Desenvolver código em notebooks do Databricks
Esta página descreve como desenvolver um código nos notebooks do Databricks, incluindo preenchimento automático, formatação automática para Python e SQL, combinação do Python e SQL em um notebook e controle do histórico de versões do notebook.
Para obter mais detalhes sobre a funcionalidade avançada disponível com o editor, como preenchimento automático, seleção de variável, suporte a vários cursores e diferenças lado a lado, consulte Usar o notebook e o editor de arquivos do Databricks.
Quando você usa o notebook ou o editor de arquivos, o Assistente do Databricks está disponível para ajudar a gerar, explicar e depurar código. Confira Usar o Assistente do Databricks para obter mais informações.
Os notebooks do Databricks também incluem um depurador interativo interno para notebooks Python. Consulte Depurar notebooks.
Obter ajuda para codificar do Assistente do Databricks
O Assistente do Databricks é um assistente de IA com reconhecimento de contexto com o qual você pode interagir usando uma interface para conversar, o que torna você mais produtivo dentro do Databricks. Você pode descrever sua tarefa em inglês e deixar que o assistente gere código em Python ou consultas SQL, explique códigos complexos e corrija erros automaticamente. O assistente usa metadados do Catálogo do Unity para entender suas tabelas, colunas, descrições e os ativos de dados mais populares em toda a sua empresa e fornecer respostas personalizadas.
O Assistente do Databricks pode ajudar você nas seguintes tarefas:
- Gerar código.
- Depurar código, incluindo identificação de erros e sugestão de correções.
- Transformar e otimizar código.
- Explicar o código.
- Ajudar você a encontrar informações relevantes na documentação do Azure Databricks.
Para obter informações sobre como usar o Assistente do Databricks para ajudar você a codificar com mais eficiência, confira Usar o Assistente do Databricks. Para obter informações de caráter geral sobre o assistente do Databricks, confira Recursos alimentados pelo DatabricksIQ.
Acessar o notebook para edição
Para abrir um notebook, use a função Pesquisar do workspace ou use o navegador do workspace para navegar até o notebook e clique no nome ou ícone do notebook.
Procurar dados
Use o navegador de esquema para explorar os objetos do Catálogo do Unity disponíveis para o notebook. Clique no ![]() no lado esquerdo do notebook para abrir o navegador de esquema.
no lado esquerdo do notebook para abrir o navegador de esquema.
O botão Para você exibe apenas os objetos que você usou na sessão atual ou que marcou anteriormente como Favoritos.
À medida que você digita o texto na caixa Filtro, a exibição será alterada para mostrar apenas os objetos que contêm o texto digitado. Serão exibidos apenas os objetos que estão abertos no momento ou que foram abertos na sessão atual. A caixa Filtro não faz uma pesquisa completa dos catálogos, esquemas, tabelas e volumes disponíveis para o notebook.
Para abrir o menu kebab ![]() , passe o cursor sobre o nome do objeto, conforme mostrado:
, passe o cursor sobre o nome do objeto, conforme mostrado:
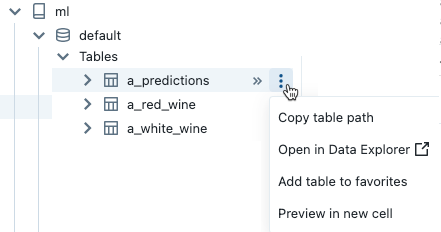
Se o objeto for uma tabela, você poderá fazer o seguinte:
- Crie e execute automaticamente uma célula para exibir uma pré-visualização dos dados na tabela. Selecione Pré-visualização em uma nova célula no menu kebab da tabela.
- Visualize um catálogo, um esquema ou uma tabela no Explorador do Catálogo. Selecione Abrir no Explorador do Catálogo no menu de kebab. Uma nova guia será aberta mostrando o objeto selecionado.
- Obtenha o caminho para um catálogo, esquema ou tabela. Selecione Copiar ... caminho no menu kebab do objeto.
- Adicione uma tabela aos Favoritos. Selecione Adicionar aos favoritos no menu kebab da tabela.
Se o objeto for um catálogo, esquema ou volume, você poderá copiar o caminho do objeto ou abri-lo no Explorador do Catálogo.
Para inserir um nome de tabela ou coluna diretamente em uma célula:
- Clique com o cursor na célula no local em que deseja inserir o nome.
- Mova o cursor sobre o nome da tabela ou da coluna no navegador de esquema.
- Clique na seta dupla
 que aparece à direita do nome do objeto.
que aparece à direita do nome do objeto.
Atalhos do teclado
Para exibir atalhos de teclado, selecione Ajuda > Atalhos de teclado. Os atalhos de teclado disponíveis dependem se o cursor está em uma célula de código (modo de edição) ou não (modo de comando).
Paleta de comandos
Você pode executar ações rapidamente no notebook usando a paleta de comandos. Para abrir um painel de ações do notebook, clique em  no canto inferior direito do workspace ou use o atalho Cmd + Shift + P no MacOS ou Ctrl + Shift + P no Windows.
no canto inferior direito do workspace ou use o atalho Cmd + Shift + P no MacOS ou Ctrl + Shift + P no Windows.
Localizar e substituir texto
Para encontrar e substituir textos em um notebook, selecione Editar > Localizar e Substituir. A correspondência atual é realçada em laranja e todas as outras correspondências são realçadas em amarelo.
Para substituir a correspondência atual, clique em Substituir. Para substituir todas as correspondências no notebook, clique em Substituir Tudo.
Para alternar entre as correspondências, clique nos botões Prev e Next. Você também pode pressionar SHIFT+ENTER e ENTER para ir às correspondências anteriores e seguintes, respectivamente.
Para fechar a ferramenta localizar e substituir, clique no ![]() ou pressione ESC.
ou pressione ESC.
Executar células selecionadas
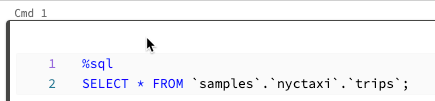
Você pode executar uma única célula ou uma coleção de células. Para selecionar uma única célula, clique em qualquer lugar da célula. Para selecionar várias células, mantenha pressionada a tecla Command no MacOS ou a tecla Ctrl no Windows e clique na célula fora da área de texto, conforme mostrado na captura de tela.
Para executar o comando selecionado O comportamento desse comando depende do cluster ao qual o notebook está conectado.
- Em um cluster executando o Databricks Runtime 13.3 LTS ou inferior, as células selecionadas são executadas individualmente. Se ocorrer um erro em uma célula, a execução continuará com as células subsequentes.
- Em um cluster executando o Databricks Runtime 14.0 ou superior, ou em um SQL warehouse, as células selecionadas são executadas como um lote. Qualquer erro interrompe a execução e você não pode cancelar a execução de células individuais. Você pode usar o botão Interromper para interromper a execução de todas as células.
Modularizar seu código
Importante
Esse recurso está em uma versão prévia.
Com o Databricks Runtime 11.3 LTS e superior, você pode criar e gerenciar arquivos de código-fonte no espaço de trabalho do Azure Databricks e, em seguida, importar esses arquivos para seus notebooks conforme necessário.
Para obter mais informações sobre como trabalhar com arquivos de código-fonte, consulte Compartilhar código entre notebooks do Databricks e Trabalhar com módulos Python e R.
Executar o texto selecionado
Você pode realçar código ou instruções SQL em uma célula do notebook e executar somente essa seleção. Isso é útil quando você deseja iterar rapidamente no código e em consultas.
Realce as linhas que você quer executar.
Selecione Executar > Executar texto selecionado ou use o atalho de teclado
Ctrl+Shift+Enter. Se nenhum texto estiver realçado, Executar Texto Selecionado executará a linha atual.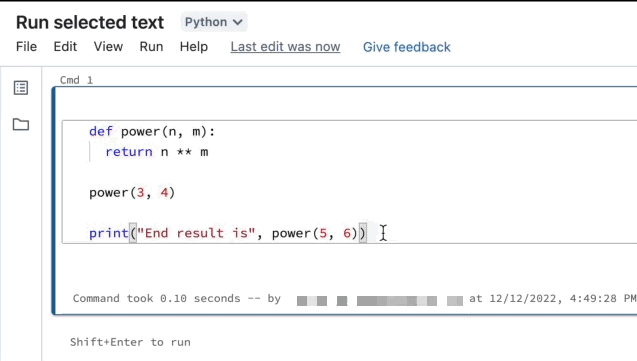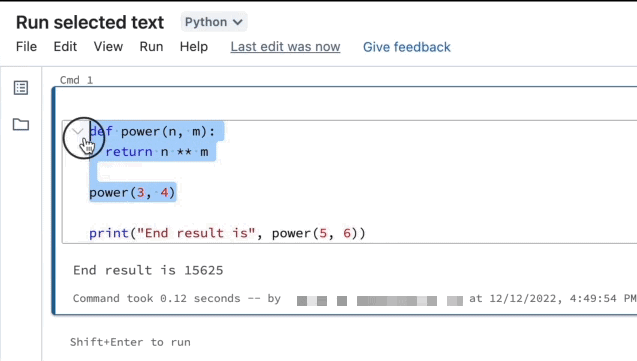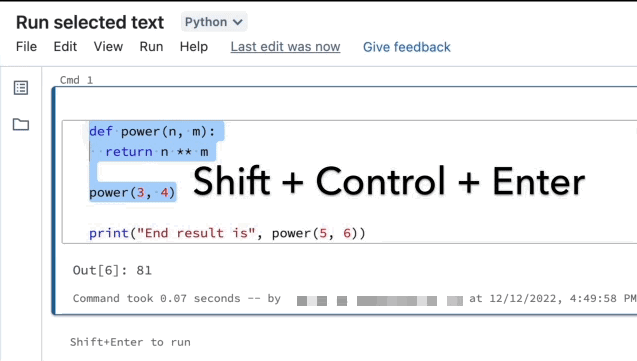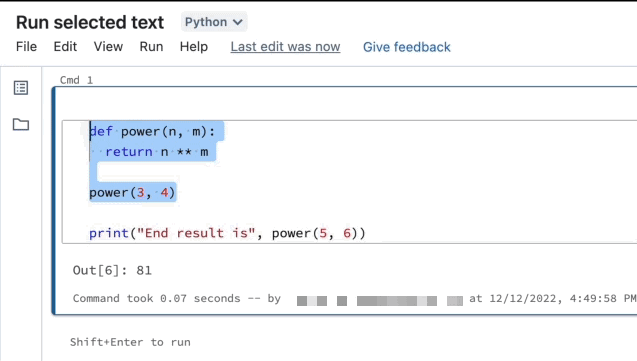
Se você estiver usando idiomas mistos em uma célula, deverá incluir a linha %<language> na seleção.
Executar o texto selecionado também executará o código recolhido, se houver algum na seleção realçada.
Há suporte para comandos de célula especiais, como %run, %pip e %sh.
Não é possível usar Executar texto selecionado em células que tenham várias guias de saída (ou seja, células em que você definiu um perfil de dados ou visualização).
Formatar células de código
O Azure Databricks fornece ferramentas que permitem formatar código SQL e Python em células do notebook de maneira rápida e fácil. Essas ferramentas reduzem o esforço para manter seu código formatado e ajudam a impor os mesmos padrões de codificação em seus notebooks.
Biblioteca formatadora Black do Python
Importante
Esse recurso está em uma versão prévia.
O Azure Databricks dá suporte à formatação de código Python usando a black no notebook. O notebook deve ser anexado a um cluster com os pacotes Python black e tokenize-rt instalados.
No Databricks Runtime 11.3 LTS e superior, o Azure Databricks pré-instala black e tokenize-rt. Você pode usar o formatador diretamente, sem a necessidade de instalar essas bibliotecas.
No Databricks Runtime 10.4 LTS e abaixo, você deve instalar black==22.3.0 e tokenize-rt==4.2.1 do PyPI em seu notebook ou cluster para usar o formatador Python. Execute o comando a seguir no seu notebook:
%pip install black==22.3.0 tokenize-rt==4.2.1
ou instale a biblioteca em seu cluster.
Para saber mais detalhes sobre como instalar bibliotecas, confira Gerenciamento de ambiente do Python.
Quanto aos arquivos e notebooks nas pastas Git do Databricks, você pode configurar o formatador Python com base no arquivo pyproject.toml. Para usar esse recurso, crie um arquivo pyproject.toml no diretório raiz da pasta Git e configure-o de acordo com o Formato de configuração Black. Edite a seção [tool.black] no arquivo. A configuração é aplicada quando você formata qualquer arquivo e bloco de anotações nessa pasta Git.
Como formatar células Python e SQL
Você precisa ter a permissão CAN EDIT no notebook para formatar código.
O Azure Databricks usa a biblioteca Gethue/sql-formatter para formatar o SQL e o formatador de código black para Python.
Você pode disparar o formatador das seguintes maneiras:
Formatar uma única célula
- Atalho de teclado: pressione CMD+SHIFT+F.
- Menu de contexto de comando:
- Formatar célula SQL: selecione Formatar SQL no menu suspenso de contexto de comando de uma célula SQL. Esse item de menu fica visível apenas nas células do bloco de notas SQL ou naquelas com
%sqllinguagem magic. - Formatar célula Python: selecione Formatar Python no menu suspenso de contexto de comando de uma célula Python. Este item de menu é visível apenas em células de notebook Python ou naquelas com uma
%pythonlinguagem magic.
- Formatar célula SQL: selecione Formatar SQL no menu suspenso de contexto de comando de uma célula SQL. Esse item de menu fica visível apenas nas células do bloco de notas SQL ou naquelas com
- Menu Editar do notebook: selecione uma célula Python ou SQL e, em seguida, selecione Editar > Formatar Célula(s).
Formatar várias células
Selecione várias células e, em seguida, selecione Editar > Formatar Células. Se você selecionar células de mais de uma linguagem, somente células SQL e Python serão formatadas. Isso inclui aquelas que usam
%sqle%python.Formatar todas as células Python e SQL no notebook
Selecione Editar > Formatar Notebook. Se o notebook contiver células de mais de uma linguagem, somente células SQL e Python serão formatadas. Isso inclui aquelas que usam
%sqle%python.
Limitações da formatação de código
- Black impõe padrões PEP 8 para recuo de 4 espaços. O recuo não é configurável.
- Não há suporte para formatação de cadeias de caracteres do Python inseridas em um UDF do SQL. Da mesma forma, não há suporte para formatação de cadeias de caracteres SQL dentro de uma UDF do Python.
Histórico de versões
Os notebooks do Azure Databricks mantêm um histórico de versões do notebook, permitindo que você exiba e restaure instantâneos anteriores do notebook. Você pode executar as seguintes ações nas versões: adicionar comentários, restaurar e excluir versões e limpar o histórico de versões.
Você também pode sincronizar seu trabalho no Databricks com um repositório Git remoto.
Para acessar as versões do notebook, clique no  na barra lateral direita. Aparece o histórico de versões do notebook. Você também pode selecionar Arquivo > Histórico de versão.
na barra lateral direita. Aparece o histórico de versões do notebook. Você também pode selecionar Arquivo > Histórico de versão.
Adicionar um comentário
Para adicionar um comentário à versão mais recente:
Clique na versão.
Clique em Salvar agora.
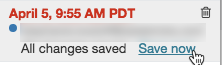
Na caixa de diálogo Salvar Versão do Notebook, insira um comentário.
Clique em Save (Salvar). A versão do notebook é salva com o comentário inserido.
Restaurar uma versão
Para restaurar uma versão:
Clique na versão.
Clique em Restaurar esta versão.
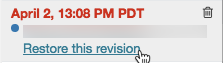
Clique em Confirmar. A versão selecionada se torna a versão mais recente do notebook.
Excluir uma versão
Para excluir uma entrada de versão:
Clique na versão.
Clique no ícone
 .
.
Clique em Sim, apagar. A versão selecionada é excluída do histórico.
Limpar histórico de versões
O histórico de versões não pode ser recuperado depois de limpo.
Para limpar o histórico de versões de um notebook:
- Selecione Arquivo >Limpar histórico de versões.
- Clique em Sim, limpar. O histórico de vesões do notebook foi limpo.
Idiomas de código em notebooks
Definir como idioma padrão
O idioma padrão do notebook aparece ao lado do nome do notebook.

Para alterar o idioma padrão, clique no botão de idioma e selecione o novo idioma no menu suspenso. Para garantir o funcionamento dos comandos existentes, os comandos do idioma padrão anterior são prefixados automaticamente com um comando magic de idioma.
Misturar idiomas
Por padrão, as células usam o idioma padrão do notebook. Você pode substituir o idioma padrão em uma célula clicando no botão de idioma e selecionando um idioma no menu suspenso.
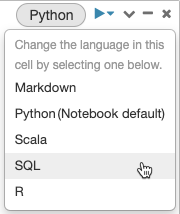
Como alternativa, é possível usar o comando magic de idioma %<language> no inicio de uma célula. Os comandos magic com suporte são: %python, %r, %scala e %sql.
Observação
Quando você invoca um comando magic de linguagem, o comando é expedido para o REPL no contexto de execução do notebook. As variáveis definidas em um idioma (e, portanto, no REPL para esse idioma) não estão disponíveis no REPL de outro idioma. As REPLs podem compartilhar status somente por meio de recursos externos, como arquivos em DBFS ou objetos no armazenamento de objetos.
Os notebooks também dão suporte a alguns comandos magic auxiliares:
%sh: permite que você execute o código do shell em seu notebook. Para falhar a célula se o comando shell tiver um status de saída diferente de zero, adicione a opção-e. Esse comando é executado somente no driver do Apache Spark e não nos trabalhadores. Para executar um comando shell em todos os nós use um script de inicialização.%fs: permite que você use comandosdbutilsdo sistema de arquivos. Por exemplo, para executar o comandodbutils.fs.lspara listar arquivos, você pode especificar%fs lsem vez disso. Para obter mais informações, confira Trabalhar com arquivos no Azure Databricks.%md: permite que você inclua vários tipos de documentação, incluindo texto, imagens, fórmulas e equações matemáticas. Veja a próxima seção.
Realce de sintaxe do SQL e preenchimento automático em comandos do Python
O realce de sintaxe e o preenchimento automático do SQL ficam disponíveis quando você usa o SQL em um comando do Python, como em um comando spark.sql.
Explorar os resultados da célula SQL
Em um notebook do Databricks, os resultados de uma célula de linguagem SQL são disponibilizados automaticamente como um DataFrame implícito atribuído à variável _sqldf. Em seguida, você pode usar essa variável em qualquer célula Python e SQL executada posteriormente, independentemente de sua posição no notebook.
Observação
Este recurso tem as seguintes limitações:
- A
_sqldfvariável não está disponível em notebooks que usam um SQL warehouse para computação. - O uso
_sqldfem células subsequentes do Python tem suporte no Databricks Runtime 13.3 e superior. - O uso
_sqldfem células SQL subsequentes só tem suporte no Databricks Runtime 14.3 e superior. - Se a consulta usar as palavras-chave
CACHE TABLEouUNCACHE TABLE, a_sqldfvariável não estará disponível.
A captura de tela abaixo mostra como _sqldf pode ser usado em células Python e SQL subsequentes:
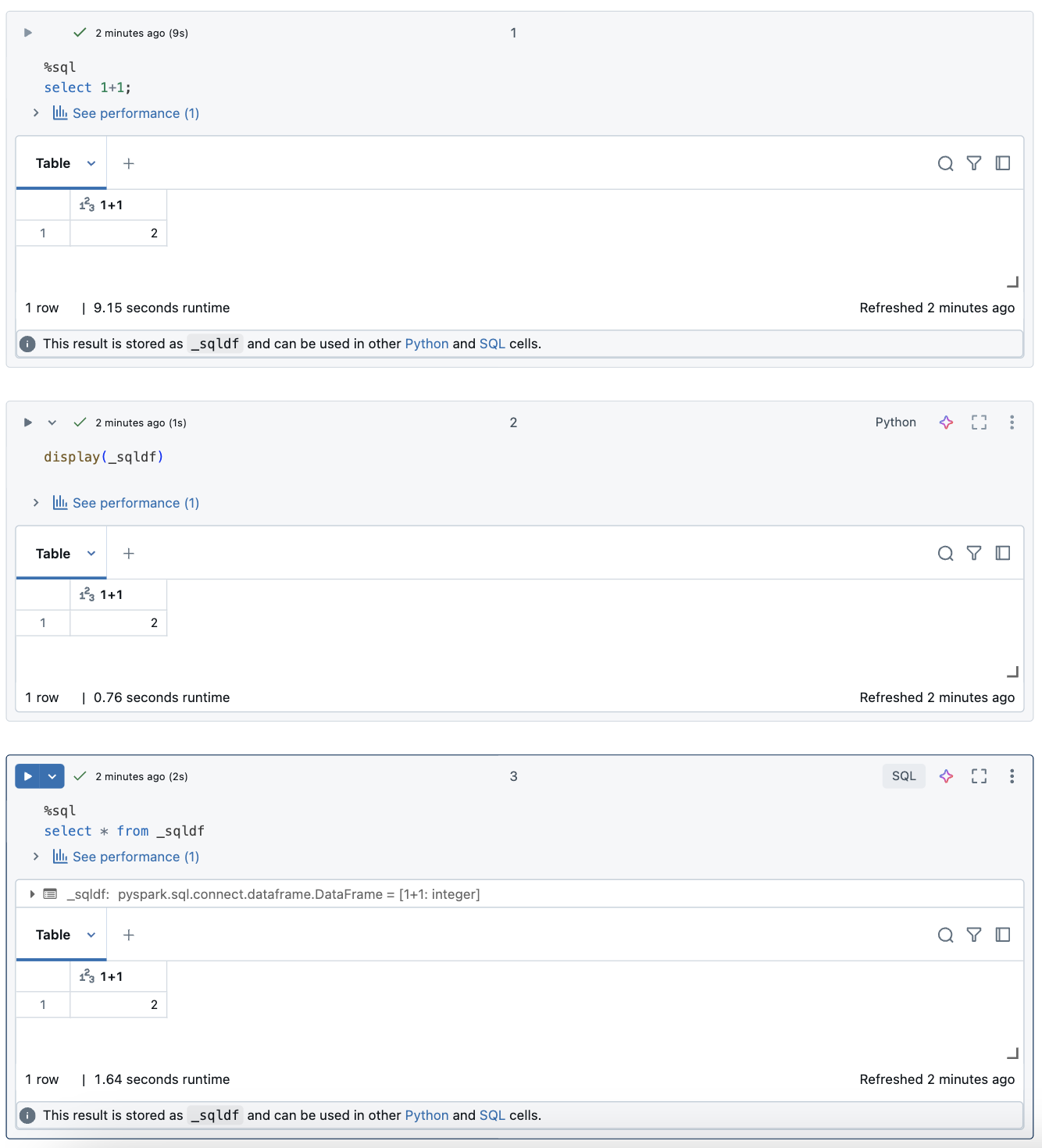
Importante
A variável _sqldf é reatribuída cada vez que uma célula SQL é executada. Para evitar a perda de referência a um resultado DataFrame específico, atribua-o a um novo nome de variável antes de executar a próxima célula SQL:
Python
new_dataframe_name = _sqldf
SQL
ALTER VIEW _sqldf RENAME TO new_dataframe_name
Executar células SQL em paralelo
Enquanto um comando estiver em execução e o notebook estiver anexado a um cluster interativo, você poderá executar uma célula SQL simultaneamente com o comando atual. A célula SQL é executada em uma nova sessão paralela.
Para executar uma célula em paralelo:
Clique em Executar agora. A célula é executada imediatamente.
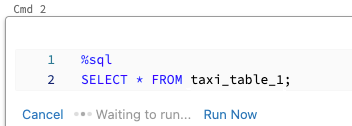
Como a célula é executada em uma nova sessão, não há suporte para exibições temporárias, UDFs e DataFrame implícito do Python (_sqldf) para células executadas em paralelo. Além disso, os nomes padrão do catálogo e do banco de dados são usados durante a execução paralela. Se o código se referir a uma tabela em um catálogo ou banco de dados diferente, você deverá especificar o nome da tabela usando o namespace de três níveis (catalog.schema.table).
Executar células SQL em um SQL warehouse
Você pode executar comandos SQL em um notebook do Databricks em um SQL warehouse, um tipo de computação otimizado para análise de SQL. Confira Usar um notebook com um SQL warehouse.
Exibir imagens
O Azure Databricks dá suporte à exibição de imagens em células Markdown. Você pode exibir imagens armazenadas no Workspace, em Volumes ou no FileStore.
Exibir imagens armazenadas no Workspace
Você pode usar caminhos absolutos ou caminhos relativos para exibir imagens armazenadas no Workspace. Para exibir uma imagem armazenada no FileStore, use a seguinte sintaxe:
%md


Exibir imagens armazenadas em Volumes
Você pode usar caminhos absolutos para exibir imagens armazenadas em Volumes. Para exibir uma image armazenada no FileStore, use a seguinte sintaxe:
%md

Exibir imagens armazenadas no FileStore
Para exibir as imagens armazenadas no FileStore, use a seguinte sintaxe:
%md

Por exemplo, vamos supor que você tem o arquivo de imagem de logotipo do Databricks no FileStore:
dbfs ls dbfs:/FileStore/
databricks-logo-mobile.png
Ao incluir o seguinte código em uma célula Markdown:

a imagem é processada na célula:

Arrastar e soltar imagens
Você pode arrastar e soltar imagens do seu sistema de arquivos local em células Markdown. A imagem é carregada no diretório atual do workspace e exibida na célula.
Exibir equações matemáticas
Os notebooks recebem suporte do KaTeX para exibir fórmulas matemáticas e equações. Por exemplo,
%md
\\(c = \\pm\\sqrt{a^2 + b^2} \\)
\\(A{_i}{_j}=B{_i}{_j}\\)
$$c = \\pm\\sqrt{a^2 + b^2}$$
\\[A{_i}{_j}=B{_i}{_j}\\]
renderiza como:
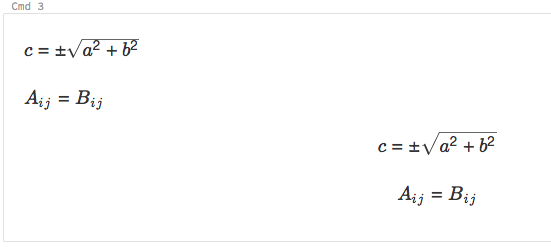
e
%md
\\( f(\beta)= -Y_t^T X_t \beta + \sum log( 1+{e}^{X_t\bullet\beta}) + \frac{1}{2}\delta^t S_t^{-1}\delta\\)
where \\(\delta=(\beta - \mu_{t-1})\\)
renderiza como:
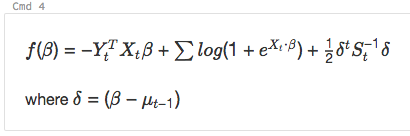
Incluir HTML
Você pode incluir HTML em um notebook usando a função displayHTML. Consulte HTML, D3 e SVG em notebooks para ver um exemplo de como fazer isso.
Observação
O iframe displayHTML é servido do domínio databricksusercontent.com e a área restrita do iframe inclui o atributo allow-same-origin. databricksusercontent.com deve ser acessível em seu navegador. Se estiver bloqueado pela sua rede corporativa, ele precisará ser adicionado em uma lista de permitidos.
Vincular a outros notebooks
Você pode vincular a outros notebooks ou pastas em células Markdown usando caminhos relativos. Especifique o atributo href de uma marca de âncora como o caminho relativo, começando com um $ e, siga o mesmo padrão usado dos sistemas de arquivos Unix:
%md
<a href="$./myNotebook">Link to notebook in same folder as current notebook</a>
<a href="$../myFolder">Link to folder in parent folder of current notebook</a>
<a href="$./myFolder2/myNotebook2">Link to nested notebook</a>