Alta disponibilidade e recuperação de desastres do Hub IoT
Como primeiro passo para implementar uma solução de IoT resiliente, os arquitetos, desenvolvedores e proprietários de negócios devem definir as metas de tempo de atividade das soluções que estão criando. Essas metas podem ser definidas principalmente com base em objetivos de negócios específicos para cada cenário. Neste contexto, o artigo Orientação Técnica de Continuidade de Negócios do Azure descreve uma estrutura geral para ajudá-lo a pensar em continuidade de negócios e recuperação de desastres. O documento Recuperação de desastre e alta disponibilidade para aplicativos do Azure fornece diretrizes de arquitetura sobre estratégias para que os aplicativos do Azure consigam alta disponibilidade (HA) e recuperação de desastres (DR).
Este artigo descreve os recursos de HA e DR oferecidos especificamente pelo serviço IoT Hub. As grandes áreas discutidas neste artigo são:
- HA entre regiões
- Recuperação de desastres de região cruzada
- Alcançar a região cruzada HA
Dependendo das metas de tempo de atividade definidas para suas soluções de IoT, você deve determinar quais das opções descritas neste artigo são mais adequadas aos seus objetivos de negócios. Incorporar qualquer uma dessas alternativas de HA / DR à sua solução de IoT requer uma avaliação cuidadosa dos trade-offs entre:
- Nível de resiliência que você precisa
- Complexidade de implementação e manutenção
- Impacto de COGS
HA entre regiões
O serviço Hub IoT fornece HA intra-região implementando redundâncias em quase todas as camadas do serviço. O SLA publicado pelo serviço IoT Hub é obtido com o uso dessas redundâncias. Nenhum trabalho adicional é exigido pelos desenvolvedores de uma solução de IoT para aproveitar esses recursos de alta disponibilidade. Embora o IoT Hub ofereça uma garantia razoavelmente alta de tempo de atividade, falhas transitórias ainda podem ser esperadas como em qualquer plataforma de computação distribuída. Se você está apenas começando a migrar suas soluções para a nuvem a partir de uma solução local, seu foco precisa mudar de "tempo médio entre falhas" para "tempo médio para recuperação". Em outras palavras, falhas transitórias devem ser consideradas normais durante a operação com a nuvem no mix. Os padrões de repetição adequados devem ser incorporados aos componentes que interagem com um aplicativo em nuvem para lidar com falhas transitórias.
Zonas de disponibilidade
O Hub IoT também dá suporte a Zonas de disponibilidade do Azure. Uma zona de disponibilidade é uma oferta de alta disponibilidade que protege aplicativos e dados contra falhas de datacenter. Uma região com suporte à zona de disponibilidade é composta de três zonas com suporte a essa região. Cada zona fornece um ou mais datacenters um em um local físico exclusivo com energia, resfriamento e rede independentes. Essa configuração fornece replicação e redundância dentro da região.
As zonas de disponibilidade oferecem duas vantagens: resiliência de dados e implantações mais tranquilas.
A resiliência de dados vem da substituição dos serviços de armazenamento subjacentes pelo armazenamento com suporte de zonas de disponibilidade. A resiliência de dados é importante para soluções de IoT porque essas soluções geralmente operam em ambientes complexos, dinâmicos e incertos, onde falhas ou interrupções podem ter consequências significativas. Se uma solução de IoT oferece suporte a um chão de fábrica, ambientes de varejo ou restaurantes, sistemas de saúde ou infraestruturas, a disponibilidade e a qualidade dos dados são necessárias para se recuperar de falhas e fornecer serviços confiáveis e consistentes.
As implantações mais tranquilas vêm da substituição do hardware de data center subjacente por um hardware mais recente que oferece suporte a zonas de disponibilidade. Essas melhorias de hardware minimizam o impacto causado ao cliente por desconexões e reconexões de dispositivos, bem como outras questões de tempo de inatividade relacionadas à implantação. A equipe de engenharia do Hub IoT implanta várias atualizações em cada hub IoT todos os meses, tanto por motivos de segurança quanto para oferecer melhorias nos recursos. O hardware com suporte para zonas de disponibilidade é dividido em 15 domínios de atualização. Dessa forma, cada atualização fica mais tranquila, com impacto mínimo nos fluxos de trabalho. Para obter mais informações sobre domínios de atualização, confira Conjuntos de disponibilidade.
O suporte à zona de disponibilidade para o Hub IoT é habilitado automaticamente para novos recursos do Hub IoT criados nas seguintes regiões do Azure:
| Região | Resiliência de dados | Implantações mais tranquilas |
|---|---|---|
| Leste da Austrália | ||
| Brazil South | ||
| Canadá Central | ||
| Índia Central | ||
| Centro dos EUA | ||
| Leste dos EUA | ||
| França Central | ||
| Centro-Oeste da Alemanha | ||
| Leste do Japão | ||
| Coreia Central | ||
| Norte da Europa | ||
| Leste da Noruega | ||
| Catar Central | ||
| Centro-Sul dos EUA | ||
| Sudeste Asiático | ||
| Sul do Reino Unido | ||
| Europa Ocidental | ||
| Oeste dos EUA 2 | ||
| Oeste dos EUA 3 |
Recuperação de desastres de região cruzada
Pode haver algumas situações raras em que um datacenter experimenta interrupções prolongadas devido a falhas de energia ou outras falhas envolvendo ativos físicos. Tais eventos são raros durante os quais a capacidade de HA da região intra descrita anteriormente nem sempre ajuda. O Hub IoT fornece várias soluções para recuperar-se de interrupções prolongadas.
As opções de recuperação disponíveis para clientes nessa situação são failover iniciado pela Microsof e failover manual. A diferença fundamental entre os dois é que a Microsoft inicia a primeira e o usuário inicia a segunda. Além disso, o failover manual fornece um menor objetivo tempo de recuperação (RTO) em comparação comparado a opção de failover iniciado pelo Microsoft. Os RTOs específicos oferecidos com cada opção são discutidos nas seções a seguir. Quando qualquer uma dessas opções para executar o failover de um hub de IoT de sua região primária for exercida, o hub se tornará totalmente funcional na região correspondente do Azure emparelhada geograficamente.
Ambas as opções de failover oferecem os seguintes objetivos de ponto de recuperação (RPOs):
| Tipo de dados | Objetivos do ponto de recuperação (RPO) |
|---|---|
| Registro de identidade | Perda de dados de 0 a 5 minutos |
| Dados do dispositivo gêmeo | Perda de dados de 0 a 5 minutos |
| Mensagens da nuvem para dispositivo1 | Perda de dados de 0 a 5 minutos |
| Pai1 e trabalhos do dispositivo | Perda de dados de 0 a 5 minutos |
| Mensagens do dispositivo para a nuvem | Todas as mensagens não lidas são perdidas |
| Mensagens de feedback da nuvem para o dispositivo | Todas as mensagens não lidas são perdidas |
1 As mensagens da nuvem para dispositivo e os trabalhos pai não são recuperados como parte do failover manual.
Depois que a operação de failover do hub IoT for concluída, espera-se que todas as operações do dispositivo e dos aplicativos de back-end continuem funcionando sem exigir uma intervenção manual. Isso significa que as mensagens do dispositivo para nuvem devem continuar funcionando e todo o registro do dispositivo está intacto. Os eventos emitidos via Grade de Eventos podem ser consumidos por meio da(s) mesma(s) assinatura(s) configurada(s) anteriormente, contanto que essas assinaturas da Grade de Eventos continuem disponíveis. Nenhum tratamento adicional é necessário para pontos de extremidade personalizados.
Cuidado
- O nome e o ponto de extremidade compatível com os Hubs de Eventos do ponto de extremidade de eventos internos do Hub IoT são alterados após o failover. Ao receber mensagens de telemetria do terminal interno usando o host dos Hubs de Eventos ou do processador de eventos, você deve usar a cadeia de conexão de hub IoT para estabelecer a conexão. Isso garante que seus aplicativos de back-end continuem a funcionar sem exigir o failover de pós-intervenção manual. Se você usar o nome e o ponto de extremidade compatíveis com o Hub de Eventos no seu aplicativo de back-end diretamente, busque o novo nome e ponto de extremidade compatíveis com o Hub de Eventos após o failover para continuar as operações. Para saber mais, veja Failover manual e hub de eventos.
- Se você usar Azure Functions ou Azure Stream Analytics para conectar o ponto de extremidade interno de Eventos, talvez seja necessário executar uma Reinicialização. Isso é porque, durante o failover, os deslocamentos anteriores não são mais válidos.
- Ao rotear para o armazenamento, é recomendável listar os blobs ou arquivos e iterar sobre eles, para garantir que todos os blobs ou arquivos sejam lidos sem fazer nenhuma suposição de partição. O intervalo de partição potencialmente pode ser alterado durante um failover iniciado pela Microsoft ou um failover manual. Você pode usar Listar API de blobs para enumerar a lista de blobs ou Listar API de ADLS Gen2 para ver a lista de arquivos. Para saber mais, confira Armazenamento do Microsoft Azure como um ponto de extremidade de roteamento.
Failover iniciado pelo Microsoft
Failover iniciado pelo Microsoft seja utilizado pela Microsoft em raras situações de failover a IoT todos os hubs de uma região afetada à região geográfica emparelhada correspondente. Este processo é uma opção padrão e não requer intervenção do usuário. A Microsoft se reserva o direito de determinar quando essa opção será exercida. Esse mecanismo não envolve o consentimento do usuário antes do failover do hub do usuário. Failover iniciado pelo Microsoft tem um objetivo de tempo de recuperação (RTO) de 2 a 26 horas.
O grande RTO é porque a Microsoft deve executar a operação de failover em nome de todos os clientes afetados nessa região. Se você estiver executando uma solução de IoT menos importante que possa manter um tempo de inatividade de aproximadamente um dia, não há problema em você depender dessa opção para satisfazer as metas gerais de recuperação de desastre da sua solução de IoT. O tempo total para operações de runtime se tornarem totalmente operacionais depois que esse processo é acionado é descrito na seção "Tempo para recuperação".
Somente os usuários que estão implantando hubs IoT nas regiões Sul do Brasil e Sudeste da Ásia (Singapura) podem recusar esse recurso. Para obter mais informações, consulte Desabilitar recuperação de desastre.
Observação
O Hub IoT do Azure não armazena nem processa dados do cliente fora da geografia em que você implanta a instância de serviço. Para saber mais, confira Replicação entre regiões no Azure.
Failover manual
Se as suas metas de tempo de atividade de negócios não forem atendidas pelo RTO fornecido pelo failover iniciado pela Microsoft, considere usar o failover manual para acionar o processo de failover sozinho. O RTO usando essa opção pode estar entre 10 minutos a algumas horas. O RTO é atualmente uma função do número de dispositivos registrados em relação à instância do hub IoT com failover. Você pode esperar que o RTO para um hub que hospede aproximadamente 100.000 dispositivos seja de 15 minutos. O tempo total para operações de runtime se tornarem totalmente operacionais depois que esse processo é acionado é descrito na seção "Tempo para recuperação".
A opção de failover manual está sempre disponível para uso, independentemente de a região principal estar com tempo de inatividade ou não. Portanto, essa opção poderia ser usada para realizar failovers planejados. Um exemplo de uso de failovers planejados é executar exercícios de failover periódicos. Uma palavra de cautela é que uma operação de failover planejada resulta em um tempo de inatividade para o hub para o período definido pelo RTO para essa opção e também resulta em uma perda de dados, conforme definido pela tabela de RPO acima. Você pode considerar a configuração de uma instância de hub de IoT de teste para exercer a opção de failover planejada periodicamente para ganhar confiança em sua capacidade de obter suas soluções de ponta a ponta funcionando quando ocorre um desastre real.
O failover manual é disponibilizado sem custo adicional para os hubs IoT criados após 18 de maio de 2017
Para obter as instruções passo a passo, consulte Tutorial: Executar failover manual para um hub IoT
Failover manual e Hubs de Eventos
O nome e o ponto de extremidade compatível com os Hubs de Eventos do ponto de extremidade de eventos internos do Hub IoT são alterados após o failover manual. Isso ocorre porque o cliente dos Hubs de Eventos não tem visibilidade dos eventos do Hub IoT. O mesmo vale para outros clientes baseados em nuvem, como o Functions e o Azure Stream Analytics. Para recuperar o ponto de extremidade e o nome, você pode usar o portal do Azure ou a SDK do .NET.
Usar o portal
Para saber mais sobre como usar o portal para recuperar o ponto de extremidade e o nome compatíveis com o Hub de Eventos, consulte Conectar-se ao ponto de extremidade interno.
Usar o SDK .NET
Para usar a cadeia de conexão do Hub IoT para recapturar o ponto de extremidade compatível com os Hubs de Eventos, use um exemplo localizado em https://github.com/Azure/azure-sdk-for-net/tree/main/samples/iothub-connect-to-eventhubs. O exemplo de código usa a cadeia de conexão para obter o novo ponto de extremidade dos Hubs de Eventos e restabelecer a conexão. Você deve ter o Visual Studio instalado.
Executar exercícios de teste
Os exercícios de teste não devem ser executados em hubs de IoT que estão sendo usados em seus ambientes de produção.
Não use o failover manual para migrar o Hub IoT para uma região diferente
O failover manual não deve ser usado como um mecanismo para migrar permanentemente seu hub entre as regiões do Azure emparelhadas geograficamente. Supondo que os dispositivos estavam localizados mais próximos da região primária do hub, a latência para operações que estão sendo executadas no hub IoT aumentará quando o hub fizer failover para uma região secundária.
Failback
Você pode fazer failback para a região primária antiga disparando a ação de failover uma segunda vez. Se a operação de failover original foi executada para recuperar de uma interrupção estendida na região primária original, recomendamos que o hub seja reprovado para o local original depois que esse local tiver se recuperado da situação de interrupção.
Importante
- Os usuários só podem executar 2 failover bem-sucedido e 2 operações de failback bem-sucedidas por dia.
- As operações de failover / failback de volta para trás não são permitidas. Você deve aguardar 1 hora entre essas operações.
Tempo de recuperação
Enquanto o FQDN (e, portanto, a cadeia de conexão) da instância do hub IoT permanecem inalterados após o failover, o endereço IP subjacente é alterado. O tempo para as operações de runtime que está sendo executada em relação a sua instância do hub IoT para se tornar totalmente operacional depois que o processo de failover pode ser expresso usando a função a seguir:
Tempo para recuperar = RTO [10 min - 2 horas para failover manual | 2 a 26 horas para failover iniciado pela Microsoft] + atraso de propagação de DNS + tempo gasto pelo aplicativo cliente para atualizar qualquer endereço IP do IoT Hub armazenado em cache.
Importante
Os SDKs da IoT não armazenam em cache o endereço IP do hub IoT. Recomendamos que a interface de código de usuário com os SDKs não armazene em cache o endereço IP do hub IoT.
Desabilitar a recuperação de desastre
O Hub IoT fornece failover iniciado pela Microsoft e failover manual e failover manual, replicando dados para a região emparelhada para cada hub IoT. Para algumas regiões, você pode evitar a replicação de dados fora da região desabilitando a recuperação de desastre ao criar um Hub IoT. As seguintes regiões têm suporte a esse recurso:
- Sul do Brasil; região emparelhada, Centro-Sul dos EUA.
- Sudeste da Ásia (Singapura); região emparelhada, Leste da Ásia (RAE de Hong Kong).
Para desabilitar a recuperação de desastre em regiões com suporte, certifique-se de que a recuperação de desastre habilitada não seja eleita quando você criar o hub IoT:
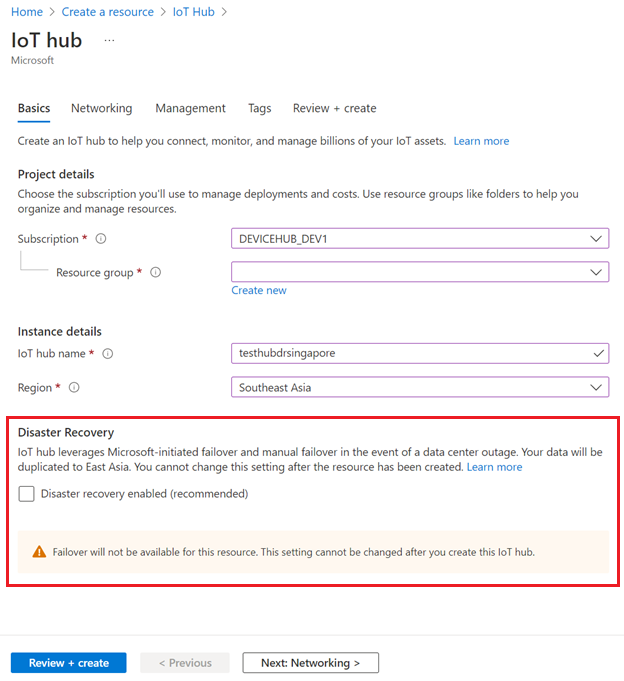
Você também pode desabilitar a recuperação de desastre ao criar um hub IoT usando um modelo do ARM.
A funcionalidade de failover não estará disponível se você desabilitar a recuperação de desastre para um hub IoT.
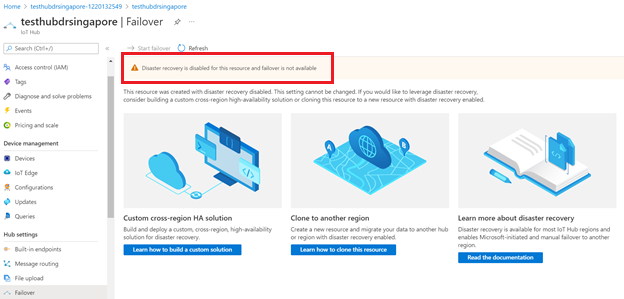
Você só pode desabilitar a recuperação de desastre para evitar a replicação de dados fora da região emparelhada no Sul do Brasil ou Sudeste da Ásia ao criar um hub IoT. Se você quiser configurar seu hub IoT existente para desabilitar a recuperação de desastre, será necessário criar um novo hub IoT com a recuperação de desastre desabilitada e migrar manualmente o hub IoT existente. Para obter as diretrizes, consulte Como fazer para migrar um hub IoT.
Alcance a região cruzada HA
Se suas metas de tempo de atividade de negócios não forem atendidas pelo RTO que as opções de failover manual ou de failover iniciadas pela Microsoft fornecem, você deve considerar a implementação de um mecanismo de failover de região cruzada automático por dispositivo. Um tratamento completo das topologias de implantação em soluções de IoT está fora do escopo deste artigo. O artigo discute o modelo de implantação de failover regional para alta disponibilidade e recuperação de desastres.
Em um modelo de failover regional, o back-end da solução é executado primariamente em um local de datacenter. Um hub IoT secundário e o back-end são implantadas em outro local do datacenter. Se o hub IoT na região primária sofrer uma interrupção ou a conectividade de rede do dispositivo para a região principal for interrompida, os dispositivos usarão um ponto de extremidade de serviço secundário. Você pode melhorar a disponibilidade da solução com a implementação de um modelo de failover entre regiões, em vez de manter-se dentro de uma única região.
Em um nível alto, para implementar um modelo de failover regional com o Hub IoT, você precisa seguir os seguintes passos:
Uma lógica de roteamento de dispositivo e Hub IoT secundário: se o serviço na sua região primária for interrompido, os dispositivos deverão começar a conectar-se da sua região secundária. Com base na natureza consciente do estado da maioria dos serviços envolvidos, é comum os administradores de solução acionarem o processo de failover entre regiões. A melhor maneira de comunicar o novo ponto de extremidade para os dispositivos, enquanto mantém o controle do processo, é fazer com que eles verifiquem regularmente um serviço de concierge para o ponto de extremidade ativo atual. O serviço de concierge pode ser um aplicativo Web que é replicado e acessível usando técnicas de redirecionamento de DNS (por exemplo, usando o Gerenciador de Tráfego do Azure).
Observação
O serviço de hub da IoT não é um tipo de terminal suportado no Gerenciador de Tráfego do Azure. A recomendação é integrar o serviço de concierge proposto ao gerenciador de tráfego do Azure, implementando a API de análise de integridade do ponto de extremidade.
Replicação do registro de identidade: para ser utilizável, o Hub IoT secundário deverá conter todas as identidades de dispositivo que possam se conectar à solução. A solução deve manter backups replicados geograficamente das identidades do dispositivo e carregá-los no Hub IoT secundário antes de mudar o ponto de extremidade ativo para os dispositivos. A funcionalidade de exportação de identidade do dispositivo do Hub IoT é útil neste contexto. Para obter mais informações, consulte Guia do desenvolvedor do Hub IoT - Registro de identidade.
Lógica de mesclagem: quando a região primária ficar disponível novamente, o estado e os dados criados no site secundário deverão ser migrados de volta para a região primária. Esse estado e os dados estão relacionados principalmente às identidades de dispositivo e aos metadados do aplicativo, que deverão ser mesclados ao Hub IoT primário e com todos os outros armazenamentos específicos do aplicativo na região primária.
Para simplificar essa etapa, você deve usar operações idempotentes. Operações idempotentes minimizam os efeitos colaterais da distribuição eventual e consistente de eventos e também de duplicatas ou a entrega de eventos fora de ordem. Além disso, a lógica do aplicativo deve ser projetada para tolerar possíveis inconsistências ou um estado ligeiramente desatualizado. Essa situação pode ocorrer devido ao tempo adicional necessário para o sistema recuperar com base nos objetivos de ponto de recuperação (RPO).
Escolha a opção de HA/DR certa
Aqui está um resumo das opções de HA/DR apresentado neste artigo que pode ser usado como um quadro de referência para escolher a opção correta que funciona para sua solução.
| Opção de HA/DR | RTO | RPO | Requer intervenção manual? | Complexidade da implementação | Impacto de custo |
|---|---|---|---|---|---|
| Failover iniciado pelo Microsoft | 2 - 26 horas | Consulte a tabela RPO acima | Não | Nenhum | Nenhum |
| Failover manual | 10 min - 2 horas | Consulte a tabela RPO acima | Sim | Muito baixa. Você só precisará disparar essa operação no portal. | Nenhum |
| Entre a alta disponibilidade de região | < 1 min | Depende da frequência de replicação de sua solução personalizada de alta disponibilidade | No | Alta | > 1x o sucto de 1 Hub IoT |