Como usar o Azure Pipelines com o Apache Flink® no HDInsight no AKS
Observação
Desativaremos o Microsoft Azure HDInsight no AKS em 31 de janeiro de 2025. Para evitar o encerramento abrupto das suas cargas de trabalho, você precisará migrá-las para o Microsoft Fabric ou para um produto equivalente do Azure antes de 31 de janeiro de 2025. Os clusters restantes em sua assinatura serão interrompidos e removidos do host.
Somente o suporte básico estará disponível até a data de desativação.
Importante
Esse recurso está atualmente na visualização. Os Termos de uso complementares para versões prévias do Microsoft Azure incluem mais termos legais que se aplicam aos recursos do Azure que estão em versão beta, em versão prévia ou ainda não lançados em disponibilidade geral. Para obter informações sobre essa versão prévia específica, confira Informações sobre a versão prévia do Azure HDInsight no AKS. Caso tenha perguntas ou sugestões de recursos, envie uma solicitação no AskHDInsight com os detalhes e siga-nos para ver mais atualizações sobre a Comunidade do Azure HDInsight.
Neste artigo, você aprenderá a usar o Azure Pipelines com o HDInsight no AKS para enviar trabalhos do Flink com a API REST do cluster. Orientamos você pelo processo usando um pipeline YAML de exemplo e um script do PowerShell, ambos simplificando a automação das interações da API REST.
Pré-requisitos
Assinatura do Azure. Se você não tiver uma assinatura do Azure, crie uma conta gratuita.
Uma conta do GitHub, na qual você pode criar um repositório. Crie um gratuitamente.
Criar diretório
.pipeline, copiar flink-azure-pipelines.yml e flink-job-azure-pipeline.ps1Organização do Azure DevOps. Crie um gratuitamente. Se sua equipe já tiver uma, verifique se você é administrador do projeto do Azure DevOps que deseja usar.
Capacidade de executar pipelines em agentes hospedados pela Microsoft. Para usar agentes hospedados pela Microsoft, sua organização do Azure DevOps precisa ter acesso a trabalhos paralelos hospedados pela Microsoft. Você pode comprar um trabalho paralelo ou solicitar uma concessão gratuita.
Um cluster Flink. Se você não tiver um, Crie um cluster Flink no HDInsight no AKS.
Crie um diretório na conta de armazenamento do cluster para copiar o jar do trabalho. Posteriormente, esse diretório precisará ser configurado no YAML do pipeline para a localização do jar do trabalho (<JOB_JAR_STORAGE_PATH>).
Etapas para configurar o pipeline
Criar uma entidade de serviço para Azure Pipelines
Crie uma entidade de serviço do Microsoft Entra para acessar o Azure – Conceda permissão para acessar o cluster do HDInsight no AKS com a função Colaborador e anote os valores de appId, senha e locatário da resposta.
az ad sp create-for-rbac -n <service_principal_name> --role Contributor --scopes <Flink Cluster Resource ID>`
Exemplo:
az ad sp create-for-rbac -n azure-flink-pipeline --role Contributor --scopes /subscriptions/abdc-1234-abcd-1234-abcd-1234/resourceGroups/myResourceGroupName/providers/Microsoft.HDInsight/clusterpools/hiloclusterpool/clusters/flinkcluster`
Referência
Observação
Apache, Apache Flink, Flink e nomes de projeto de software livre associados são marcas comerciais da Apache Software Foundation (ASF).
Criar um cofre de chave
Crie o Azure Key Vault, siga este tutorial para criar um novo Azure Key Vault.
Crie três Segredos
cluster-storage-key para chave de armazenamento.
service-principal-key para clientId principal ou appId.
service-principal-secret para segredo da entidade de segurança.
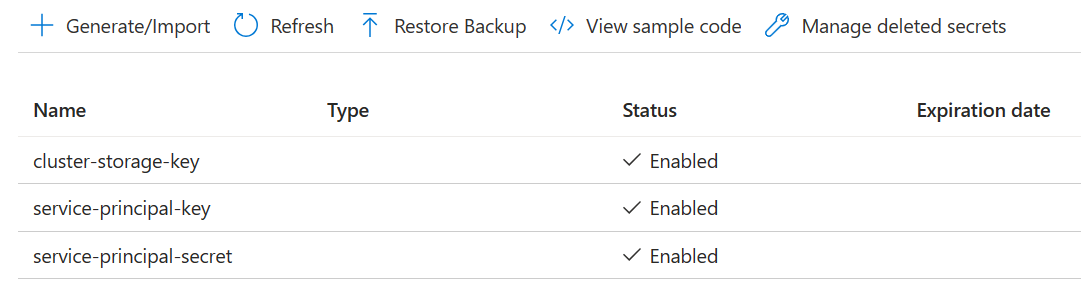
Conceda permissão para acessar o Azure Key Vault com a função "Responsável por segredos do Key Vault" à entidade de serviço.

Configurar pipeline
Navegue até seu projeto e clique em Configurações do Projeto.
Role a tela para baixo e selecione Conexões do Serviço e, em seguida, Nova Conexão do Serviço.
Selecione Azure Resource Manager.

No método de autenticação, selecione Entidade de serviço (automático).
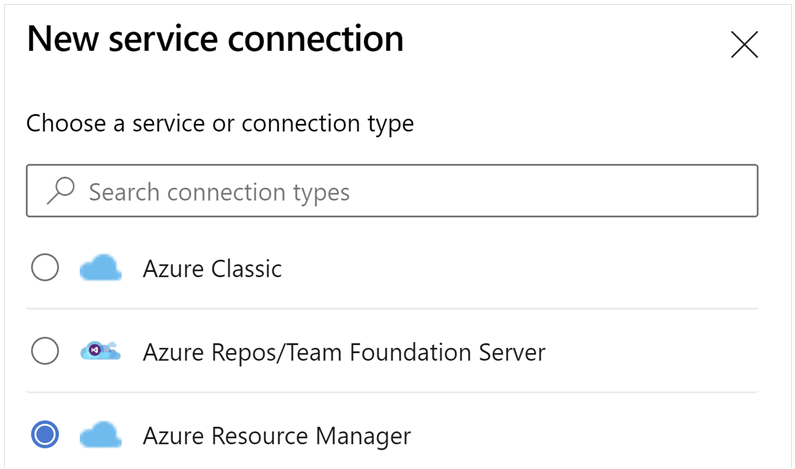
Edite as propriedades da conexão do serviço. Selecione a entidade de serviço que você criou recentemente.

Clique em Verificar para conferir se a conexão foi configurada corretamente. Se você encontrar o seguinte erro:

Será necessário atribuir a função Leitor à assinatura.
Depois disso, a verificação deve ter sucesso.
Salvar a conexão de serviço.

Navegue até pipelines e clique em Novo Pipeline.
Selecione GitHub como o local do código.
Selecione o repositório . Confira como criar um repositório no GitHub. select-github-repo image.
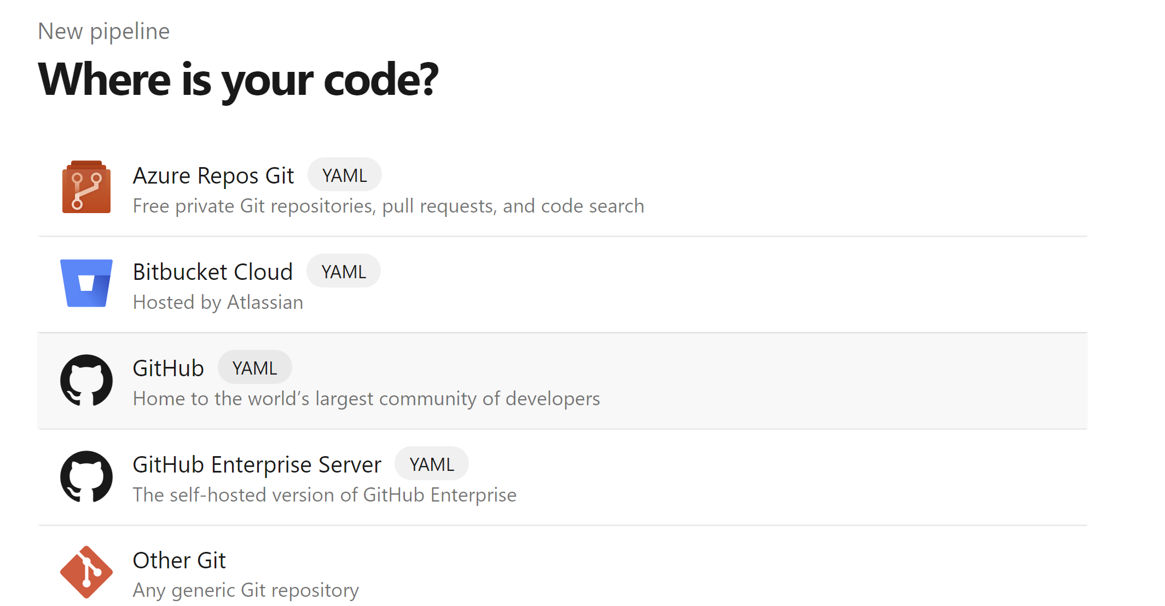
Selecione o repositório . Para saber mais, confira Como criar um repositório no GitHub.
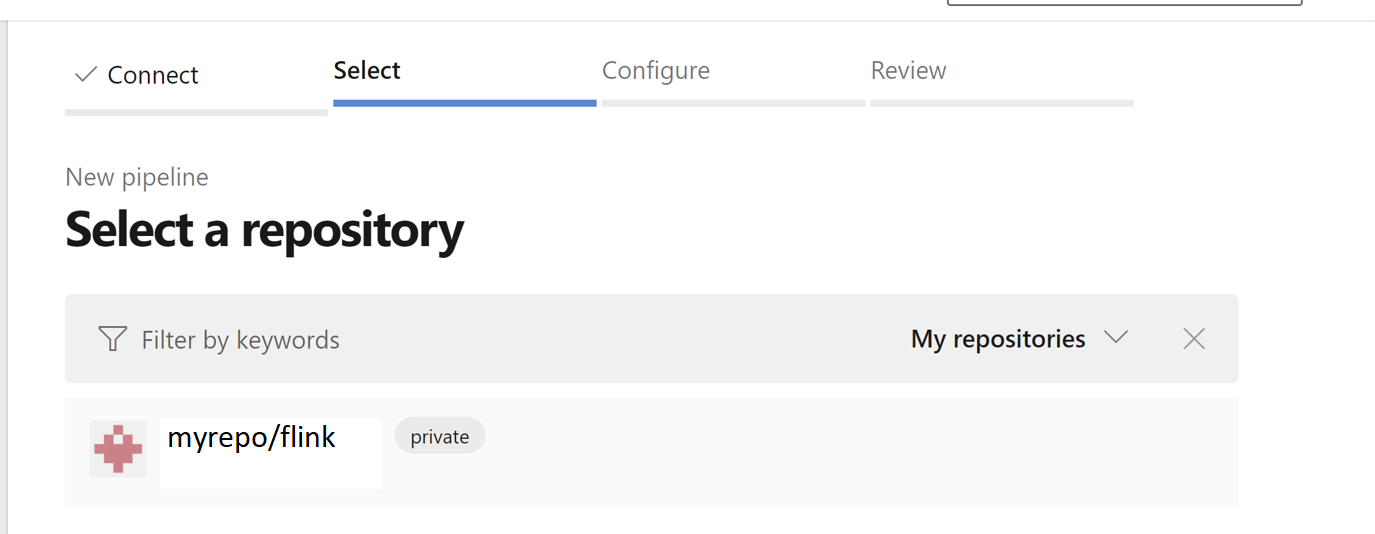
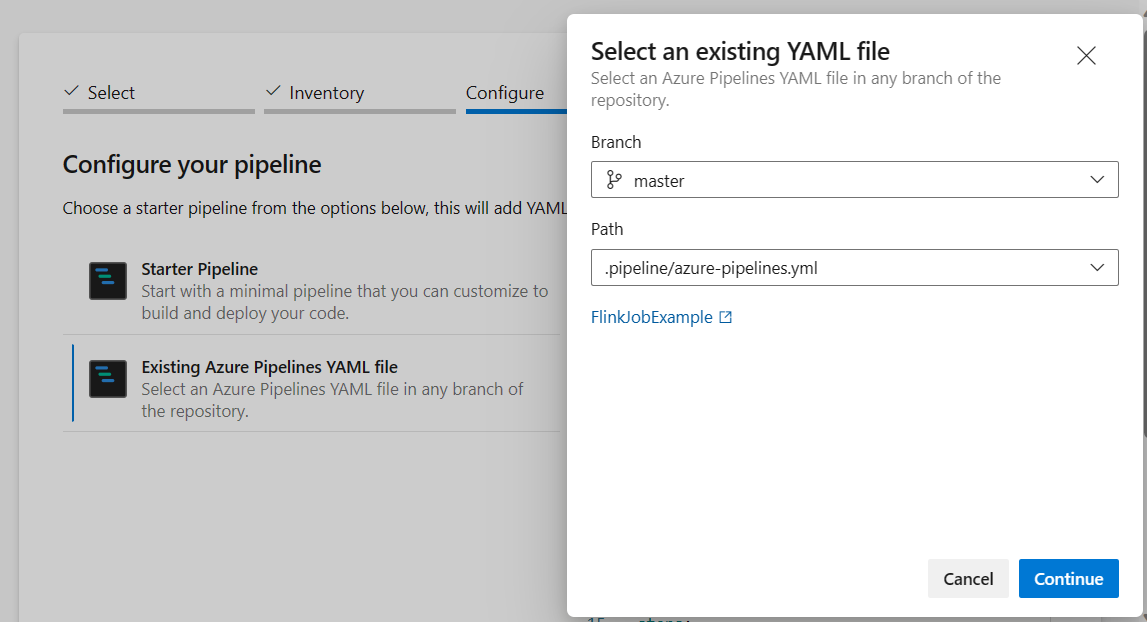
Na opção de configuração de pipeline, escolha Arquivo YAML do Azure Pipelines existente. Selecione o script do branch e do pipeline copiado anteriormente. (.pipeline/flink-azure-pipelines.yml)
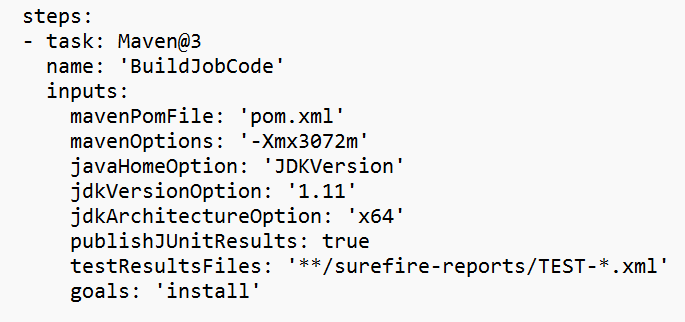
Substitua o valor na seção variável.

Corrija a seção de build de código com base em suas necessidades e configure <JOB_JAR_LOCAL_PATH> na seção variável para o caminho local do jar de trabalho.
Adicione a variável de pipeline "action" e configure o valor "RUN".
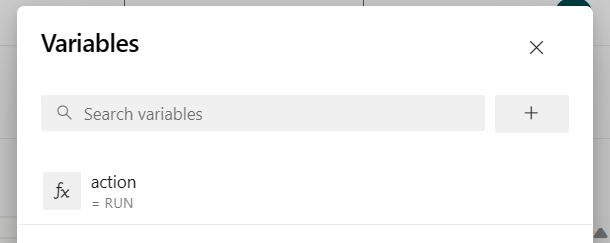
é possível alterar os valores da variável antes de executar o pipeline.
NEW: esse é o valor padrão. Ele inicia um novo trabalho e, se o trabalho já estiver em execução, atualizará o trabalho em execução com o jar mais recente.
SAVEPOINT: esse valor usa o ponto de salvamento para executar o trabalho.
DELETE: cancelar ou excluir o trabalho em execução.
Salve e execute o pipeline. Veja o trabalho em execução no portal na seção Trabalho do Flink.








Observação
Esse é um exemplo para enviar o trabalho usando o pipeline. Você pode seguir o documento da API REST do Flink para escrever seu próprio código para enviar o trabalho.