Falha na depuração do trabalho do Spark com o Azure Toolkit for IntelliJ (versão prévia)
Este artigo contém orientações passo a passo para usar as Ferramentas do HDInsight no Azure Toolkit for IntelliJ para executar aplicativos de depuração de falha do Spark.
Pré-requisitos
Kit de desenvolvimento Oracle Java. Este tutorial usa o Java versão 8.0.202.
IntelliJ IDEA. Este artigo usa o IntelliJ IDEA Community 2019.1.3.
Azure Toolkit for IntelliJ. Confira Installing the Azure Toolkit for IntelliJ (Instalação do Azure Toolkit for IntelliJ).
Conectar-se ao cluster do HDInsight. Confira Conectar-se ao cluster do HDInsight.
Gerenciador de Armazenamento do Microsoft Azure. Confira Baixar o Gerenciador de Armazenamento do Microsoft Azure.
Criar um projeto com modelo de depuração
Crie um projeto do Spark 2.3.2 para continuar a depuração de falha. Escolha o arquivo de exemplo de depuração de tarefa de falha neste documento.
Abra o IntelliJ IDEA. Abra a janela Novo Projeto.
a. Selecione Azure Spark/HDInsight no painel esquerdo.
b. Selecione Projeto do Spark com Amostra de Depuração de Tarefa de Falha (Versão Prévia) (Scala) na janela principal.
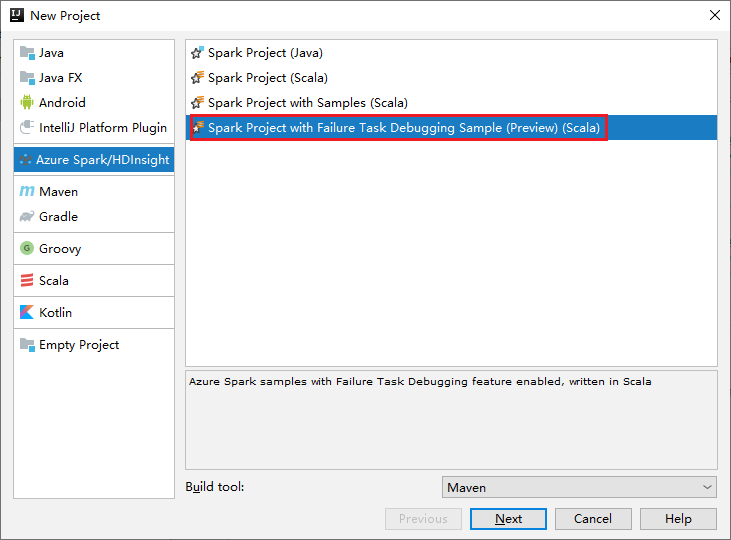
c. Selecione Avançar.
Na janela Novo Projeto, execute as seguintes etapas:
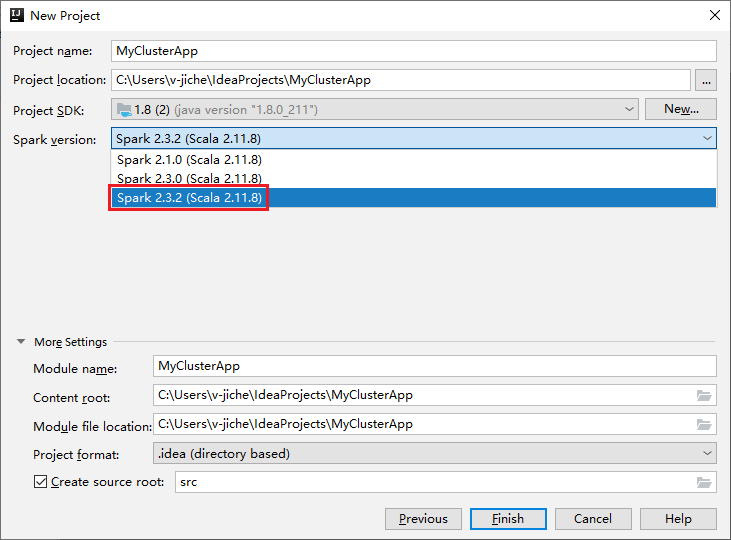
a. Insira um nome de projeto e o local do projeto.
b. Na lista suspensa SDK do Projeto, selecione Java 1.8 para o cluster do Spark 2.3.2.
c. Na lista suspensa Versão do Spark, selecione Spark 2.3.2 (escala 2.11.8) .
d. Selecione Concluir.
Selecione src>main>scala para abrir seu código no projeto. Este exemplo usa o script AgeMean_Div() .
Executar um aplicativo Scala/Java do Spark em um cluster do HDInsight
Siga as etapas abaixo para criar um aplicativo Scala/Java e executá-lo em um cluster do Spark:
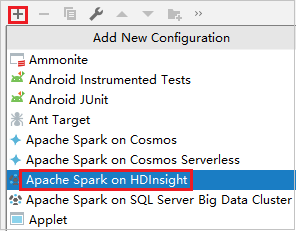
Clique em Adicionar Configuração para abrir a janela Executar/Depurar Configurações.

Na caixa de diálogo Configurações de Execução/Depuração, selecione o sinal de mais (+). Em seguida, selecione a opção Apache Spark no HDInsight.
Alterne para a guia Executar Remotamente no Cluster. Insira as informações de Nome, Cluster do Spark e Nome da classe principal. Nossas ferramentas oferecem suporte à depuração com Executores. O numExecutors, o valor padrão é 5, e é melhor não definir mais do que 3. Para reduzir o tempo de execução, você pode adicionar spark.yarn.maxAppAttempts às Configurações de trabalho e definir o valor como 1. Clique no botão OK para salvar a configuração.
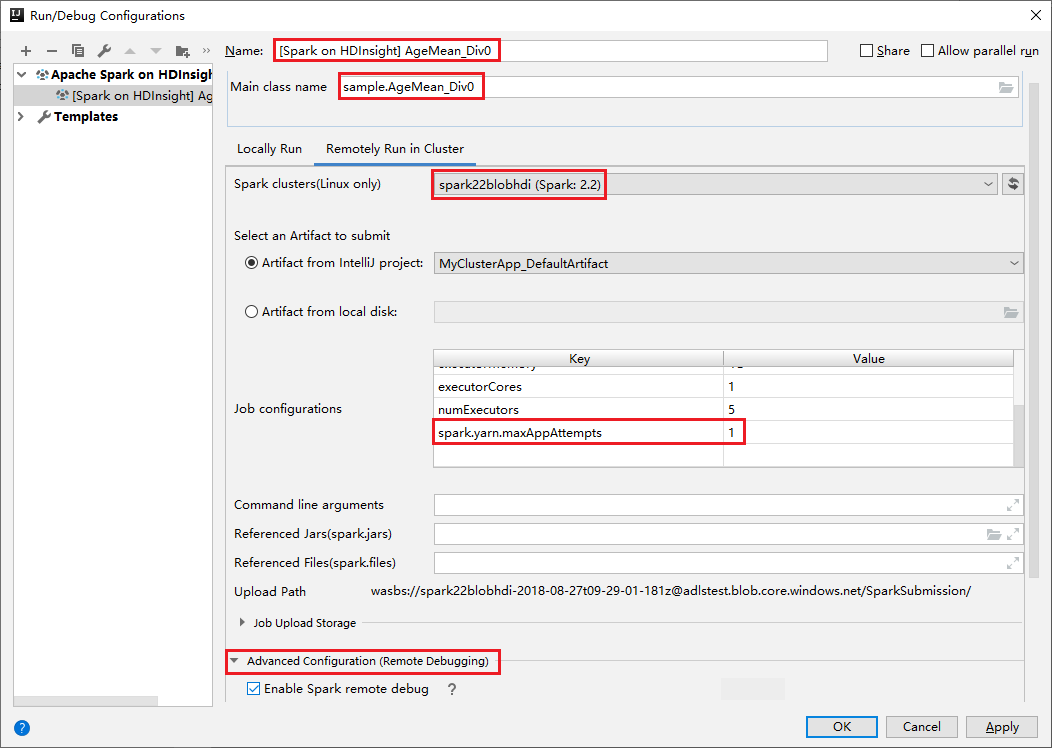
Agora, a configuração está salva com o nome fornecido. Para exibir os detalhes de configuração, selecione o nome da configuração. Para fazer alterações, selecione Editar configurações.
Após concluir as definições de configurações, você poderá executar o projeto no cluster remoto.

Você pode verificar a ID do aplicativo na janela de saída.

Baixar perfil de trabalho com falha
Se o envio do trabalho falhar, você poderá baixar o perfil de trabalho com falha no computador local para depuração posterior.
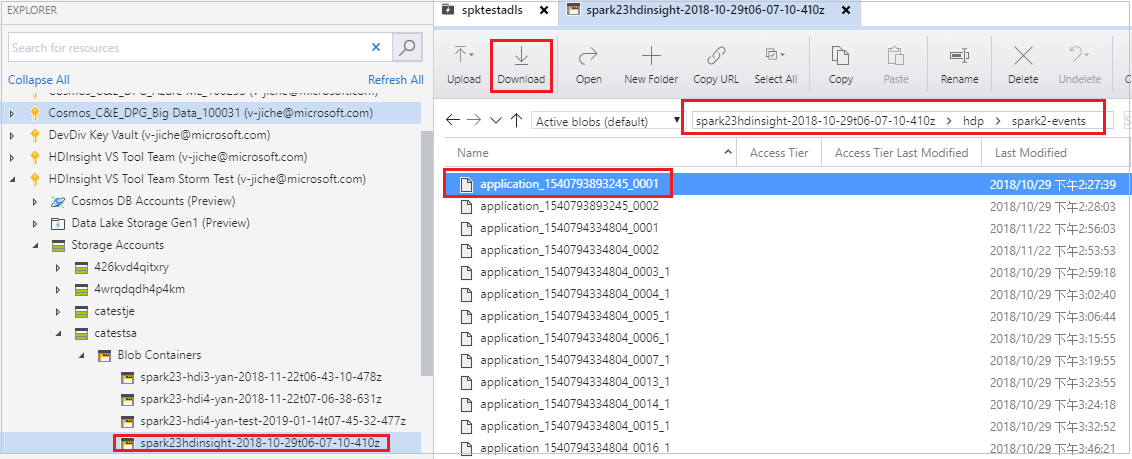
Abra Gerenciador de Armazenamento do Microsoft Azure, localize a conta do HDInsight do cluster do trabalho com falha, baixe os recursos de trabalho com falha do local correspondente: \hdp\spark2-events\.spark-failures\<application ID> para uma pasta local. A janela atividades mostrará o progresso do download.
Configurar o ambiente de depuração local e depurar em caso de falha
Abra o projeto original ou crie um projeto e associe-o ao código-fonte original. Somente a versão do Spark 2.3.2 é compatível com a depuração de falha no momento.
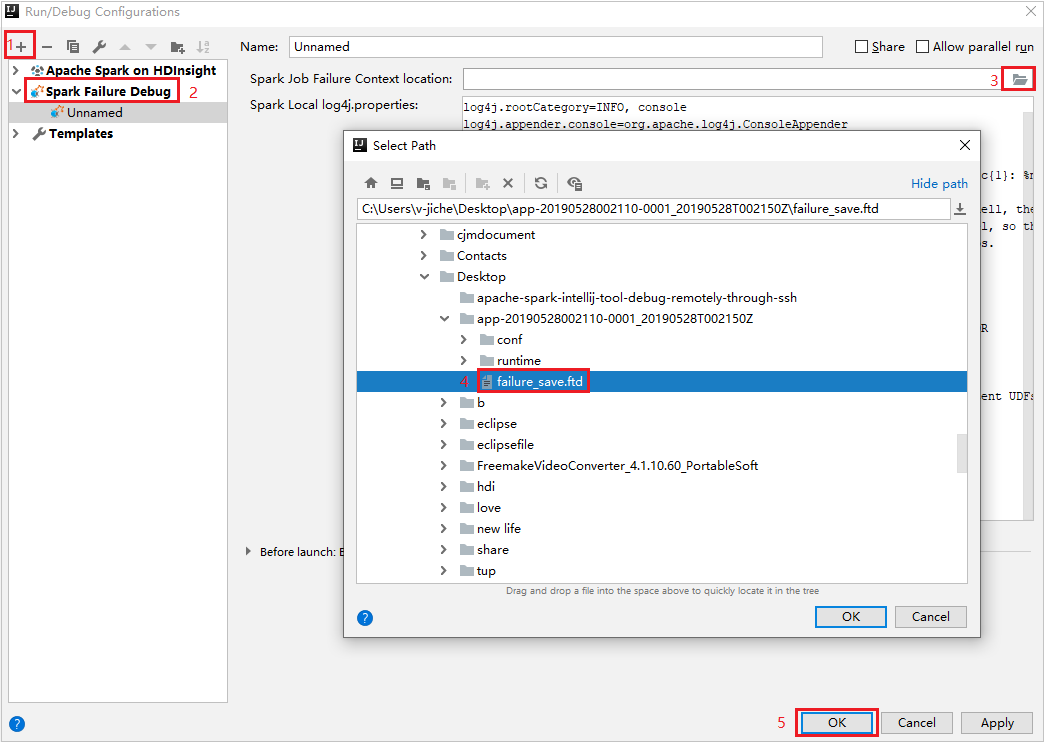
No IntelliJ IDEA, crie um arquivo de configuração de Depuração de Falha do Spark, selecione o arquivo FTD nos recursos de trabalho com falha baixados anteriormente para o campo Local de Contexto de Falha de Trabalho do Spark.
Clique no botão executar local na barra de ferramentas, e o erro será exibido na janela Executar.
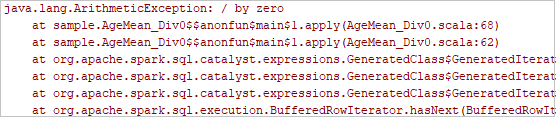
Defina o ponto de interrupção como o log indica e, em seguida, clique no botão de depuração local para fazer a depuração local, assim como seus projetos Scala/Java normais no IntelliJ.
Após a depuração, se o projeto for concluído com êxito, você poderá reabrir o trabalho com falha do Spark no cluster do HDInsight.
Próximas etapas
Cenários
- Apache Spark com BI: realize a análise interativa de dados usando o Spark no HDInsight com ferramentas de BI
- Apache Spark com Machine Learning: use o Spark no HDInsight para analisar a temperatura do edifício usando dados de HVAC
- Apache Spark com Machine Learning: use o Spark no HDInsight para prever os resultados da inspeção de alimentos
- Análise de log do site usando o Apache Spark no HDInsight
Criar e executar aplicativos
- Criar um aplicativo autônomo usando Scala
- Execute trabalhos remotamente em um cluster do Apache Spark usando o Apache Livy
Ferramentas e extensões
- Use o Azure Toolkit for IntelliJ para criar aplicativos do Apache Spark para um cluster do HDInsight
- Use o Azure Toolkit for IntelliJ para depurar aplicativos Apache Spark remotamente por meio de VPN
- Use as ferramentas do HDInsight no Azure Toolkit for Eclipse para criar aplicativos do Apache Spark
- Use os blocos de anotações do Apache Zeppelin com um cluster do Apache Spark no HDInsight
- Kernels disponíveis para o Jupyter Notebook no cluster do Apache Spark para HDInsight
- Usar pacotes externos com Jupyter Notebooks
- Instalar o Jupyter em seu computador e conectar-se a um cluster Spark do HDInsight