Recursos de extensão dos Pacotes de Ativos do Databricks
A extensão do Databricks para Visual Studio Code fornece recursos adicionais no Visual Studio Code que permitem definir, implantar e executar facilmente os Pacotes de Ativos do Databricks para aplicar as melhores práticas de CI/CD aos trabalhos do Azure Databricks, pipelines do Delta Live Tables e pilhas de MLOps. Veja que são pacotes de ativos do Databricks?.
Para instalar a extensão do Databricks para Visual Studio Code, consulte Instalar a extensão do Databricks para Visual Studio Code.
Suporte a pacotes de ativos do Databricks em projetos
A extensão do Databricks para Visual Studio Code adiciona os seguintes recursos para seus projetos de Pacotes de Ativos do Databricks:
- Fácil autenticação e configuração de seus pacotes de ativos do Databricks por meio da interface do usuário do Visual Studio Code, incluindo a seleção de perfil AuthType. Confira Configuração de autenticação da extensão do Databricks para Visual Studio Code.
- Um seletor de Destino no painel de extensão do Databricks para alternar rapidamente entre ambientes de destino de pacote. Consulte Alterar o espaço de trabalho de implantação de destino.
- A opção Substituir Trabalhos de Cluster no Pacote no painel de extensão para permitir a substituição fácil do cluster.
- Uma exibição do Gerenciador de Recursos de Pacotes, que permite que você navegue pelos recursos do pacote usando a interface do usuário do Visual Studio Code, implante os recursos do Pacote de Ativos do Databricks local no espaço de trabalho remoto do Azure Databricks com um único clique e vá diretamente para os recursos implantados no espaço de trabalho do Visual Studio Code. Consulte Gerenciador de Recursos de Pacote.
- Uma Exibição de Variáveis de Pacotes, que permite que você navegue e edite suas variáveis de pacote usando a interface do usuário do Visual Studio Code. Consulte Exibição de Variáveis de Pacote.
Gerenciador de Recursos de Pacote
A exibição do Gerenciador de Recursos de Pacote na extensão do Databricks para Visual Studio Code usa as definições de trabalho e pipeline na configuração do pacote do projeto para exibir recursos. Também permite que você implante e execute recursos e navegue até eles em seu espaço de trabalho remoto do Azure Databricks. Para obter informações sobre recursos de configuração de pacote, consulte recursos.
Por exemplo, dada uma definição de trabalho simples:
resources:
jobs:
my-notebook-job:
name: "My Notebook Job"
tasks:
- task_key: notebook-task
existing_cluster_id: 1234-567890-abcde123
notebook_task:
notebook_path: notebooks/my-notebook.py
A exibição do Gerenciador de Recursos de Pacote na extensão exibe o recurso de trabalho do notebook:
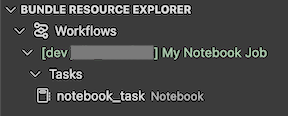
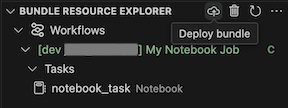
Para implantar o pacote, clique no ícone de nuvem (Implantar pacote).
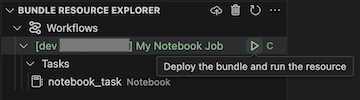
Para executar o trabalho, no modo de exibição Gerenciador de Recursos de Pacote, selecione o nome do trabalho, que é Meu Trabalho de Bloco de Anotações neste exemplo. Em seguida, clique no ícone reproduzir (Implantar o pacote e executar o recurso).
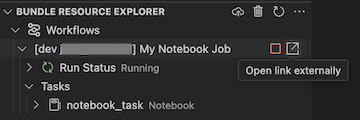
Para exibir o trabalho em execução, no modo de exibição Gerenciador de Recursos de Pacote, expanda o nome do trabalho, clique em Status da Execução e, em seguida, clique no ícone de link (Abrir link externamente).
Exibição de variáveis de pacote
A Exibição de Variáveis de Pacote na extensão do Databricks para Visual Studio Code exibe todas as variáveis personalizadas e configurações associadas definidas na configuração do pacote. Você também pode definir variáveis diretamente usando a Exibição de Variáveis de Pacotes. Esses valores substituem os definidos nos arquivos de configuração do pacote. Para obter informações sobre variáveis personalizadas, consulte Variáveis personalizadas.
Por exemplo, a Exibição de Variáveis de Pacote na extensão exibiria o seguinte:

Para a variável my_custom_var definida nesta configuração de pacote:
variables:
my_custom_var:
description: "Max workers"
default: "4"
resources:
jobs:
my_job:
name: my_job
tasks:
- task_key: notebook_task
job_cluster_key: job_cluster
notebook_task:
notebook_path: ../src/notebook.ipynb
job_clusters:
- job_cluster_key: job_cluster
new_cluster:
spark_version: 13.3.x-scala2.12
node_type_id: i3.xlarge
autoscale:
min_workers: 1
max_workers: ${var.my_custom_var}