Executar a distribuição segura de novas implantações para inferência em tempo real
APLICA-SE A: Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Neste artigo, você vai aprender a implantar uma nova versão do modelo de machine learning em produção sem causar nenhuma interrupção. Você usará a estratégia de implantação azul-verde, também conhecida como uma estratégia de distribuição segura, para introduzir uma nova versão de um serviço Web em produção. Essa estratégia permitirá que você implemente sua nova versão do serviço Web a um pequeno subconjunto de usuários ou solicitações antes de implantá-la completamente.
Este artigo pressupõe que você esteja usando pontos de extremidade online, ou seja, pontos de extremidade usados para inferência online (em tempo real). Há dois tipos de pontos de extremidade online: pontos de extremidade online gerenciados e pontos de extremidade online do Kubernetes. Para obter mais informações sobre pontos de extremidade e diferenças entre pontos de extremidade online gerenciados e pontos de extremidade online do Kubernetes, confira O que são pontos de extremidade do Azure Machine Learning?.
O exemplo principal neste artigo usa pontos de extremidade online gerenciados para implantação. Para usar os pontos de extremidade do Kubernetes, confira as observações neste documento que estão alinhadas à discussão sobre os pontos de extremidade online gerenciados.
Neste artigo, você aprenderá a:
- Definir um ponto de extremidade online e uma implantação chamada "azul" para atender à versão 1 de um modelo
- Escalar a implantação azul para que ela possa lidar com mais solicitações
- Implantar a versão 2 do modelo (chamada de implantação "verde") no ponto de extremidade, mas enviar a implantação sem tráfego dinâmico
- Testar a implantação verde em isolamento
- Espelhar um percentual do tráfego dinâmico para a implantação verde para validá-lo
- Envie um pequeno percentual de tráfego dinâmico para a implantação verde
- Enviar todo o tráfego dinâmico para a implantação verde
- Excluir a implantação azul da v1 agora não usada
Pré-requisitos
Antes de seguir as etapas neste artigo, verifique se você tem os seguintes pré-requisitos:
A CLI do Azure e a
mlextensão na CLI do Azure. Para obter mais informações, confira Instalar, configurar e usar a CLI (v2).Importante
Os exemplos de CLI neste artigo pressupõem que você esteja usando o shell Bash (ou compatível). Por exemplo, de um sistema Linux ou Subsistema do Windows para Linux.
Um Workspace do Azure Machine Learning. Se você não tiver um, use as etapas em Instalar, configurar e usar a CLI (v2) para criar.
O RBAC do Azure (controle de acesso baseado em função) do Azure é usado para permitir acesso a operações no Azure Machine Learning. Para executar as etapas neste artigo, sua conta de usuário deve receber a função de proprietário ou colaborador para o espaço de trabalho do Azure Machine Learning ou uma função personalizada que permita
Microsoft.MachineLearningServices/workspaces/onlineEndpoints/*. Para obter mais informações, consulte Gerenciar acesso a um workspace do Azure Machine Learning.(Opcional) Para implantar localmente, você deve instalar o Mecanismo do Docker em seu computador local. Recomendamos enfaticamente esta opção, pois assim é mais fácil depurar problemas.
Preparar seu sistema
Definir variáveis de ambiente
Se você ainda não definiu os padrões da CLI do Azure, salve as configurações padrão. Para evitar passar os valores para sua assinatura, espaço de trabalho e grupo de recursos várias vezes, execute este código:
az account set --subscription <subscription id>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Clone o repositório de exemplos
Para acompanhar este artigo, primeiro clone o repositório de exemplos (azureml-examples). Em seguida, vá para o diretório cli/ do repositório:
git clone --depth 1 https://github.com/Azure/azureml-examples
cd azureml-examples
cd cli
Dica
Use --depth 1 para clonar apenas o commit mais recente para o repositório. Isso reduz o tempo para concluir a operação.
Os comandos deste tutorial estão no arquivo deploy-safe-rollout-online-endpoints.sh no diretório cli, e os arquivos de configuração YAML estão no subdiretório endpoints/online/managed/sample/.
Observação
Os arquivos de configuração YAML para pontos de extremidade online do Kubernetes estão no subdiretório endpoints/online/kubernetes/.
Definir o ponto de extremidade e a implantação
Os pontos de extremidade online são usados para inferência online (em tempo real). Os pontos de extremidade online contêm implantações que estão prontas para receber dados de clientes e podem retornar respostas em tempo real.
Definir um ponto de extremidade
A tabela a seguir lista os atributos de chave a serem especificados quando você define um ponto de extremidade.
| Atributo | Descrição |
|---|---|
| Nome | Obrigatórios. Nome do ponto de extremidade. O valor precisa ser exclusivo na região do Azure. Para obter mais informações sobre as regras de nomenclatura, confira limites de pontos de extremidade. |
| Modo de autenticação | O método de autenticação para o ponto de extremidade. Escolha entre a autenticação baseada em chave key e a autenticação baseada em token do Azure Machine Learning aml_token. Uma chave não expira, mas um token sim. Para obter mais informações sobre autenticação, confira Autenticação em um ponto de extremidade online. |
| Descrição | Descrição do ponto de extremidade. |
| Marcas | Dicionário de tags para o ponto de extremidade. |
| Tráfego | Regras sobre como rotear o tráfego entre implantações. Ele é representado por um dicionário de pares chave-valor, em que as chaves representam o nome e o valor da implantação representam a porcentagem de tráfego para essa implantação. Você pode definir o tráfego somente quando as implantações em um ponto de extremidade tiverem sido criadas. Você pode atualizar o tráfego para um ponto de extremidade online após as implantações terem sido criadas usando. Para obter mais informações sobre como usar o tráfego espelhado, consulte Alocar uma pequena porcentagem de tráfego dinâmico para a nova implantação. |
| Tráfego espelho | Porcentagem de tráfego dinâmico para espelhar para uma implantação. Para obter mais informações sobre como usar o tráfego espelhado, consulte Testar a implantação com tráfego espelhado. |
Para ver uma lista completa de atributos que você pode especificar ao criar um ponto de extremidade, consulte Esquema YAML do ponto de extremidade online da CLI (v2) ou Classe ManagedOnlineEndpoint do SDK (v2).
Definir uma implantação
Uma implantação é um conjunto de recursos necessários para hospedar o modelo que executa a inferência real. A tabela a seguir descreve os principais atributos a serem especificados quando você define uma implantação.
| Atributo | Descrição |
|---|---|
| Nome | Obrigatórios. Nome da implantação. |
| Nome do ponto de extremidade | Obrigatórios. O nome do ponto de extremidade no qual criar a implantação. |
| Modelar | O modelo a ser usado para a implantação. Esse valor pode ser uma referência a um modelo com versão existente no workspace ou uma especificação de modelo embutida. No exemplo, temos um modelo scikit-learn que faz regressão. |
| Caminho do código | O diretório no ambiente de desenvolvimento local que contém todo o código-fonte do Python para pontuar o modelo. Você pode usar diretórios e pacotes aninhados. |
| Script de pontuação | O código executa o modelo em uma determinada solicitação de entrada. Esse valor pode ser o caminho relativo para o arquivo de pontuação no diretório do código-fonte Este script de pontuação recebe os dados enviados para um serviço Web implantado e os transmite ao modelo. Em seguida, o script executa o modelo e retorna sua resposta ao cliente. O script de pontuação é específico para seu modelo e deve compreender os dados que o modelo espera como entrada e retorna como saída. Nesse caso, temos um arquivo score.py. Esse código Python precisa ter uma função init() e uma função run(). A função init() será chamada depois que o modelo for criado ou atualizado (você pode usá-la para armazenar o modelo em cache na memória, por exemplo). A função run() é chamada em cada invocação do ponto de extremidade para fazer a pontuação e previsão real. |
| Ambiente | Obrigatórios. Contém os detalhes do ambiente para hospedar o modelo e o código. Esse valor pode ser uma referência para um ambiente com versão existente no espaço de trabalho ou uma especificação de ambiente embutido. O ambiente pode ser uma imagem do Docker com dependências do Conda, um Dockerfile ou um ambiente registrado. |
| Tipo de instância | Obrigatórios. O tamanho da VM a ser usado para a implantação. Para obter a lista de tamanhos com suporte, confira Lista de SKU de pontos de extremidade online gerenciados. |
| Contagem de instâncias | Obrigatórios. O número de instâncias a serem usadas para a implantação. Baseie o valor na carga de trabalho esperada. Para alta disponibilidade, recomendamos que você defina o valor mínimo de 3 Reservamos mais 20% para executar atualizações. Para obter mais informações, confira limites de pontos de extremidade online. |
Para ver uma lista completa de atributos que você pode especificar ao criar uma implantação, consulte Esquema YAML do ponto de extremidade online da CLI (v2) ou Classe ManagedOnlineEndpoint do SDK (v2).
Criar um ponto de extremidade online
Primeiro defina o nome do ponto de extremidade e configure-o. Neste artigo, você usará o arquivo endpoints/online/managed/sample/endpoint.yml para configurar o ponto de extremidade. O seguinte snippet mostra o conteúdo do arquivo:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineEndpoint.schema.json
name: my-endpoint
auth_mode: key
A referência para o formato de ponto de extremidade YAML é descrita na tabela a seguir. Para saber como especificar esses atributos, consulte areferência do YAML para ponto de extremidade online . Para obter informações sobre os limites relacionados aos pontos de extremidade online, confira os limites de pontos de extremidade online.
| Key | Descrição |
|---|---|
$schema |
(Opcional) O esquema YAML. Para ver todas as opções disponíveis no arquivo YAML, você pode visualizar o esquema no exemplo anterior em um navegador. |
name |
O nome do ponto de extremidade. |
auth_mode |
Use key para autenticação baseada em chave. Use aml_token para autenticação baseada em chave do Azure Machine Learning. Para obter um token mais recente, use o comando az ml online-endpoint get-credentials. |
Para criar um ponto de extremidade online:
Defina o nome do ponto de extremidade:
Para Unix, execute este comando (substitua
YOUR_ENDPOINT_NAMEpor um nome exclusivo):export ENDPOINT_NAME="<YOUR_ENDPOINT_NAME>"Importante
Os nomes de ponto de extremidade devem ser exclusivos dentro de uma região do Azure. Por exemplo, na região
westus2do Azure, pode haver apenas um ponto de extremidade com o nomemy-endpoint.Criar o ponto de extremidade na nuvem:
Execute o seguinte código para usar o arquivo
endpoint.ymlpara configurar o ponto de extremidade:az ml online-endpoint create --name $ENDPOINT_NAME -f endpoints/online/managed/sample/endpoint.yml
Criar a implantação 'blue'
Neste artigo, você usará o arquivo endpoints/online/managed/sample/blue-deployment.yml para configurar os principais aspectos da implantação. O seguinte snippet mostra o conteúdo do arquivo:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: blue
endpoint_name: my-endpoint
model:
path: ../../model-1/model/
code_configuration:
code: ../../model-1/onlinescoring/
scoring_script: score.py
environment:
conda_file: ../../model-1/environment/conda.yaml
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04:latest
instance_type: Standard_DS3_v2
instance_count: 1
Para criar uma implantação chamada blue para o ponto de extremidade, execute o seguinte comando para usar o arquivoblue-deployment.yml para configurar
az ml online-deployment create --name blue --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/blue-deployment.yml --all-traffic
Importante
O sinalizador --all-traffic no az ml online-deployment create aloca 100% do tráfego do ponto de extremidade para a implantação azul recém-criada.
No arquivoblue-deployment.yaml, especificamos o path (local de onde carregar os arquivos) em linha. A CLI carrega automaticamente os arquivos e registra o modelo e o ambiente. Como melhor prática para produção, você deve registrar o modelo e o ambiente e especificar o nome e a versão registrados separadamente no YAML. Use a forma model: azureml:my-model:1 ou environment: azureml:my-env:1.
Para fazer o registro, você pode extrair as definições do YAML de model e environment em arquivos YAML separados e usar os comandos az ml model create e az ml environment create. Para saber mais sobre esses comandos, execute az ml model create -h e az ml environment create -h.
Para obter mais informações sobre como registrar seu modelo como um ativo, consulte Registrar seu modelo como um ativo no Machine Learning usando o CLI. Para obter mais informações sobre como criar um ambiente, consulte Gerenciar ambientes do Azure Machine Learning com o CLI e SDK (v2).





Confirme sua implantação
Uma maneira de confirmar sua implantação existente é invocar seu ponto de extremidade para que ele possa pontuar seu modelo para uma determinada solicitação de entrada. Ao invocar seu ponto de extremidade por meio da CLI ou do SDK do Python, você pode optar por especificar o nome da implantação que receberá o tráfego de entrada.
Observação
Ao contrário da CLI ou do SDK do Python, o Estúdio do Azure Machine Learning exige que você especifique uma implantação ao invocar um ponto de extremidade.
Invocar o ponto de extremidade com nome da implantação
Se você invocar o ponto de extremidade com o nome da implantação que receberá o tráfego, o Azure Machine Learning roteará o tráfego do ponto de extremidade diretamente para a implantação especificada e retornará sua saída. Você pode usar a opção --deployment-namepara o CLI v2 ou a opção deployment_name para o SDK v2 para especificar a implantação.
Invocar o ponto de extremidade sem especificar a implantação
Se você invocar o ponto de extremidade sem especificar a implantação que receberá tráfego, o Azure Machine Learning roteará o tráfego de entrada do ponto de extremidade para a(s) implantação(ões) no ponto de extremidade com base nas configurações de controle de tráfego.
As configurações de controle de tráfego alocam porcentagens especificadas do tráfego de entrada em cada implantação no ponto de extremidade. Por exemplo, se suas regras de tráfego especificarem que uma implantação específica no seu ponto de extremidade receberá o tráfego de entrada 40% do tempo, o Azure Machine Learning roteará 40% do tráfego do ponto de extremidade para essa implantação.
É possível visualizar o status de seu ponto de extremidade existente e implantação executando:
az ml online-endpoint show --name $ENDPOINT_NAME
az ml online-deployment show --name blue --endpoint $ENDPOINT_NAME
Você verá o ponto de extremidade identificado por $ENDPOINT_NAME e uma implantação chamada blue.
Testar o ponto de extremidade usando dados de exemplo
O ponto de extremidade pode ser invocado usando o comando invoke. Enviaremos uma solicitação de exemplo usando um arquivo json.
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json


Escalar a implantação existente para lidar com mais tráfego
Na implantação descrita em Implantar e pontuar um modelo de machine learning com um ponto de extremidade online, você definirá a instance_count com o valor 1 no arquivo YAML de implantação. É possível escalar horizontalmente usando o comando update:
az ml online-deployment update --name blue --endpoint-name $ENDPOINT_NAME --set instance_count=2
Observação
Observe que, no comando acima, usamos para --set substituir a configuração de implantação. Como alternativa, você pode atualizar o arquivo yaml e passá-lo como uma entrada para o comando update usando a entrada --file.

Implantar um novo modelo, mas ainda não enviar o tráfego para ele
Criar uma nova implantação chamada green:
az ml online-deployment create --name green --endpoint-name $ENDPOINT_NAME -f endpoints/online/managed/sample/green-deployment.yml
Como não alocamos explicitamente nenhum tráfego para green, ele terá zero tráfego alocado a ele. Você pode verificar isso usando o comando :
az ml online-endpoint show -n $ENDPOINT_NAME --query traffic
Testar a nova implantação
Embora green tenha 0% do tráfego alocado, invoque-a diretamente especificando o nome --deployment:
az ml online-endpoint invoke --name $ENDPOINT_NAME --deployment-name green --request-file endpoints/online/model-2/sample-request.json
Caso deseje usar um cliente REST para invocar a implantação diretamente sem passar pelas regras de tráfego, defina o seguinte cabeçalho HTTP: azureml-model-deployment: <deployment-name>. O snippet de código abaixo usa curl para invocar a implantação diretamente. O snippet de código deve funcionar em ambientes Unix/WSL:
# get the scoring uri
SCORING_URI=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query scoring_uri)
# use curl to invoke the endpoint
curl --request POST "$SCORING_URI" --header "Authorization: Bearer $ENDPOINT_KEY" --header 'Content-Type: application/json' --header "azureml-model-deployment: green" --data @endpoints/online/model-2/sample-request.json


Teste a implantação com tráfego espelhado
Depois de testar sua implantação do green, você pode "espelhar" (ou copiar) uma porcentagem do tráfego ativo para ela. O espelhamento de tráfego (também chamado de sombreamento) não altera os resultados retornados aos clientes. As solicitações ainda fluem 100% para a implantação blue. A porcentagem espelhada do tráfego é copiada e enviada para a implantação green para que você possa coletar métricas e registrar em log sem afetar seus clientes. O espelhamento é útil ao desejar validar uma nova implantação sem afetar os clientes. Por exemplo, você pode usar o espelhamento para verificar se a latência está dentro dos limites aceitáveis e se não há erros de protocolo HTTP. Testar a nova implantação com espelhamento/sombreamento de tráfego também é conhecido como teste de sombra. A implantação que recebe o tráfego espelhado (nesse caso, a implantação green) também pode ser chamada de implantação de sombra.
O espelhamento tem as seguintes limitações:
- O tráfego espelhado tem suporte para a CLI (v2) (versão 2.4.0 ou superior) e o SDK do Python (v2) (versão 1.0.0 ou superior). Se você usar uma versão mais antiga da CLI/SDK para atualizar um ponto de extremidade, perderá a configuração de tráfego espelho.
- Atualmente, não há suporte para o espelhamento nos pontos de extremidade online do Kubernetes.
- Você pode espelhar o tráfego apenas para uma implantação em um ponto de extremidade.
- O percentual máximo de tráfego que você pode espelhar é de 50%. Esse limite é para reduzir o efeito na sua cota de largura de banda do ponto de extremidade (padrão de 5 MBPS). A largura de banda do ponto de extremidade será limitada se você exceder a cota alocada. Para obter informações sobre como monitorar a limitação da largura de banda, confira Monitorar pontos de extremidade online gerenciados.
Observe também os seguintes comportamentos:
- Uma implantação pode ser configurada para receber apenas tráfego dinâmico ou espelhado, não ambos.
- Quando você invoca um ponto de extremidade, é possível especificar o nome de qualquer uma de suas implantações, até mesmo uma implantação de sombra, para retornar a previsão.
- Quando você invoca um ponto de extremidade com o nome da implantação que receberá o tráfego de entrada, o Azure Machine Learning não espelhará o tráfego para a implantação sombra. O Azure Machine Learning espelha o tráfego para a implantação de sombra do tráfego enviado para o ponto de extremidade quando você não especifica uma implantação.
Agora, vamos definir a implantação verde para receber 10% do tráfego espelhado. Os clientes ainda receberão previsões somente da implantação azul.
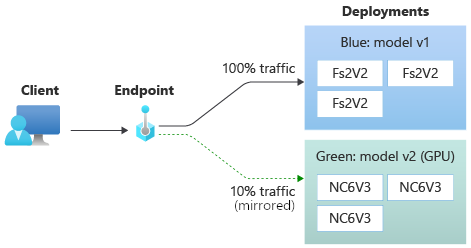
O comando a seguir espelha 10% do tráfego para a implantação green:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=10"
Você pode testar o tráfego espelhado invocando o ponto de extremidade várias vezes sem especificar uma implantação para receber o tráfego de entrada:
for i in {1..20} ; do
az ml online-endpoint invoke --name $ENDPOINT_NAME --request-file endpoints/online/model-1/sample-request.json
done
Você pode confirmar que o percentual específico do tráfego foi enviado para a implantação green vendo os logs da implantação:
az ml online-deployment get-logs --name blue --endpoint $ENDPOINT_NAME
Após o teste, você pode definir o tráfego espelho como zero para desabilitar o espelhamento:
az ml online-endpoint update --name $ENDPOINT_NAME --mirror-traffic "green=0"



Aloque um pequeno percentual de tráfego dinâmico para a nova implantação
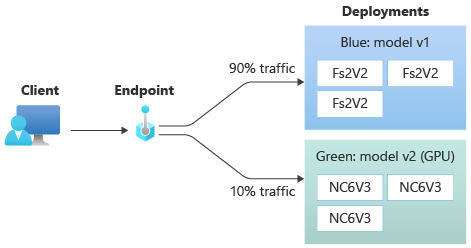
Depois de testar sua implantação green, aloque um pequeno percentual de tráfego para ela:
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=90 green=10"
Dica
O percentual total de tráfego precisa somar 0% (para desabilitar o tráfego) ou 100% (para habilitá-lo).
Agora, sua implantação green recebe 10% de todo o tráfego dinâmico. Os clientes receberão previsões das implantações blue e green.
Enviar todo o tráfego para a nova implantação
Quando estiver totalmente satisfeito com a implantação green, alterne todo o tráfego para ela.
az ml online-endpoint update --name $ENDPOINT_NAME --traffic "blue=0 green=100"
Remover a implantação antiga
Use as etapas a seguir para excluir uma implantação individual de um ponto de extremidade online gerenciado. Excluir uma implantação individual afeta as outras implantações no ponto de extremidade online gerenciado:
az ml online-deployment delete --name blue --endpoint $ENDPOINT_NAME --yes --no-wait
Excluir o ponto de extremidade e a implantação
Se você não estiver usando a implantação, exclua-a para reduzir custos. Excluindo o ponto de extremidade, você também excluirá todas as implantações subjacentes.
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
Conteúdo relacionado
- Explorar exemplos de ponto de extremidade online
- Implantar modelos com o REST
- Usar isolamento de rede com pontos de extremidade online gerenciados
- Acessar os recursos do Azure com um ponto de extremidade online e uma identidade gerenciada
- monitorar pontos de extremidade online gerenciados
- Gerenciar e aumentar cotas para recursos com o Azure Machine Learning
- Ver os custos de um ponto de extremidade online gerenciado do Azure Machine Learning
- Lista de SKUs de pontos de extremidade online gerenciados
- Solução de problemas de implantação e pontuação de pontos de extremidade online
- Referência YAML do ponto de extremidade online