Estudo de caso da arquitetura de solução de alta disponibilidade do Azure HDInsight
Os mecanismos de replicação do Azure HDInsight podem ser integrados em uma arquitetura de solução altamente disponível. Neste artigo, um estudo de caso fictício para o varejo da Contoso é usado para explicar possíveis abordagens de recuperação de desastres de alta disponibilidade, considerações de custo e seus designs correspondentes.
As recomendações de recuperação de desastre de alta disponibilidade podem ter muitas permutações e combinações. Essas soluções devem ser acessadas após a deliberação dos prós e contras de cada opção. Este artigo aborda apenas uma solução possível.
Arquitetura do cliente
A imagem a seguir ilustra a arquitetura primária de varejo da Contoso. A arquitetura consiste em uma carga de trabalho de streaming, carga de trabalho em lote, camada de serviço, camada de consumo, camada de armazenamento e controle de versão.
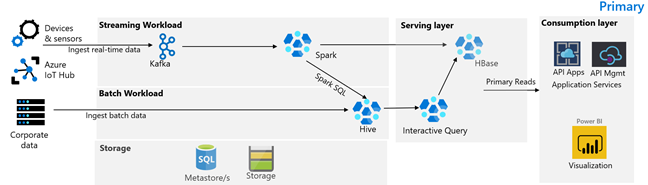
Carga de trabalho de streaming
Os dispositivos e sensores produzem dados para o HDInsight Kafka, que constitui a estrutura de mensagens. Um consumidor do HDInsight Spark lê a partir dos tópicos do Kafka. O Spark transforma e grava as mensagens de entrada em um cluster do HDInsight HBase na camada de serviço.
Carga de trabalho do lote
Um cluster do HDInsight Hadoop que executa o Hive e o MapReduce ingere os dados de sistemas transacionais locais. Os dados brutos transformados pelo Hive e pelo MapReduce são armazenados em tabelas Hive em uma partição lógica do data lake apoiada pelo Azure Data Lake Storage Gen2. Os dados armazenados em tabelas do Hive também são disponibilizados para o Spark SQL, que faz transformações em lote antes de armazenar os dados coletados no HBase para serviço.
Camada de serviço
Um cluster do HDInsight HBase com Apache Phoenix é usado para servir dados para aplicativos Web e painéis de visualização. Um cluster do HDInsight LLAP é usado para atender aos requisitos de relatórios internos.
Camada de consumo
Uma camada de Gerenciamento de API e Aplicativos de API do Azure atrás de uma página da Web voltada para o público. Os requisitos de relatórios internos são atendidos pelo Power BI.
Camada de armazenamento
O Azure Data Lake Storage Gen2 particionado logicamente é usado como um data lake corporativo. Os metastores do HDInsight são apoiados pelo BD SQL do Azure.
Sistema de controle de versão
Um sistema de controle de versão integrado a um Azure Pipelines e hospedado fora do Azure.
Requisitos de continuidade dos negócios do cliente
É importante determinar a funcionalidade de negócios mínima que você precisará se houver um desastre.
Requisitos de continuidade dos negócios de varejo do Contoso
- Devemos ser protegidos contra uma falha regional ou um problema de integridade do serviço regional.
- Meus clientes nunca devem ver um erro 404. O conteúdo público sempre deve ser atendido. (RTO = 0)
- Para a maior parte do ano, podemos mostrar o conteúdo público que está obsoleto em 5 horas. (RPO = 5 horas)
- Durante a época de Natal, nosso conteúdo voltado ao público deve estar sempre atualizado. (RPO = 0)
- Meus requisitos de relatórios internos não são considerados críticos para a continuidade dos negócios.
- Otimize os custos de continuidade dos negócios.
Solução proposta
A imagem a seguir mostra a arquitetura de recuperação de desastre de alta disponibilidade de varejo da Contoso.
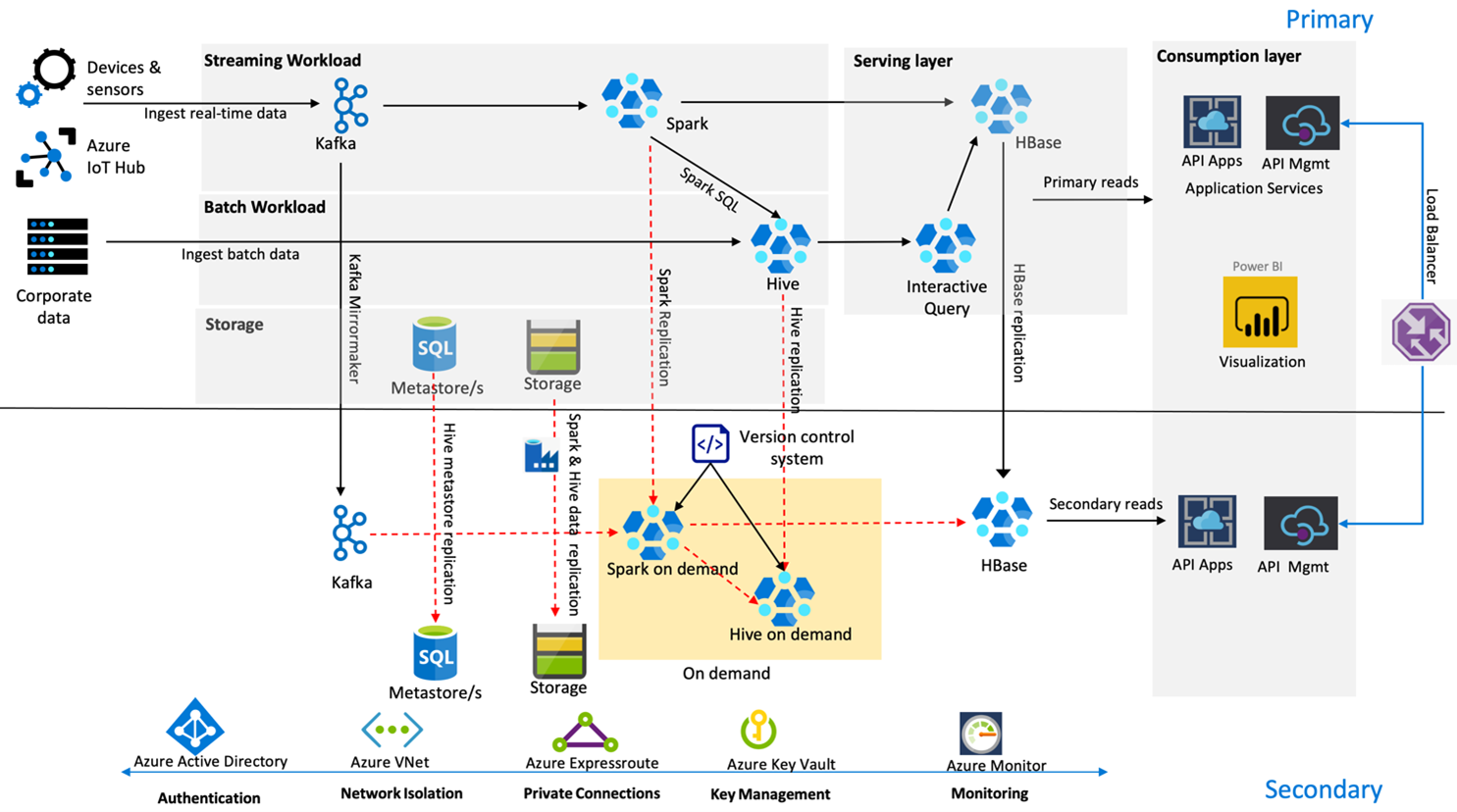
O Kafka usa a replicação Ativa – Passiva para espelhar os tópicos Kafka da região primária para a região secundária. Uma alternativa à replicação Kafka pode ser produzida para Kafka em ambas as regiões.
O Hive e o Spark usam modelos de replicação Primária Ativa – Secundária sob Demanda durante o horário normal. O processo de replicação do Hive é executado periodicamente e acompanha o metastore Hive SQL do Azure e a replicação da conta de armazenamento do Hive. A conta de armazenamento do Spark é replicada periodicamente usando o ADF DistCP. A natureza transitória desses clusters ajuda a otimizar os custos. As replicações são agendadas a cada 4 horas para chegar a um RPO que está bem dentro do requisito de cinco horas.
A replicação do HBase usa o modelo Líder – Seguidor durante os horários normais para garantir que os dados sejam sempre atendidos, independentemente da região, e se é muito baixo o RPO.
Se houver uma falha regional na região primária, a página da Web e o conteúdo de back-end serão servidos na região secundária por 5 horas com um certo grau de desatualização. Se o painel de integridade do serviço do Azure não indicar uma recuperação ETA na janela de cinco horas, o varejo da Contoso criará a camada de transformação do Hive e do Spark na região secundária e, em seguida, apontará todas as fontes de dados de upstream para a região secundária. Tornar a região secundária gravável causaria um processo de failback, o que envolve a replicação de volta para o primário.
Durante uma temporada de compras de pico, todo o pipeline secundário estará sempre ativo e em execução. Produtores do Kafka produzem para as duas regiões e a replicação do HBase seria alterada de Líder – Seguidor para Líder – Líder para garantir que o conteúdo voltado ao público esteja sempre atualizado.
Nenhuma solução de failover precisa ser projetada para relatórios internos, pois isso não é essencial para a continuidade dos negócios.
Próximas etapas
Para saber mais sobre os itens discutidos neste artigo, veja: