Lidar com tempos limite do procedimento armazenado no conector do SQL para aplicativos lógicos do Azure
Aplica-se a: Aplicativos Lógicos do Azure (Consumo)
Quando seu aplicativo lógico funciona com conjuntos de resultados tão grandes que o conector do SQL não retorna todos os resultados ao mesmo tempo, ou se você quiser mais controle sobre o tamanho e a estrutura de seus conjuntos de resultados, poderá criar um procedimento armazenado que organize os resultados da maneira desejada. O conector do SQL fornece muitos recursos de back-end que você pode acessar usando os Aplicativos Lógicos do Azure, permitindo a você automatizar com mais facilidade as tarefas comerciais que funcionam com tabelas do banco de dados SQL.
Por exemplo, ao obter ou inserir várias linhas, o aplicativo lógico pode iterar por essas linhas usando um Until loop dentro desses limites. No entanto, quando o aplicativo lógico precisa trabalhar com milhares ou milhões de linhas, você deseja minimizar os custos resultantes de chamadas para o banco de dados. Para obter mais informações, consulte Lidar com dados em massa usando o conector do SQL.
Tempo limite na execução de procedimento armazenado
O conector do SQL tem um tempo limite máximo para procedimento armazenado inferior a 2 minutos. Alguns procedimentos armazenados podem levar mais tempo do que esse limite para ser concluído, causando um 504 Timeout erro. Às vezes, esses processos de execução longa são codificados como procedimentos armazenados explicitamente para essa finalidade. Devido ao tempo limite, chamar esses procedimentos a partir de aplicativos lógicos do Azure pode criar problemas. Embora o conector do SQL não dê suporte nativo a um modo assíncrono, você pode contornar esse problema e simular esse modo usando um gatilho de conclusão do SQL, uma consulta de passagem SQL nativa, uma tabela de estado e trabalhos do lado do servidor. Para esta tarefa, você pode usar o Agente de Trabalho Elástico do Azure para o Banco de Dados SQL do Azure. Para o SQL Server local e a Instância Gerenciada de SQL do Azure, você pode usar o SQL Server Agent.
Por exemplo, suponha que você tenha o seguinte procedimento armazenado de execução longa, que leva mais tempo do que o tempo limite para concluir a execução. Se você executar esse procedimento armazenado a partir de um aplicativo lógico usando o conector do SQL, obterá um HTTP 504 Gateway Timeout erro como resultado.
CREATE PROCEDURE [dbo].[WaitForIt]
@delay char(8) = '00:03:00'
AS
BEGIN
SET NOCOUNT ON;
WAITFOR DELAY @delay
END
Em vez de chamar diretamente o procedimento armazenado, você pode executar o procedimento de forma assíncrona em segundo plano usando um agente de trabalho. Você pode armazenar as entradas e saídas em uma tabela de estados com a qual você pode interagir por meio de seu aplicativo lógico. Se você não precisar das entradas e saídas, ou se já estiver gravando os resultados em uma tabela no procedimento armazenado, será possível simplificar essa abordagem.
Importante
Verifique se o procedimento armazenado e todos os trabalhos são idempotentes, o que significa que eles podem ser executados várias vezes sem afetar os resultados. Se o processamento assíncrono falhar ou expirar, o agente de trabalho poderá repetir a etapa e, ainda, o procedimento armazenado, várias vezes. Para evitar a duplicação de saída, antes de criar qualquer objeto, examine essas práticas recomendadas e abordagens.
A próxima seção descreve como você pode usar o agente de trabalho elástico do Azure para o banco de dados SQL do Azure. Para o SQL Server e a Instância Gerenciada de SQL do Azure, você pode usar o SQL Server Agent. Alguns detalhes de gerenciamento serão diferentes, mas as etapas fundamentais permanecerão as mesmas que a configuração de um agente de trabalho para o banco de dados SQL do Azure.
Agente de trabalho para banco de dados SQL do Azure
Para criar um trabalho que possa executar o procedimento armazenado para o Banco de dados SQL do Azure, use o Agente de trabalho elástico do Azure. Crie seu agente de trabalho no portal do Azure. Essa abordagem adicionará vários procedimentos armazenados ao banco de dados que é usado pelo agente, também conhecido como o banco de dados do agente. Você pode criar um trabalho que executa o procedimento armazenado no banco de dados de destino e captura a saída quando terminar.
Antes de criar o trabalho, você precisa configurar permissões, grupos e destinos conforme descrito pela documentação completa para o agente de trabalho elástico do Azure. Você também precisa criar uma tabela de suporte no banco de dados de destino, conforme descrito nas seções a seguir.
Criar tabela de estados para registrar parâmetros e armazenar entradas
Os trabalhos do SQL Agent não aceitam parâmetros de entrada. Em vez disso, no banco de dados de destino, crie uma tabela de estado na qual você registra os parâmetros e armazene as entradas a serem usadas para chamar os procedimentos armazenados. Todas as etapas de trabalho do Agent são executadas no banco de dados de destino, mas os procedimentos armazenados do trabalho são executados no banco de dados do agente.
Para criar a tabela de estados, use este esquema:
CREATE TABLE [dbo].[LongRunningState](
[jobid] [uniqueidentifier] NOT NULL,
[rowversion] [timestamp] NULL,
[parameters] [nvarchar](max) NULL,
[start] [datetimeoffset](7) NULL,
[complete] [datetimeoffset](7) NULL,
[code] [int] NULL,
[result] [nvarchar](max) NULL,
CONSTRAINT [PK_LongRunningState] PRIMARY KEY CLUSTERED
( [jobid] ASC
)WITH (STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF) ON [PRIMARY]
) ON [PRIMARY] TEXTIMAGE_ON [PRIMARY]
Veja a aparência da tabela resultante no SQL Server Management Studio (SMSS):
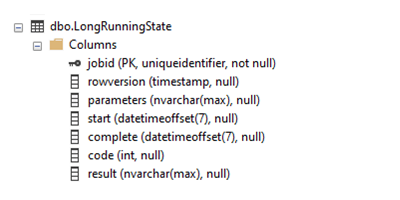
Para garantir um bom desempenho e certificar-se de que o trabalho do Agent possa localizar o registro associado, a tabela usa a ID de execução do trabalho (jobid) como a chave primária. Se desejar, você também pode adicionar colunas individuais para os parâmetros de entrada. O esquema descrito anteriormente pode geralmente lidar com vários parâmetros, mas é limitado ao tamanho calculado por NVARCHAR(MAX).
Criar um trabalho de nível superior para executar o procedimento armazenado
Para executar o procedimento armazenado de execução longa, crie este agente de trabalho de nível superior no banco de dados do agente:
EXEC jobs.sp_add_job
@job_name='LongRunningJob',
@description='Execute Long-Running Stored Proc',
@enabled = 1
Agora, adicione etapas ao trabalho que parametrizar, executar e concluir o procedimento armazenado. Por padrão, uma etapa de trabalho expira após 12 horas. Se o procedimento armazenado precisar de mais tempo, ou se você quiser que o procedimento expire antes, você poderá alterar o step_timeout_seconds parâmetro para outro valor que é especificado em segundos. Por padrão, uma etapa tem 10 repetições internas com um tempo limite de retirada entre cada repetição, que você pode usar a seu favor.
Aqui estão as etapas a serem adicionadas:
Aguarde até que os parâmetros apareçam na
LongRunningStatetabela.Essa primeira etapa aguarda que os parâmetros sejam adicionados à
LongRunningStatetabela, o que acontece logo depois que o trabalho é iniciado. Se a ID de execução do trabalho (jobid) não for adicionada àLongRunningStatetabela, a etapa simplesmente falhará e o tempo limite de repetição ou retirada padrão fará a espera:EXEC jobs.sp_add_jobstep @job_name='LongRunningJob', @step_name= 'Parameterize WaitForIt', @step_timeout_seconds = 30, @command= N' IF NOT EXISTS(SELECT [jobid] FROM [dbo].[LongRunningState] WHERE jobid = $(job_execution_id)) THROW 50400, ''Failed to locate call parameters (Step1)'', 1', @credential_name='JobRun', @target_group_name='DatabaseGroupLongRunning'Consulte os parâmetros da tabela de estados e passe-os para o procedimento armazenado. Essa etapa também executa o procedimento em segundo plano.
Se o procedimento armazenado não precisar de parâmetros, basta chamar diretamente o procedimento armazenado. Caso contrário, para passar o
@timespanparâmetro, use o@callparams, que também pode ser estendido para passar parâmetros adicionais.EXEC jobs.sp_add_jobstep @job_name='LongRunningJob', @step_name='Execute WaitForIt', @command=N' DECLARE @timespan char(8) DECLARE @callparams NVARCHAR(MAX) SELECT @callparams = [parameters] FROM [dbo].[LongRunningState] WHERE jobid = $(job_execution_id) SET @timespan = @callparams EXECUTE [dbo].[WaitForIt] @delay = @timespan', @credential_name='JobRun', @target_group_name='DatabaseGroupLongRunning'Conclua o trabalho e registre os resultados.
EXEC jobs.sp_add_jobstep @job_name='LongRunningJob', @step_name='Complete WaitForIt', @command=N' UPDATE [dbo].[LongRunningState] SET [complete] = GETUTCDATE(), [code] = 200, [result] = ''Success'' WHERE jobid = $(job_execution_id)', @credential_name='JobRun', @target_group_name='DatabaseGroupLongRunning'
Iniciar o trabalho e passar os parâmetros
Para iniciar o trabalho, use uma consulta nativa de passagem com a ação Executar uma consulta SQL e envie imediatamente os parâmetros do trabalho para a tabela de estados. Para fornecer entrada para o atributo jobid na tabela de destino, os aplicativos lógicos adicionam um loop Para cada que itera através da saída da tabela da ação anterior. Para cada ID de execução de trabalho, execute uma ação Inserir linha que usa a saída de dados dinâmicos, ResultSets JobExecutionId, para adicionar os parâmetros para o trabalho a ser desempacotado e passar para o procedimento armazenado de destino.
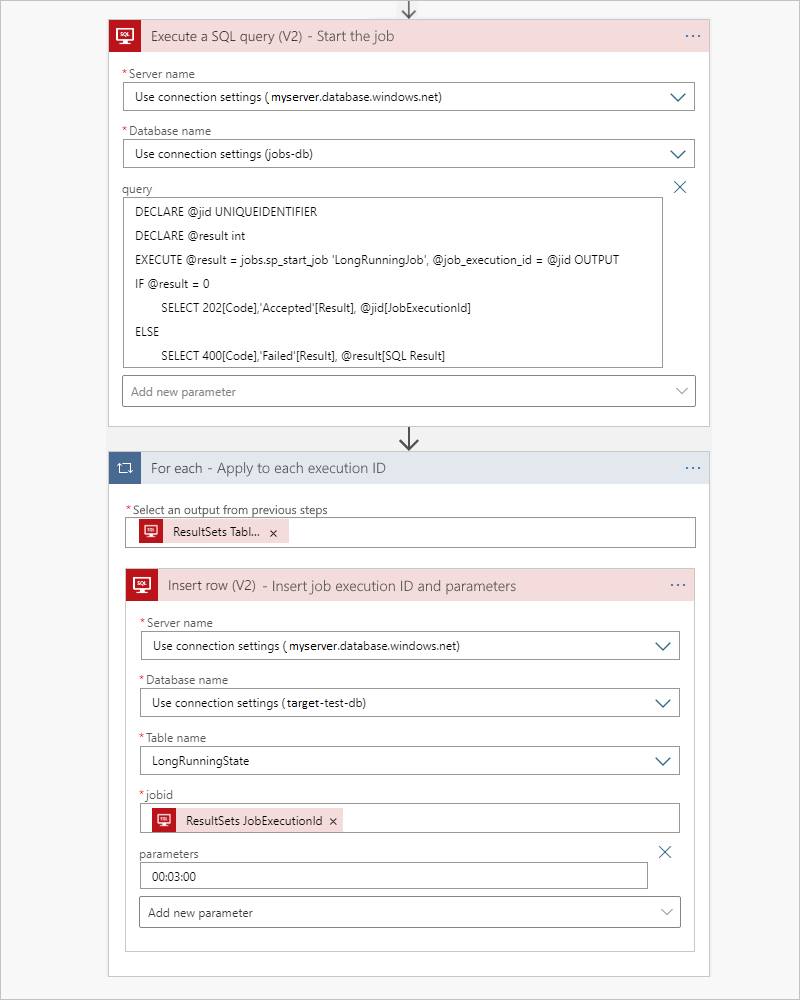
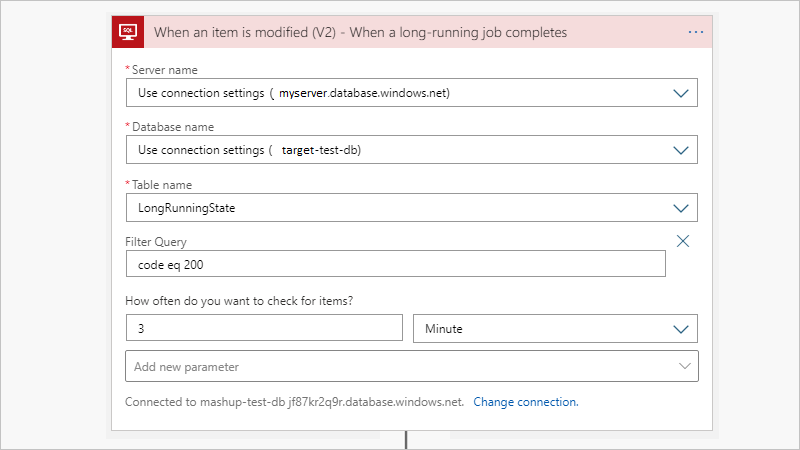
Quando o trabalho é concluído, o trabalho atualiza a LongRunningState tabela para que você possa disparar facilmente o resultado usando o gatilho Quando um item é modificado. Se você não precisar da saída ou se já tiver um gatilho que monitora uma tabela de saída, poderá ignorar essa parte.
Agente de trabalho para SQL Server ou SQL ou Instância Gerenciada de SQL do Azure
Para o mesmo cenário, você pode usar o SQL Server Agent para SQL Server no local e Instância Gerenciada de SQL do Azure. Alguns detalhes de gerenciamento serão diferentes, mas as etapas fundamentais permanecerão as mesmas que a configuração de um agente de trabalho para o banco de dados SQL do Azure.