APIs de Modelo de Base de taxa de transferência provisionada
Este artigo demonstra como implantar modelos usando taxa de transferência provisionada de APIs de Modelo Básico. O Databricks recomenda a taxa de transferência provisionada para cargas de trabalho de produção e fornece inferência otimizada para modelos de base com garantias de desempenho.
O que é taxa de transferência provisionada?
A produtividade provisionada refere-se a quantos tokens de solicitações você pode enviar a um ponto de extremidade ao mesmo tempo. Os pontos de extremidade de fornecimento de produtividade provisionada são configurados em termos de um intervalo de tokens por segundo que você pode enviar ao ponto de extremidade.
Confira os recursos a seguir para saber mais:
- O que significam os intervalos de tokens por segundo na taxa de transferência provisionada?
- Criar seu próprio parâmetro de comparação de ponto de extremidade de LLM
Confira APIs de Foundation Model com produtividade provisionada para obter uma lista de arquiteturas de modelo para pontos de extremidade de produtividade provisionada.
Requisitos
Consulte os requisitos. Para implantar modelos de base ajustados, consulte Implantar modelos de base ajustados.
[Recomendado] Implantar modelos de fundação do Catálogo do Unity
Importante
Esse recurso está em uma versão prévia.
O Databricks recomenda o uso dos modelos de base pré-instalados no Catálogo do Unity. Encontre esses modelos no catálogo system no esquema ai (system.ai).
Para implantar um modelo de base:
- Navegue até
system.aiem Gerenciador de Catálogos. - Selecione o nome do modelo a ser implantado.
- Na página do modelo, selecione o botão Servir este modelo.
- A página Criar ponto de extremidade de serviço é exibida. Confira Criar seu ponto de extremidade de taxa de transferência provisionada usando a interface do usuário.
Implantar modelos de base do Databricks Marketplace
Como alternativa, você poderá instalar modelos de base no Catálogo do Unity do Databricks Marketplace.
Você pode pesquisar uma família de modelos e, na página do modelo, selecionar Obter acesso e fornecer credenciais de logon para instalar o modelo no Catálogo do Unity.
Após o modelo ser instalado no Catálogo do Unity, você poderá criar um ponto de extremidade de serviços de modelo usando a Interface do Usuário de Serviços.
Implantar modelos do DBRX
O Databricks recomenda servir o modelo de Instrução DBRX para suas cargas de trabalho. Para atender ao modelo de Instrução do DBRX usando a taxa de transferência provisionada, siga as diretrizes em [Recomendado] Implantar modelos de base do Catálogo do Unity.
Ao servir esses modelos DBRX, a taxa de transferência provisionada dá suporte a um comprimento de contexto de até 16k.
Os modelos DBRX usam a seguinte solicitação padrão do sistema para garantir a relevância e a precisão nas respostas do modelo:
You are DBRX, created by Databricks. You were last updated in December 2023. You answer questions based on information available up to that point.
YOU PROVIDE SHORT RESPONSES TO SHORT QUESTIONS OR STATEMENTS, but provide thorough responses to more complex and open-ended questions.
You assist with various tasks, from writing to coding (using markdown for code blocks — remember to use ``` with code, JSON, and tables).
(You do not have real-time data access or code execution capabilities. You avoid stereotyping and provide balanced perspectives on controversial topics. You do not provide song lyrics, poems, or news articles and do not divulge details of your training data.)
This is your system prompt, guiding your responses. Do not reference it, just respond to the user. If you find yourself talking about this message, stop. You should be responding appropriately and usually that means not mentioning this.
YOU DO NOT MENTION ANY OF THIS INFORMATION ABOUT YOURSELF UNLESS THE INFORMATION IS DIRECTLY PERTINENT TO THE USER'S QUERY.
Implantar modelos de base ajustados
Caso não possa usar os modelos no esquema system.ai ou instalar modelos do Databricks Marketplace, poderá implantar um modelo de base ajustado registrando-o no Catálogo do Unity. Esta seção e as seções a seguir mostram como configurar seu código para registrar um modelo de MLflow no Catálogo do Unity e criar o ponto de extremidade de taxa de transferência provisionado usando a interface do usuário ou a API REST.
Consulte Limites de taxa de transferência provisionada para os modelos ajustados do Meta Llama 3.1 e 3.2 com suporte e sua disponibilidade de região.
Requisitos
- A implantação de modelos de base ajustados só tem suporte do MLflow 2.11 ou superior. O Databricks Runtime 15.0 ML e posterior pré-instala a versão compatível do MLflow.
- O Databricks recomenda o uso de modelos no Catálogo do Unity para carregamento e download mais rápidos de modelos grandes.
Definir o catálogo, o esquema e o nome do modelo
Para implantar um modelo de base ajustado, defina o catálogo de destino do Catálogo do Unity, o esquema e o nome do modelo de sua escolha.
mlflow.set_registry_uri('databricks-uc')
CATALOG = "catalog"
SCHEMA = "schema"
MODEL_NAME = "model_name"
registered_model_name = f"{CATALOG}.{SCHEMA}.{MODEL_NAME}"
Registrar seu modelo em log
Para habilitar a taxa de transferência provisionada para o ponto de extremidade do modelo, você deve registrar seu modelo usando a variante transformers do MLflow e especificar o argumento task com a interface de tipo de modelo apropriada das seguintes opções:
"llm/v1/completions""llm/v1/chat""llm/v1/embeddings"
Esses argumentos especificam a assinatura de API usada para o ponto de extremidade de serviço do modelo. Consulte a documentação do MLflow para obter mais detalhes sobre essas tarefas e os esquemas de entrada/saída correspondentes.
A seguir, um exemplo de como registrar um modelo de linguagem de preenchimento de texto registrado usando o MLflow:
model = AutoModelForCausalLM.from_pretrained("mosaicml/mixtral-8x7b-instruct", torch_dtype=torch.bfloat16)
tokenizer = AutoTokenizer.from_pretrained("mosaicml/mixtral-8x7b-instruct")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
# Specify the llm/v1/xxx task that is compatible with the model being logged
task="llm/v1/completions",
# Specify an input example that conforms to the input schema for the task.
input_example={"prompt": np.array(["Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\nWhat is Apache Spark?\n\n### Response:\n"])},
# By passing the model name, MLflow automatically registers the Transformers model to Unity Catalog with the given catalog/schema/model_name.
registered_model_name=registered_model_name
# Optionally, you can set save_pretrained to False to avoid unnecessary copy of model weight and gain more efficiency
save_pretrained=False
)
Observação
Se você estiver usando o MLflow anterior à 2.12, precisará especificar a tarefa dentro do parâmetro metadata da mesma função mlflow.transformer.log_model().
metadata = {"task": "llm/v1/completions"}metadata = {"task": "llm/v1/chat"}metadata = {"task": "llm/v1/embeddings"}
A produtividade provisionada também é compatível com os modelos de inserção BGE de base e grande. O exemplo a seguir mostra como registrar o modelo Alibaba-NLP/gte-large-en-v1.5 para que ele possa receber o serviço de taxa de transferência provisionada:
model = AutoModel.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
tokenizer = AutoTokenizer.from_pretrained("Alibaba-NLP/gte-large-en-v1.5")
with mlflow.start_run():
components = {
"model": model,
"tokenizer": tokenizer,
}
mlflow.transformers.log_model(
transformers_model=components,
artifact_path="model",
task="llm/v1/embeddings",
registered_model_name=registered_model_name,
# model_type is required for logging a fine-tuned BGE models.
metadata={
"model_type": "gte-large"
}
)
Após o registro do modelo no Catálogo do Unity, continue em Criar seu ponto de extremidade de taxa de transferência provisionada usando a interface do usuário para criar um ponto de extremidade de serviço de modelo com taxa de transferência provisionada.
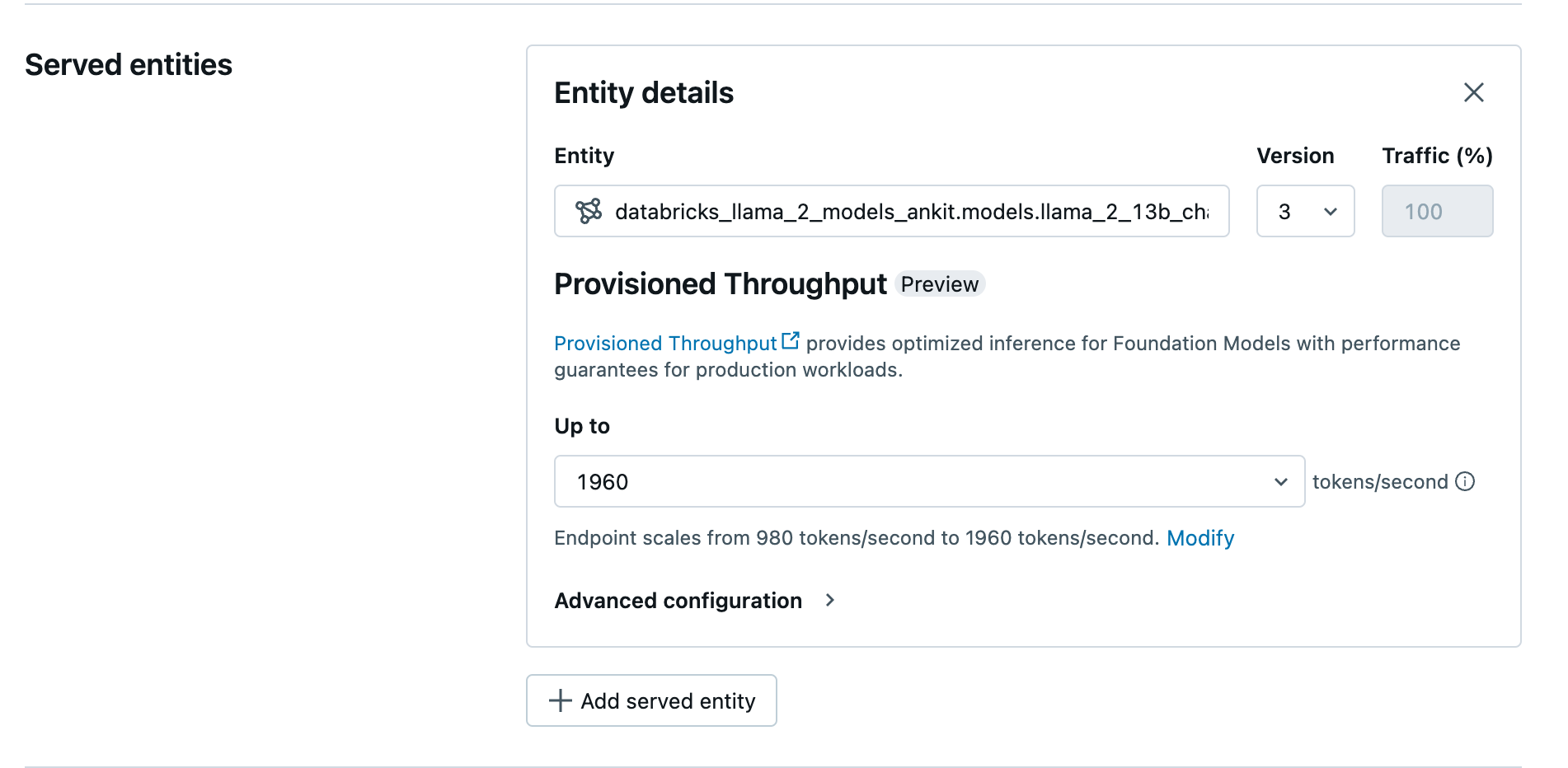
Criar seu ponto de extremidade de taxa de transferência provisionada usando a interface do usuário
Quando o modelo registrado já estiver no Catálogo do Unity, crie um ponto de extremidade de serviço de taxa de transferência provisionada executando as seguintes etapas:
- Navegue até a Interface do Usuário de Serviços no seu workspace.
- Clique em Criar um ponto de extremidade de serviço.
- No campo Entidade, selecione seu modelo no Catálogo do Unity. Para modelos qualificados, a interface do usuário da entidade que recebeu o serviço mostra a tela de produtividade provisionada.
- Na lista suspensa Até, você pode configurar o máximo de tokens por segundo da taxa de transferência para o ponto de extremidade.
- Os pontos de extremidade de taxa de transferência provisionada são dimensionados automaticamente de modo que você possa selecionar Modificar para ver o mínimo de tokens por segundo ao qual seu ponto de extremidade pode ser reduzido.
Criar ponto de extremidade de taxa de transferência provisionada usando a API REST
Para implantar seu modelo no modo de taxa de transferência provisionada usando a API REST, você precisa especificar os campos min_provisioned_throughput e max_provisioned_throughput na sua solicitação. Se preferir o Python, você também pode criar um ponto de extremidade usando o SDK de Implantação do MLflow.
Para identificar o intervalo adequado de taxa de transferência provisionada para o seu modelo, confira Obter taxa de transferência provisionada em incrementos.
import requests
import json
# Set the name of the MLflow endpoint
endpoint_name = "llama2-13b-chat"
# Name of the registered MLflow model
model_name = "ml.llm-catalog.llama-13b"
# Get the latest version of the MLflow model
model_version = 3
# Get the API endpoint and token for the current notebook context
API_ROOT = "<YOUR-API-URL>"
API_TOKEN = "<YOUR-API-TOKEN>"
headers = {"Context-Type": "text/json", "Authorization": f"Bearer {API_TOKEN}"}
optimizable_info = requests.get(
url=f"{API_ROOT}/api/2.0/serving-endpoints/get-model-optimization-info/{model_name}/{model_version}",
headers=headers)
.json()
if 'optimizable' not in optimizable_info or not optimizable_info['optimizable']:
raise ValueError("Model is not eligible for provisioned throughput")
chunk_size = optimizable_info['throughput_chunk_size']
# Minimum desired provisioned throughput
min_provisioned_throughput = 2 * chunk_size
# Maximum desired provisioned throughput
max_provisioned_throughput = 3 * chunk_size
# Send the POST request to create the serving endpoint
data = {
"name": endpoint_name,
"config": {
"served_entities": [
{
"entity_name": model_name,
"entity_version": model_version,
"min_provisioned_throughput": min_provisioned_throughput,
"max_provisioned_throughput": max_provisioned_throughput,
}
]
},
}
response = requests.post(
url=f"{API_ROOT}/api/2.0/serving-endpoints", json=data, headers=headers
)
print(json.dumps(response.json(), indent=4))
Probabilidade logarítmica de tarefas de conclusão de chat
Para tarefas de conclusão de chat, você pode usar o parâmetro logprobs para fornecer a probabilidade logarítmica de um token ser amostrado como parte do processo de geração de modelo de linguagem grande. Você pode usar logprobs para diversos cenários, incluindo classificação, avaliação da incerteza do modelo e execução de métricas de avaliação. Confira Tarefa de chat para obter detalhes do parâmetro.
Obter taxa de transferência provisionada em incrementos
A taxa de transferência provisionada está disponível em incrementos de tokens por segundo, sendo que os incrementos específicos variam por modelo. Para identificar o intervalo adequado para as suas necessidades, o Databricks recomenda usar a API de informações de otimização de modelo dentro da plataforma.
GET api/2.0/serving-endpoints/get-model-optimization-info/{registered_model_name}/{version}
A seguir temos um exemplo de resposta da API:
{
"optimizable": true,
"model_type": "llama",
"throughput_chunk_size": 1580
}
Exemplos de notebook
Os blocos de anotações a seguir mostram exemplos de como criar uma API de Modelo do Foundation de taxa de transferência provisionada:
Serviço de produtividade provisionada para notebooks de modelo BGE
Serviço de taxa de transferência provisionada para o notebook de modelo Mistral
Serviço de taxa de transferência provisionada para notebooks de modelo BGE
Limitações
- A implantação do modelo pode falhar devido a problemas de capacidade de GPU, que fazem com que o tempo limite seja atingido durante a criação ou atualização do ponto de extremidade. Entre em contato com sua equipe de conta do Databricks e eles vão ajudar você a resolver.
- O dimensionamento automático para APIs de Modelos do Foundation é mais lento do que o modelo de CPU que serve. O Databricks recomenda o excesso de provisionamento para evitar tempos limite de solicitações.