Executar modelos do Azure Machine Learning no Fabric usando pontos de extremidade em lote (versão prévia)
APLICA-SE A: Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Neste artigo, você aprenderá a consumir implantações em lotes do Azure Machine Learning no Microsoft Fabric. Embora o fluxo de trabalho use modelos implantados nos pontos de extremidade em lotes, ele também dá suporte ao uso de implantações de pipeline em lote no Fabric.
Importante
Esse recurso está atualmente em visualização pública. Essa versão prévia é fornecida sem um contrato de nível de serviço e não é recomendada para cargas de trabalho de produção. Alguns recursos podem não ter suporte ou podem ter restrição de recursos.
Para obter mais informações, consulte Termos de Uso Complementares de Versões Prévias do Microsoft Azure.
Pré-requisitos
- Obtenha uma assinatura do Microsoft Fabric. Ou inscreva-se para uma avaliação gratuita do Microsoft Fabric.
- Entre no Microsoft Fabric.
- Uma assinatura do Azure. Caso não tenha uma assinatura do Azure, crie uma conta gratuita antes de começar. Experimente a versão gratuita ou paga do Azure Machine Learning.
- Um workspace do Azure Machine Learning. Se você não tiver, use as etapas em Como gerenciar espaços de trabalho para criar um.
- Certifique-se de ter as seguintes permissões no espaço de trabalho:
- Criar/gerenciar pontos de extremidade e implantações em lotes: use as funções Proprietário, Colaborador ou função personalizada que permita
Microsoft.MachineLearningServices/workspaces/batchEndpoints/*. - Criar implantações do ARM no grupo de recursos do espaço de trabalho: use as funções Proprietário, Colaborador ou função personalizada que permita
Microsoft.Resources/deployments/writeno grupo de recursos em que o espaço de trabalho está implantado.
- Criar/gerenciar pontos de extremidade e implantações em lotes: use as funções Proprietário, Colaborador ou função personalizada que permita
- Certifique-se de ter as seguintes permissões no espaço de trabalho:
- Um modelo implantado em um ponto de extremidade em lote. Se você não tiver um, use as etapas em Implantar modelos para pontuação em pontos de extremidade em lote para criar um.
- Baixe o conjunto de dados de exemplo heart-unlabeled.csv a ser usado para pontuação.
Arquitetura
O Azure Machine Learning não pode acessar diretamente os dados armazenados no OneLake do Fabric. No entanto, você pode usar a funcionalidade do OneLake para criar atalhos em um Lakehouse para ler e gravar dados armazenados no Azure Data Lake Gen2. Como o Azure Machine Learning dá suporte ao armazenamento do Azure Data Lake Gen2, essa configuração permite que você use o Fabric e o Azure Machine Learning juntos. A arquitetura de dados é a seguinte:

Configurar o acesso a dados
Para permitir que o Fabric e o Azure Machine Learning leiam e escrevam os mesmos dados, sem precisar copiá-los, você pode aproveitar os atalhos do OneLake e armazenamentos de dados do Azure Machine Learning. Ao apontar um atalho do OneLake e um armazenamento de dados para a mesma conta de armazenamento, você pode garantir que o Fabric e o Azure Machine Learning leiam e escrevam nos mesmos dados subjacentes.
Nesta seção, você criará ou identificará uma conta de armazenamento a ser usada para armazenar as informações que o ponto de extremidade em lote consumirá e que os usuários do Fabric verão no OneLake. O Fabric só dá suporte a contas de armazenamento com nomes hierárquicos habilitados, como o Azure Data Lake Gen2.
Criar um atalho do OneLake para a conta de armazenamento
Abra a experiência de Engenharia de Dados do Synapse no Fabric.
No painel esquerdo, selecione o workspace do Fabric para abri-lo.
Abra o lakehouse que você usará para configurar a conexão. Se você ainda não tiver um lakehouse, vá para a experiência de Engenharia de Dados para criar um lakehouse. Neste exemplo, você usa um lakehouse chamado trusted.
Na barra de navegação do lado esquerdo, abra mais opções para Arquivos e selecione Novo atalho para abrir o assistente.
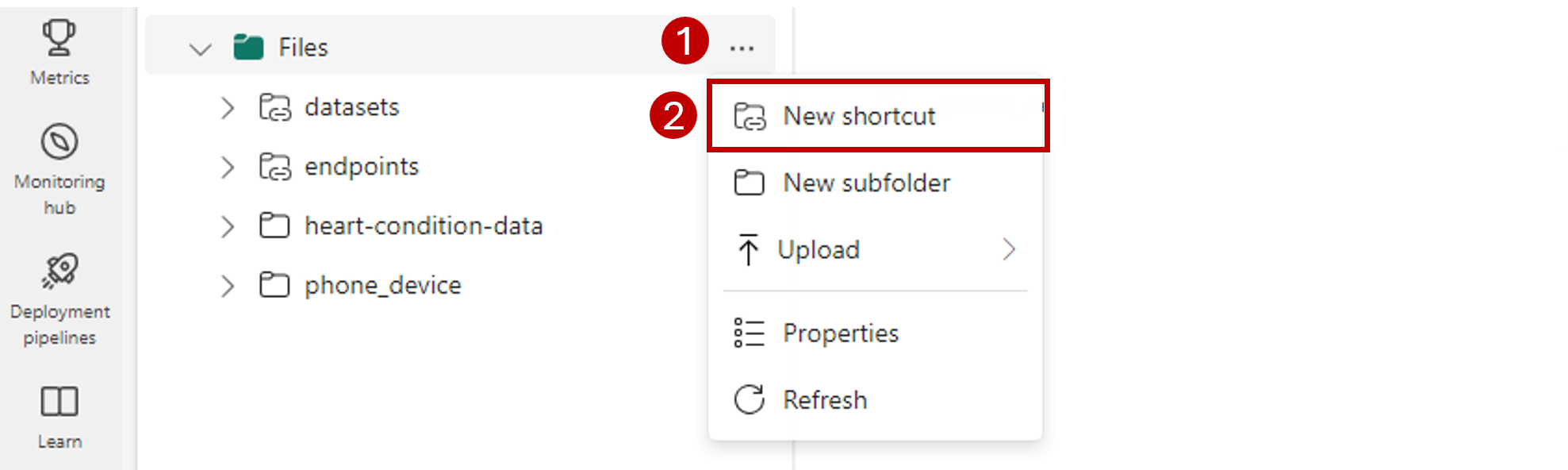
Selecione a opção Azure Data Lake Storage Gen2.

Na seção Configurações de conexão, cole a URL associada à conta de armazenamento do Azure Data Lake Gen2.

Na seção Credenciais de conexão:
- Em Conexão, selecione Criar nova conexão.
- Em Nome da conexão, mantenha o valor padrão preenchido.
- Em Tipo de autenticação, selecione Conta organizacional para usar as credenciais do usuário conectado por meio do OAuth 2.0.
- Selecione Entrar para entrar.
Selecione Avançar.
Configure o caminho para o atalho em relação à conta de armazenamento, se necessário. Use essa configuração para configurar a pasta para a qual o atalho apontará.
Configure o Nome do atalho. Esse nome será um caminho dentro do lakehouse. Neste exemplo, nomeie os conjuntos de dados do atalho.
Salve as alterações.



Criar um armazenamento de dados que aponte para a conta de armazenamento
Acesse o Workspace do Azure Machine Learning.
Vá para a seção Dados.
Selecione a guia Armazenamentos de dados.
Selecione Criar.
Configure o armazenamento de dados da seguinte maneira:
Em Nome do armazenamento de dados, insira trusted_blob.
Em Tipo de armazenamento de dados: selecione Armazenamento de Blobs do Azure.
Dica
Por que você deve configurar o Armazenamento de Blobs do Azure, em vez do Azure Data Lake Gen2? Os pontos de extremidade em lote só podem gravar previsões nas contas do Armazenamento de Blobs. No entanto, cada conta de armazenamento do Azure Data Lake Gen2 também é uma conta de armazenamento de blobs. Portanto, elas podem ser usadas de forma intercambiável.
Selecione a conta de armazenamento no assistente, usando a ID de Assinatura, a conta de Armazenamento e Contêiner de blobs (sistema de arquivos).
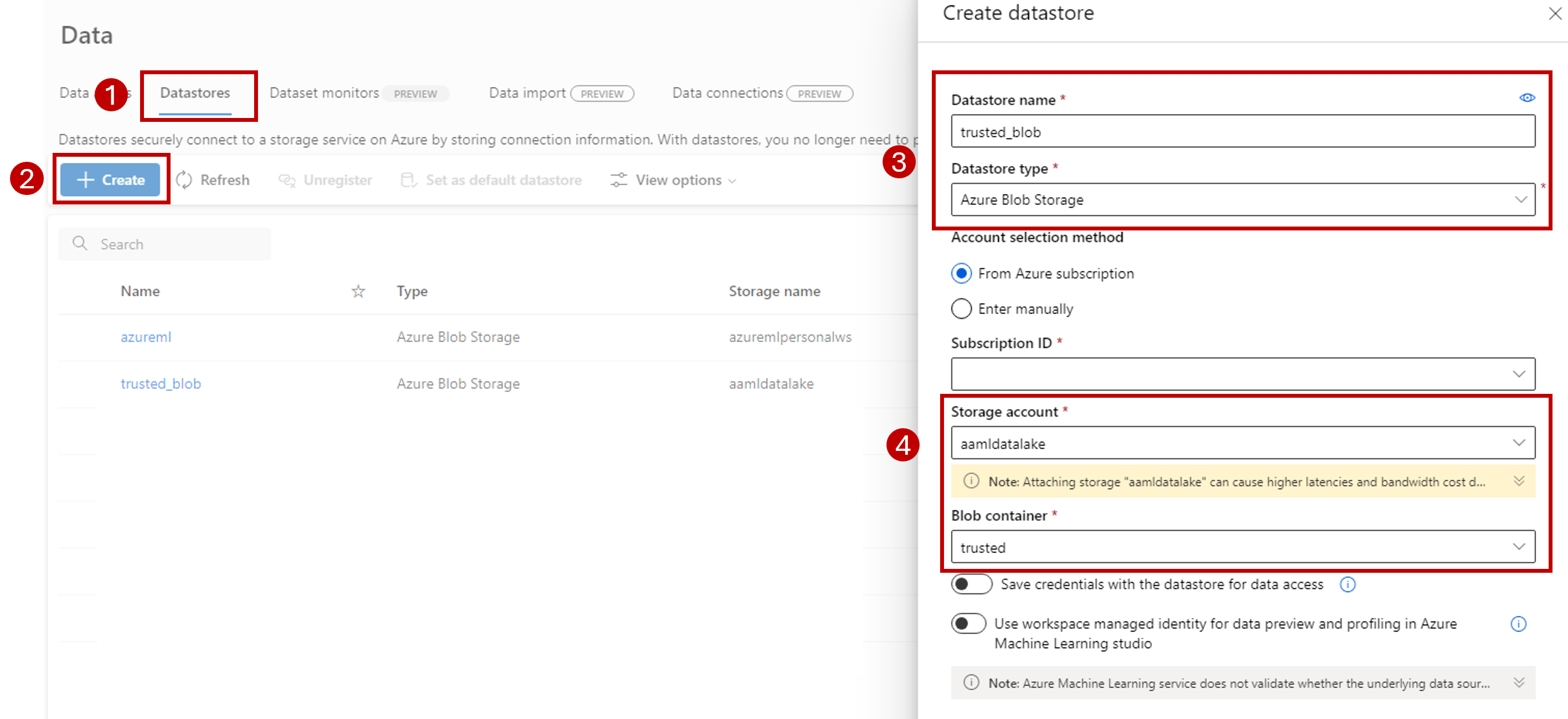
Selecione Criar.
Verifique se a computação em que o ponto de extremidade em lote está em execução tem permissões para montar os dados nessa conta de armazenamento. como entrada. Embora o acesso ainda seja concedido pela identidade que invoca o ponto de extremidade, a computação em que o ponto de extremidade em lote é executado precisa ter permissão para montar a conta de armazenamento que você fornece. Para obter mais informações, confira Como acessar os serviços de armazenamento.
Carregar conjunto de dados de exemplo
Carregue alguns dados de exemplo para o ponto de extremidade a ser usado como entrada:
Acesse o workspace do Fabric.
Selecione o lakehouse em que você criou o atalho.
Vá para o atalho dos conjuntos de dados.
Crie uma pasta para armazenar o conjunto de dados de exemplo que você deseja pontuar. Nomeie a pasta uci-heart-unlabeled.
Use a opção Obter dados e selecione Carregar arquivos para carregar o conjunto de dados de exemplo heart-unlabeled.csv.
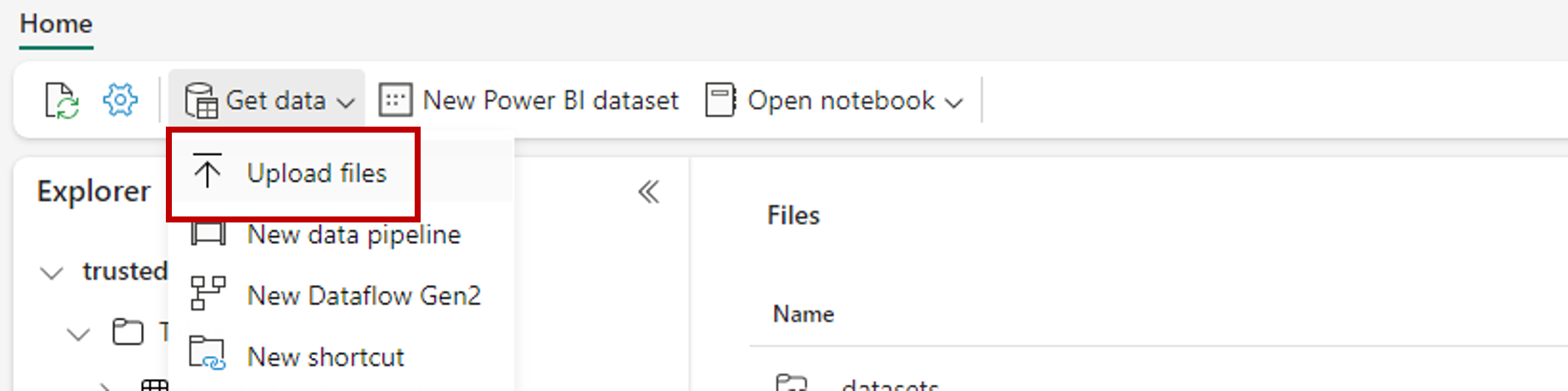
Carregar o conjunto de dados de exemplo.

O arquivo de exemplo está pronto para ser consumido. Observe o caminho para o local em que você o salvou.


Criar um pipeline de inferência do Fabric para o lote
Nesta seção, você criará um pipeline de inferência do Fabric para o lote no seu workspace do Fabric existente e invocará os pontos de extremidade em lote.
Retorne à experiência de Engenharia de Dados (se você já tiver saído dela), usando o ícone de seletor da experiência no canto inferior esquerdo da home page.
Abra o workspace do Fabric.
Na seção Nova da home page, selecione Pipeline de dados.
Nomeie o pipeline e selecione Criar.

Selecione a guia Atividades na barra de ferramentas na tela do designer.
Selecione mais opções no final da guia e selecione Azure Machine Learning.
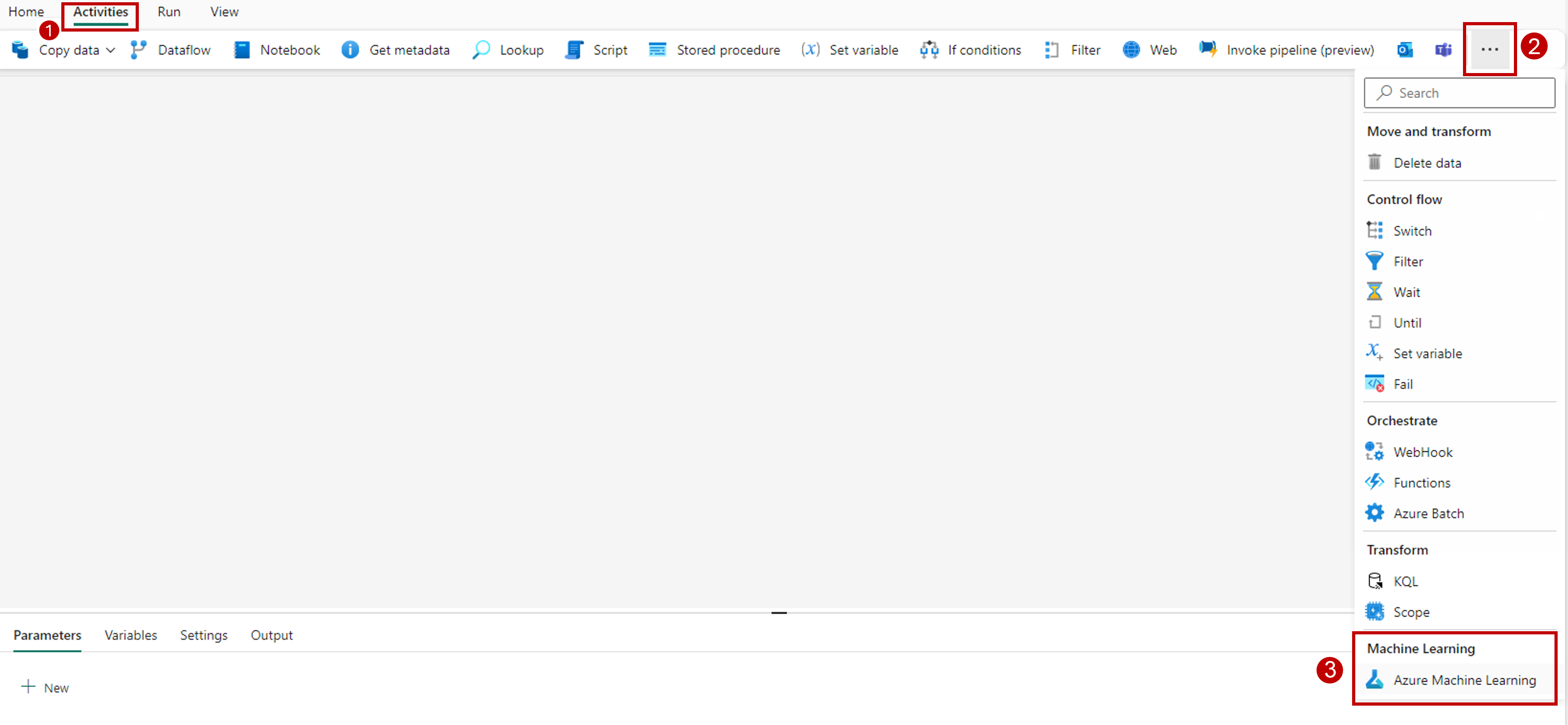
Vá para a guia Configurações e configure a atividade da seguinte maneira:
Selecione Novo ao lado da conexão do Azure Machine Learning para criar uma nova conexão com o workspace do Azure Machine Learning que contém a implantação.
Na seção Configurações de conexão do assistente de criação, especifique os valores da ID de assinatura, Nome do grupo de recursos e Nome do workspace em que o ponto de extremidade foi implantado.

Na seção Credenciais de conexão, selecione Conta organizacional como o valor do Tipo de autenticação para a conexão. A conta organizacional usa as credenciais do usuário conectado. Como alternativa, você pode usar a Entidade de serviço. Nas configurações de produção, recomendamos que você use uma Entidade de serviço. Independentemente do tipo de autenticação, verifique se a identidade associada à conexão tem os direitos para chamar o ponto de extremidade em lote que você implantou.

Salve a conexão. Depois que a conexão é selecionada, o Fabric preenche automaticamente os pontos de extremidade em lote disponíveis no workspace selecionado.
Em Ponto de extremidade em lote, selecione o ponto de extremidade em lote que você quer chamar. Neste exemplo, selecione heart-classifier-....
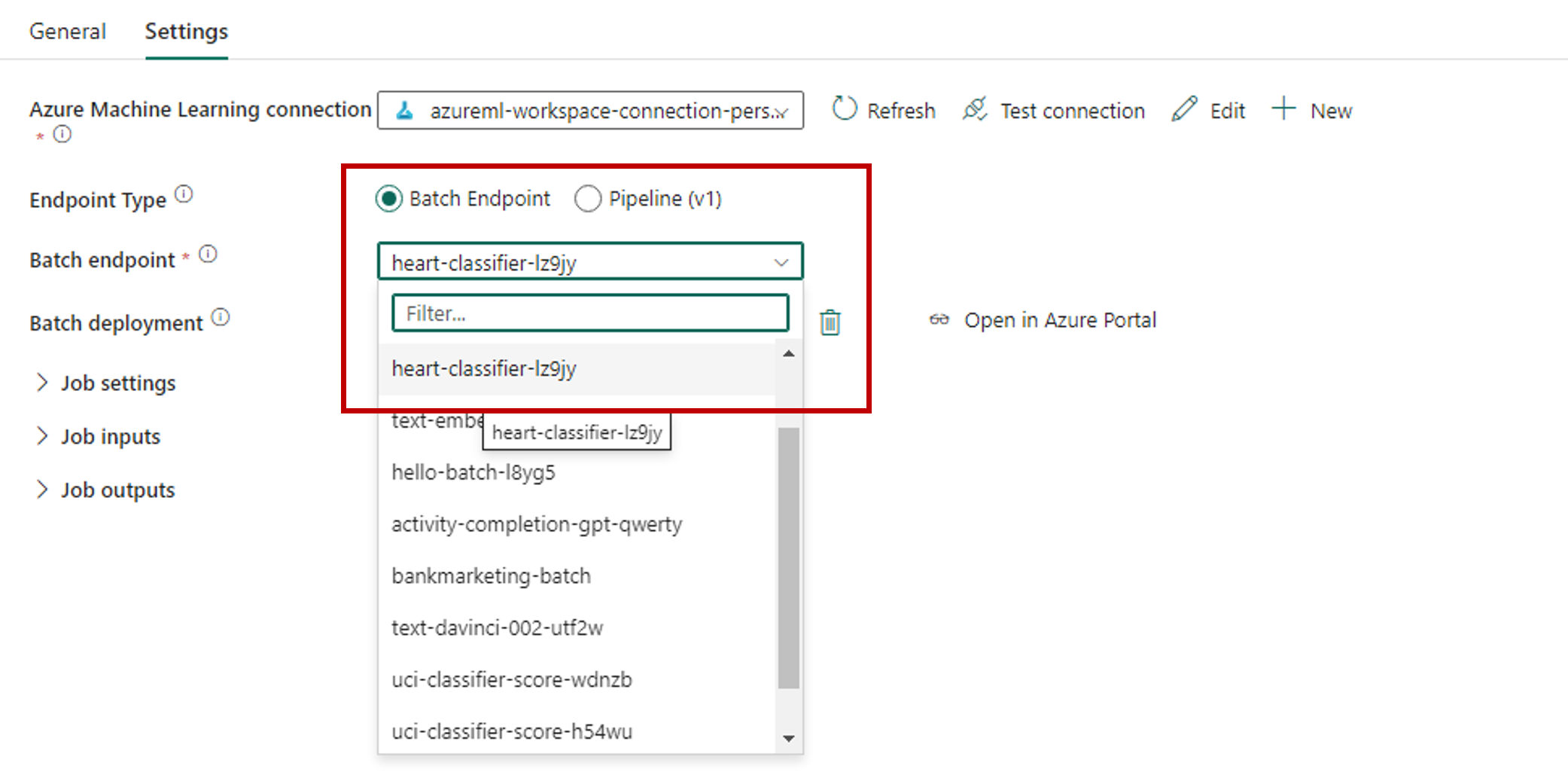
A seção Implantação de lote é preenchida automaticamente com as implantações disponíveis no ponto de extremidade.
Em Implantação de lote, selecione uma implantação específica na lista, se necessário. Se você não selecionar uma implantação, o Fabric invocará a implantação Padrão no ponto de extremidade, permitindo que o criador do ponto de extremidade em lote decida qual implantação será chamada. Na maioria dos cenários, você deseja manter esse comportamento padrão.








Configurar entradas e saídas para o ponto de extremidade em lote
Nesta seção, você configurará entradas e saídas no ponto de extremidade em lote. As entradas para os pontos de extremidade em lote fornecem os dados e parâmetros necessários para executar o processo. O pipeline em lote do Azure Machine Learning no Fabric dá suporte a implantações de modelo e implantações de pipeline. O número e o tipo de entradas que você fornece dependem do tipo de implantação. Neste exemplo, você usa uma implantação de modelo que exige exatamente uma entrada e produz uma saída.
Para obter mais informações sobre as entradas e saídas do ponto de extremidade em lote, confira Noções básicas sobre as entradas e saídas nos pontos de extremidade em lote.
Configurar a seção de entrada
Configure a seção Entradas de trabalho da seguinte maneira:
Expanda a seção Entradas de trabalho.
Selecione Novo para adicionar uma nova entrada ao ponto de extremidade.
Nomeie a entrada
input_data. Como você está usando uma implantação de modelo, pode usar qualquer nome. Para implantações de pipeline, no entanto, você precisa indicar o nome exato da entrada que o modelo está esperando.Selecione o menu suspenso ao lado da entrada que você acabou de adicionar para abrir a propriedade da entrada (campos Nome e Valor).
Insira
JobInputTypeno campo Nome para indicar o tipo de entrada que você está criando.Insira
UriFolderno campo Valor para indicar que a entrada é um caminho de pasta. Outros valores com suporte para esse campo são UriFile (um caminho de arquivo) ou Literal (qualquer valor literal como cadeia de caracteres ou inteiro). Você precisa usar o tipo certo que a implantação espera.Selecione o sinal de adição ao lado da propriedade para adicionar outra propriedade para essa entrada.
Insira
Urino campo Nome para indicar o caminho para os dados.Insira
azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled, o caminho para localizar os dados, no campo Valor. Aqui, você usa um caminho que leva à conta de armazenamento vinculada ao OneLake no Fabric e ao Azure Machine Learning. azureml://datastores/trusted_blob/datasets/uci-heart-unlabeled é o caminho para arquivos CSV com os dados de entrada esperados para o modelo implantado no ponto de extremidade em lote. Você também pode usar um caminho direto para a conta de armazenamento, comohttps://<storage-account>.dfs.azure.com.
Dica
Se a entrada for do tipo Literal, substitua a propriedade
Uripor 'Value'.
Se o ponto de extremidade exigir mais entradas, repita as etapas anteriores para cada uma delas. Neste exemplo, as implantações de modelo exigem exatamente uma entrada.
Configure a seção de saída
Configure a seção Saídas de trabalho da seguinte maneira:
Expanda a seção Saídas de trabalho.
Selecione Novo para adicionar uma nova saída ao ponto de extremidade.
Dê ao botão o nome
output_data. Como você está usando uma implantação de modelo, pode usar qualquer nome. Para implantações de pipeline, no entanto, você precisa indicar o nome exato da saída que o modelo está gerando.Selecione o menu suspenso ao lado da saída que você acabou de adicionar para abrir a propriedade da saída (campos Nome e Valor).
Insira
JobOutputTypeno campo Nome para indicar o tipo de saída que você está criando.Insira
UriFileno campo Valor para indicar que a saída é um caminho de arquivo. O outro valor com suporte para esse campo é UriFolder (um caminho de pasta). Ao contrário da seção Entrada de trabalho, o Literal (qualquer valor literal como cadeia de caracteres ou inteiro) não tem suporte como saída.Selecione o sinal de adição ao lado da propriedade para adicionar outra propriedade para essa saída.
Insira
Urino campo Nome para indicar o caminho para os dados.Insira
@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv'), o caminho para onde a saída deve ser colocada, no campo Valor. Os pontos de extremidade em lote do Azure Machine Learning só dão suporte ao uso de caminhos de armazenamento de dados como saídas. Como as saídas precisam ser exclusivas para evitar conflitos, você usou uma expressão dinâmica,@concat(@concat('azureml://datastores/trusted_blob/paths/endpoints', pipeline().RunId, 'predictions.csv'), para construir o caminho.
Se o ponto de extremidade retornar mais saídas, repita as etapas anteriores para cada uma delas. Neste exemplo, as implantações de modelo produzem exatamente uma saída.
(Opcional) Configure as configurações de trabalho
Você também pode definir as Configurações de trabalho adicionando as seguintes propriedades:
Para implantações de modelos:
| Configuração | Descrição |
|---|---|
MiniBatchSize |
O tamanho do lote. |
ComputeInstanceCount |
O número de instâncias de computação a serem solicitadas na implantação. |
Para implantações de pipeline:
| Configuração | Descrição |
|---|---|
ContinueOnStepFailure |
Indica se o pipeline deve parar de processar os nós após uma falha. |
DefaultDatastore |
Indica o armazenamento de dados padrão a ser usado para saídas. |
ForceRun |
Indica se o pipeline deve forçar a execução de todos os componentes mesmo que a saída possa ser inferida em uma execução anterior. |
Depois de configurado, você pode testar o pipeline.