Tutorial: Usar o Apache HBase no Azure HDInsight
Este tutorial demonstra como criar um cluster do Apache HBase no Azure HDInsight, criar tabelas do HBase e consultar tabelas usando o Apache Hive. Para saber mais sobre o HBase, confira Visão geral do HBase do HDInsight.
Neste tutorial, você aprenderá como:
- Criar cluster do Apache HBase
- Criar tabelas do HBase e inserir dados
- Usar o Apache Hive para consultar o Apache HBase
- Usar APIs de REST do HBase usando Curl
- Verificar o status do cluster
Pré-requisitos
Um cliente SSH. Para saber mais, confira Conectar-se ao HDInsight (Apache Hadoop) usando SSH.
Bash. Os exemplos neste artigo usam o shell Bash no Windows 10 para os comandos de cURL. Confira o Guia de instalação do subsistema do Windows para Linux para o Windows 10 para conhecer as etapas de instalação. Outros shells do Unix também funcionarão. Os exemplos de cURL, com algumas pequenas modificações, podem funcionar em um prompt de comando do Windows. Ou é possível usar o cmdlet do Windows PowerShell Invoke-RestMethod.
Criar cluster do Apache HBase
O procedimento a seguir usa um modelo do Azure Resource Manager para criar um cluster do HBase. O modelo também cria a conta de Armazenamento do Azure padrão dependente. Para compreender os parâmetros usados no procedimento e em outros métodos de criação de cluster, consulte Criar clusters Hadoop baseados em Linux no HDInsight.
Selecione a imagem a seguir para abrir o modelo no portal do Azure. O modelo está localizado nos Modelos de Início Rápido do Azure.

Na caixa de diálogo Implantação personalizada, insira os seguintes valores:
Propriedade Descrição Subscription Selecione sua assinatura do Azure que é usada para criar o cluster. Resource group Crie um grupo de gerenciamento de recursos do Azure ou use um existente. Location Especifique o local do grupo de recursos. ClusterName Insira um nome para o cluster HBase. Nome e senha de logon do cluster O nome padrão de logon é admin.Nome de usuário e senha SSH O nome de usuário padrão é sshuser.Outros parâmetros são opcionais.
Cada cluster tem uma dependência de conta de Armazenamento do Azure. Depois que você excluir um cluster, os dados ficarão na conta de armazenamento. O nome de conta de armazenamento padrão do cluster é o nome do cluster com "store" acrescentado. Eles são embutidos no código na seção de variáveis do modelo.
Selecione Concordo com os termos e condições declarados acima e selecione Comprar. Demora cerca de 20 minutos para criar um cluster.
Depois que um cluster do HBase é excluído, você pode criar outro cluster HBase usando o mesmo contêiner de blob padrão. O novo cluster seleciona as tabelas HBase criadas por você no cluster original. É recomendável desabilitar as tabelas HBase antes de excluir o cluster para evitar inconsistências.
Criar tabelas e inserir dados
Você pode usar o SSH para se conectar a clusters do HBase e, em seguida, usar o Shell do Apache HBase para criar tabelas do HBase, inserir dados e consultar dados.
Para a maioria das pessoas, os dados aparecem no formato de tabela:

No HBase (uma implementação do Cloud BigTable), os mesmos dados se parecem com:

Para usar o shell HBase
Use o comando
sshpara se conectar ao cluster HBase. Edite o seguinte comando substituindoCLUSTERNAMEpelo nome do cluster e insira o comando:ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netUse o comando
hbase shellpara iniciar o shell interativo do HBase. Digite o seguinte comando em sua conexão de SSH:hbase shellUse o comando
createpara criar uma tabela HBase com famílias de duas colunas. Os nomes de coluna e tabela diferenciam maiúsculas de minúsculas. Insira o seguinte comando:create 'Contacts', 'Personal', 'Office'Use o comando
listpara listar todas as tabelas no HBase. Insira o seguinte comando:listUse o comando
putpara inserir valores em uma coluna e linha especificadas em uma determinada tabela. Digite os seguintes comandos:put 'Contacts', '1000', 'Personal:Name', 'John Dole' put 'Contacts', '1000', 'Personal:Phone', '1-425-000-0001' put 'Contacts', '1000', 'Office:Phone', '1-425-000-0002' put 'Contacts', '1000', 'Office:Address', '1111 San Gabriel Dr.'Use o comando
scanpara verificar e retornar os dados da tabelaContacts. Insira o seguinte comando:scan 'Contacts'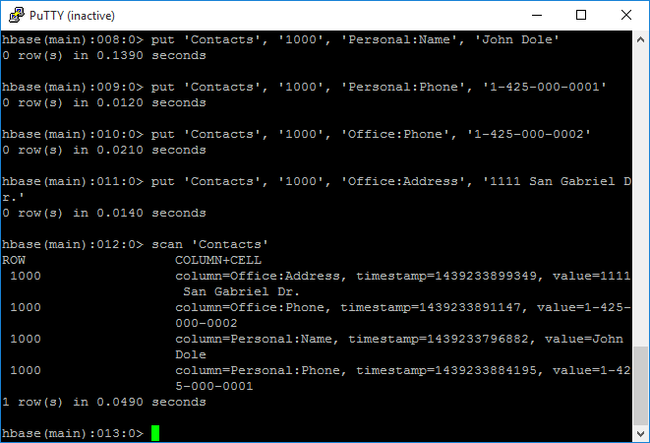
Use o comando
getpara buscar o conteúdo de uma linha. Insira o seguinte comando:get 'Contacts', '1000'Você verá resultados semelhantes usando o comando
scanporque há apenas uma linha.Para saber mais sobre o esquema da tabela HBase, confira Introdução ao projeto de esquema do Apache HBase. Para obter mais comandos HBase, confira Guia de referência do Apache HBase.
Use o comando
exitpara interromper o shell interativo do HBase. Insira o seguinte comando:exit
Para carregar dados em massa na tabela de contatos HBase
O HBase inclui vários métodos de carregamento de dados em tabelas. Para obter mais informações, consulte Carregamento em massa.
Um arquivo de dados de exemplo pode ser encontrado em um contêiner de blobs público, wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txt. O conteúdo do arquivo de dados é:
8396 Calvin Raji 230-555-0191 230-555-0191 5415 San Gabriel Dr.
16600 Karen Wu 646-555-0113 230-555-0192 9265 La Paz
4324 Karl Xie 508-555-0163 230-555-0193 4912 La Vuelta
16891 Jonn Jackson 674-555-0110 230-555-0194 40 Ellis St.
3273 Miguel Miller 397-555-0155 230-555-0195 6696 Anchor Drive
3588 Osa Agbonile 592-555-0152 230-555-0196 1873 Lion Circle
10272 Julia Lee 870-555-0110 230-555-0197 3148 Rose Street
4868 Jose Hayes 599-555-0171 230-555-0198 793 Crawford Street
4761 Caleb Alexander 670-555-0141 230-555-0199 4775 Kentucky Dr.
16443 Terry Chander 998-555-0171 230-555-0200 771 Northridge Drive
Você pode, opcionalmente, criar um arquivo de texto e carregá-lo na sua própria conta de armazenamento se desejar. Para obter instruções, confira Carregar dados para trabalhos do Apache Hadoop no HDInsight.
Este procedimento usa a tabela Contacts do HBase que você criou no último procedimento.
Na conexão ssh aberta, execute o seguinte comando para transformar o arquivo de dados para StoreFiles e armazene em um caminho relativo especificado por
Dimporttsv.bulk.output.hbase org.apache.hadoop.hbase.mapreduce.ImportTsv -Dimporttsv.columns="HBASE_ROW_KEY,Personal:Name,Personal:Phone,Office:Phone,Office:Address" -Dimporttsv.bulk.output="/example/data/storeDataFileOutput" Contacts wasb://hbasecontacts@hditutorialdata.blob.core.windows.net/contacts.txtExecute o seguinte comando para carregar os dados de
/example/data/storeDataFileOutputna tabela do HBase:hbase org.apache.hadoop.hbase.mapreduce.LoadIncrementalHFiles /example/data/storeDataFileOutput ContactsVocê pode abrir o shell do HBase e usar o comando
scanpara listar o conteúdo da tabela.
Usar o Apache Hive para consultar o Apache HBase
Você pode consultar os dados nas tabelas do HBase usando Apache Hive. Nesta seção você cria uma tabela Hive que faz o mapeamento para a tabela do HBase e usa-a para consultar os dados em sua tabela do HBase.
Na sua conexão ssh aberta, use o seguinte comando para iniciar o Beeline:
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -n adminPara saber mais sobre o Beeline, consulte Usar o Hive com Hadoop no HDInsight com Beeline.
Execute o script do HiveQL a seguir para criar uma tabela Hive que é mapeada para a tabela do HBase. Verifique se você criou a tabela de exemplo referenciada anteriormente neste artigo, usando o shell do HBase antes de executar essa instrução.
CREATE EXTERNAL TABLE hbasecontacts(rowkey STRING, name STRING, homephone STRING, officephone STRING, officeaddress STRING) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ('hbase.columns.mapping' = ':key,Personal:Name,Personal:Phone,Office:Phone,Office:Address') TBLPROPERTIES ('hbase.table.name' = 'Contacts');Execute o seguinte script do HiveQL para consultar os dados na tabela do HBase:
SELECT count(rowkey) AS rk_count FROM hbasecontacts;Para sair do Beeline, use
!exit.Para sair da sua conexão ssh, use
exit.
Separar clusters do Hive e do HBase
A consulta de Hive para acessar dados do HBase não precisa ser executada do cluster do HBase. Qualquer cluster fornecido com o Hive (incluindo Spark, Hadoop, HBase ou Interactive Query) pode ser usado para consultar dados do HBase, desde que as seguintes etapas sejam concluídas:
- Ambos os clusters devem ser anexados à mesma Rede Virtual e Sub-rede
- Copie
/usr/hdp/$(hdp-select --version)/hbase/conf/hbase-site.xmldos nós de cabeçalho do cluster HBase para os nós de cabeçalho e de trabalho do cluster do Hive.
Clusters seguros
Os dados do HBase também podem ser consultados no Hive usando o HBase habilitado para ESP:
- Ao seguir um padrão com vários clusters, ambos os clusters devem ser habilitados para ESP.
- Para permitir que o Hive consulte dados do HBase, verifique se o usuário
hiverecebeu permissões para acessar dados do HBase por meio do plug-in HBase Apache Ranger - Quando você usa clusters separados habilitados para ESP, o conteúdo de
/etc/hostsdos nós de cabeçalho do cluster do HBase deve ser acrescentado ao/etc/hostsdos nós de cabeçalho e de trabalho do cluster do Hive.
Observação
Após o dimensionamento dos clusters, /etc/hosts deve ser acrescentado novamente
Usar a API REST do HBase via Curl
A API REST do HBase é protegida por meio de autenticação Básica. Você deve sempre fazer solicitações usando HTTPS (HTTP seguro) para ajudar a garantir que suas credenciais sejam enviadas com segurança para o servidor.
Para habilitar a API REST do HBase no cluster do HDInsight, adicione o script de inicialização personalizado a seguir na seção Ação de Script. Você pode adicionar o script de inicialização ao criar o cluster ou após ele ter sido criado. Para Tipo de Nó, selecione Servidores de Região para garantir que o script seja executado somente nos Servidores de Região do HBase. O script inicia o proxy REST do HBase na porta 8090 em servidores regionais.
#! /bin/bash THIS_MACHINE=`hostname` if [[ $THIS_MACHINE != wn* ]] then printf 'Script to be executed only on worker nodes' exit 0 fi RESULT=`pgrep -f RESTServer` if [[ -z $RESULT ]] then echo "Applying mitigation; starting REST Server" sudo python /usr/lib/python2.7/dist-packages/hdinsight_hbrest/HbaseRestAgent.py else echo "REST server already running" exit 0 fiDefina a variável de ambiente para facilitar o uso. Edite os comandos a seguir substituindo
MYPASSWORDpela senha de logon do cluster. SubstituaMYCLUSTERNAMEpelo nome do cluster do HBase. Em seguida, insira os comandos.export PASSWORD='MYPASSWORD' export CLUSTER_NAME=MYCLUSTERNAMEUse o seguinte comando para listar as tabelas HBase:
curl -u admin:$PASSWORD \ -G https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Use o seguinte comando para criar uma nova tabela HBase com famílias de duas colunas:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/schema" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"@name\":\"Contact1\",\"ColumnSchema\":[{\"name\":\"Personal\"},{\"name\":\"Office\"}]}" \ -vO esquema é fornecido no formato JSON.
Use o comando a seguir para inserir alguns dados:
curl -u admin:$PASSWORD \ -X PUT "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/false-row-key" \ -H "Accept: application/json" \ -H "Content-Type: application/json" \ -d "{\"Row\":[{\"key\":\"MTAwMA==\",\"Cell\": [{\"column\":\"UGVyc29uYWw6TmFtZQ==\", \"$\":\"Sm9obiBEb2xl\"}]}]}" \ -vCodifique em Base64 os valores especificados na opção -d. No exemplo:
MTAwMA==: 1000
UGVyc29uYWw6TmFtZQ==: Pessoal: Nome
Sm9obiBEb2xl: Julio Dole
false-row-key permite inserir diversos valores (em lote).
Use o comando a seguir para obter uma linha:
curl -u admin:$PASSWORD \ GET "https://$CLUSTER_NAME.azurehdinsight.net/hbaserest/Contacts1/1000" \ -H "Accept: application/json" \ -v
Observação
Ainda não há suporte para a verificação pelo ponto de extremidade do cluster.
Para saber mais sobre o Rest HBase, veja Guia de referência do Apache HBase.
Observação
Não há suporte para thrift pelo HBase no HDInsight.
Ao usar Curl ou qualquer outra comunicação REST com o WebHCat, você deve autenticar as solicitações fornecendo o nome de usuário e a senha para o administrador do cluster do HDInsight. Você também deve usar o nome do cluster como parte do Uniform Resource Identifier (URI) usado para enviar as solicitações ao servidor:
curl -u <UserName>:<Password> \
-G https://<ClusterName>.azurehdinsight.net/templeton/v1/status
Você deve receber uma resposta semelhante à resposta a seguir:
{"status":"ok","version":"v1"}
Verificar o status do cluster
O HBase em HDInsight é fornecido com uma interface do usuário da Web para monitorar clusters. Usando a interface do usuário da Web, você pode solicitar estatísticas ou informações sobre regiões.
Para acessar a interface do usuário mestre HBase
Entre na interface do usuário do Ambari Web em
https://CLUSTERNAME.azurehdinsight.net, em queCLUSTERNAMEé o nome do seu cluster do HBase.Selecione HBase no menu à esquerda.
Selecione Links Rápidos no topo da página, aponte para o link do nó ativo do Zookeeper e, em seguida, selecione Interface do usuário HBase Master. A interface do usuário é aberta em outra guia do navegador:
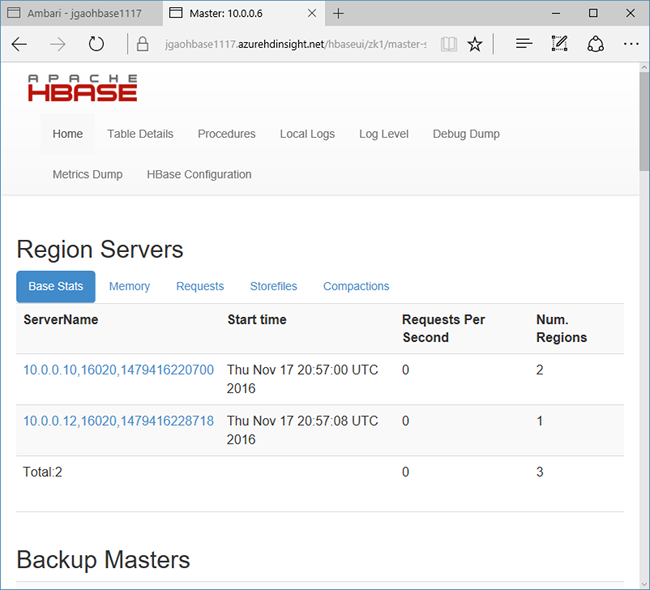
A Interface do Usuário Mestre HBase contém as seguintes seções:
- servidores de região
- mestres de backup
- tabelas
- tarefas
- atributos de software
Recriação de clusters
Depois que um cluster do HBase é excluído, você pode criar outro cluster HBase usando o mesmo contêiner de blob padrão. O novo cluster seleciona as tabelas HBase criadas por você no cluster original. No entanto, é recomendável desabilitar as tabelas HBase antes de excluir o cluster para evitar inconsistências.
Use o comando disable 'Contacts' do HBase.
Limpar os recursos
Se não for continuar usando este aplicativo, exclua o cluster do HBase que você criou seguindo estas etapas:
- Entre no portal do Azure.
- Na caixa Pesquisar na parte superior, digite HDInsight.
- Selecione Clusters do HDInsight em Serviços.
- Na lista de clusters do HDInsight que aparece, clique em … ao lado do cluster que você criou para este tutorial.
- Clique em Excluir. Clique em Sim.
Próximas etapas
Neste tutorial, você aprendeu como criar um cluster do Apache HBase. Além disso, também aprendeu a criar tabelas e ver os dados nessas tabelas no shell do HBase. Você também aprendeu a usar uma consulta do Hive dos dados em tabelas do HBase. E como usar a API REST C# do HBase para criar uma tabela do HBase e recuperar dados da tabela. Para obter mais informações, consulte: