Início rápido: Estruturação de dados interativa com o Apache Spark no Azure Machine Learning
Para lidar com a estruturação de dados interativa do notebook do Azure Machine Learning, a integração do Azure Machine Learning com o Azure Synapse Analytics fornece acesso fácil à estrutura do Apache Spark. Esse acesso permite a estruturação interativa de dados do Notebook do Azure Machine Learning.
Neste guia de início rápido, você aprenderá a executar a disputa interativa de dados com a computação spark sem servidor do Azure Machine Learning, a conta de armazenamento do AdLS (Azure Data Lake Storage) Gen 2 e a passagem de identidade do usuário.
Pré-requisitos
- Uma assinatura do Azure. Caso não tenha uma, crie uma conta gratuita antes de começar.
- Um Workspace do Azure Machine Learning. Acesse Criar recursos do espaço de trabalho.
- Uma conta de armazenamento do ADLS (Azure Data Lake Storage) Gen 2. Visite Criar uma conta de armazenamento do Azure Data Lake Storage (ADLS) Gen 2.
Armazenar credenciais da conta de armazenamento do Azure como segredos no Azure Key Vault
Para armazenar as credenciais da conta de armazenamento do Azure como segredos no Azure Key Vault, com a interface do usuário do portal do Azure:
Navegue até o Azure Key Vault no portal do Azure
Selecione Segredos no painel esquerdo
Selecione + Gerar/importar
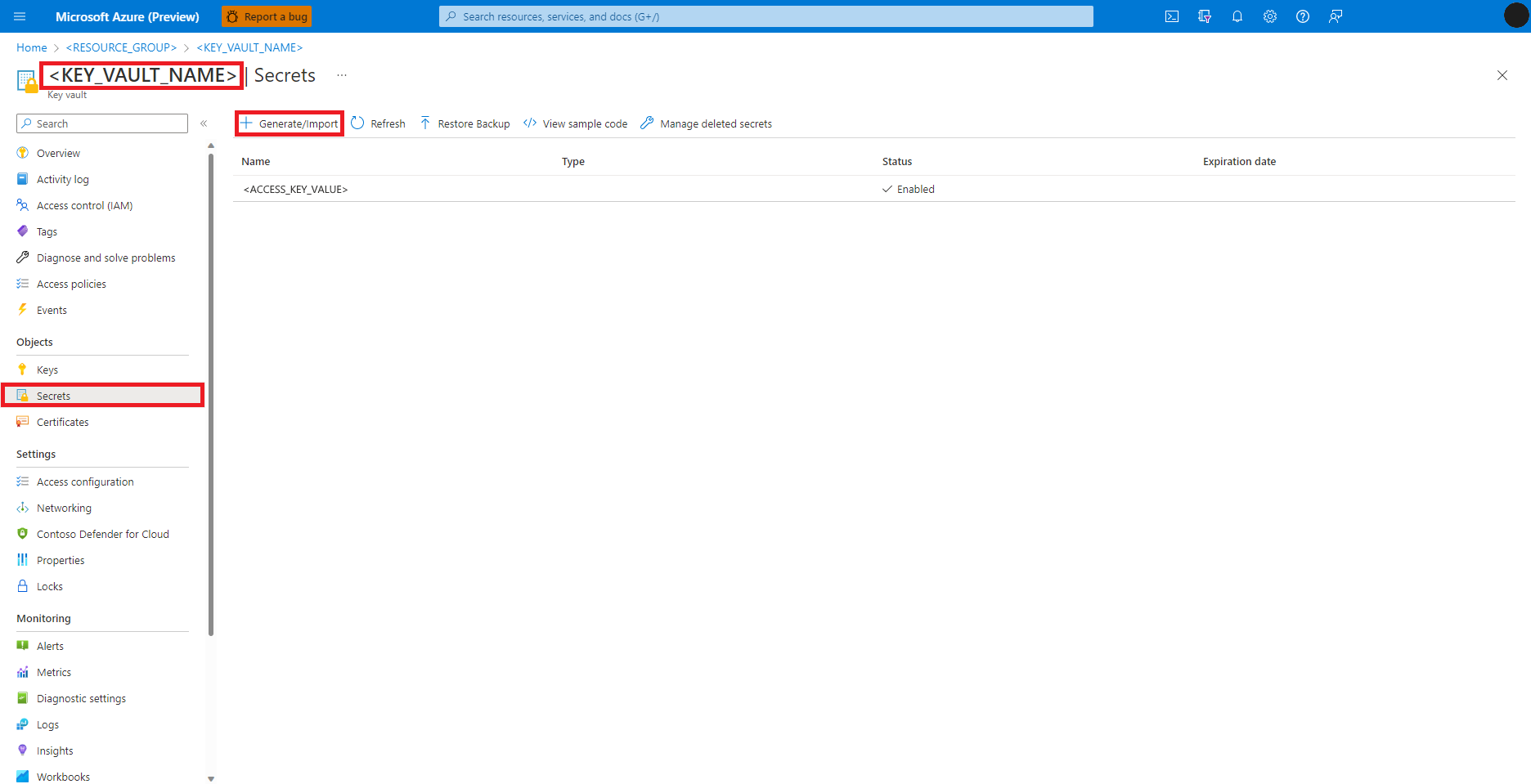
Na tela Criar um segredo, insira um Nome para o segredo que você deseja criar
Navegue até a Conta de Armazenamento de Blobs do Azure, no portal do Azure, conforme mostrado nesta imagem:
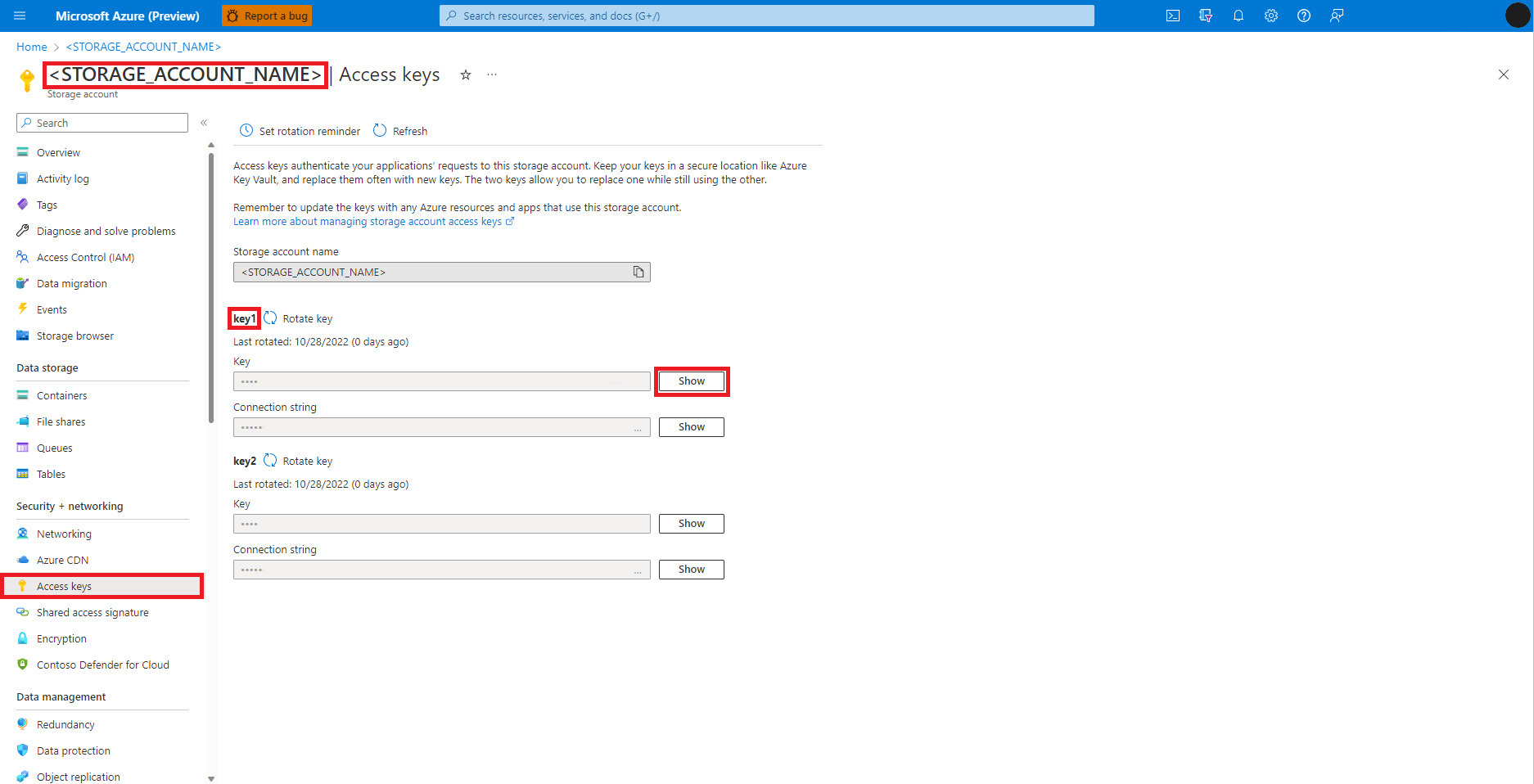
Selecione Chaves de acesso no painel esquerdo da página Conta de Armazenamento de Blobs do Azure
Selecione Exibir ao lado de Chave 1 e, em seguida, Copiar para área de transferência para obter a chave de acesso à conta de armazenamento
Observação
Selecione as opções apropriadas para copiar
- Tokens SAS (assinatura de acesso compartilhado) do contêiner de armazenamento de blobs do Azure
- Credenciais da entidade de serviço da conta de armazenamento do ADLS (Azure Data Lake Storage) Gen 2
- ID do locatário
- ID do cliente e
- segredo
nas respectivas interfaces do usuário enquanto você cria os segredos do Azure Key Vault para eles
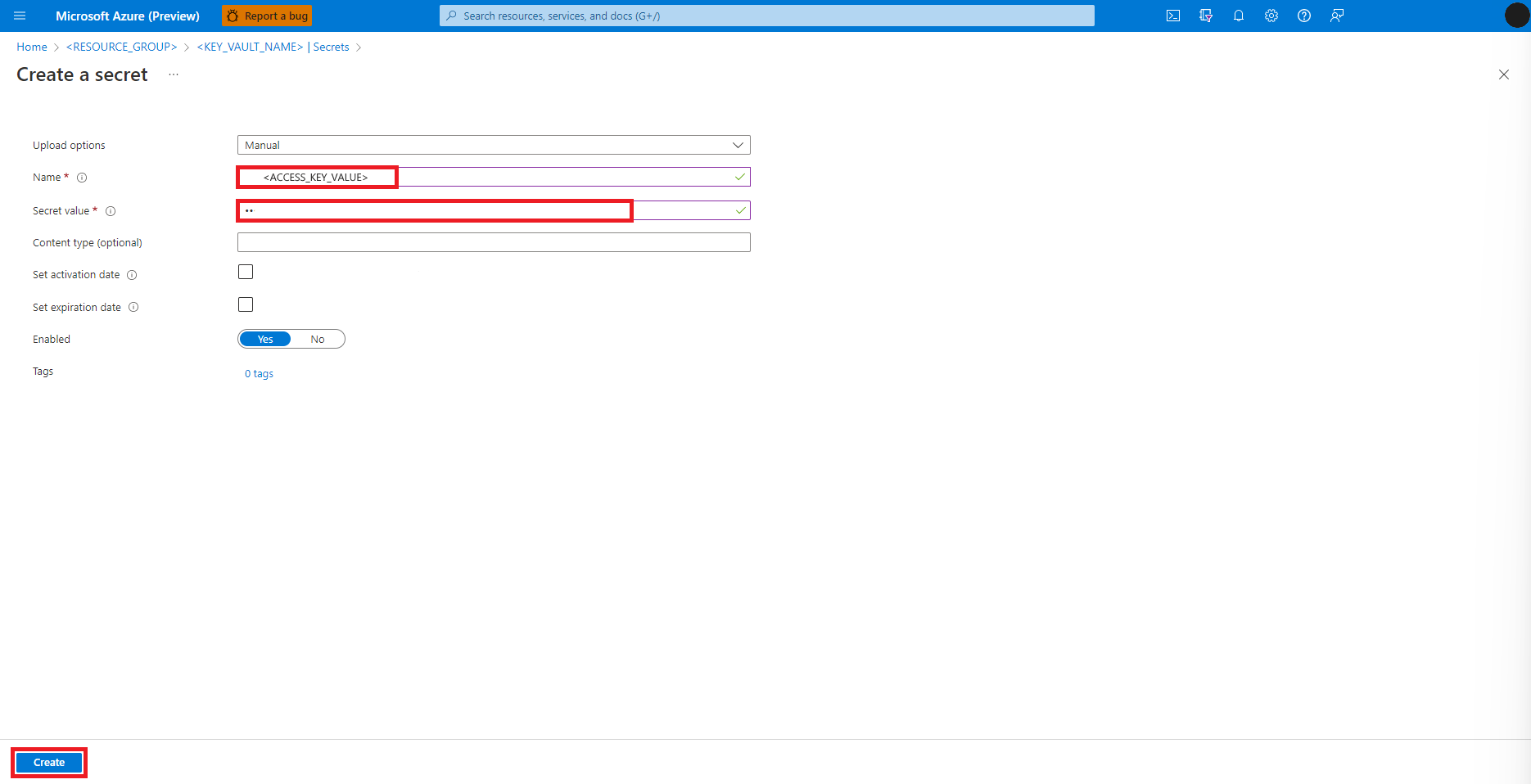
Volte para a tela Criar um segredo
Na caixa de texto Valor do segrego, insira a credencial da chave de acesso para a conta de armazenamento do Azure, que foi copiada para a área de transferência na etapa anterior
Escolha Criar
Dica
A CLI do Azure e a biblioteca de clientes do segredo do Azure Key Vault para Python também podem criar segredos do Azure Key Vault.
Adicionar atribuições de função em contas de armazenamento do Azure
Devemos garantir que os caminhos dos dados de entrada e saída estejam acessíveis antes de iniciarmos a estruturação de dados interativa. Primeiro, para
a identidade do usuário conectado da sessão Notebooks
or
uma entidade de serviço
atribua funções Leitor e Leitor de Dados de Blob de Armazenamento à identidade do usuário conectado. No entanto, em alguns cenários, talvez seja desejável gravar os dados estruturados de volta na conta de armazenamento do Azure. As funções Leitor e Leitor de Dados do Blob de Armazenamento fornecem acesso somente leitura à identidade do usuário ou à entidade de serviço. Para habilitar o acesso de leitura e gravação, atribua as funções Colaborador e Colaborador de Dados do Blob de Armazenamento à identidade do usuário ou entidade de serviço. Para atribuir funções apropriadas à identidade do usuário:
Abra o portal do Microsoft Azure
Pesquise e selecione o serviço Contas de armazenamento

Na página Contas de armazenamento, selecione a conta de armazenamento do Azure Data Lake Storage (ADLS) Gen 2 na lista. Uma página mostrando a conta de armazenamento Visão geral é aberta
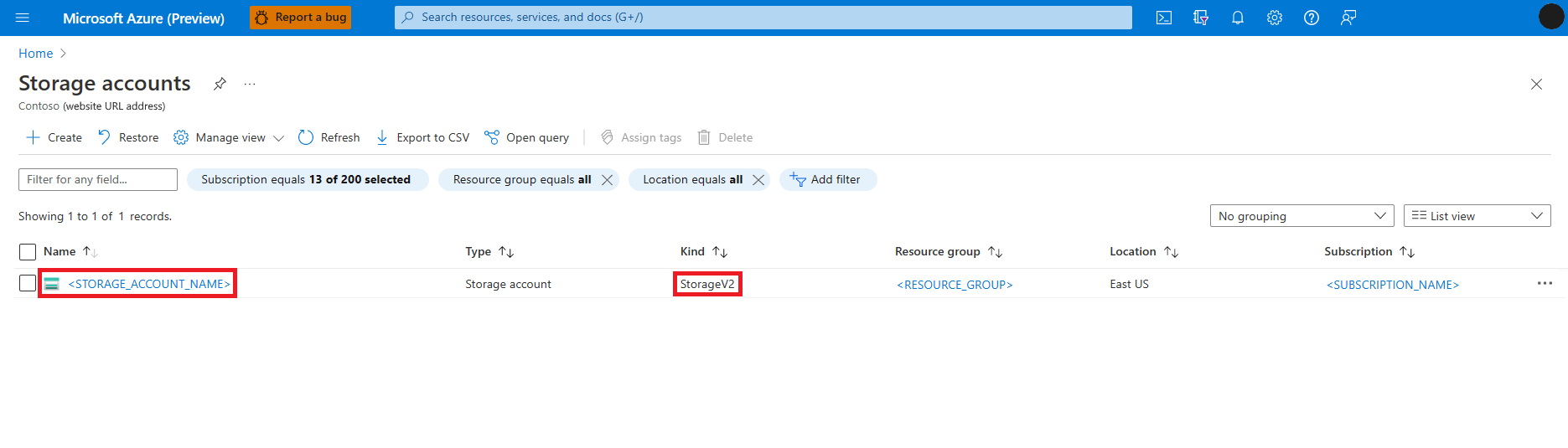
Selecione Controle de Acesso (IAM) no painel esquerdo
Selecione Adicionar atribuição de função
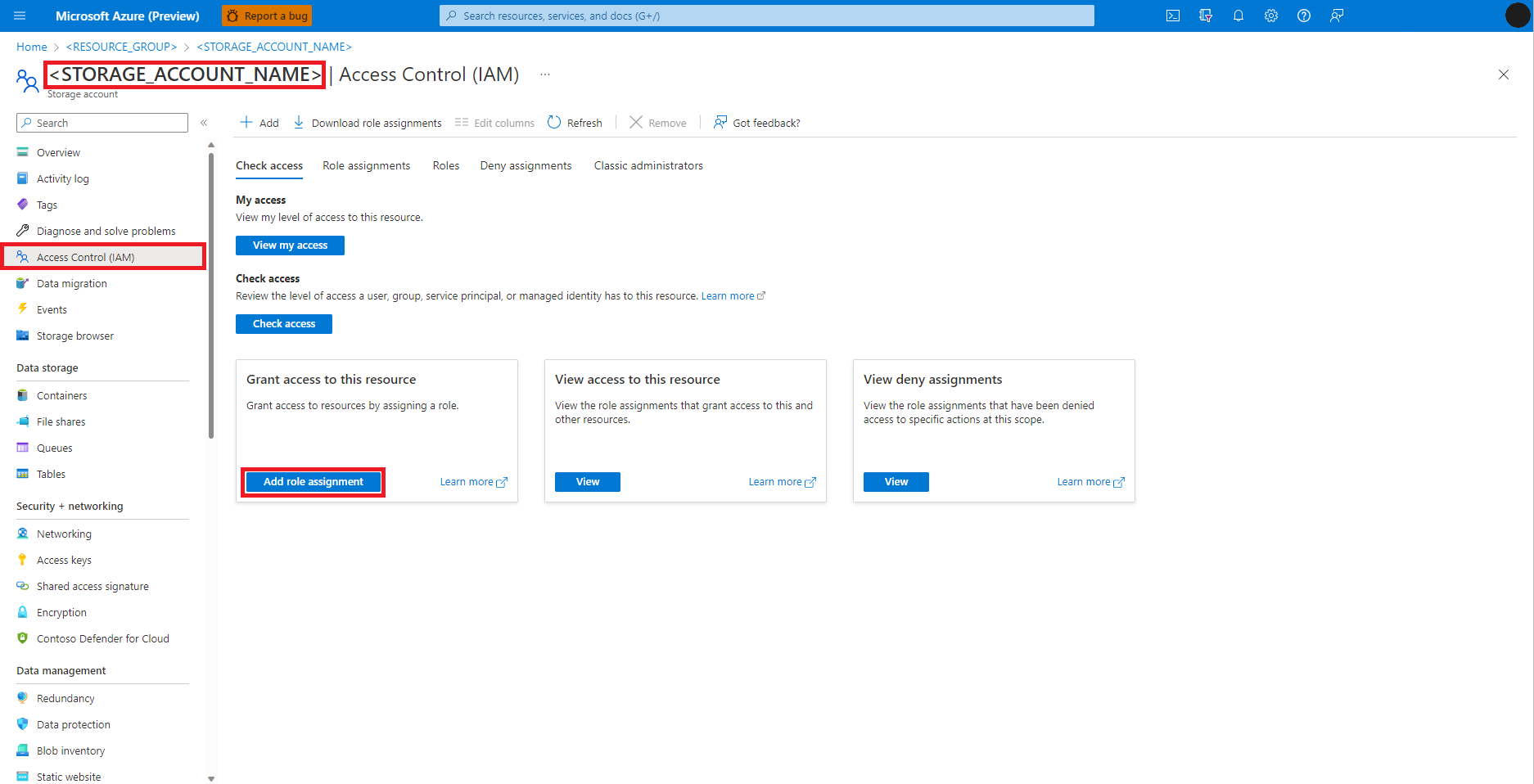
Encontre e selecione a função Colaborador de Dados de Blob de Armazenamento
Selecione Avançar
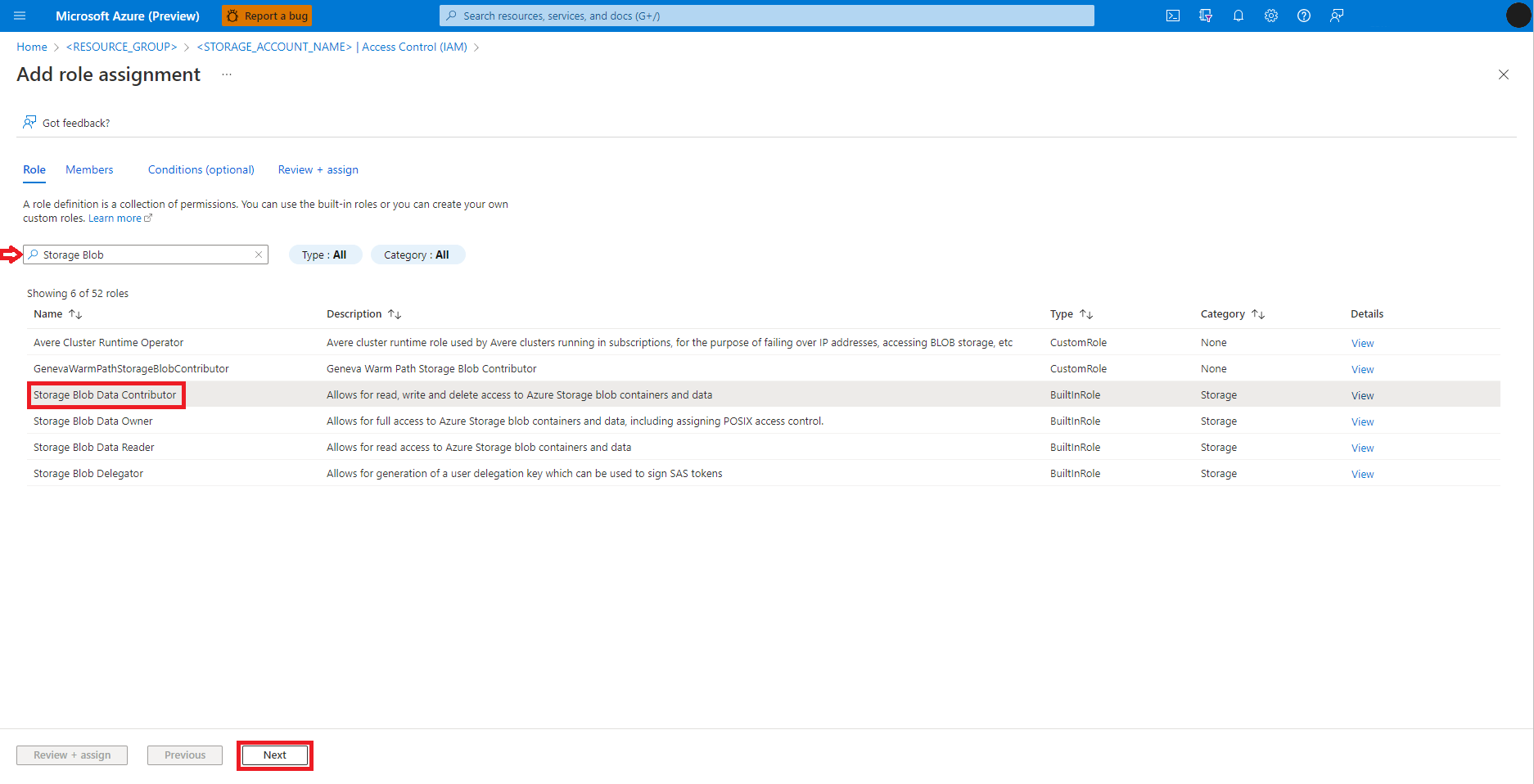
Selecione Usuário, grupo ou entidade de serviço
Selecione + Selecionar membros
Pesquise pela identidade do usuário abaixo de Selecionar
Selecione a identidade do usuário na lista para que apareça em Membros selecionados
Selecione a identidade do usuário apropriada
Selecione Avançar
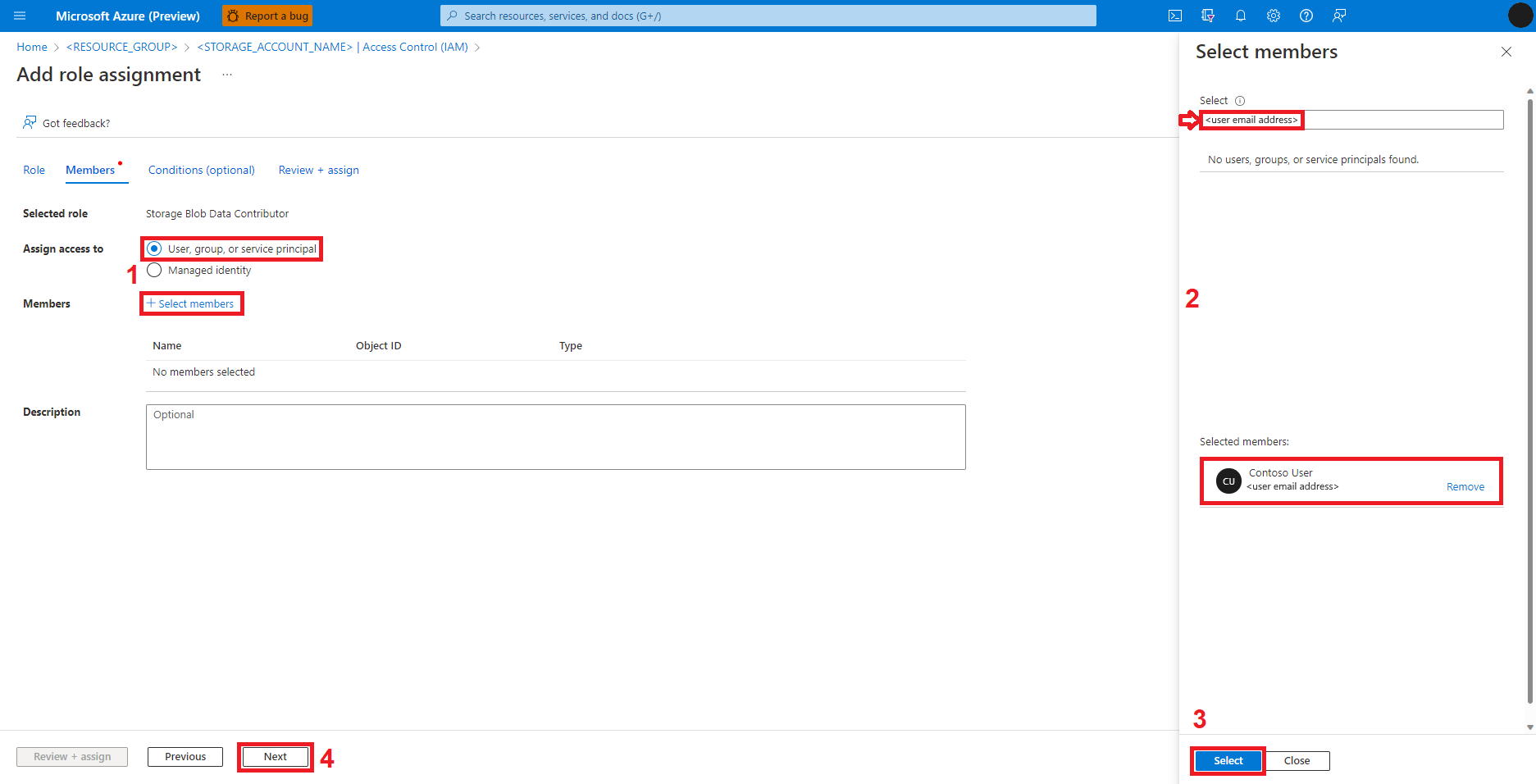
Selecione Revisar + Atribuir
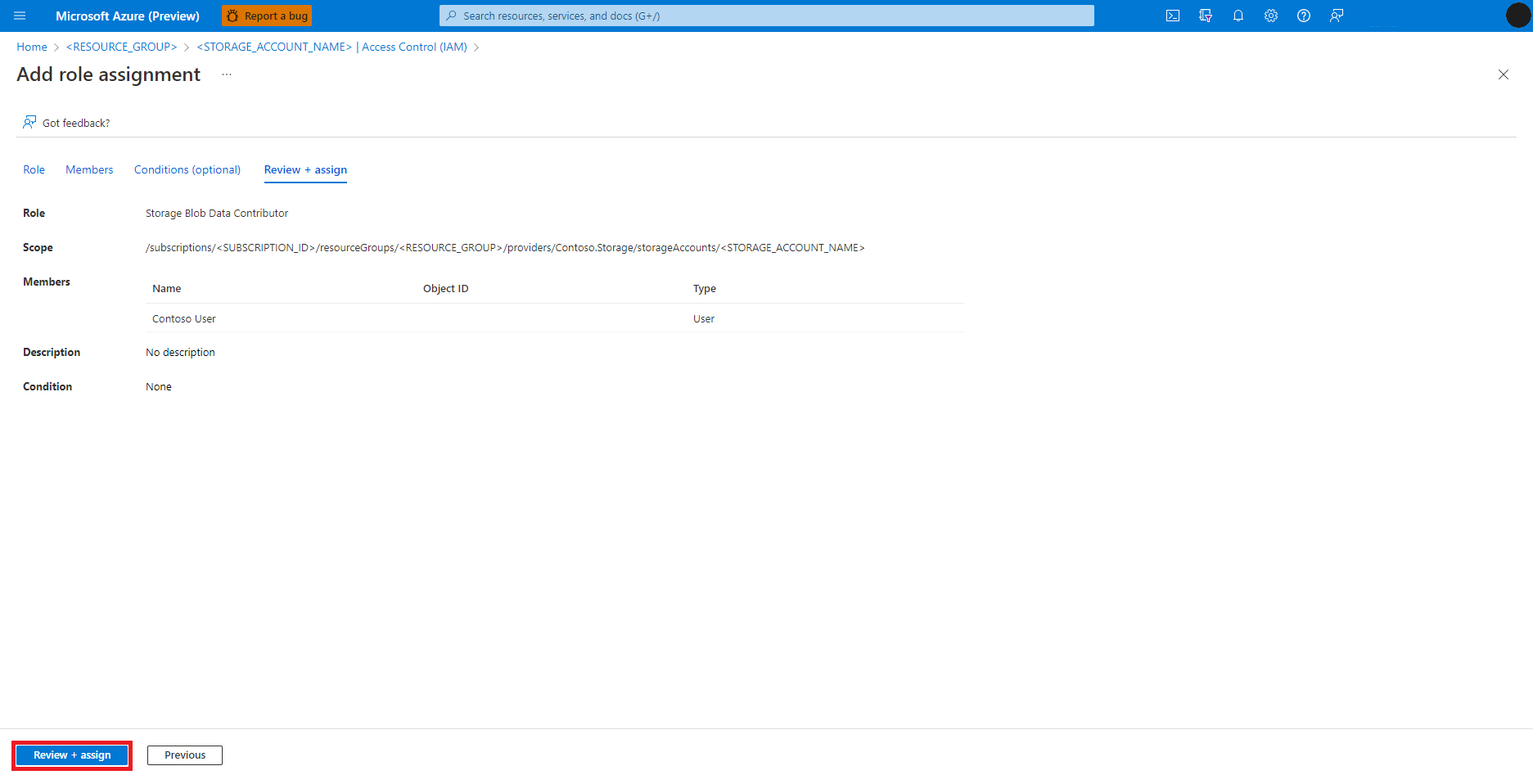
Repita as etapas 2 a 13 para atribuição de função Colaborador






Depois que as funções apropriadas da identidade do usuário ou da entidade de serviço forem atribuídas, os dados na conta de armazenamento do Azure deverão ficar acessíveis.
Observação
Se um pool do Synapse Spark anexado aponta para um pool do Synapse Spark, em um workspace do Azure Synapse, que tem uma rede virtual gerenciada associada a ele, você deve configurar um ponto de extremidade privado gerenciado para uma conta de armazenamento para garantir o acesso aos dados.
Garanta o acesso a recursos de trabalhos do Spark
Os trabalhos do Spark podem usar a passagem de identidade do usuário ou uma identidade gerenciada para acessar dados e outros recursos. A tabela a seguir resume os diferentes mecanismos de acesso a recursos enquanto você usa a computação spark sem servidor do Azure Machine Learning e o pool do Spark do Synapse anexado.
| Pool do Spark | Identidades com suporte | Identidade padrão |
|---|---|---|
| Computação do Spark sem servidor | Identidade do usuário, identidade gerenciada atribuída pelo usuário anexada ao espaço de trabalho | Identidade do usuário |
| Pool do Spark do Synapse anexado | Identidade do usuário, identidade gerenciada atribuída pelo usuário anexada ao pool do Spark do Synapse anexado, identidade gerenciada atribuída pelo sistema do pool do Spark do Synapse anexado | Identidade gerenciada atribuída pelo sistema do pool do Spark do Synapse anexado |
Se o código da CLI ou do SDK definir uma opção para usar a identidade gerenciada, a computação do Spark sem servidor do Azure Machine Learning dependerá de uma identidade gerenciada atribuída pelo usuário anexada ao espaço de trabalho. Você pode anexar uma identidade gerenciada atribuída pelo usuário a um workspace do Azure Machine Learning existente com a CLI do Azure Machine Learning v2 ou com ARMClient.
Próximas etapas
- Apache Spark no Azure Machine Learning
- Anexar e gerenciar um Pool do Spark do Synapse no Azure Machine Learning
- Estruturação de dados interativa com o Apache Spark no Azure Machine Learning
- Enviar trabalhos do Spark no Azure Machine Learning
- Exemplos de código para trabalhos do Spark usando a CLI do Azure Machine Learning
- Exemplos de código para trabalhos do Spark usando o SDK do Python do Azure Machine Learning