Use trabalhos paralelos em pipelines
APLICA-SE A: Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Extensão de ML da CLI do Azure v2 (atual)SDK do Python azure-ai-ml v2 (atual)
Esse artigo explica como usar a CLI v2 e o Python SDK v2 para executar trabalhos paralelos em pipelines do Azure Machine Learning. Trabalhos paralelos aceleram a execução de trabalhos distribuindo tarefas repetidas em poderosos clusters de computação multinós.
Engenheiros de aprendizado de máquina sempre têm requisitos de escala em suas tarefas de treinamento ou inferência. Por exemplo, quando um cientista de dados fornece um único script para treinar um modelo de previsão de vendas, os engenheiros de aprendizado de máquina precisam aplicar essa tarefa de treinamento a cada armazenamento de dados individual. Os desafios desse processo de expansão incluem longos tempos de execução que causam atrasos e problemas inesperados que exigem intervenção manual para manter a tarefa em execução.
A principal tarefa da paralelização do Azure Machine Learning é dividir uma única tarefa serial em minilotes e distribuí-los para vários computadores para execução em paralelo. Trabalhos paralelos reduzem significativamente o tempo de execução de ponta a ponta e também lidam com erros automaticamente. Considere usar o trabalho paralelo do Azure Machine Learning para treinar muitos modelos sobre seus dados particionados ou para acelerar suas tarefas de inferência em lote em larga escala.
Por exemplo, em um cenário em que você está executando um modelo de detecção de objetos em um grande conjunto de imagens, os trabalhos paralelos do Azure Machine Learning permitem que você distribua facilmente suas imagens para executar código personalizado em paralelo em um cluster de computação específico. A paralelização pode reduzir significativamente o custo de tempo. Os trabalhos paralelos do Azure Machine Learning também podem simplificar e automatizar seu processo para torná-lo mais eficiente.
Pré-requisitos
- Tenha uma conta e um espaço de trabalho do Azure Machine Learning.
- Entenda os pipelines do Azure Machine Learning.
- Instale a CLI do Azure e a extensão
ml. Para obter mais informações, confira Instalar, configurar e usar a CLI (v2). A extensãomlserá instalada automaticamente na primeira vez que você executar um comandoaz ml. - Entenda como criar e executar pipelines e componentes do Azure Machine Learning com a CLI v2.
Crie e execute um pipeline com uma etapa de trabalho paralela
Um trabalho paralelo do Azure Machine Learning pode ser usado apenas como uma etapa em um trabalho de pipeline.
Os exemplos a seguir vêm de Executar um trabalho de pipeline usando um trabalho paralelo no pipeline no repositório Exemplos do Azure Machine Learning.
Preparar para paralelização
Essa etapa paralela do trabalho requer preparação. Você precisa de um script de entrada que implemente as funções predefinidas. Você também precisa definir atributos na sua definição de tarefa paralela que:
- Defina e vincule seus dados de entrada.
- Defina o método de divisão de dados.
- Configure seus recursos de computação.
- Chame o script de entrada.
As seções a seguir descrevem como preparar o trabalho paralelo.
Declare as entradas e a configuração da divisão de dados
Um trabalho paralelo requer que uma entrada principal seja dividida e processada em paralelo. O principal formato de dados de entrada pode ser dados tabulares ou uma lista de arquivos.
Diferentes formatos de dados têm diferentes tipos de entrada, modos de entrada e métodos de divisão de dados. A tabela a seguir descreve as opções:
| Formato dos dados | Tipo de entrada | Modo de entrada | Método de divisão de dados |
|---|---|---|---|
| Lista de arquivos | mltable ou uri_folder |
ro_mount ou download |
Por tamanho (número de arquivos) ou por partição |
| Dados tabulares | mltable |
direct |
Por tamanho (tamanho físico estimado) ou por partição |
Observação
Se você usar tabular mltable como seus principais dados de entrada, você precisa:
- Instale a biblioteca
mltableem seu ambiente, como na linha 9 deste arquivo conda. - Tenha um arquivo de especificação MLTable no caminho especificado com a seção
transformations: - read_delimited:preenchida. Para obter exemplos, veja Criar e gerenciar ativos de dados.
Você pode declarar seus principais dados de entrada com o atributo input_data no YAML ou Python do trabalho paralelo e vincular os dados com o input definido do seu trabalho paralelo usando ${{inputs.<input name>}}. Em seguida, você define o atributo de divisão de dados para sua entrada principal, dependendo do seu método de divisão de dados.
| Método de divisão de dados | Nome do atributo | Tipo de atributo | Exemplo de trabalho |
|---|---|---|---|
| Por tamanho | mini_batch_size |
string | Previsão em lote de Iris |
| Por partição | partition_keys |
lista de cadeias de caracteres | Previsão de vendas de suco de laranja |
Configurar os recursos de computação para paralelização
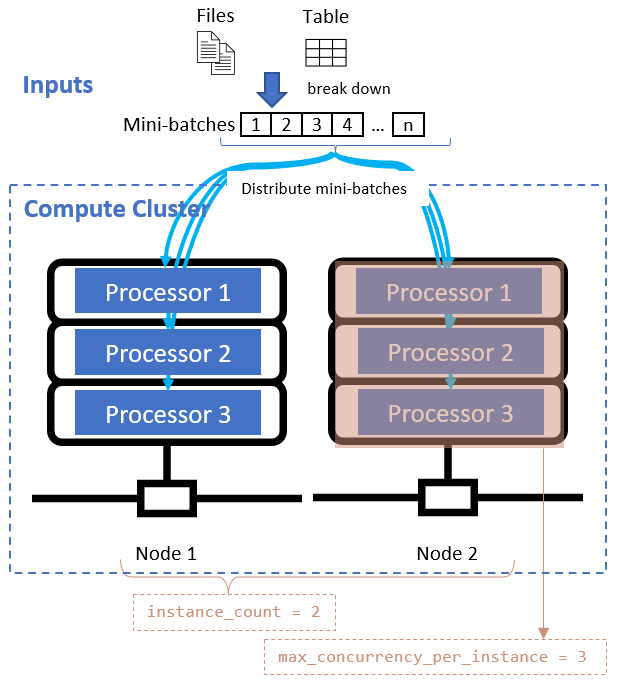
Depois de definir o atributo de divisão de dados, configure os recursos de computação para sua paralelização definindo os atributos instance_count e max_concurrency_per_instance.
| Nome do atributo | Type | Descrição | Valor padrão |
|---|---|---|---|
instance_count |
inteiro | O número de nós que serão usados para o trabalho. | 1 |
max_concurrency_per_instance |
inteiro | O número de processadores em cada nó. | Para um cálculo de GPU: 1. Para uma computação de CPU: número de núcleos. |
Esses atributos funcionam em conjunto com o cluster de computação especificado, conforme mostrado no diagrama a seguir:
Chamar o script de entrada
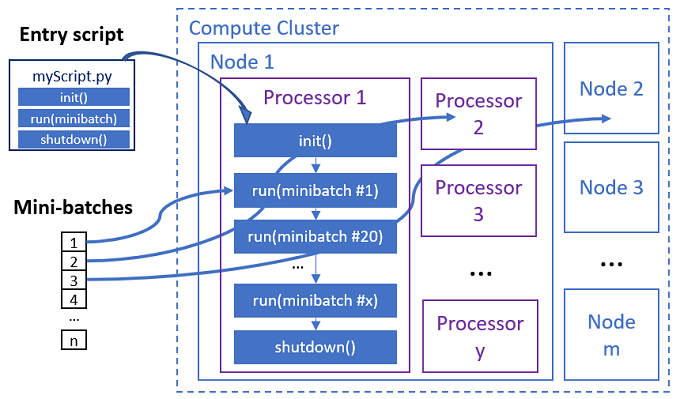
O script de entrada é um único arquivo Python que implementa as três funções predefinidas a seguir com código personalizado.
| Nome da função | Obrigatório | Description | Entrada | Retorno |
|---|---|---|---|---|
Init() |
Y | Preparação comum antes de começar a executar minilotes. Por exemplo, use essa função para carregar o modelo em um objeto global. | -- | -- |
Run(mini_batch) |
Y | Implementa a lógica de execução principal para minilotes. | mini_batch é um dataframe pandas se os dados de entrada forem dados tabulares, ou uma lista de caminhos de arquivo se os dados de entrada forem um diretório. |
Dataframe, lista ou tupla. |
Shutdown() |
N | Função opcional para fazer limpezas personalizadas antes de retornar o cálculo ao pool. | -- | -- |
Importante
Para evitar exceções ao analisar argumentos em funções Init() ou Run(mini_batch), use parse_known_args em vez deparse_args. Veja o exemplo iris_score para um script de entrada com analisador de argumentos.
Importante
A função Run(mini_batch) requer o retorno de um item de dataframe, lista ou tupla. O trabalho paralelo usa a contagem desse retorno para medir os itens de sucesso naquele minilote. A contagem do minilote deve ser igual à contagem da lista de devolução se todos os itens tiverem sido processados.
O trabalho paralelo executa as funções em cada processador, conforme mostrado no diagrama a seguir.
Veja os seguintes exemplos de script de entrada:
- Identificação de imagem para uma lista de arquivos de imagem
- Classificação do Iris para dados tabulares de íris
Para chamar o script de entrada, defina os dois atributos a seguir na definição do seu trabalho paralelo:
| Nome do atributo | Type | Descrição |
|---|---|---|
code |
string | Caminho local para o diretório do código-fonte para fazer upload e usar no trabalho. |
entry_script |
string | O arquivo Python que contém a implementação de funções paralelas predefinidas. |
Exemplo de etapa de trabalho paralela
A etapa de trabalho paralela a seguir declara o tipo de entrada, o modo e o método de divisão de dados, vincula a entrada, configura o cálculo e chama o script de entrada.
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
Considere as configurações de automação
O trabalho paralelo do Azure Machine Learning expõe muitas configurações opcionais que podem controlar automaticamente o trabalho sem intervenção manual. A tabela a seguir descreve cada uma das configurações.
| Chave | Type | Descrição | Valores permitidos | Valor padrão | Definido em atributo ou argumento de programa |
|---|---|---|---|---|---|
mini_batch_error_threshold |
Número inteiro | Número de minilotes com falha a serem ignorados neste trabalho paralelo. Se a contagem de minilotes com falha for maior que esse limite, o trabalho paralelo será marcado como com falha. O minilote é marcado como reprovado se: – A contagem de retorno de run() é menor que a contagem de entrada do minilote.- Exceções são capturadas no código run() personalizado. |
[-1, int.max] |
-1, significa ignorar todos os mini-lotes com falha |
Atributo mini_batch_error_threshold |
mini_batch_max_retries |
Número inteiro | Número de tentativas quando o minilote falha ou atinge o tempo limite. Se todas as tentativas falharem, o minilote será marcado como reprovado pelo cálculo mini_batch_error_threshold. |
[0, int.max] |
2 |
Atributo retry_settings.max_retries |
mini_batch_timeout |
Número inteiro | Tempo limite em segundos para execução da função personalizada run(). Se o tempo de execução for maior que esse limite, o minilote será abortado e marcado como falha ao acionar a nova tentativa. |
(0, 259200] |
60 |
Atributo retry_settings.timeout |
item_error_threshold |
Número inteiro | O limite de itens com falha. Os itens com falha são contados pela diferença numérica entre entradas e retornos de cada minilote. Se a soma de itens com falha for maior que esse limite, o trabalho paralelo será marcado como com falha. | [-1, int.max] |
-1, significa ignorar todas as falhas durante o trabalho paralelo |
Argumento do programa--error_threshold |
allowed_failed_percent |
Número inteiro | Semelhante a mini_batch_error_threshold, mas usa a porcentagem de minilotes com falha em vez da contagem. |
[0, 100] |
100 |
Argumento do programa--allowed_failed_percent |
overhead_timeout |
Número inteiro | Tempo limite em segundos para inicialização de cada minilote. Por exemplo, carregue dados de minilote e passe-os para a função run(). |
(0, 259200] |
600 |
Argumento do programa--task_overhead_timeout |
progress_update_timeout |
Número inteiro | Tempo limite em segundos para monitorar o progresso da execução do minilote. Se nenhuma atualização de progresso for recebida dentro dessa configuração de tempo limite, o trabalho paralelo será marcado como falha. | (0, 259200] |
Calculado dinamicamente por outras configurações | Argumento do programa--progress_update_timeout |
first_task_creation_timeout |
Número inteiro | Tempo limite em segundos para monitorar o tempo entre o início do trabalho e a execução do primeiro minilote. | (0, 259200] |
600 |
Argumento do programa--first_task_creation_timeout |
logging_level |
string | O nível de logs a serem despejados nos arquivos de log do usuário. | INFO, WARNING ou DEBUG |
INFO |
Atributo logging_level |
append_row_to |
string | Agregue todos os retornos de cada execução do minilote e gere-os nesse arquivo. Pode se referir a uma das saídas do trabalho paralelo usando a expressão ${{outputs.<output_name>}} |
Atributo task.append_row_to |
||
copy_logs_to_parent |
string | Opção booleana para copiar o progresso do trabalho, a visão geral e os logs para o trabalho do pipeline pai. | True ou False |
False |
Argumento do programa--copy_logs_to_parent |
resource_monitor_interval |
Número inteiro | Intervalo de tempo em segundos para despejar o uso de recursos do nó (por exemplo, CPU ou memória) na pasta de log no caminho logs/sys/perf. Observação: Logs de recursos de despejo frequentes reduzem um pouco a velocidade de execução. Defina esse valor como 0 para parar de despejar o uso de recursos. |
[0, int.max] |
600 |
Argumento do programa--resource_monitor_interval |
O código de exemplo a seguir atualiza essas configurações:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Crie o pipeline com etapa de trabalho paralela
O exemplo a seguir mostra o trabalho completo do pipeline com a etapa de trabalho paralela em linha:
$schema: https://azuremlschemas.azureedge.net/latest/pipelineJob.schema.json
type: pipeline
display_name: iris-batch-prediction-using-parallel
description: The hello world pipeline job with inline parallel job
tags:
tag: tagvalue
owner: sdkteam
settings:
default_compute: azureml:cpu-cluster
jobs:
batch_prediction:
type: parallel
compute: azureml:cpu-cluster
inputs:
input_data:
type: mltable
path: ./neural-iris-mltable
mode: direct
score_model:
type: uri_folder
path: ./iris-model
mode: download
outputs:
job_output_file:
type: uri_file
mode: rw_mount
input_data: ${{inputs.input_data}}
mini_batch_size: "10kb"
resources:
instance_count: 2
max_concurrency_per_instance: 2
logging_level: "DEBUG"
mini_batch_error_threshold: 5
retry_settings:
max_retries: 2
timeout: 60
task:
type: run_function
code: "./script"
entry_script: iris_prediction.py
environment:
name: "prs-env"
version: 1
image: mcr.microsoft.com/azureml/openmpi4.1.0-ubuntu20.04
conda_file: ./environment/environment_parallel.yml
program_arguments: >-
--model ${{inputs.score_model}}
--error_threshold 5
--allowed_failed_percent 30
--task_overhead_timeout 1200
--progress_update_timeout 600
--first_task_creation_timeout 600
--copy_logs_to_parent True
--resource_monitor_interva 20
append_row_to: ${{outputs.job_output_file}}
Enviar o trabalho de pipeline
Envie seu trabalho de pipeline com etapa paralela usando o comando az ml job create CLI:
az ml job create --file pipeline.yml
Verifique a etapa paralela na interface do usuário do estúdio
Depois de enviar um trabalho de pipeline, o widget SDK ou CLI fornece um link de URL da Web para o gráfico de pipeline na interface do usuário do Estúdio do Azure Machine Learning.
Para visualizar os resultados do trabalho paralelo, clique duas vezes na etapa paralela no gráfico do pipeline, selecione a guia Configurações no painel de detalhes, expanda Configurações de execução e, em seguida, expanda a seção Paralelo.

Para depurar falhas de tarefas paralelas, selecione a guia Saídas + logs, expanda a pasta logs e verifique job_result.txt para entender por que a tarefa paralela falhou. Para obter informações sobre a estrutura de registro de trabalhos paralelos, veja readme.txt na mesma pasta.
