Definir configurações do agente para alta disponibilidade, dimensionamento e uso de memória
O recurso Agente é o principal recurso que define as configurações gerais do Agente MQTT. Também determina o número e o tipo de pods que executam a configuração do Agente, como front-ends e back-ends. Você também pode usar o recurso Agente para configurar seu perfil de memória. Mecanismos de autorrecuperação são integrados ao agente e geralmente podem se recuperar automaticamente de falhas de componente. Por exemplo, um nó falha em um cluster do Kubernetes configurado para alta disponibilidade.
Você pode dimensionar horizontalmente o agente MQTT adicionando mais réplicas de front-end e partições de back-end. As réplicas de front-end são responsáveis por aceitar conexões MQTT de clientes e encaminhá-las para as partições de back-end. As partições de back-end são responsáveis por armazenar e entregar mensagens aos clientes. Os pods de front-end distribuem o tráfego de mensagens entre os pods de back-end e o fator de redundância de back-end determina o número de cópias de dados para fornecer resiliência contra falhas de nó no cluster.
Para uma lista das configurações disponíveis, confira a Referência de API do Agente.
Definir as configurações de dimensionamento
Importante
Essa configuração requer a modificação do recurso do Agente e só pode ser configurada no momento da implantação inicial usando a CLI do Azure ou o Portal do Azure. Uma nova implantação será necessária se forem necessárias alterações na configuração do Agente. Para saber mais, confira Personalizar o Agente padrão.
Para definir as configurações de dimensionamento do agente MQTT, especifique os campos de cardinalidade na especificação do recurso broker durante a implantação de Operações do Azure IoT.
Cardinalidade de implantação automática
Para determinar automaticamente a cardinalidade inicial durante a implantação, omita o campo de cardinalidade no recurso Broker.
Ainda não há suporte para cardinalidade automática ao implantar as Operações de IoT do Azure por meio do portal do Azure. No entanto, você pode especificar manualmente o modo de implantação do cluster como nó único ouvários nós. Para saber mais, consulte Implantar Operações do Azure IoT.
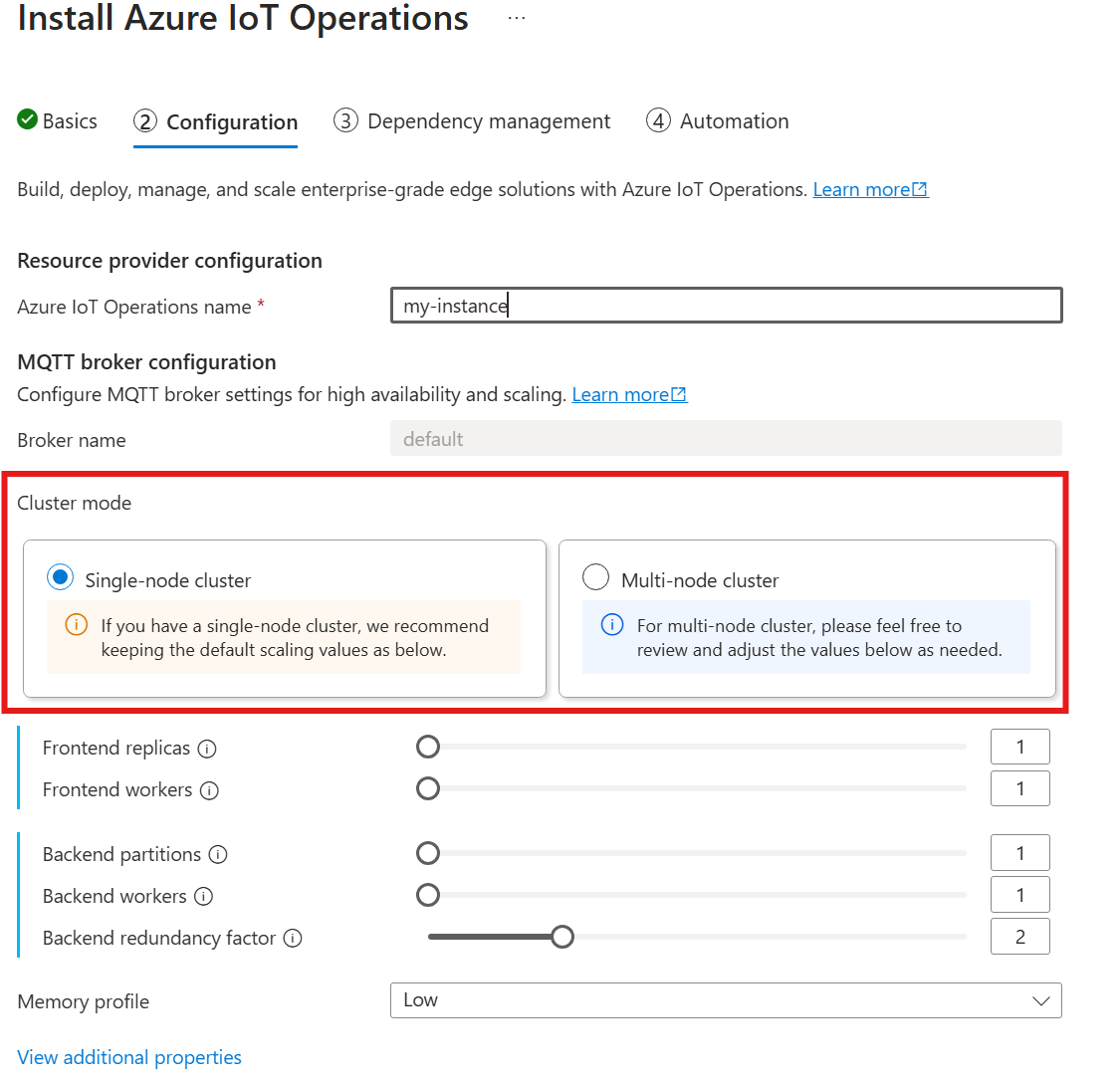
O operador do agente MQTT implanta automaticamente o número apropriado de pods com base no número de nós disponíveis no momento da implantação. Isso é útil para cenários de não produção em que você não precisa de alta disponibilidade ou escala.
No entanto, isso não é dimensionamento automático. O operador não dimensiona automaticamente o número de pods com base na carga. O operador determina apenas o número inicial de pods a serem implantados com base no hardware do cluster. Conforme observado anteriormente, a cardinalidade só pode ser definida no momento da implantação inicial e uma nova implantação será necessária se as configurações de cardinalidade precisarem ser alteradas.
Configurar a cardinalidade diretamente
Para definir as configurações de cardinalidade diretamente, especifique cada um dos campos de cardinalidade.
Ao seguir o guia para implantar as Operações do Azure IoT, na seção Configuração, examine a Configuração do agente MQTT. Aqui, você pode especificar o número de réplicas de front-end, partições de back-end e trabalhos de back-end.
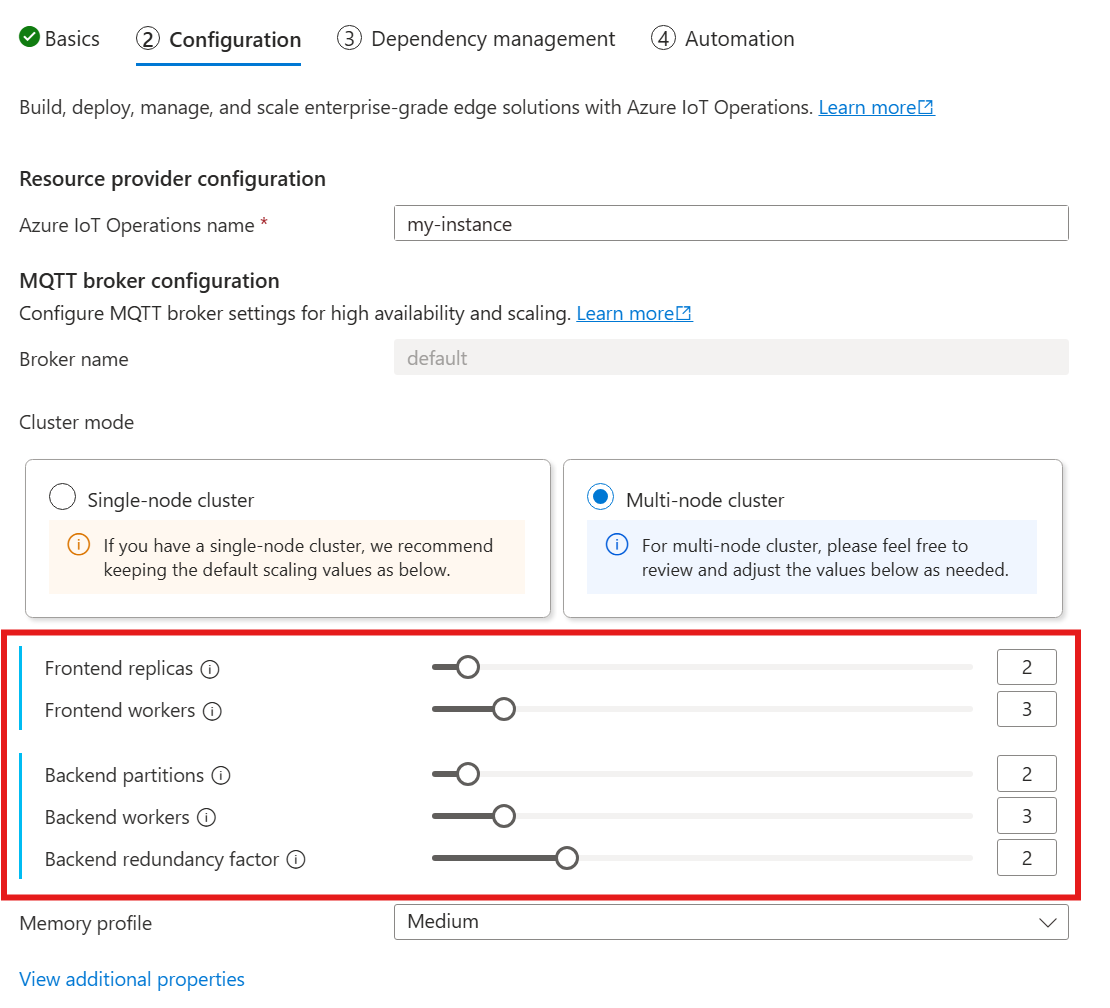
Noções básicas sobre cardinalidade
Cardinalidade significa o número de instâncias de uma entidade específica em um conjunto. No contexto do agente MQTT, cardinalidade refere-se ao número de réplicas de front-end, partições de back-end e trabalhos de back-end a serem implantados. As configurações de cardinalidade são usadas para dimensionar o agente horizontalmente e melhorar a alta disponibilidade se houver falhas de pod ou nó.
O campo de cardinalidade é um campo aninhado, com subcampos para front-end e back-endChain. Cada um desses subcampos tem suas próprias configurações.
Front-end
O subcampo de front-end define as configurações para os pods de front-end. As duas configurações principais são:
Réplicas: o número de réplicas de front-end (pods) a serem implantadas. Aumentar o número de réplicas de front-end fornece alta disponibilidade caso um dos pods de front-end falhe.
Trabalhos: o número de trabalhos de front-end lógicos por réplica. Cada trabalho pode consumir até um núcleo de CPU no máximo.
Cadeia de back-end
O subcampo de cadeia de back-end define as configurações para as partições de back-end. As três configurações principais são:
Partições: o número de partições a serem implantadas. Por meio de um processo chamado fragmentação, cada partição é responsável por uma parte das mensagens, dividida por ID do tópico e ID da sessão. Os pods de front-end distribuem o tráfego de mensagens entre as partições. Aumentar o número de partições aumenta o número de mensagens que o agente pode manipular.
Fator de redundância: o número de réplicas de back-end (pods) a serem implantadas por partição. Aumentar o fator de redundância aumenta o número de cópias de dados para fornecer resiliência contra falhas de nó no cluster.
Trabalhos: o número de trabalhadores a serem implantados por réplica de back-end. Aumentar o número de trabalhos por réplica de back-end pode aumentar o número de mensagens que o pod de back-end pode manipular. Cada trabalho pode consumir até dois núcleos de CPU no máximo, portanto, tenha cuidado ao aumentar o número de trabalhos por réplica para não exceder o número de núcleos de CPU no cluster.
Considerações
Quando você aumenta os valores de cardinalidade, a capacidade do agente de lidar com mais conexões e mensagens geralmente melhora e aumenta a alta disponibilidade se houver falhas de pod ou nó. No entanto, isso também leva a um maior consumo de recursos. Portanto, ao ajustar os valores de cardinalidade, considere as configurações de perfil de memória e as solicitações de recurso de CPU do agente. Aumentar o número de trabalhos por réplica de front-end pode ajudar a aumentar a utilização do núcleo da CPU se você descobrir que a utilização da CPU de front-end é um gargalo. Aumentar o número de trabalhos de back-end pode ajudar com a taxa de transferência da mensagem se a CPU de back-end for um gargalo.
Por exemplo, se o cluster tiver três nós, cada um com oito núcleos de CPU, defina o número de réplicas de front-end para corresponder ao número de nós (3) e definir o número de trabalhos como 1. Defina o número de partições de back-end para corresponder ao número de nós (3) e aos trabalhos de back-end como 1. Defina o fator de redundância conforme desejado (2 ou 3). Aumente o número de trabalhadores de front-end se você descobrir que a CPU de front-end é um gargalo. Lembre-se de que os trabalhadores de back-end e front-end podem competir por recursos de CPU entre si e com outros pods.
Configurar o perfil de memória
Importante
Essa configuração requer a modificação do recurso do Agente e só pode ser configurada no momento da implantação inicial usando a CLI do Azure ou o Portal do Azure. Uma nova implantação será necessária se forem necessárias alterações na configuração do Agente. Para saber mais, confira Personalizar o Agente padrão.
Para definir o agente MQTT de configurações de perfil de memória, especifique os campos de perfil de memória na especificação do recurso broker durante a implantação de Operações de IoT do Azure.
Ao seguir o guia para implantar o Azure IoT Operations, na seção Configuração , examine a configuração do agente do MQTT e localize a configuração de perfil de memória. Aqui, você pode selecionar entre os perfis de memória disponíveis em uma lista suspensa.
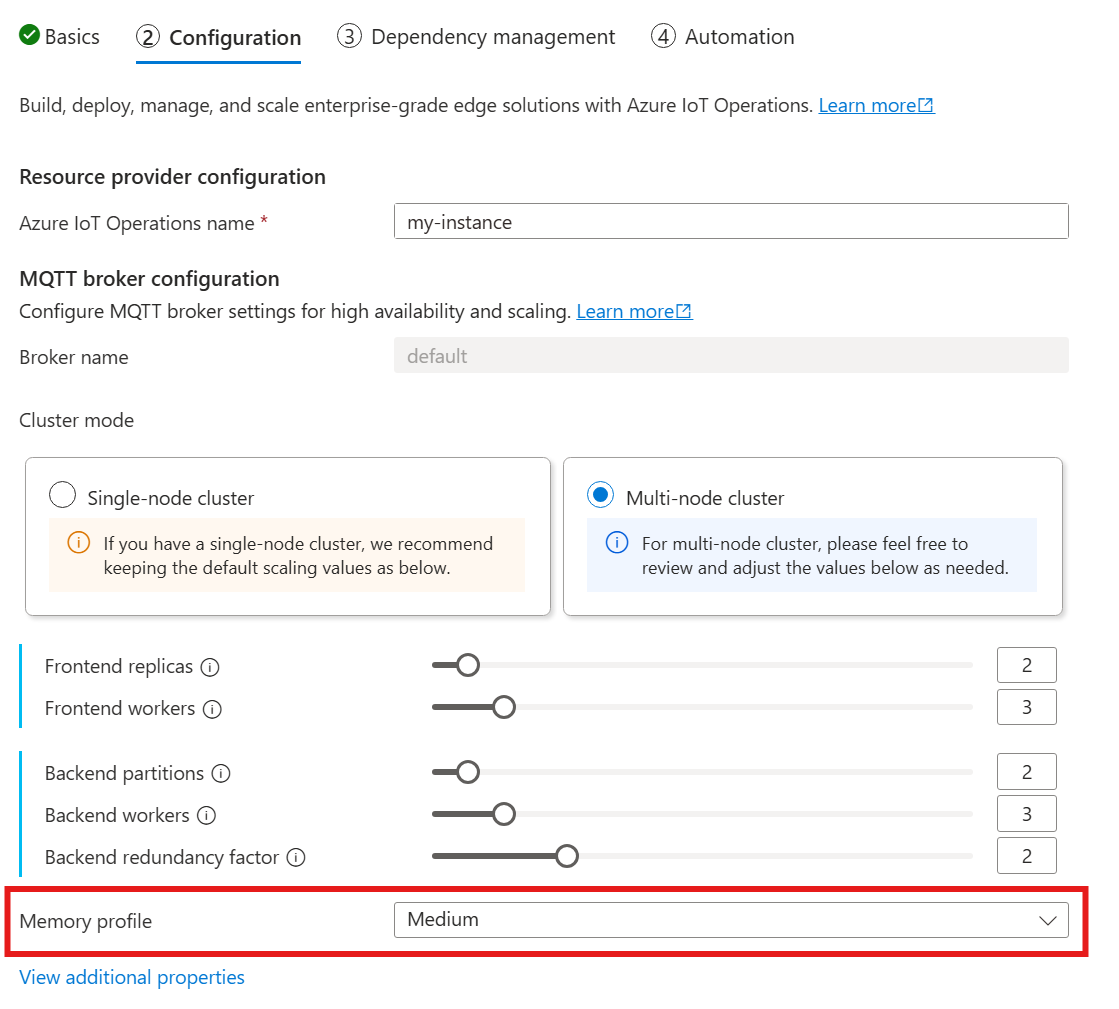
Há alguns perfis de memória para escolher, cada um com diferentes características de uso de memória.
Pequeno
Ao usar este perfil:
- O uso máximo de memória de cada réplica de front-end é de aproximadamente 99 MiB, mas o uso máximo real de memória pode ser maior.
- O uso máximo de memória de cada réplica de back-end é de aproximadamente 102 MiB multiplicado pelo número de trabalhos de back-end, mas o uso máximo real de memória pode ser maior.
Recomendações ao usar este perfil:
- Apenas um front-end deve ser usado.
- Os clientes não devem enviar pacotes grandes. Você só deve enviar pacotes menores que 4 MiB.
Baixo
Ao usar este perfil:
- O uso máximo de memória de cada réplica de front-end é de aproximadamente 387 MiB, mas o uso máximo real de memória pode ser maior.
- O uso máximo de memória de cada réplica de back-end é de aproximadamente 390 MiB multiplicado pelo número de trabalhos de back-end, mas o uso máximo real de memória pode ser maior.
Recomendações ao usar este perfil:
- Apenas um ou dois front-ends devem ser usados.
- Os clientes não devem enviar pacotes grandes. Você só deve enviar pacotes menores que 10 MiB.
Médio
Médio é o perfil padrão.
- O uso máximo de memória de cada réplica de front-end é de aproximadamente 1,9 GiB, mas o uso máximo real de memória pode ser maior.
- O uso máximo de memória de cada réplica de back-end é de aproximadamente 1,5 GiB multiplicado pelo número de trabalhos de back-end, mas o uso máximo real de memória pode ser maior.
Alto
- O uso máximo de memória de cada réplica de front-end é de aproximadamente 4,9 GiB, mas o uso máximo real de memória pode ser maior.
- O uso máximo de memória de cada réplica de back-end é de aproximadamente 5,8 GiB multiplicado pelo número de trabalhos de back-end, mas o uso máximo real de memória pode ser maior.
Limites de recursos de Cardinalidade e Kubernetes
Para evitar a falta de recursos no cluster, o agente é configurado por padrão para solicitar limites de recursos de CPU do Kubernetes. Dimensionar proporcionalmente o número de réplicas ou trabalhadores aumenta proporcionalmente os recursos de CPU necessários. Um erro de implantação será emitido se houver recursos de CPU insuficientes disponíveis no cluster. Isso ajuda a evitar situações em que a cardinalidade do agente solicitada não tem recursos suficientes para ser executada de forma ideal. Ele também ajuda a evitar possíveis remoções de pod e contenção de CPU.
Atualmente, o agente MQTT solicita uma (1,0) unidade de CPU por trabalho de front-end e duas (2,0) unidades de CPU por trabalho de back-end. Consulte unidades de recursos de CPU do Kubernetes para obter mais detalhes.
Por exemplo, a cardinalidade abaixo solicitaria os seguintes recursos de CPU:
- Para front-ends: 2 unidades de CPU por pod de front-end, totalizando 6 unidades de CPU.
- Para back-ends: 4 unidades de CPU por pod de back-end (para dois trabalhos de back-end), vezes 2 (fator de redundância), vezes 3 (número de partições), totalizando 24 unidades de CPU.
{
"cardinality": {
"frontend": {
"replicas": 3,
"workers": 2
},
"backendChain": {
"partitions": 3,
"redundancyFactor": 2,
"workers": 2
}
}
}
Para desabilitar essa configuração, defina o campo generateResourceLimits.cpu como Disabled no recurso Broker.
Não há suporte para alterar o campo generateResourceLimits no portal do Azure. Para desabilitar essa configuração, use a CLI do Azure.
Implantação de vários nós
Para garantir alta disponibilidade e resiliência com implantações de vários nós, o agente MQTT de Operações IoT do Azure define automaticamente regras anti-afinidade para pods de back-end.
Essas regras são predefinidas e não podem ser modificadas.
Finalidade de regras anti-afinidade
As regras anti-afinidade garantem que os pods de back-end da mesma partição não sejam executados no mesmo nó. Isso ajuda a distribuir a carga e fornece resiliência contra falhas de nó. Especificamente, os pods de back-end da mesma partição têm anti-afinidade entre si.
Verificando as configurações de anti-afinidade
Para verificar as configurações de anti-afinidade de um pod de back-end, use o seguinte comando:
kubectl get pod aio-broker-backend-1-0 -n azure-iot-operations -o yaml | grep affinity -A 15
A saída mostrará a configuração anti-afinidade, semelhante à seguinte:
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- podAffinityTerm:
labelSelector:
matchExpressions:
- key: chain-number
operator: In
values:
- "1"
topologyKey: kubernetes.io/hostname
weight: 100
Essas são as únicas regras anti-afinidade definidas para o agente.