Aumentar a Velocidade do Ponto de Verificação e Reduzir o Custo com o Nebula
Saiba como aumentar a velocidade do ponto de verificação e reduzir o custo do ponto de verificação para modelos grandes de treinamento do Azure Machine Learning.
Visão geral
O Nebula é uma ferramenta de ponto de verificação rápida, simples, sem disco e com reconhecimento de modelo no Contêiner do Azure para PyTorch (ACPT). O Nebula oferece uma solução de ponto de verificação simples e de alta velocidade para trabalhos de treinamento de modelos distribuídos em grande escala com o PyTorch. Ao utilizar as tecnologias de computação distribuídas mais recentes, o Nebula pode reduzir os tempos de ponto de verificação de horas para segundos, potencialmente economizando de 95% a 99,9% de tempo. Trabalhos de treinamento em larga escala podem se beneficiar muito do desempenho do Nebula.
Para disponibilizar o Nebula para seus trabalhos de treinamento, importe o pacote Python nebulaml em seu script. O Nebula tem compatibilidade total com diferentes estratégias de treinamento do PyTorch distribuídas, incluindo o PyTorch Lightning, DeepSpeed e muito mais. A API do Nebula oferece uma maneira simples de monitorar e exibir os ciclos de vida do ponto de verificação. As APIs dão suporte a vários tipos de modelo e garantem a consistência e a confiabilidade do ponto de verificação.
Importante
O pacote nebulaml não está disponível no índice do pacote Python PyPI público. Esse pacote só está disponível no ambiente coletado do Contêiner Azure para PyTorch (ACPT) no Azure Machine Learning. Para evitar problemas, não tente instalar nebulaml a partir do PyPI ou usando o comando pip.
Nesse documento, você aprenderá a usar o Nebula com o ACPT no Azure Machine Learning para verificar rapidamente seus trabalhos de treinamento de modelo. Além disso, você aprenderá a exibir e gerenciar dados de ponto de verificação do Nebula. Você também aprenderá a retomar os trabalhos de treinamento de modelo do último ponto de verificação disponível se o Azure Machine Learning sofrer interrupção, falha ou encerramento.
Por que a otimização do ponto de verificação para treinamento de modelo grande é importante
À medida que os volumes de dados aumentam e os formatos de dados se tornam mais complexos, os modelos de machine learning também se tornaram mais sofisticados. Treinar esses modelos complexos pode se tornar um desafio devido aos limites de capacidade de memória da GPU e aos longos tempos de treinamento. Como resultado, o treinamento distribuído geralmente é usado ao trabalhar com grandes conjuntos de dados e modelos complexos. No entanto, as arquiteturas distribuídas podem enfrentar falhas inesperadas e de nó, o que pode se tornar cada vez mais problemático à medida que o número de nós em um modelo de machine learning aumenta.
Os pontos de verificação podem ajudar a atenuar esses problemas salvando periodicamente uma instantâneo do estado completo do modelo em um determinado momento. Em caso de falha, esse instantâneo pode ser usado para recompilar o modelo para seu estado no momento do instantâneo para que o treinamento possa ser retomado a partir desse ponto.
Quando operações de treinamento de modelo grande apresentam falhas e encerramentos, cientistas de dados e pesquisadores podem restaurar o processo de treinamento de um ponto de verificação salvo anteriormente. No entanto, qualquer progresso feito entre o ponto de verificação e o encerramento é perdido, pois os cálculos devem ser executados novamente para recuperar resultados intermediários não salvos. Intervalos de ponto de verificação mais curtos podem ajudar a reduzir essa perda. O diagrama ilustra o tempo perdido entre o processo de treinamento dos pontos de verificação e o encerramento:

No entanto, o processo de salvar pontos de verificação em si pode gerar uma sobrecarga significativa. Salvar um ponto de verificação do tamanho de TB geralmente pode se tornar um gargalo no processo de treinamento, com o processo de ponto de verificação sincronizado bloqueando o treinamento por horas. Em média, as sobrecargas relacionadas ao ponto de verificação podem ser responsáveis por 12% do tempo total de treinamento e podem chegar a até 43% (Maeng et al., 2021).
Para resumir, o gerenciamento do ponto de verificação de modelo grande envolve armazenamento pesado e sobrecargas de tempo de recuperação de trabalho. Os salvamentos frequentes de ponto de verificação, combinados com retomadas de trabalho de treinamento dos pontos de verificação mais recentes disponíveis, tornam-se um grande desafio.
Nebula para o Rescue
Ao treinar grandes modelos distribuídos, é importante retomar o processo de treinamento de maneira confiável e eficiente para evitar perda de dados e desperdício de recursos. O Nebula ajuda a reduzir os tempos de salvamento de ponto de verificação e as demandas por hora de GPU para trabalhos grandes de treinamento do Azure Machine Learning, fornecendo gerenciamento de ponto de verificação mais rápido e fácil.
Com o Nebula, você pode:
Aumentar as velocidades de ponto de verificação até 1000 vezes com uma API simples que funciona de forma assíncrona com seu processo de treinamento. O Nebula pode reduzir o tempo de ponto de verificação de horas para segundos - uma possível redução de 95% para 99%.
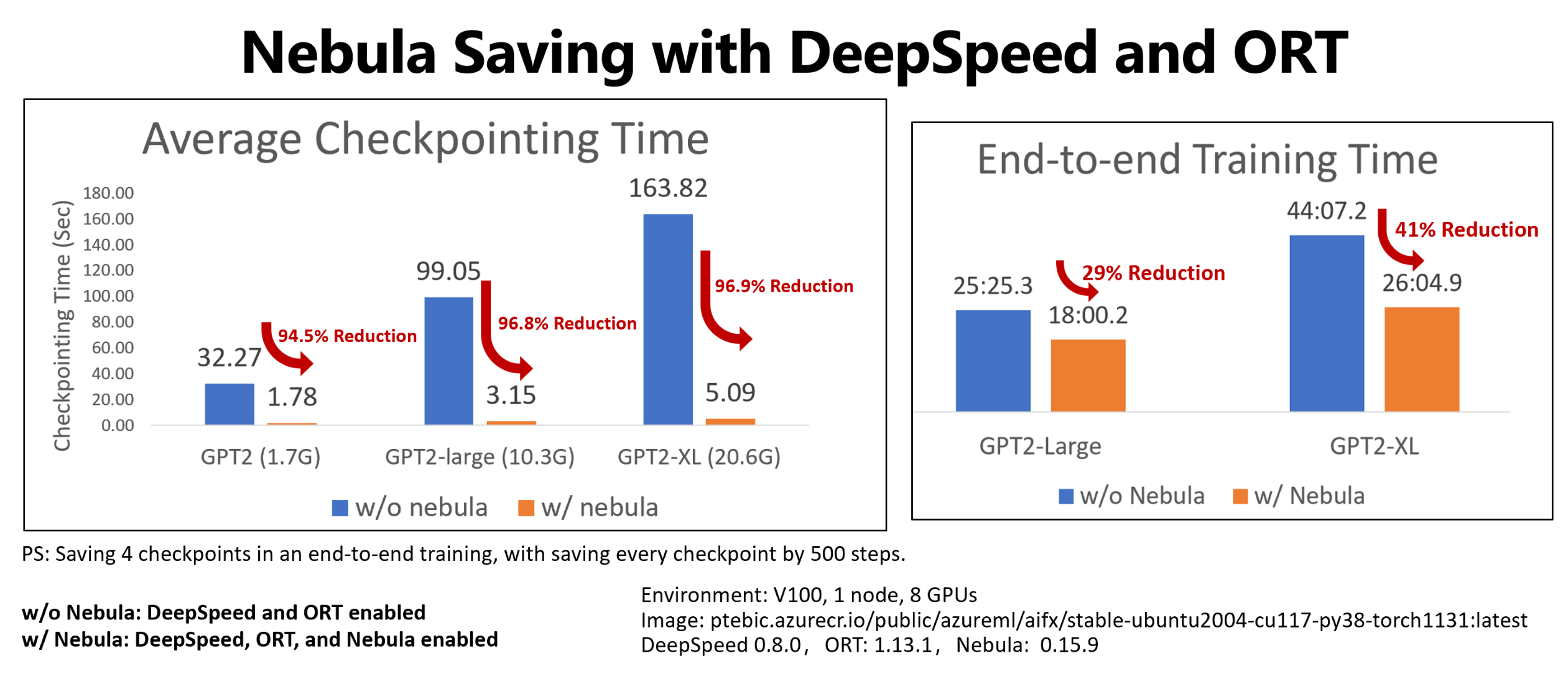
Este exemplo mostra o ponto de verificação e a redução do tempo de treinamento de ponta a ponta de quatro salvamentos de ponto de verificação de trabalhos de treinamento de GPT2, GPT2-Large e GPT-XL do Hugging Face. Para os salvamentos de ponto de verificação GPT2-XL de tamanho médio do Hugging Face (20,6 GB), o Nebula obteve uma redução de tempo de 96,9% em um ponto de verificação.
O ganho de velocidade do ponto de verificação ainda pode aumentar com o tamanho do modelo e os números de GPU. Por exemplo, testar um salvamento de ponto de verificação de treinamento de 97 GB em 128 GPUs Nvidia A100 pode diminuir de 20 minutos para 1 segundo.
Reduza o tempo de treinamento de ponta a ponta e os custos de computação para modelos grandes minimizando a sobrecarga de ponto de verificação e reduzindo o número de horas de GPU desperdiçadas na recuperação do trabalho. O Nebula salva pontos de verificação de forma assíncrona e desbloqueia o processo de treinamento para reduzir o tempo de treinamento de ponta a ponta. Também permite salvamentos de ponto de verificação mais frequentes. Dessa forma, você pode retomar o treinamento do ponto de verificação mais recente após qualquer interrupção e economizar tempo e dinheiro desperdiçado em horas de treinamento de GPU e recuperação de trabalho.
Forneça compatibilidade completa no PyTorch. O Nebula oferece compatibilidade completa com o PyTorch e oferece integração completa com estruturas de treinamento distribuídas, incluindo DeepSpeed (>=0.7.3) e PyTorch-Lightning (>=1.5.0). Você também pode usá-lo com diferentes destinos de computação do Azure Machine Learning, como a Computação do Azure Machine Learning ou o AKS.
Gerencie facilmente seus pontos de verificação com um pacote do Python que ajuda a listar, obter, salvar e carregar seus pontos de verificação. Para mostrar o ciclo de vida do ponto de verificação, o Nebula também fornece logs abrangentes no Estúdio do Azure Machine Learning. Você pode optar por salvar seus pontos de verificação em um local de armazenamento local ou remoto
- Armazenamento do Blobs do Azure
- Armazenamento do Azure Data Lake
- NFS
e acessá-los a qualquer momento com algumas linhas de código.

Pré-requisitos
- Uma assinatura do Azure e um workspace do Azure Machine Learning. Confira Criar recursos do workspace para obter mais informações sobre a criação de recursos do workspace
- Um destino de computação do Azure Machine Learning. Consulte Gerenciar treinamento e implantar computações para saber mais sobre a criação de destinos de computação
- Um script de treinamento que usa o PyTorch.
- Ambiente coletado pelo ACPT (Contêiner do Azure para Pytorch). Confira Ambientes coletados para obter a imagem ACPT. Saiba como usar o ambiente coletado
Como Usar o Nebula
O Nebula fornece uma experiência de ponto de verificação rápida e fácil, diretamente em seu script de treinamento existente. As etapas para iniciar rapidamente o Nebulosa incluem:
- Usando o ambiente ACPT
- Inicializando o Nebula
- Chamar APIs para salvar e carregar pontos de verificação
Usando o ambiente ACPT
O Contêiner Azure para PyTorch (ACPT), um ambiente coletado para treinamento de modelo PyTorch, inclui o Nebula como um pacote Python dependente e pré-instalado. Confira o Contêiner Azure para PyTorch (ACPT) para exibir o ambiente coletado e Habilitar o Aprendizado Profundo com o Contêiner Azure para PyTorch no Azure Machine Learning para saber mais sobre a imagem ACPT.
Inicializando o Nebula
Para habilitar o Nebula no ambiente ACPT, você só precisará modificar o script de treinamento para importar o pacote nebulaml e, em seguida, chamar as APIs do Nebula nos locais apropriados. Você pode evitar a modificação do SDK ou da CLI do Azure Machine Learning. Você também pode evitar a modificação de outras etapas para treinar seu modelo grande na Plataforma do Azure Machine Learning.
O Nebula precisa de inicialização para ser executado em seu script de treinamento. Na fase de inicialização, especifique as variáveis que determinam a localização e a frequência de salvamento de ponto de verificação, conforme mostrado neste snippet de código:
import nebulaml as nm
nm.init(persistent_storage_path=<YOUR STORAGE PATH>) # initialize Nebula
O Nebula foi integrado ao DeepSpeed e PyTorch Lightning. Como resultado, a inicialização torna-se simples e fácil. Esses exemplos mostram como integrar o Nebula aos scripts de treinamento.
Importante
Salvar pontos de verificação com o Nebula requer memória para armazenar pontos de verificação. Verifique se a memória é maior do que pelo menos três cópias dos pontos de verificação.
Se a memória não for suficiente para manter pontos de verificação, é recomendável configurar uma variável NEBULA_MEMORY_BUFFER_SIZE de ambiente no comando para limitar o uso da memória por cada nó ao salvar pontos de verificação. Ao definir essa variável, o Nebula usará essa memória como buffer para salvar pontos de verificação. Se o uso de memória não for limitado, o Nebula usará a memória o máximo possível para armazenar os pontos de verificação.
Se vários processos estiverem em execução no mesmo nó, a memória máxima para salvar pontos de verificação será metade do limite dividido pelo número de processos. O Nebula usará a outra metade para coordenação de vários processos. Por exemplo, se você quiser limitar o uso de memória por cada nó a 200 MB, poderá definir a variável de ambiente como export NEBULA_MEMORY_BUFFER_SIZE=200000000 (em bytes, cerca de 200 MB) no comando. Nesse caso, o Nebula usará apenas 200 MB de memória para armazenar os pontos de verificação em cada nó. Se houver quatro processos em execução no mesmo nó, O Nebula usará 25 MB de memória por cada processo para armazenar os pontos de verificação.
Chamar APIs para salvar e carregar pontos de verificação
O Nebula fornece APIs para lidar com salvamentos de ponto de verificação. Você pode usar essas APIs em seus scripts de treinamento, semelhante à API torch.save() do PyTorch. Esses exemplos mostram como usar o Nebula em seus scripts de treinamento.
Exibir seus históricos de ponto de verificação
Quando o trabalho de treinamento for concluído, navegue até o painel Trabalho Name> Outputs + logs. No painel esquerdo, expanda a pasta Nebula e selecione checkpointHistories.csv para ver informações detalhadas sobre salvamentos de ponto de verificação do Nebula – duração, taxa de transferência e tamanho do ponto de verificação.

Exemplos
Esses exemplos mostram como usar o Nebula com diferentes tipos de estrutura. Você pode escolher o exemplo que melhor se ajusta ao script de treinamento.
Para habilitar a compatibilidade completa do Nebula com scripts de treinamento baseados em PyTorch, modifique o script de treinamento conforme necessário.
Primeiro, importe o pacote
nebulamlnecessário:# Import the Nebula package for fast-checkpointing import nebulaml as nmPara inicializar o Nebula, chame a função
nm.init()emmain(), conforme mostrado aqui:# Initialize Nebula with variables that helps Nebula to know where and how often to save your checkpoints persistent_storage_path="/tmp/test", nm.init(persistent_storage_path, persistent_time_interval=2)Para salvar pontos de verificação, substitua a instrução original
torch.save()para salvar seu ponto de verificação por Nebula. Certifique-se de que sua instância de ponto de verificação comece com "global_step", como "global_step500" ou "global_step1000":checkpoint = nm.Checkpoint('global_step500') checkpoint.save('<CKPT_NAME>', model)Observação
<'CKPT_TAG_NAME'>é a ID exclusiva do ponto de verificação. Uma marca geralmente é o número de etapas, o número da época ou qualquer nome definido pelo usuário. O parâmetro opcional<'NUM_OF_FILES'>especifica o número de estado que você salvaria para essa marca.Carregue o ponto de verificação válido mais recente, conforme mostrado aqui:
latest_ckpt = nm.get_latest_checkpoint() p0 = latest_ckpt.load(<'CKPT_NAME'>)Como um ponto de verificação ou instantâneo pode conter muitos arquivos, você pode carregar um ou mais deles pelo nome. Com o ponto de verificação mais recente, o estado de treinamento pode ser restaurado para o estado salvo pelo último ponto de verificação.
Outras APIs podem lidar com o gerenciamento do ponto de verificação
- listar todos os pontos de verificação
- obter pontos de verificação mais recentes
# Managing checkpoints ## List all checkpoints ckpts = nm.list_checkpoints() ## Get Latest checkpoint path latest_ckpt_path = nm.get_latest_checkpoint_path("checkpoint", persisted_storage_path)