Configurar o AutoML para treinar modelos de pesquisa visual computacional
APLICA-SE A: Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Neste artigo, você aprenderá a treinar modelos de visão computacional em dados de imagem com ML automatizado. Você pode treinar modelos usando a extensão CLI do Azure Machine Learning v2 ou o SDK do Python do Azure Machine Learning v2.
O ML automatizado dá suporte ao treinamento de modelos para tarefas de pesquisa visual computacional, como classificação de imagem, detecção de objetos e segmentação de instância. Atualmente, há suporte à criação de modelos de AutoML para tarefas de pesquisa visual computacional por meio do SDK do Python do Azure Machine Learning. As avaliações, os modelos e as saídas de experimentação resultantes podem ser acessados na interface do usuário do Estúdio do Azure Machine Learning. Saiba mais sobre ML automatizado para tarefas de pesquisa visual computacional em dados de imagem.
Pré-requisitos
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
- Um Workspace do Azure Machine Learning. Para criar o workspace, confira Criar recursos do workspace.
- Instale e configure a CLI (v2) e instale também a extensão
ml.
Selecionar o tipo de tarefa
O ML automatizado para imagens dá suporte aos seguintes tipos de tarefa:
| Tipo de tarefa | Sintaxe do Trabalho do AutoML |
|---|---|
| classificação de imagem | CLI v2: image_classification SDK v2: image_classification() |
| classificação de imagem vários rótulos | CLI v2: image_classification_multilabel SDK v2: image_classification_multilabel() |
| detecção de objetos da imagem | CLI v2: image_object_detection SDK v2: image_object_detection() |
| segmentação de instâncias da imagem | CLI v2: image_instance_segmentation SDK v2: image_instance_segmentation() |
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
Esse tipo de tarefa é um parâmetro necessário e pode ser definido usando a chave task.
Por exemplo:
task: image_object_detection
Dados de treinamento e validação
Para gerar modelos da pesquisa visual computacional, você precisa trazer dados de imagem rotulados como entrada para o treinamento do modelo na forma de um MLTable. Você pode criar um MLTable de dados de treinamento no formato JSONL.
Se os dados de treinamento estão em um formato diferente (como Pascal VOC ou COCO), você pode aplicar os scripts auxiliares incluídos nos notebooks de amostra para converter os dados em JSONL. Saiba mais sobre como preparar dados para tarefas de pesquisa visual computacional ML automatizado.
Observação
Os dados de treinamento precisam ter pelo menos 10 imagens para poder enviar um trabalho do AutoML.
Aviso
Há suporte para a criação de MLTable com base em dados em formato JSONL usando apenas o SDK e a CLI, para essa funcionalidade. Não há suporte à criação de MLTable por meio da interface do usuário no momento.
Exemplos de esquema JSONL
A estrutura do TabularDataset depende da tarefa em questão. Para tipos de tarefa de pesquisa visual computacional, ele consiste nos seguintes campos:
| Campo | Descrição |
|---|---|
image_url |
Contém filepath como um objeto StreamInfo |
image_details |
As informações de metadados de imagem consistem em altura, largura e formato. Esse campo é opcional e, portanto, pode ou não existir. |
label |
Uma representação json do rótulo da imagem, com base no tipo de tarefa. |
O código a seguir é um exemplo de arquivo JSONL para classificação de imagem:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label": "cat"
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.jpeg",
"image_details":
{
"format": "jpeg",
"width": "3456px",
"height": "3467px"
},
"label": "dog"
}
O código a seguir é um arquivo JSONL de exemplo para detecção de objetos:
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_01.png",
"image_details":
{
"format": "png",
"width": "2230px",
"height": "4356px"
},
"label":
{
"label": "cat",
"topX": "1",
"topY": "0",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "true",
}
}
{
"image_url": "azureml://subscriptions/<my-subscription-id>/resourcegroups/<my-resource-group>/workspaces/<my-workspace>/datastores/<my-datastore>/paths/image_data/Image_02.png",
"image_details":
{
"format": "jpeg",
"width": "1230px",
"height": "2356px"
},
"label":
{
"label": "dog",
"topX": "0",
"topY": "1",
"bottomX": "0",
"bottomY": "1",
"isCrowd": "false",
}
}
Dados de consumo
Com os dados no formato JSONL, você poderá criar treinamento e validação MLTable, conforme mostrado abaixo.
paths:
- file: ./train_annotations.jsonl
transformations:
- read_json_lines:
encoding: utf8
invalid_lines: error
include_path_column: false
- convert_column_types:
- columns: image_url
column_type: stream_info
O ML Automatizado não impõe restrições ao tamanho dos dados de treinamento ou validação para tarefas de pesquisa visual computacional. O tamanho máximo do conjunto de dados é limitado apenas pela camada de armazenamento por trás do conjunto de dados (exemplo: armazenamento de blob). Não há nenhum número mínimo de imagens ou rótulos. No entanto, recomendamos começar com o mínimo de 10 a 15 amostras por rótulo para ter certeza de que o modelo de saída será suficientemente treinado. Quanto maior o número total de rótulos/classes, de mais amostras você precisará por rótulo.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
Dados de treinamento são um parâmetro obrigatório e são transmitidos pelo uso da chave training_data. Opcionalmente, você pode especificar outra MLtable como dados de validação com a chave validation_data. Se nenhum dado de validação for especificado, 20% dos dados de treinamento serão usados para validação por padrão, a menos que você passe o argumento validation_data_size com um valor diferente.
O nome da coluna de destino é um parâmetro necessário e é usado como destino para a tarefa de ML supervisionada. São transmitidos usando a chave target_column_name. Por exemplo,
target_column_name: label
training_data:
path: data/training-mltable-folder
type: mltable
validation_data:
path: data/validation-mltable-folder
type: mltable
Computação para executar o experimento
Forneça um destino de computação para o ML automatizado realizar o treinamento do modelo. Os modelos de ML automatizados para tarefas de pesquisa visual computacional exigem SKUs de GPU e dão suporte às famílias NC e ND. Recomendamos a série NCsv3 (com GPUs v100) para um treinamento mais rápido. Um destino de computação com um SKU de VM com várias GPUs usa várias GPUs para também acelerar o treinamento. Além disso, ao configurar um destino de computação com vários nós, você poderá realizar um treinamento de modelo mais rápido por meio de paralelismo com o ajuste de hiperparâmetros para o modelo.
Observação
Se você estiver usando uma instância de computação como destino de computação, verifique se vários trabalhos de machine learning automatizado não são executados ao mesmo tempo. Além disso, verifique se esse max_concurrent_trials está definido como 1 em seus limites de trabalho.
O destino de computação é transmitido pelo uso do parâmetro compute. Por exemplo:
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
compute: azureml:gpu-cluster
Configurar experimentos
Para tarefas de pesquisa visual computacional, você pode iniciar avaliações individuais, varreduras manuais ou varreduras automáticas. É recomendável começar com uma varredura automática para obter um primeiro modelo de linha de base. Em seguida, você pode experimentar avaliações individuais com alguns modelos e configurações de hiperparâmetro. Por fim, com varreduras manuais, é possível explorar vários valores de hiperparâmetro próximos a modelos mais promissores e configurações de hiperparâmetro. Este fluxo de trabalho de três etapas (varredura automática, avaliações individuais, varreduras manuais) evita pesquisar a totalidade do espaço do hiperparâmetro, que cresce exponencialmente no número de hiperparâmetros.
Varreduras automáticas podem suspender resultados competitivos para muitos conjuntos de dados. Além disso, não exigem conhecimento avançado de arquiteturas de modelos, levam em conta as correlações de hiperparâmetros e funcionam perfeitamente em diferentes configurações de hardware. Todos esses motivos as tornam uma opção forte para o estágio inicial do processo de experimentação.
Métrica principal
Um trabalho de treinamento do AutoML usa uma métrica primária para otimização de modelo e ajuste de hiperparâmetro. A métrica primária depende do tipo de tarefa, conforme mostrado abaixo; no momento, não há suporte para outros valores de métrica primária.
- Precisão para classificação de imagem
- Interseção sobre união para classificação de imagens multirrótulo
- Precisão média para detecção de objetos da imagem
- Precisão média para segmentação de instância de imagem
Limites de trabalho
Você pode controlar os recursos gastos em seu trabalho de treinamento de Imagem de machine learning automatizado especificando timeout_minutes, max_trials e max_concurrent_trials para o trabalho nas configurações de limite, conforme descrito no exemplo abaixo.
| Parâmetro | Detalhe |
|---|---|
max_trials |
Parâmetro para número máximo de avaliações a serem varridas. Precisa ser um número inteiro entre 1 e 1000. Ao explorar apenas os hiperparâmetros padrão para determinado arquitetura de modelo, defina esse parâmetro como 1. O valor padrão é 1. |
max_concurrent_trials |
Número máximo de avaliações que podem ser feitas simultaneamente. Se especificado, o tempo limite deve ser um número inteiro entre 1 e 100. O valor padrão é 1. OBSERVAÇÃO: max_concurrent_trials é limitado a max_trials internamente. Por exemplo, se o usuário definir max_concurrent_trials=4, max_trials=2, os valores serão atualizados internamente como max_concurrent_trials=2, max_trials=2. |
timeout_minutes |
A quantidade de tempo em minutos antes do término do experimento. Se nada for especificado, o timeout_minutes padrão do experimento será de sete dias (máximo de 60 dias) |
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
limits:
timeout_minutes: 60
max_trials: 10
max_concurrent_trials: 2
Hiperparâmetros do modelo de varredura automática (AutoMode)
Importante
Esse recurso está atualmente em visualização pública. Essa versão prévia é fornecida sem um contrato de nível de serviço. Alguns recursos podem não ter suporte ou podem ter restrição de recursos. Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
É difícil prever a melhor arquitetura de modelo e os melhores hiperparâmetros para um conjunto de dados. Além disso, em alguns casos, o tempo humano alocado para ajustar hiperparâmetros pode ser limitado. Para tarefas de visão computacional, você pode especificar várias avaliações e o sistema determina automaticamente a região do espaço de hiperparâmetros a ser varrida. Não é necessário definir um espaço de pesquisa de hiperparâmetros, um método de amostragem ou uma política de encerramento antecipado.
Disparar o AutoMode
Para executar varreduras automáticas, defina max_trials como um valor maior que 1 em limits e não especifique o espaço de pesquisa, o método de amostragem e a política de encerramento. Chamamos essa funcionalidade de AutoMode; veja o exemplo a seguir.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
limits:
max_trials: 10
max_concurrent_trials: 2
Um número de tentativas entre 10 e 20 provavelmente funciona bem em muitos conjuntos de dados. O orçamento de tempo para o trabalho do AutoML ainda pode ser definido, mas será recomendável fazer isso somente se cada avaliação demorar muito.
Aviso
No momento, não há suporte para iniciar varreduras automáticas por meio da interface do usuário.
Avaliações individuais
Em avaliações individuais, você controla diretamente a arquitetura de modelo e os hiperparâmetros. A arquitetura do modelo é passado por meio do parâmetro model_name.
Arquiteturas de modelo com suporte
A tabela a seguir resume os modelos herdados com suporte para cada tarefa de visão computacional. Usar apenas esses modelos herdados disparará execuções usando o runtime herdado (em que cada execução individual ou avaliação é enviada como um trabalho de comando). Confira abaixo o suporte a HuggingFace e MMDetection.
| Tarefa | arquiteturas de modelo | Sintaxe de literal de cadeia de caracteresdefault_model* anotado com * |
|---|---|---|
| Classificação de imagens (várias classes e vários rótulos) |
MobileNet: modelos leves para aplicativos móveis ResNet: redes residuais ResNeSt: redes de atenção dividida ES-ResNeXt50: redes squeeze-and-excitation ViT: redes de transformador de pesquisa visual |
mobilenetv2 resnet18 resnet34 resnet50 resnet101 resnet152 resnest50 resnest101 seresnext vits16r224 (pequeno) vitb16r224* (base) vitl16r224 (grande) |
| Detecção de objetos | YOLOv5: modelo de detecção de objetos em uma fase RCNN ResNet FPN mais rápido: modelos de detecção de objetos em duas fases RetinaNet ResNet FPN: resolver desequilíbrio de classe com perda focal Observação: consulte o hiperparâmetro model_size para obter tamanhos de modelo YOLOv5. |
yolov5* fasterrcnn_resnet18_fpn fasterrcnn_resnet34_fpn fasterrcnn_resnet50_fpn fasterrcnn_resnet101_fpn fasterrcnn_resnet152_fpn retinanet_resnet50_fpn |
| Segmentação de instâncias | MaskRCNN ResNet FPN | maskrcnn_resnet18_fpn maskrcnn_resnet34_fpn maskrcnn_resnet50_fpn* maskrcnn_resnet101_fpn maskrcnn_resnet152_fpn |
Arquiteturas de modelo com suporte – HuggingFace e MMDetection (versão prévia)
Com o novo back-end executado nos pipelines do Azure Machine Learning, você também pode usar qualquer modelo de classificação de imagem do Hub HuggingFace que faz parte da biblioteca de transformadores (como microsoft/beit-base-patch16-224), bem como qualquer modelo de segmentação de instância ou detecção de objetos do MMDetection Versão 3.1.0 Model Zoo (como atss_r50_fpn_1x_coco).
Além de dar suporte a qualquer modelo do HuggingFace Transfomers e MMDetection 3.1.0, também oferecemos uma lista de modelos coletados dessas bibliotecas no registro azureml. Esses modelos coletados foram testados detalhadamente e usam hiperparâmetros padrão selecionados com parâmetros de comparação extensivos para garantir um treinamento eficaz. A tabela abaixo resume esses modelos coletados.
| Tarefa | arquiteturas de modelo | Sintaxe de literal de cadeia de caracteres |
|---|---|---|
| Classificação de imagens (várias classes e vários rótulos) |
BEiT ViT DeiT SwinV2 |
microsoft/beit-base-patch16-224-pt22k-ft22kgoogle/vit-base-patch16-224facebook/deit-base-patch16-224microsoft/swinv2-base-patch4-window12-192-22k |
| Detecção de objetos | Sparse R-CNN Deformable DETR VFNet YOLOF Swin |
mmd-3x-sparse-rcnn_r50_fpn_300-proposals_crop-ms-480-800-3x_cocommd-3x-sparse-rcnn_r101_fpn_300-proposals_crop-ms-480-800-3x_coco mmd-3x-deformable-detr_refine_twostage_r50_16xb2-50e_coco mmd-3x-vfnet_r50-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-vfnet_x101-64x4d-mdconv-c3-c5_fpn_ms-2x_coco mmd-3x-yolof_r50_c5_8x8_1x_coco |
| Segmentação de instâncias | Swin | mmd-3x-mask-rcnn_swin-t-p4-w7_fpn_1x_coco |
Atualizamos constantemente a lista de modelos coletados. Você pode obter a lista mais atualizada dos modelos coletados para uma determinada tarefa usando o SDK do Python:
credential = DefaultAzureCredential()
ml_client = MLClient(credential, registry_name="azureml")
models = ml_client.models.list()
classification_models = []
for model in models:
model = ml_client.models.get(model.name, label="latest")
if model.tags['task'] == 'image-classification': # choose an image task
classification_models.append(model.name)
classification_models
Saída:
['google-vit-base-patch16-224',
'microsoft-swinv2-base-patch4-window12-192-22k',
'facebook-deit-base-patch16-224',
'microsoft-beit-base-patch16-224-pt22k-ft22k']
O uso de qualquer modelo HuggingFace ou MMDetection disparará execuções usando componentes de pipeline. Se os modelos herdado e HuggingFace/MMdetection forem usados, todas as execuções/avaliações serão disparadas usando componentes.
Além de controlar a arquitetura de modelo, você também pode ajustar hiperparâmetros usados no treinamento do modelo. Embora muitos dos hiperparâmetros expostos independam do modelo, há instâncias em que os hiperparâmetros são específicos da tarefa do modelo. Saiba mais sobre os hiperparâmetros disponíveis para essas instâncias.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
Se você desejar usar os valores de hiperparâmetro padrão para uma determinada arquitetura (digamos yolov5), poderá especificá-lo usando a chave model_name na seção training_parameters. Por exemplo,
training_parameters:
model_name: yolov5
Hiperparâmetros de modelo de varredura manual
Ao treinar modelos de pesquisa visual computacional, o desempenho do modelo depende muito dos valores de hiperparâmetro selecionados. Muitas vezes, talvez seja melhor ajustar os hiperparâmetros para obter um desempenho ideal. Para tarefas da pesquisa visual computacional, você pode varrer hiperparâmetros a fim de encontrar as configurações ideais para seu modelo. Esse recurso aplica os recursos de ajuste de hiperparâmetros no Azure Machine Learning. Aprenda a ajustar hiperparâmetros.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
search_space:
- model_name:
type: choice
values: [yolov5]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.01
model_size:
type: choice
values: [small, medium]
- model_name:
type: choice
values: [fasterrcnn_resnet50_fpn]
learning_rate:
type: uniform
min_value: 0.0001
max_value: 0.001
optimizer:
type: choice
values: [sgd, adam, adamw]
min_size:
type: choice
values: [600, 800]
Defina o espaço de pesquisa de parâmetro
Você pode definir as arquiteturas de modelo e hiperparâmetros para varredura no espaço de parâmetro. É possível especificar uma única arquitetura de modelo ou vários.
- Confira Avaliações individuais para obter a lista de arquiteturas de modelos compatíveis de cada tipo de tarefa.
- Consulte Hiperparâmetros para tarefas de pesquisa visual computacional, hiperparâmetros para cada tipo de tarefa de pesquisa visual computacional.
- Veja detalhes sobre as distribuições com suporte em hiperparâmetros discretos e contínuos.
Métodos de amostragem para a varredura
Ao varrer hiperparâmetros, você precisará especificar o método de amostragem a ser usado na varredura do espaço de parâmetro definido. Atualmente, os seguintes métodos de amostragem são compatíveis com o parâmetro sampling_algorithm:
| Tipo de amostragem | Sintaxe do Trabalho do AutoML |
|---|---|
| Amostragem aleatória | random |
| Amostragem de grade | grid |
| Amostragem Bayesiana | bayesian |
Observação
Atualmente, apenas amostragem aleatória e de grade têm suporte para espaços de hiperparâmetros condicionais.
Políticas de término antecipado
Você pode encerrar automaticamente avaliações de baixo desempenho com uma política de término antecipado. O encerramento antecipado melhora a eficiência computacional, pois economiza recursos de computação que, de outra forma, seriam gastos em avaliações menos promissoras. O ML automatizado para imagens dá suporte às políticas de término antecipado abaixo por meio do parâmetro early_termination. Se nenhuma política de encerramento for especificada, todas as avaliações serão executadas até a conclusão.
| Política de término antecipado | Sintaxe do Trabalho do AutoML |
|---|---|
| Política Bandit | CLI v2: bandit SDK v2: BanditPolicy() |
| Política de Encerramento Mediana | CLI v2: median_stopping SDK v2: MedianStoppingPolicy() |
| Política de seleção de truncamento | CLI v2: truncation_selection SDK v2: TruncationSelectionPolicy() |
Saiba mais sobre como configurar a política de encerramento antecipado para a varredura de hiperparâmetros.
Observação
Para obter um exemplo de configuração de varredura completa, consulte este tutorial.
Você pode configurar todos os parâmetros relacionados à varredura, conforme mostrado no exemplo a seguir.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
sweep:
sampling_algorithm: random
early_termination:
type: bandit
evaluation_interval: 2
slack_factor: 0.2
delay_evaluation: 6
Configurações fixas
Você pode passar configurações ou parâmetros fixoa que não são alterados durante a varredura do espaço de parâmetros, conforme mostrado no exemplo a seguir.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
training_parameters:
early_stopping: True
evaluation_frequency: 1
Aumento de dados
Em geral, o desempenho do modelo de aprendizado profundo costuma melhorar com mais dados. O aumento de dados é uma técnica prática para ampliar o tamanho dos dados e a variabilidade de um conjunto de dados, o que ajuda a evitar o sobreajuste e a melhorar a capacidade de generalização do modelo em dados não vistos. O ML automatizado aplica técnicas de aumento de dados diferentes com base na tarefa de pesquisa visual computacional antes de alimentar o modelo com as imagens de entrada. Atualmente, não há nenhum hiperparâmetro exposto para controlar os aumentos de dados.
| Tarefa | Conjunto de dados afetado | Técnicas de aumento de dados aplicadas |
|---|---|---|
| Classificação de imagem (várias classes e vários rótulos) | Treinamento Validação e teste |
Redimensionamento e corte aleatórios, inversão horizontal, variação de cor (brilho, contraste, saturação e matiz), normalização usando a média e o desvio padrão da ImageNet em termos de canal Redimensionamento, corte centralizado, normalização |
| Detecção de objetos, segmentação de instância | Treinamento Validação e teste |
Corte aleatório em torno de caixas delimitadoras, expansão, inversão horizontal, normalização redimensionamento Normalização, redimensionamento |
| Detecção de objetos usando yolov5 | Treinamento Validação e teste |
Mosaico, afinidade aleatória (rotação, translação, escala, distorção), inversão horizontal Redimensionamento de letterbox |
Atualmente, os aumentos definidos acima são aplicados por padrão para um ML automatizado para trabalho de imagem. Para fornecer controle sobre os aumentos, o ML automatizado para imagens expõe abaixo de dois sinalizadores para desativar determinados aumentos. Atualmente, esses sinalizadores só têm suporte para tarefas de segmentação de instância e detecção de objetos.
- apply_mosaic_for_yolo: esse sinalizador é específico apenas para o modelo Yolo. A configuração como False desativa o aumento de dados do mosaico aplicado no momento do treinamento.
- apply_automl_train_augmentations: definir esse sinalizador como false desativa o aumento aplicado durante o tempo de treinamento para os modelos de segmentação de instância e detecção de objetos. Para aumentos, consulte os detalhes na tabela acima.
- Para o modelo de detecção de objetos não yolo e modelos de segmentação de instância, esse sinalizador desativa apenas os três primeiros aumentos. Por exemplo: corte aleatório em torno de caixas delimitadoras, expansão, inversão horizontal. Os aumentos de normalização e redimensionamento ainda são aplicados independentemente desse sinalizador.
- Para o modelo Yolo, esse sinalizador desativa os aumentos aleatórios similares e de inversão horizontal.
Esses dois sinalizadores têm suporte por meio de advanced_settings em training_parameters e podem ser controlados da maneira a seguir.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
training_parameters:
advanced_settings: >
{"apply_mosaic_for_yolo": false}
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false}
Observe que esses dois sinalizadores são independentes um do outro e também podem ser usados em combinação usando as configurações a seguir.
training_parameters:
advanced_settings: >
{"apply_automl_train_augmentations": false, "apply_mosaic_for_yolo": false}
Em nossos experimentos, descobrimos que esses aumentos ajudam o modelo a generalizar melhor. Portanto, quando esses aumentos são desligados, recomendamos que os usuários os combinem com outros aumentos offline para obter melhores resultados.
Treinamento incremental (opcional)
Após a conclusão do trabalho de treinamento, você pode optar por treinar ainda mais o modelo carregando o ponto de verificação do modelo treinado. Você pode usar o mesmo conjunto de dados ou um diferente para treinamento incremental. Se estiver satisfeito com o modelo, você pode optar por interromper o treinamento e usar o modelo atual.
Passar o ponto de verificação via ID do trabalho
Você pode passar a ID do trabalho da qual você deseja carregar o ponto de verificação.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
training_parameters:
checkpoint_run_id : "target_checkpoint_run_id"
Enviar o trabalho do AutoML
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
Para enviar seu trabalho do AutoML, execute o seguinte comando da CLI v2 com o caminho para o arquivo .yml, o nome do workspace, o grupo de recursos e a ID da assinatura.
az ml job create --file ./hello-automl-job-basic.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Métricas de avaliação e saídas
Os trabalhos de treinamento do ML automatizado geram arquivos de modelo de saída, métricas de avaliação, logs e artefatos de implantação, como o arquivo de pontuação e o arquivo de ambiente. Esses arquivos e métricas podem ser visualizados na guia de saídas, logs e métricas dos trabalhos filho.
Dica
Confira como navegar até os resultados do trabalho na seção Exibir resultados do trabalho.
Para obter definições e exemplos dos gráficos e métricas de desempenho fornecidos para cada trabalho, confira Avaliar resultados do experimento de machine learning automatizado.
Registro e implantação do modelo
Quando o trabalho for concluído, você poderá registrar o modelo que foi criado da melhor avaliação (configuração que resultou na melhor métrica primária). Você pode registrar o modelo após o download ou especificando o caminho azureml com jobid correspondente. Observação: quando quiser alterar as configurações de inferência descritas abaixo, baixe o modelo, altere o settings.json e registre-se usando a pasta do modelo atualizado.
Obter a melhor avaliação
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
CLI example not available, please use Python SDK.
registrar o modelo
Registre o modelo usando o caminho azureml ou o caminho baixado localmente.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
az ml model create --name od-fridge-items-mlflow-model --version 1 --path azureml://jobs/$best_run/outputs/artifacts/outputs/mlflow-model/ --type mlflow_model --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Depois de registrar o modelo que deseja usar, você pode implantá-lo usando o ponto de extremidade online gerenciado deploy-managed-online-endpoint
Configurar o ponto de extremidade online
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: od-fridge-items-endpoint
auth_mode: key
Criar o ponto de extremidade
Usando o MLClient que já foi criado, criamos o ponto de extremidade no workspace. Esse comando inicia a criação do ponto de extremidade e retorna uma resposta de confirmação enquanto a criação do ponto de extremidade continuar.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
az ml online-endpoint create --file .\create_endpoint.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Configurar a implantação online
Uma implantação é um conjunto de recursos necessários para hospedar o modelo que executa a inferência real. Criaremos uma implantação do ponto de extremidade usando a classe ManagedOnlineDeployment. Você pode usar SKUs de VM com GPU ou CPU como cluster de implantação.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
name: od-fridge-items-mlflow-deploy
endpoint_name: od-fridge-items-endpoint
model: azureml:od-fridge-items-mlflow-model@latest
instance_type: Standard_DS3_v2
instance_count: 1
liveness_probe:
failure_threshold: 30
success_threshold: 1
timeout: 2
period: 10
initial_delay: 2000
readiness_probe:
failure_threshold: 10
success_threshold: 1
timeout: 10
period: 10
initial_delay: 2000
Criar a implantação
Usando o MLClient que já foi criado, vamos criar a implantação no workspace. Esse comando iniciará a criação da implantação e retornará uma resposta de confirmação enquanto a criação da implantação continuar.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
az ml online-deployment create --file .\create_deployment.yml --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
atualizar o tráfego:
Por padrão, a implantação atual está definida para receber 0% de tráfego. você pode definir o percentual de tráfego que a implantação atual deve receber. A soma dos percentuais de tráfego de todas as implantações com um ponto de extremidade não deve exceder 100%.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
az ml online-endpoint update --name 'od-fridge-items-endpoint' --traffic 'od-fridge-items-mlflow-deploy=100' --workspace-name [YOUR_AZURE_WORKSPACE] --resource-group [YOUR_AZURE_RESOURCE_GROUP] --subscription [YOUR_AZURE_SUBSCRIPTION]
Como alternativa, você pode implantar o modelo na interface do usuário do Estúdio do Azure Machine Learning. Navegue até o modelo que você deseja implantar na guia Modelos do trabalho de ML automatizado e selecione Implantar e Implantar no ponto de extremidade em tempo real.
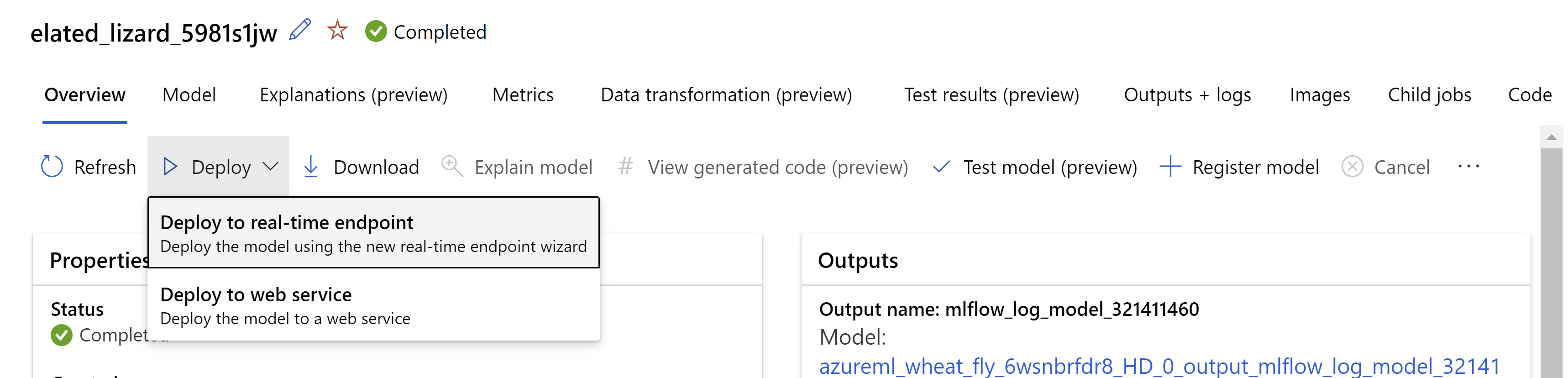 .
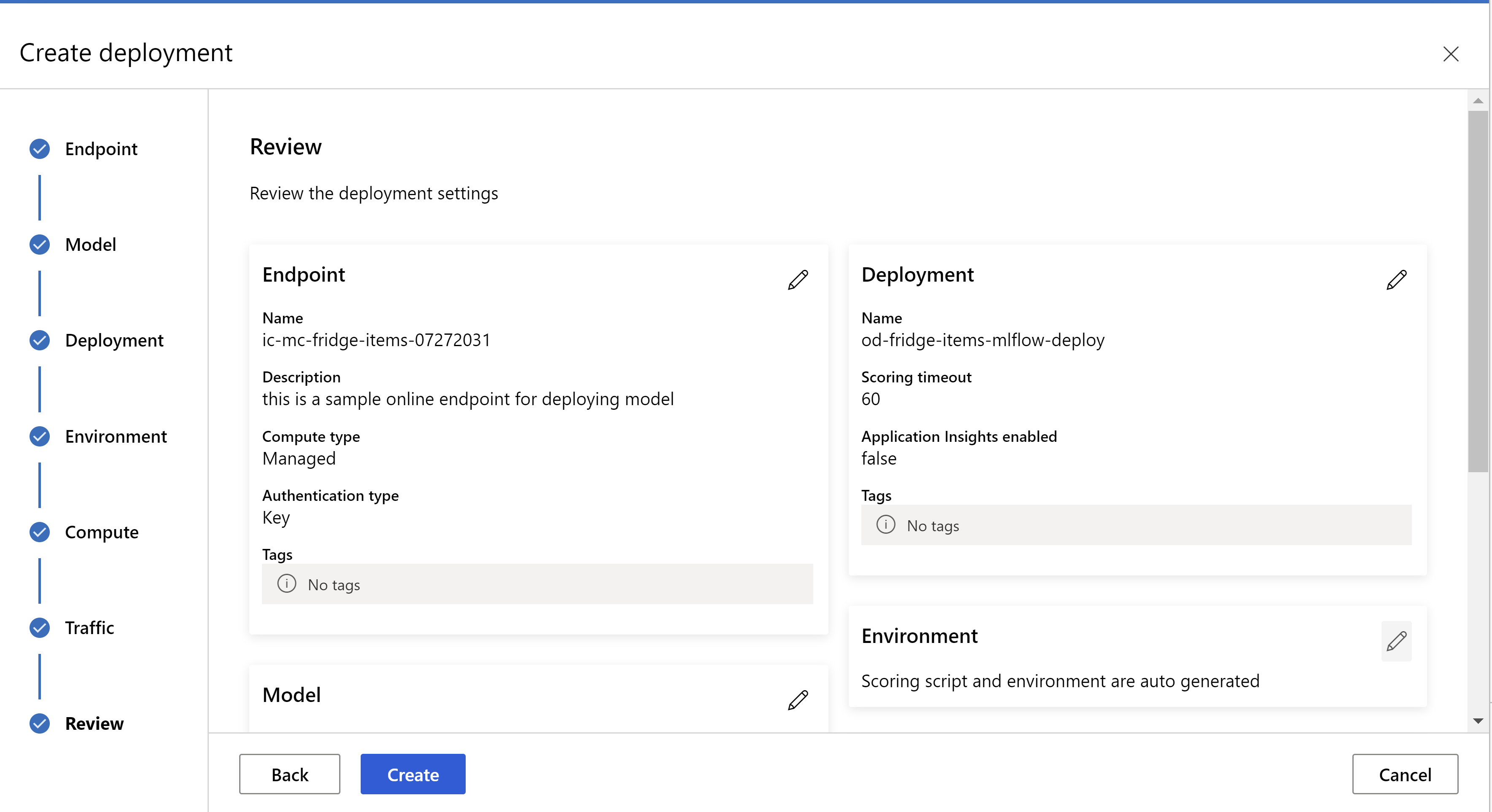
.
esta é a aparência da sua página de revisão. podemos selecionar o tipo de instância e a contagem de instâncias e definir o percentual de tráfego para a implantação atual.
 .
.
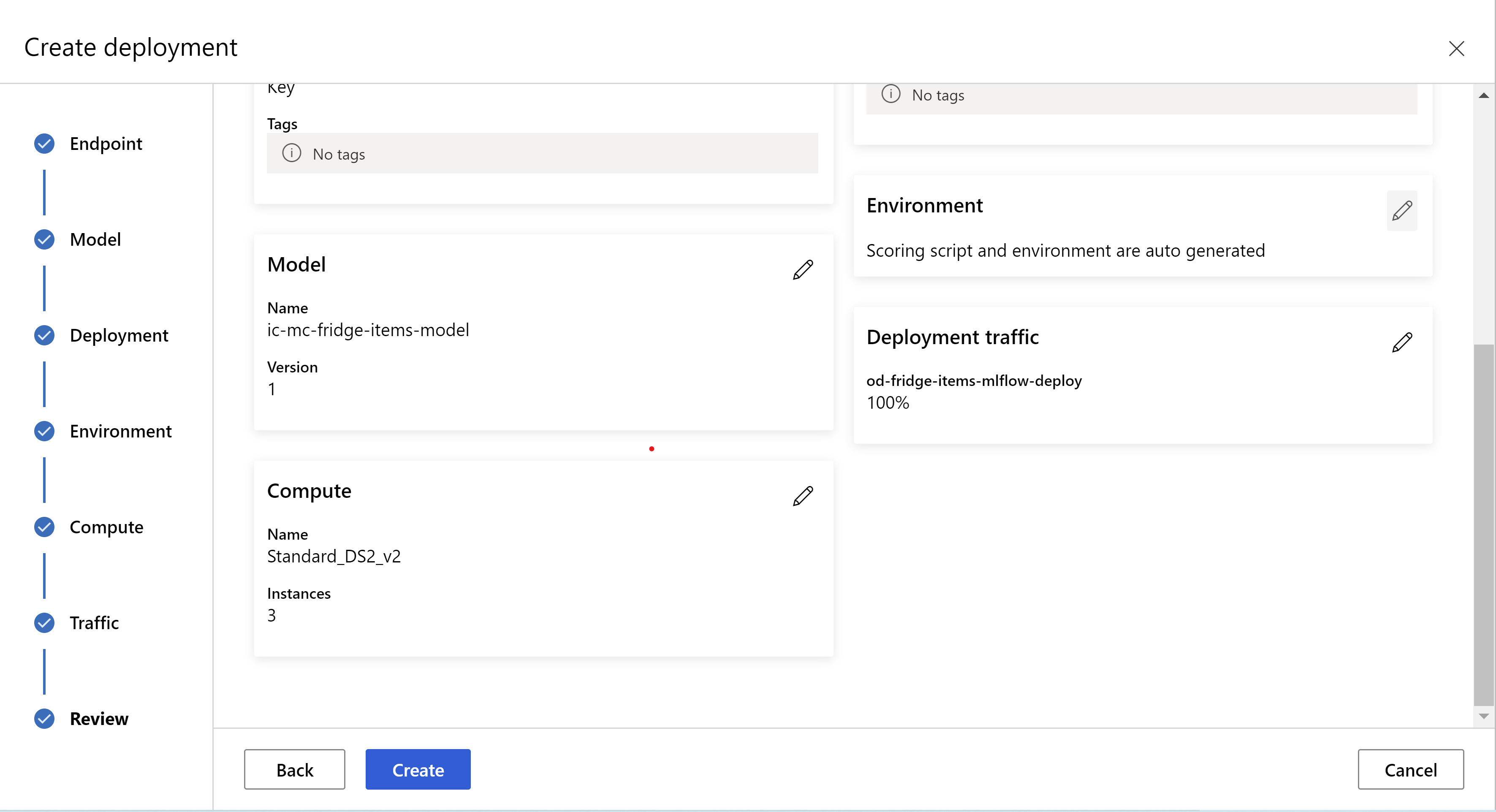 .
.
Atualizar configurações de inferência
Na etapa anterior, baixamos um arquivo mlflow-model/artifacts/settings.json do melhor modelo. que pode ser usado para atualizar as configurações de inferência antes de registrar o modelo. Embora seja recomendado usar os mesmos parâmetros do treinamento para melhor desempenho.
Cada uma das tarefas (e alguns modelos) tem um conjunto de parâmetros. Por padrão, usamos os mesmos valores dos parâmetros que foram usados durante o treinamento e a validação. Dependendo do comportamento que buscamos ao usar o modelo de inferência, podemos alterar esses parâmetros. Abaixo, você pode encontrar uma lista de parâmetros para cada tipo de tarefa e modelo.
| Tarefa | Nome do parâmetro | Padrão |
|---|---|---|
| Classificação de imagem (várias classes e vários rótulos) | valid_resize_sizevalid_crop_size |
256 224 |
| Detecção de objetos | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_img |
600 1333 0.3 0,5 100 |
Detecção de objetos usando yolov5 |
img_sizemodel_sizebox_score_threshnms_iou_thresh |
640 média 0,1 0,5 |
| Segmentação de instâncias | min_sizemax_sizebox_score_threshnms_iou_threshbox_detections_per_imgmask_pixel_score_thresholdmax_number_of_polygon_pointsexport_as_imageimage_type |
600 1333 0.3 0,5 100 0,5 100 Falso JPG |
Para obter uma descrição detalhada dos hiperparâmetros específicos da tarefa, consulte Hiperparâmetros para tarefas de visão computacional no machine learning automatizado.
Se você quiser usar blocos e desejar controlar o comportamento dos blocos, os seguintes parâmetros estarão disponíveis: tile_grid_size, tile_overlap_ratio e tile_predictions_nms_thresh. Para obter mais detalhes sobre esses parâmetros, verifique Treinar um pequeno modelo de detecção de objetos usando o AutoML.
Teste a implantação
Verifique esta seção Testar a implantação para testar a implantação e visualizar as detecções do modelo.
Gerar explicações para previsões
Importante
Essas configurações estão atualmente em visualização pública. Eles são fornecidos sem um acordo de nível de serviço. Alguns recursos podem não ter suporte ou podem ter restrição de recursos. Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
Aviso
A Explicabilidade do Modelo tem suporte apenas para classificação de várias classes e classificação de vários rótulos.
Algumas das vantagens de usar a XAI (IA Explicável) com o AutoML para imagens:
- Melhora a transparência nas previsões complexas do modelo de visão
- Ajuda os usuários a entender os recursos/pixels importantes na imagem de entrada que estão contribuindo para as previsões do modelo
- Ajuda na solução de problemas dos modelos
- Ajuda a descobrir o desvio
Explicações
Explicações são atributos de recursos ou pesos dados a cada pixel na imagem de entrada de acordo com sua contribuição para a previsão do modelo. Cada peso pode ser negativo (correlacionado negativamente com a previsão) ou positivo (correlacionado positivamente com a previsão). Essas atribuições são calculadas em relação à classe prevista. Para a classificação de várias classes, exatamente uma matriz de atribuição de tamanho [3, valid_crop_size, valid_crop_size] é gerada por exemplo, enquanto que para a classificação de vários rótulos, a matriz de atribuição de tamanho [3, valid_crop_size, valid_crop_size] é gerada para cada rótulo/classe previsto para cada exemplo.
Usando a IA Explicável no AutoML para imagens no ponto de extremidade implantado, os usuários podem obter visualizações de explicações (atribuições sobrepostas em uma imagem de entrada) e/ou atribuições (matriz multidimensional de tamanho [3, valid_crop_size, valid_crop_size]) para cada imagem. Além das visualizações, os usuários também podem obter matrizes de atribuição para obter mais controle sobre as explicações (como gerar visualizações personalizadas usando atribuições ou examinar segmentos de atribuições). Todos os algoritmos de explicação usam imagens quadradas cortadas com tamanho valid_crop_size para gerar atribuições.
As explicações podem ser geradas do ponto de extremidade online ou do ponto de extremidade em lote. Depois que a implantação for concluída, esse ponto de extremidade poderá ser utilizado para gerar as explicações para previsões. Nas implantações online, passe o parâmetro request_settings = OnlineRequestSettings(request_timeout_ms=90000) para ManagedOnlineDeployment e defina request_timeout_ms como seu valor máximo para evitar problemas de tempo limite ao gerar explicações (consulte a seção Registrar e implantar modelo). Alguns dos métodos de explicabilidade (XAI) como xrai consomem mais tempo (especialmente para classificação de vários rótulos, pois precisamos gerar atribuições e/ou visualizações em cada rótulo previsto). Portanto, é recomendável qualquer instância de GPU para obter explicações mais rápidas. Para obter mais informações sobre o esquema de entrada e saída para gerar explicações, consulte os documentos do esquema.
Damos suporte aos seguintes algoritmos de explicabilidade de última geração no AutoML para imagens:
- XRAI (xrai)
- Gradientes integrados (integrated_gradients)
- GradCAM guiado (guided_gradcam)
- BackPropagation guiado (guided_backprop)
A tabela a seguir descreve os parâmetros de ajuste específicos do algoritmo de explicabilidade para XRAI e Gradientes Integrados. A retropropagação guiada e o gradcam guiado não exigem parâmetros de ajuste.
| Algoritmo XAI | Parâmetros específicos do algoritmo | Valores padrão |
|---|---|---|
xrai |
1. n_steps: o número de etapas usadas pelo método de aproximação. Um número maior de etapas leva a melhores aproximações de atribuições (explicações). O intervalo de n_steps é [2, inf), mas o desempenho das atribuições começa a convergir após 50 etapas. Optional, Int 2. xrai_fast: se deseja usar uma versão mais rápida do XRAI. se True, o tempo de computação para explicações é mais rápido, mas leva a explicações menos precisas (atribuições) Optional, Bool |
n_steps = 50 xrai_fast = True |
integrated_gradients |
1. n_steps: o número de etapas usadas pelo método de aproximação. Um número maior de etapas leva a melhores atribuições (explicações). O intervalo de n_steps é [2, inf), mas o desempenho das atribuições começa a convergir após 50 etapas.Optional, Int 2. approximation_method: método para aproximar o integral. Os métodos de aproximação disponíveis são riemann_middle e gausslegendre.Optional, String |
n_steps = 50 approximation_method = riemann_middle |
Internamente, o algoritmo XRAI usa gradientes integrados. Portanto, o parâmetro n_steps é exigido por gradientes integrados e algoritmos XRAI. Um número maior de etapas consome mais tempo para aproximar as explicações, e isso pode resultar em problemas de tempo limite no ponto de extremidade online.
É recomendável usar algoritmos de XRAI > GradCAM guiado > Gradientes integrados > BackPropagation guiado para obter melhores explicações, enquanto BackPropagation guiado > GradCAM guiado > Gradients integrados > XRAI são recomendados para obter explicações mais rápidas na ordem especificada.
Uma solicitação de exemplo para o ponto de extremidade online é semelhante à seguinte. Essa solicitação gera explicações quando model_explainability é definido como True. A solicitação a seguir gera visualizações e atribuições usando uma versão mais rápida do algoritmo XRAI com 50 etapas.
import base64
import json
def read_image(image_path):
with open(image_path, "rb") as f:
return f.read()
sample_image = "./test_image.jpg"
# Define explainability (XAI) parameters
model_explainability = True
xai_parameters = {"xai_algorithm": "xrai",
"n_steps": 50,
"xrai_fast": True,
"visualizations": True,
"attributions": True}
# Create request json
request_json = {"input_data": {"columns": ["image"],
"data": [json.dumps({"image_base64": base64.encodebytes(read_image(sample_image)).decode("utf-8"),
"model_explainability": model_explainability,
"xai_parameters": xai_parameters})],
}
}
request_file_name = "sample_request_data.json"
with open(request_file_name, "w") as request_file:
json.dump(request_json, request_file)
resp = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
deployment_name=deployment.name,
request_file=request_file_name,
)
predictions = json.loads(resp)
Para obter mais informações sobre como gerar explicações, consulte Exemplos de repositório de notebooks do GitHub para machine learning automatizado.
Interpretar visualizações
O ponto de extremidade implantado retornará a cadeia de caracteres de imagem codificada em base64 se model_explainability e visualizations estiverem definidos como True. Decodifique a cadeia de caracteres base64 conforme descrito em notebooks ou use o código a seguir para decodificar e visualizar as cadeias de caracteres de imagem base64 na previsão.
import base64
from io import BytesIO
from PIL import Image
def base64_to_img(base64_img_str):
base64_img = base64_img_str.encode("utf-8")
decoded_img = base64.b64decode(base64_img)
return BytesIO(decoded_img).getvalue()
# For Multi-class classification:
# Decode and visualize base64 image string for explanations for first input image
# img_bytes = base64_to_img(predictions[0]["visualizations"])
# For Multi-label classification:
# Decode and visualize base64 image string for explanations for first input image against one of the classes
img_bytes = base64_to_img(predictions[0]["visualizations"][0])
image = Image.open(BytesIO(img_bytes))
A imagem a seguir descreve a Visualização de explicações para uma imagem de entrada de exemplo.

A figura base64 decodificada tem quatro seções de imagem em uma grade 2 x 2.
- Imagem no canto superior esquerdo (0, 0) é a imagem de entrada cortada
- A imagem no canto superior direito (0, 1) é o mapa de calor de atribuições em uma escala de cores bgyw (azul verde amarelo branco), em que a contribuição de pixels brancos na classe prevista é a mais alta e os pixels azuis são os mais baixos.
- A imagem no canto inferior esquerdo (1, 0) é um mapa de calor combinado de atribuições na imagem de entrada cortada
- A imagem no canto inferior direito (1, 1) é a imagem de entrada cortada com os 30% superiores dos pixels de acordo com as pontuações de atribuição.
Interpretar atribuições
O ponto de extremidade implantado retornará atribuições se model_explainability e attributions estiverem definidos como True. Para obter mais detalhes, consulte notebooks de classificação de várias classes e de classificação de vários rótulos.
Essas atribuições dão mais controle aos usuários para gerar visualizações personalizadas ou examinar pontuações de atribuição no nível de pixel. O snippet de código a seguir descreve uma maneira de gerar visualizações personalizadas usando a matriz de atribuição. Para obter mais informações sobre o esquema de atribuições para classificação de várias classes e classificação de vários rótulos, consulte os documentos do esquema.
Use os valores exatos valid_resize_size e valid_crop_size do modelo selecionado para gerar as explicações (os valores padrão são 256 e 224, respectivamente). O código a seguir usa a funcionalidade de visualização Captum para gerar visualizações personalizadas. Os usuários podem utilizar qualquer outra biblioteca para gerar visualizações. Para obter mais detalhes, consulte os utilitários de visualização captum.
import colorcet as cc
import numpy as np
from captum.attr import visualization as viz
from PIL import Image
from torchvision import transforms
def get_common_valid_transforms(resize_to=256, crop_size=224):
return transforms.Compose([
transforms.Resize(resize_to),
transforms.CenterCrop(crop_size)
])
# Load the image
valid_resize_size = 256
valid_crop_size = 224
sample_image = "./test_image.jpg"
image = Image.open(sample_image)
# Perform common validation transforms to get the image used to generate attributions
common_transforms = get_common_valid_transforms(resize_to=valid_resize_size,
crop_size=valid_crop_size)
input_tensor = common_transforms(image)
# Convert output attributions to numpy array
# For Multi-class classification:
# Selecting attribution matrix for first input image
# attributions = np.array(predictions[0]["attributions"])
# For Multi-label classification:
# Selecting first attribution matrix against one of the classes for first input image
attributions = np.array(predictions[0]["attributions"][0])
# visualize results
viz.visualize_image_attr_multiple(np.transpose(attributions, (1, 2, 0)),
np.array(input_tensor),
["original_image", "blended_heat_map"],
["all", "absolute_value"],
show_colorbar=True,
cmap=cc.cm.bgyw,
titles=["original_image", "heatmap"],
fig_size=(12, 12))
Grandes conjuntos de dados
Se você estiver usando o machine learning automatizado para treinar em grandes conjuntos de dados, há algumas configurações experimentais que podem ser úteis.
Importante
Essas configurações estão atualmente em visualização pública. Eles são fornecidos sem um acordo de nível de serviço. Alguns recursos podem não ter suporte ou podem ter restrição de recursos. Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
Treinamento de vários GPUs e vários nós
Por padrão, cada modelo é treinado em uma única VM. Se o treinamento de um modelo estiver demorando muito, o uso de VMs que contêm várias GPUs poderá ajudar. O tempo para treinar um modelo em conjuntos de dados grandes deve diminuir em proporção aproximadamente linear ao número de GPUs usadas. (Por exemplo, um modelo deve treinar aproximadamente duas vezes mais rápido em uma VM com duas GPUs do que em uma VM com uma GPU.) Se o tempo para treinar um modelo ainda for alto em uma VM com várias GPUs, você poderá aumentar o número de VMs usadas para treinar cada modelo. Semelhante ao treinamento de várias GPUs, o tempo para treinar um modelo em grandes conjuntos de dados também deve diminuir em proporção aproximadamente linear ao número de VMs usadas. Ao treinar um modelo em várias VMs, use uma SKU de computação que dê suporte ao InfiniBand para obter melhores resultados. Você pode configurar o número de VMs usadas para treinar um único modelo definindo a propriedade node_count_per_trial do trabalho de machine learning automatizado.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
properties:
node_count_per_trial: "2"
Transmissão de arquivos de imagem do armazenamento
Por padrão, todos os arquivos de imagem são baixados no disco antes do treinamento do modelo. Se o tamanho dos arquivos de imagem for maior do que o espaço em disco disponível, o trabalho falhará. Em vez de baixar todas as imagens para o disco, você pode selecionar transmitir arquivos de imagem do armazenamento do Azure conforme necessário durante o treinamento. Os arquivos de imagem são transmitidos do armazenamento do Azure diretamente para a memória do sistema, ignorando o disco. Ao mesmo tempo, o maior número possível de arquivos do armazenamento é armazenado em cache no disco para minimizar o número de solicitações para o armazenamento.
Observação
Se a transmissão estiver habilitada, verifique se a conta de armazenamento do Azure está localizada na mesma região que a computação para minimizar o custo e a latência.
APLICA-SE A: Extensão de ML da CLI do Azurev2 (atual)
training_parameters:
advanced_settings: >
{"stream_image_files": true}
Blocos de anotações de exemplo
Examine exemplos de código detalhados e casos de uso no Repositório do notebook do GitHub para obter amostras de machine learning automatizado. Verifique as pastas com o prefixo "automl-image-" para obter exemplos específicos para a criação de modelos de visão computacional.
Exemplos de código
Examine exemplos de código detalhados e casos de uso no Repositório azureml-examples para obter amostras de machine learning automatizado.