os seguintes gráficos de métricas de hardware estão disponíveis para visualização na IU de métricas de computação:
- Distribuição de carga do servidor: esse gráfico mostra a utilização da CPU no último minuto para cada nó.
- Utilização da CPU: a porcentagem de tempo gasto pela CPU em cada modo, com base no custo total de segundos da CPU. A métrica é média com base em qualquer intervalo de tempo exibido no gráfico. A seguir estão os modos rastreados:
- convidado: se você estiver executando VMs, a CPU que essas VMs usam
- iowait: tempo gasto esperando por E/S
- idle: tempo em que a CPU não tem nada para fazer
- irq: tempo gasto em solicitações de interrupção
- nice: tempo utilizado por processos que possuem uma niceness positiva, significando uma prioridade menor do que outras tarefas.
- softirq: tempo gasto em solicitações de interrupção de software
- steal: se você for uma VM, o tempo que outras VMs "roubaram" de suas CPUs
- system (sistema): o tempo gasto no kernel
- user: o tempo gasto no espaço do usuário
- Utilização de memória: o uso total de memória por cada modo, medido em bytes e média com base em qualquer intervalo de tempo exibido no gráfico. Os seguintes tipos de uso são acompanhados:
- usada: memória usada (incluindo a memória usada por processos em segundo plano executados em uma computação)
- livre: memória não utilizada
- buffer: memória usada pelos buffers do kernel
- em cache: memória usada pelo cache do sistema de arquivos no nível do sistema operacional
- Utilização de troca de memória: o uso total de troca de memória por cada modo, medido em bytes e média com base em qualquer intervalo de tempo exibido no gráfico.
- Espaço livre do sistema de arquivos: o uso total do sistema de arquivos por cada ponto de montagem, medido em bytes e média com base em qualquer intervalo de tempo exibido no gráfico.
- Recebido por meio da rede: o número de bytes recebidos pela rede por cada dispositivo, em média com base em qualquer intervalo de tempo exibido no gráfico.
- Transmitido pela rede: o número de bytes transmitidos pela rede por cada dispositivo, em média com base em qualquer intervalo de tempo exibido no gráfico.
- Número de nós ativos: isso mostra o número de nós ativos em cada carimbo de data/hora para a computação fornecida.
Gráficos de métricas do Spark
Os seguintes gráficos de métricas do Spark estão disponíveis para exibição na interface do usuário das métricas de computação:
- Distribuição de carga do servidor: esse gráfico mostra a utilização da CPU no último minuto para cada nó.
- Tarefas ativas: o número total de tarefas em execução a qualquer momento, em média, com base em qualquer intervalo de tempo exibido no gráfico.
- Total de tarefas com falha: o número total de tarefas que falharam em executores, em média, com base em qualquer intervalo de tempo exibido no gráfico.
- Total de tarefas concluídas: o número total de tarefas concluídas em executores, com base em qualquer intervalo de tempo exibido no gráfico.
- Número total de tarefas: o número total de todas as tarefas (em execução, com falha e concluídas) em executores, com base em qualquer intervalo de tempo exibido no gráfico.
- Leitura aleatória total: o tamanho total de dados de leitura embaralhados, medidos em bytes e médias com base em qualquer intervalo de tempo exibido no gráfico.
Shuffle readsignifica a soma de dados de leitura serializados em todos os executores no início de um estágio. - Gravação de embaralhamento total: o tamanho total dos dados de gravação de embaralhamento, medidos em bytes e médios com base em qualquer intervalo de tempo exibido no gráfico.
Shuffle Writeé a soma de todos os dados serializados gravados em todos os executores antes de transmitir (normalmente no final de um estágio). - Duração total da tarefa: o tempo total decorrido que a JVM gastou executando tarefas em executores, medido em segundos e em média com base em qualquer intervalo de tempo exibido no gráfico.
Gráficos de métricas de GPU
Observação
As métricas de GPU só estão disponíveis no Databricks Runtime ML 13.3 e superior.
Os seguintes gráficos de métricas de GPU estão disponíveis para exibição na interface do usuário das métricas de computação:
- Distribuição de carga do servidor: esse gráfico mostra a utilização da CPU no último minuto para cada nó.
- Utilização do decodificador por GPU: o percentual de utilização do decodificador de GPU, com base em qualquer intervalo de tempo exibido no gráfico.
- Utilização do codificador por GPU: a porcentagem da utilização do codificador de GPU, média com base em qualquer intervalo de tempo exibido no gráfico.
- Bytes de utilização de memória de buffer por quadro de GPU: a utilização da memória do buffer de quadro, medida em bytes e média com base em qualquer intervalo de tempo exibido no gráfico.
- Utilização de memória por GPU: a porcentagem de utilização de memória de GPU, média com base em qualquer intervalo de tempo exibido no gráfico.
- Utilização por GPU: a porcentagem de utilização de GPU, média com base em qualquer intervalo de tempo exibido no gráfico.
Solução de problemas
Se você vir métricas incompletas ou ausentes por um período, pode ser um dos seguintes problemas:
- Uma interrupção no serviço do Databricks responsável por consultar e armazenar métricas.
- Problemas de rede no lado do cliente.
- A computação está ou estava em um estado não íntegro.