Usar o Apache Oozie com o Apache Hadoop para definir e executar um fluxo de trabalho no Azure HDInsight baseado no Linux
Saiba como usar o Apache Oozie com o Apache Hadoop no Azure HDInsight. O Oozie é um sistema de fluxo de trabalho e coordenação que gerencia trabalhos do Hadoop. O Oozie é integrado à pilha do Hadoop e dá suporte aos seguintes trabalhos:
- Apache Hadoop MapReduce
- Apache Pig
- Apache Hive
- Apache Sqoop
Você também pode usar o Oozie para agendar trabalhos específicos para um sistema, como programas Java ou scripts de shell.
Observação
Outra opção para definir fluxos de trabalho com HDInsight é usar o Azure Data Factory. Para saber mais sobre o Azure Data Factory, consulte Usar o Apache Pig e Apache Hive com Data Factory. Para usar o Oozie em clusters com o Enterprise Security Package, consulte Executar o Apache Oozie em clusters do HDInsight Hadoop com o Enterprise Security Package.
Pré-requisitos
Um cluster Hadoop no HDInsight. Consulte Introdução ao HDInsight no Linux.
Um cliente SSH. Veja Conectar ao HDInsight (Apache Hadoop) usando SSH.
Um Banco de Dados SQL do Azure. Veja Criar um banco de dados no Banco de Dados SQL do Azure no portal do Azure. Este artigo usa um banco de dados chamado oozietest.
O esquema de URI do seu armazenamento primário de clusters.
wasb://para o Armazenamento do Microsoft Azure,abfs://para o Azure Data Lake Storage Gen2 ouadl://para o Azure Data Lake Storage Gen1. Se a transferência segura estiver habilitada para o Armazenamento do Azure, o URI seráwasbs://. Confira também Transferência segura.
Fluxo de trabalho de exemplo
O fluxo de trabalho usado neste documento contém duas ações. Ações são definições de tarefas, como a execução de Sqoop, Hive, MapReduce ou outro processo:
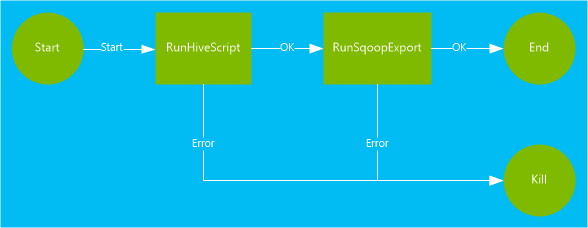
Uma ação do Hive executa um script HiveQL para extrair registros do
hivesampletableincluídos no HDInsight. Cada linha de dados descreve uma visita de um dispositivo móvel específico. O formato de registro se parece com o seguinte texto:8 18:54:20 en-US Android Samsung SCH-i500 California United States 13.9204007 0 0 23 19:19:44 en-US Android HTC Incredible Pennsylvania United States NULL 0 0 23 19:19:46 en-US Android HTC Incredible Pennsylvania United States 1.4757422 0 1O script do Hive usado neste documento conta o total de visitas de cada plataforma,como Android ou iPhone, e armazena as contagens em uma nova tabela do Hive.
Para obter mais informações sobre o Hive, veja [Usar o Apache Hive com o HDInsight][hdinsight-use-hive].
Uma ação do Sqoop exporta o conteúdo da nova tabela Hive para uma tabela criada em um Banco de Dados SQL do Azure. Para obter mais informações sobre o Sqoop, consulte Usar Apache Sqoop com HDInsight.
Observação
Para obter as versões do Oozie com suporte em clusters HDInsight, confira Novidades nas versões de clusters Hadoop fornecidas pelo HDInsight.
Criar o diretório de trabalho
O Oozie espera armazenar todos os recursos necessários para um trabalho no mesmo diretório. Este exemplo usa o wasbs:///tutorials/useoozie. Para criar o diretório, conclua as seguintes etapas:
Edite o código abaixo para substituir
sshuserpelo nome de usuário SSH do cluster e substituaCLUSTERNAMEpelo nome do cluster. Depois, insira o código para se conectar ao cluster HDInsight usando SSH.ssh sshuser@CLUSTERNAME-ssh.azurehdinsight.netPara criar o diretório, use o seguinte comando:
hdfs dfs -mkdir -p /tutorials/useoozie/dataObservação
O parâmetro
-pcria todos os diretórios no caminho. O diretório dedataé usado para armazenar dados usados pelo scriptuseooziewf.hql.Edite o código abaixo para substituir
sshuserpelo nome de usuário SSH. Para certificar-se de que Oozie pode representar a conta de usuário, use o seguinte comando:sudo adduser sshuser usersObservação
Você pode ignorar os erros que indicam o usuário como já sendo membro do grupo
users.
Adicionar um driver de banco de dados
Esse fluxo de trabalho usa o Sqoop para exportar dados para o banco de dados SQL. Portanto, você deve fornecer uma cópia do driver JDBC usado para interagir com o Banco de Dados SQL. Para copiar o driver JDBC para o diretório de trabalho, use o seguinte comando da sessão SSH:
hdfs dfs -put /usr/share/java/sqljdbc_7.0/enu/mssql-jdbc*.jar /tutorials/useoozie/
Importante
Verifique o driver JDBC real que existe em /usr/share/java/.
Caso o fluxo de trabalho tenha usado outros recursos, como um jar que contém um aplicativo MapReduce, você precisará adicionar esses recursos também.
Definir a consulta de Hive
Use as etapas a seguir para criar um script de HiveQL (linguagem de consulta Hive) que define uma consulta. Você usará a consulta em um fluxo de trabalho do Oozie mais adiante neste documento.
Na conexão SSH, use o seguinte comando para criar um arquivo denominado
useooziewf.hql:nano useooziewf.hqlQuando o editor nano GNU for aberto, use a seguinte consulta como o conteúdo do arquivo:
DROP TABLE ${hiveTableName}; CREATE EXTERNAL TABLE ${hiveTableName}(deviceplatform string, count string) ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t' STORED AS TEXTFILE LOCATION '${hiveDataFolder}'; INSERT OVERWRITE TABLE ${hiveTableName} SELECT deviceplatform, COUNT(*) as count FROM hivesampletable GROUP BY deviceplatform;Duas variáveis são usadas no script:
${hiveTableName}: contém o nome da tabela a ser criada.${hiveDataFolder}: contém o local para armazenar os arquivos de dados para a tabela.O arquivo de definição do fluxo de trabalho, workflow.xml neste artigo, transmite esses valores para o script HiveQL no runtime.
Para salvar o arquivo, selecione Ctrl+X, insira Y e selecione Enter.
Use o seguinte comando para copiar
useooziewf.hqlemwasbs:///tutorials/useoozie/useooziewf.hql:hdfs dfs -put useooziewf.hql /tutorials/useoozie/useooziewf.hqlEsse comando armazena o arquivo
useooziewf.hqlno armazenamento compatível com o HDFS para o cluster.
Definir o fluxo de trabalho
As definições de fluxo de trabalho do Oozie são codificadas em hPDL (linguagem de definição de processo do Hadoop), que é uma linguagem de definição de processo XML. Use as etapas a seguir para definir o fluxo de trabalho:
Use a instrução a seguir para criar e editar um novo arquivo:
nano workflow.xmlQuando o editor nano for aberto, insira o seguinte XML como conteúdo do arquivo:
<workflow-app name="useooziewf" xmlns="uri:oozie:workflow:0.2"> <start to = "RunHiveScript"/> <action name="RunHiveScript"> <hive xmlns="uri:oozie:hive-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.job.queue.name</name> <value>${queueName}</value> </property> </configuration> <script>${hiveScript}</script> <param>hiveTableName=${hiveTableName}</param> <param>hiveDataFolder=${hiveDataFolder}</param> </hive> <ok to="RunSqoopExport"/> <error to="fail"/> </action> <action name="RunSqoopExport"> <sqoop xmlns="uri:oozie:sqoop-action:0.2"> <job-tracker>${jobTracker}</job-tracker> <name-node>${nameNode}</name-node> <configuration> <property> <name>mapred.compress.map.output</name> <value>true</value> </property> </configuration> <arg>export</arg> <arg>--connect</arg> <arg>${sqlDatabaseConnectionString}</arg> <arg>--table</arg> <arg>${sqlDatabaseTableName}</arg> <arg>--export-dir</arg> <arg>${hiveDataFolder}</arg> <arg>-m</arg> <arg>1</arg> <arg>--input-fields-terminated-by</arg> <arg>"\t"</arg> <archive>mssql-jdbc-7.0.0.jre8.jar</archive> </sqoop> <ok to="end"/> <error to="fail"/> </action> <kill name="fail"> <message>Job failed, error message[${wf:errorMessage(wf:lastErrorNode())}] </message> </kill> <end name="end"/> </workflow-app>Existem duas ações definidas no fluxo de trabalho:
RunHiveScript: essa ação é a ação inicial e executa o script do Hiveuseooziewf.hql.RunSqoopExport: essa ação exporta os dados criados do script Hive para um banco de dados SQL usando o Sqoop. Essa ação será executada apenas se a açãoRunHiveScriptfor bem-sucedida.O fluxo de trabalho tem várias entradas, como
${jobTracker}. Você substituirá essas entradas pelos valores usados na definição do trabalho. Você criará a definição de trabalho mais adiante neste documento.Observe também a entrada
<archive>mssql-jdbc-7.0.0.jre8.jar</archive>na seção Sqoop. Essa entrada instrui o Oozie a disponibilizar esse arquivo morto ao Sqoop quando essa ação é executada.
Para salvar o arquivo, selecione Ctrl+X, insira Y e selecione Enter.
Use o seguinte comando para copiar o arquivo
workflow.xmlpara/tutorials/useoozie/workflow.xml:hdfs dfs -put workflow.xml /tutorials/useoozie/workflow.xml
Criar uma tabela
Observação
Há várias maneiras para se conectar ao Banco de Dados SQL para criar uma tabela. As seguintes etapas usam FreeTDS do cluster HDInsight.
Use o seguinte comando para instalar o FreeTDS no cluster do HDInsight:
sudo apt-get --assume-yes install freetds-dev freetds-binEdite o código abaixo para substituir
<serverName>pelo nome Servidor SQL lógico e<sqlLogin>pelo logon do servidor. Insira o comando para conectar-se ao banco de dados SQL de pré-requisito. Insira a senha no prompt.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestVocê receberá uma saída parecida com o seguinte texto:
locale is "en_US.UTF-8" locale charset is "UTF-8" using default charset "UTF-8" Default database being set to oozietest 1>Ao prompt
1>, insira o seguinte:CREATE TABLE [dbo].[mobiledata]( [deviceplatform] [nvarchar](50), [count] [bigint]) GO CREATE CLUSTERED INDEX mobiledata_clustered_index on mobiledata(deviceplatform) GOQuando a instrução
GOfor inserida, as instruções anteriores serão avaliadas. Essas instruções criam uma tabela chamadamobiledataque é usada pelo fluxo de trabalho.Para verificar se a tabela foi criada, use os seguintes comandos:
SELECT * FROM information_schema.tables GOVocê vê uma saída semelhante à seguinte:
TABLE_CATALOG TABLE_SCHEMA TABLE_NAME TABLE_TYPE oozietest dbo mobiledata BASE TABLESaia do utilitário tsql inserindo
exitno prompt1>.
Criar a definição de trabalho
A definição de trabalho descreve o local em que o workflow.xml se encontra. Ela também descreve o local em que você pode encontrar outros arquivos usados pelo fluxo de trabalho, como useooziewf.hql. Além disso, ele define os valores para as propriedades usadas no fluxo de trabalho e nos arquivos associados.
Para obter o endereço completo do armazenamento padrão, use o comando a seguir. Esse endereço é usado no arquivo de configuração que você vai criar na próxima etapa.
sed -n '/<name>fs.default/,/<\/value>/p' /etc/hadoop/conf/core-site.xmlO comando retorna informações semelhantes ao seguinte XML:
<name>fs.defaultFS</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value>Observação
Se o cluster HDInsight usa o armazenamento do Azure como o armazenamento padrão, o conteúdo de elemento
<value>começa comwasbs://. Se o Azure Data Lake Storage Gen1 for usado, ele começará comadl://. Se o Azure Data Lake Storage Gen2 for usado, ele começará comabfs://.Salve o conteúdo do elemento
<value>, pois ele será usado nas próximas etapas.Edite o xml abaixo da seguinte forma:
Valor de espaço reservado Valor substituído wasbs://mycontainer@mystorageaccount.blob.core.windows.net Valor recebido da etapa 1. administrador Substitua o nome de logon para o cluster do HDInsight se não for admin. serverName Nome do servidor do Banco de Dados SQL do Azure. sqlLogin Logon do servidor do Banco de Dados SQL do Azure. sqlPassword Senha de logon do servidor do Banco de Dados SQL do Azure. <?xml version="1.0" encoding="UTF-8"?> <configuration> <property> <name>nameNode</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net</value> </property> <property> <name>jobTracker</name> <value>headnodehost:8050</value> </property> <property> <name>queueName</name> <value>default</value> </property> <property> <name>oozie.use.system.libpath</name> <value>true</value> </property> <property> <name>hiveScript</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/useooziewf.hql</value> </property> <property> <name>hiveTableName</name> <value>mobilecount</value> </property> <property> <name>hiveDataFolder</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie/data</value> </property> <property> <name>sqlDatabaseConnectionString</name> <value>"jdbc:sqlserver://serverName.database.windows.net;user=sqlLogin;password=sqlPassword;database=oozietest"</value> </property> <property> <name>sqlDatabaseTableName</name> <value>mobiledata</value> </property> <property> <name>user.name</name> <value>admin</value> </property> <property> <name>oozie.wf.application.path</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property> </configuration>A maioria das informações contidas nesse arquivo é usada para preencher os valores usados nos arquivos workflow.xml ou ooziewf.hql, como
${nameNode}. Se o caminho for um caminhowasbs, use o caminho completo. Não o reduza a apenaswasbs:///. A entradaoozie.wf.application.pathdefine onde encontrar o arquivo workflow.xml. Esse arquivo contém o fluxo de trabalho que foi executado pelo trabalho.Para criar a configuração de definição de trabalho do Oozie, use o seguinte comando:
nano job.xmlQuando o editor nano for aberto, use o XML editado como conteúdo do arquivo.
Para salvar o arquivo, selecione Ctrl+X, insira Y e selecione Enter.
Enviar e gerenciar o trabalho
As etapas a seguir usam o comando Oozie para enviar e gerenciar fluxos de trabalho do Oozie no cluster. O comando do Oozie é uma interface amigável sobre a API REST do Oozie.
Importante
Ao usar o comando Oozie, você deverá usar o FQDN para o nó de cabeçalho do HDInsight. Esse FQDN só está acessível no cluster ou, se o cluster estiver em uma rede virtual do Azure, de outros computadores na mesma rede.
Para obter a URL para o serviço Oozie, use o seguinte comando:
sed -n '/<name>oozie.base.url/,/<\/value>/p' /etc/oozie/conf/oozie-site.xmlIsso retorna informações semelhantes ao seguinte XML:
<name>oozie.base.url</name> <value>http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozie</value>A parte
http://ACTIVE-HEADNODE-NAME.UNIQUEID.cx.internal.cloudapp.net:11000/oozieé a URL a ser usada com o comando do Oozie.Edite o código para substituir a URL por aquela que você recebeu antes. Para criar uma variável de ambiente para a URL, use o seguinte para não precisar digitá-la a cada comando:
export OOZIE_URL=http://HOSTNAMEt:11000/ooziePara enviar o trabalho, use o seguinte código:
oozie job -config job.xml -submitEsse comando carrega as informações do trabalho de
job.xmle as envia para o Oozie, mas não executa.Depois que o comando é concluído, ele deve retornar a ID do trabalho, por exemplo,
0000005-150622124850154-oozie-oozi-W. Essa ID será usada para gerenciar o trabalho.Edite o código abaixo para substituir
<JOBID>pela ID retornada na etapa anterior. Para exibir o status do trabalho, use o seguinte comando:oozie job -info <JOBID>Isso retorna informações semelhantes ao seguinte texto:
Job ID : 0000005-150622124850154-oozie-oozi-W ------------------------------------------------------------------------------------------------------------------------------------ Workflow Name : useooziewf App Path : wasb:///tutorials/useoozie Status : PREP Run : 0 User : USERNAME Group : - Created : 2015-06-22 15:06 GMT Started : - Last Modified : 2015-06-22 15:06 GMT Ended : - CoordAction ID: - ------------------------------------------------------------------------------------------------------------------------------------Este trabalho tem o status
PREP. Este status indica que o trabalho foi criado, mas não foi iniciado.Edite o código abaixo para substituir
<JOBID>pela ID retornada na anteriormente. Para iniciar o trabalho, use o seguinte comando:oozie job -start <JOBID>Se você verificar o status após o comando, ele estará em um estado de execução e as informações serão retornadas para as ações dentro do trabalho. O trabalho levará alguns minutos para ser concluído.
Edite o código abaixo para substituir
<serverName>pelo nome do servidor e<sqlLogin>pelo logon do servidor. Depois que a tarefa for concluída com sucesso, você poderá verificar se os dados foram gerados e exportados para a tabela do Banco de Dados SQL usando o seguinte comando. Insira a senha no prompt.TDSVER=8.0 tsql -H <serverName>.database.windows.net -U <sqlLogin> -p 1433 -D oozietestNo prompt
1>, insira a seguinte consulta:SELECT * FROM mobiledata GOAs informações retornadas são semelhantes ao seguinte texto:
deviceplatform count Android 31591 iPhone OS 22731 proprietary development 3 RIM OS 3464 Unknown 213 Windows Phone 1791 (6 rows affected)
Para obter mais informações sobre o comando do Oozie, consulte Ferramenta de linha de comando do Apache Oozie.
API REST do Oozie
Com a API REST do Oozie, você pode criar suas próprias ferramentas que funcionem com Oozie. As informações abaixo são específicas do HDInsight sobre como usar a API REST do Oozie:
URI: você pode acessar a API REST de fora do cluster em
https://CLUSTERNAME.azurehdinsight.net/oozie.Autenticação: para fazer a autenticação, use a API com a conta (administrador) e a senha do cluster HTTP. Por exemplo:
curl -u admin:PASSWORD https://CLUSTERNAME.azurehdinsight.net/oozie/versions
Para saber mais sobre como usar a API REST do Oozie, consulte API de Serviços do Apache Oozie Web.
Interface do usuário da Web do Oozie
A IU da Web do Oozie fornece um modo de exibição baseado na web sobre o status dos trabalhos do Oozie no cluster. Com a interface do usuário da Web, você pode exibir as seguintes informações:
- Status do trabalho
- Definição de trabalho
- Configuração
- Um grafo das ações no trabalho
- Logs do trabalho
Você também pode exibir detalhes de ações dentro de um trabalho.
Para acessar a interface do usuário do Oozie da Web, conclua as seguintes etapas:
Crie um túnel SSH para o cluster HDInsight. Para obter mais informações, consulte Usar túnel SSH com o HDInsight.
Depois de criar um túnel, abra a interface do usuário da Web do Ambari no navegador da Web usando a URI
http://headnodehost:8080.No lado esquerdo da página, selecione Oozie>Links Rápidos>IU da Web do Oozie.
A interface do usuário da Web do Oozie assume como padrão a exibição de trabalhos do fluxo de trabalho em execução. Para ver todos os trabalhos de fluxo de trabalho, selecione Todos os trabalhos.
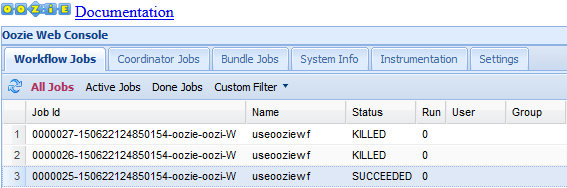
Selecione um trabalho para exibir mais informações sobre ele.
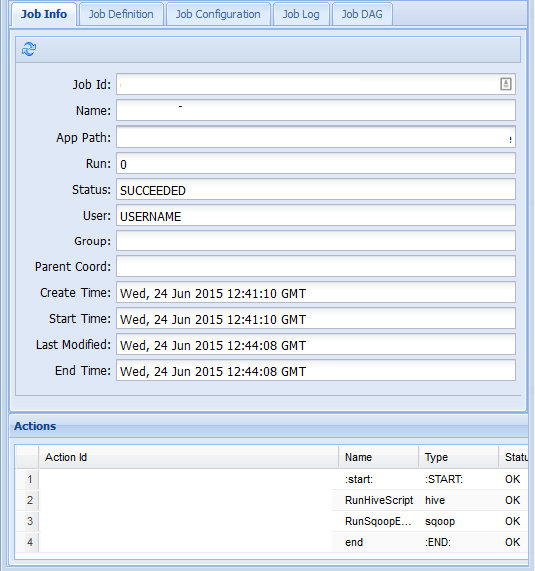
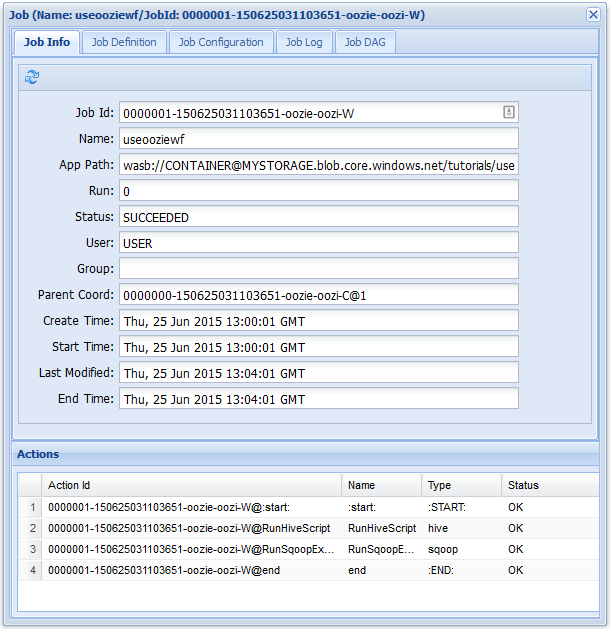
Na guia Informações do Trabalho, veja informações básicas sobre o trabalho, bem como as ações individuais dentro do trabalho. Você pode usar as guias na parte superior para exibir a Definição de Trabalho, a Configuração de Trabalho, acessar o Log de Trabalho ou ver um DAG (grafo direcionado acíclico) do trabalho em DAG do Trabalho.
Log de Trabalhos: selecione o botão Obter Logs para obter todos os logs do trabalho ou use o campo
Enter Search Filterpara filtrar os logs.
DAG do Trabalho: o DAG é uma visão geral gráfica dos caminhos de dados percorridos pelo fluxo de trabalho.
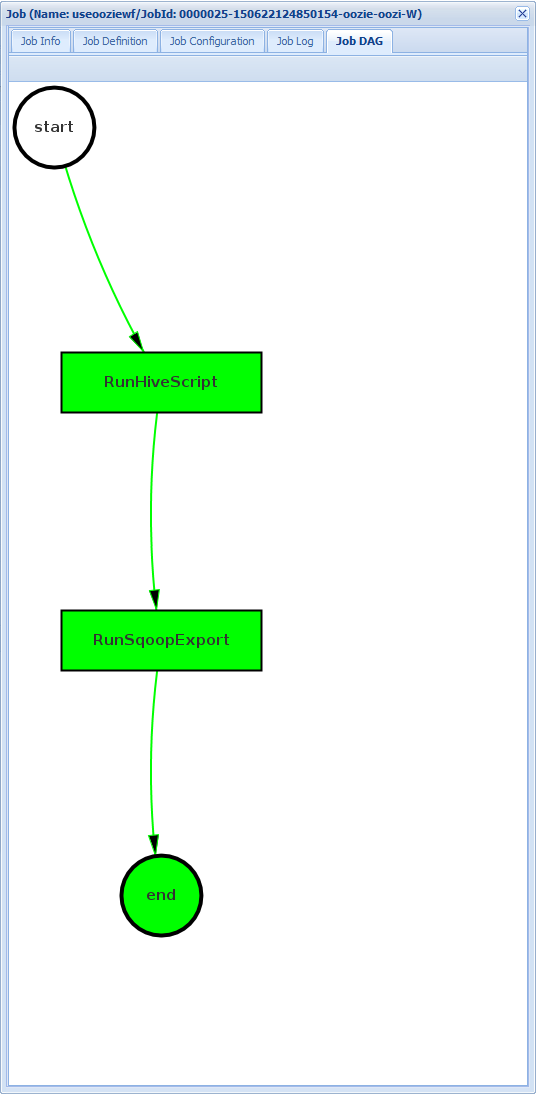
Se você selecionar uma das ações na guia Informações do Trabalho, ela exibirá informações para a ação. Por exemplo, selecione a ação RunSqoopExport.
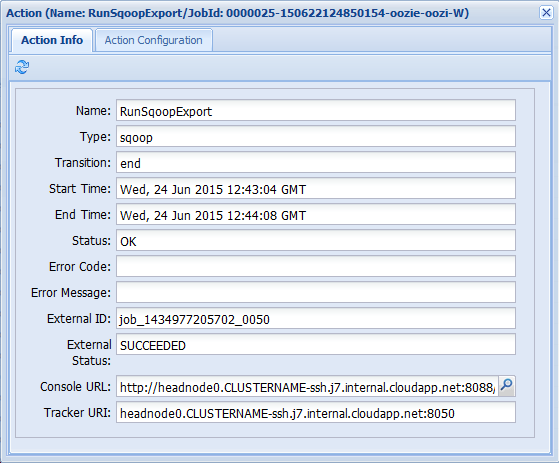
Você pode ver detalhes da ação, como um link para a URL do Console. Use este link para exibir informações do rastreador de trabalho para o trabalho.
Agendar trabalhos
Você pode usar o coordenador para especificar um início, um fim e a frequência da ocorrência dos trabalhos. Para definir uma agenda para o fluxo de trabalho, conclusa as seguintes etapas:
Use o seguinte comando para criar um arquivo chamado coordinator.xml:
nano coordinator.xmlUse o seguinte XML como o conteúdo do arquivo:
<coordinator-app name="my_coord_app" frequency="${coordFrequency}" start="${coordStart}" end="${coordEnd}" timezone="${coordTimezone}" xmlns="uri:oozie:coordinator:0.4"> <action> <workflow> <app-path>${workflowPath}</app-path> </workflow> </action> </coordinator-app>Observação
As variáveis
${...}são substituídas por valores na definição de trabalho no runtime. As variáveis são:${coordFrequency}: o tempo entre as instâncias do trabalho em execução.${coordStart}: a hora de início do trabalho.${coordEnd}: a hora de término do trabalho.${coordTimezone}: os trabalhos do coordenador estão em um fuso horário fixo sem horário de verão, geralmente representado com o uso do UTC. Esse fuso horário é chamado de fuso horário de processamento do Oozie.${wfPath}: o caminho para workflow.xml.
Para salvar o arquivo, selecione Ctrl+X, insira Y e selecione Enter.
Para copiar o arquivo para o diretório de trabalho para este trabalho, use o seguinte comando:
hadoop fs -put coordinator.xml /tutorials/useoozie/coordinator.xmlPara modificar o arquivo
job.xmlcriado antes, use o seguinte comando:nano job.xmlFaça as seguintes alterações:
Para instruir o Oozie a executar o arquivo coordenador em vez do de fluxo de trabalho, altere
<name>oozie.wf.application.path</name>para<name>oozie.coord.application.path</name>.Para definir o
workflowPathvariável usada pelo coordenador, adicione o XML a seguir:<property> <name>workflowPath</name> <value>wasbs://mycontainer@mystorageaccount.blob.core.windows.net/tutorials/useoozie</value> </property>Substitua o texto
wasbs://mycontainer@mystorageaccount.blob.core.windowspelo valor usado nas outras entradas no arquivo job.xml.Para definir o início, o fim e a frequência a usar para o coordenador, adicione o XML a seguir:
<property> <name>coordStart</name> <value>2018-05-10T12:00Z</value> </property> <property> <name>coordEnd</name> <value>2018-05-12T12:00Z</value> </property> <property> <name>coordFrequency</name> <value>1440</value> </property> <property> <name>coordTimezone</name> <value>UTC</value> </property>Esses valores definem a hora de início como 12h00 em 10 de maio de 2018 e a hora de término como 12 de maio de 2018. O intervalo para execução desse trabalho é definido como diário. A frequência está em minutos, então 24 horas x 60 minutos = 1440 minutos. Por fim, o fuso horário é definido como UTC.
Para salvar o arquivo, selecione Ctrl+X, insira Y e selecione Enter.
Para iniciar o trabalho, use o seguinte comando:
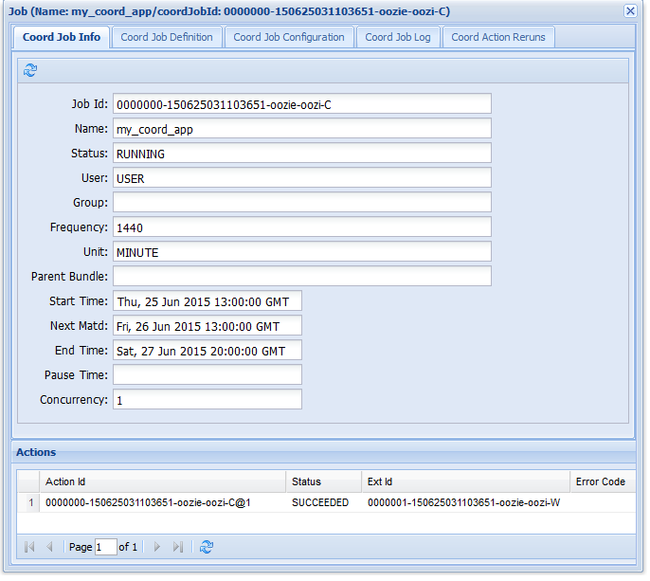
oozie job -config job.xml -runSe você acessar a interface do usuário da Web do Oozie e selecionar a guia Trabalhos do Coordenador, verá informações semelhantes à seguinte imagem:

A entrada Próxima Materialização contém a próxima hora em que o trabalho é executado.
De forma semelhante ao fluxo de trabalho anterior, se você selecionar a entrada de trabalho na interface do usuário da Web, ela exibirá informações sobre o trabalho:
Observação
Essa imagem mostra apenas as execuções bem-sucedidas do trabalho, não as ações individuais do fluxo de trabalho agendado. Para ver as ações individuais, selecione uma das entradas em Ação.
Próximas etapas
Neste artigo, você aprendeu a definir um fluxo de trabalho do Oozie e a executar um trabalho do Oozie. Para saber mais sobre como trabalhar com o HDInsight, consulte os seguintes artigos: