Fragmente documentos grandes para soluções de em busca de vetores no IA do Azure Search
Particionar documentos grandes em partes menores pode ajudar você a ficar abaixo dos limites máximos de entrada de token dos modelos de inserção. Por exemplo, o comprimento máximo do texto de entrada para o modelo text-embedding-ada-002 do OpenAI do Azure é de 8.191 tokens. Considerando que cada token tem cerca de quatro caracteres de texto para modelos comuns do OpenAI, esse limite máximo é equivalente a cerca de 6.000 palavras de texto. Se você estiver usando esses modelos para gerar inserções, é fundamental que o texto de entrada permaneça abaixo do limite. Particionar seu conteúdo em partes garante que seus dados possam ser processados pelos modelos de inserção e que você não perca informações devido ao truncamento.
Recomendamos vetorização integrada para agrupamento e incorporação de dados integrados. A vetorização integrada usa uma dependência de indexadores, conjuntos de habilidades, a habilidade de Divisão de Texto e uma habilidade de inserção como a habilidade de Incorporação do OpenAI do Azure. Se você não puder usar a vetorização integrada, esse artigo descreve algumas abordagens para agrupar seu conteúdo.
Técnicas comuns de agrupamento
O agrupamento só será necessário se os documentos de origem forem muito grandes para o tamanho máximo de entrada imposto pelos modelos.
Estas são algumas técnicas comuns de agrupamento, começando com o método mais usado:
Partes de tamanho fixo: definir um tamanho fixo que seja suficiente para parágrafos semanticamente significativos (por exemplo, 200 palavras) e permita determinada sobreposição (por exemplo, de 10 a 15% do conteúdo) pode produzir boas partes como entrada para a inserção de geradores de vetor.
Partes de tamanho variável com base no conteúdo: particione seus dados com base em características de conteúdo, como marcas de pontuação de fim de frase, marcadores de fim de linha ou uso de recursos nas bibliotecas NLP (Processamento de Linguagem Natural). A estrutura de linguagem Markdown também pode ser usada para dividir os dados.
Personalize ou itere usando uma das técnicas acima. Por exemplo, ao lidar com documentos grandes, você pode usar partes de tamanho variável, mas também acrescentar o título do documento a partes do meio do documento para evitar a perda de contexto.
Considerações sobre a sobreposição de conteúdo
Quando você agrupa dados, sobrepor um pequeno valor de texto entre as partes pode ajudar a preservar o contexto. É recomendável começar com uma sobreposição de aproximadamente 10%. Por exemplo, considerando um tamanho fixo de parte de 256 tokens, você começará a testar com uma sobreposição de 25 tokens. O valor real de sobreposição varia dependendo do tipo de dados e do caso de uso específico, mas constatamos que de 10 a 15% funcionam para muitos cenários.
Fatores para agrupamento de dados
Quando se trata de agrupar dados, pense nesses fatores:
Forma e densidade dos documentos. Se você precisar de texto intacto ou passagens, partes maiores e agrupamento variável que preserve a estrutura das frases poderão produzir melhores resultados.
Consultas de usuário: partes maiores e estratégias de sobreposição ajudam a preservar o contexto e a riqueza semântica para consultas que visam informações específicas.
O LLM (Modelo de Linguagem Grande) têm diretrizes de desempenho para o tamanho da parte. Você precisa definir um tamanho de parte que funcione melhor para todos os modelos que você está usando. Por exemplo, se você usar modelos para resumo e inserções, escolha um tamanho de parte ideal que funcione para ambos.
Como o agrupamento se adapta ao fluxo de trabalho
Se você tiver documentos grandes, deverá inserir uma etapa de fragmentação nos fluxos de trabalho de indexação e consulta que dividem texto grande. Ao usar vetorização integrada, uma estratégia de agrupamento padrão usando a habilidade de divisão de texto é aplicada. Você também poderá aplicar uma estratégia de fragmentação personalizada usando uma habilidade personalizada. Algumas bibliotecas que fornecem agrupamento incluem:
A maioria das bibliotecas fornece técnicas comuns de fragmentação para tamanho fixo, tamanho variável ou uma combinação. Você também pode especificar a sobreposição que duplica um pequeno valor de conteúdo em cada parte para preservação de contexto.
Exemplos de fragmentação
Os exemplos a seguir demonstram como as estratégias de fragmentação são aplicadas ao arquivo PDF e-book Earth at Night da NASA:
Exemplo de habilidade de Divisão de Texto
A fragmentação de dados integrada por meio da habilidade de divisão de texto está geralmente disponível.
Essa seção descreve a fragmentação de dados integrada usando uma abordagem baseada em habilidades e parâmetros de habilidade Divisão de texto.
Um notebook de amostra para esse exemplo pode ser encontrado no repositório azure-search-vector-samples.
Defina textSplitMode para dividir o conteúdo em partes menores:
pages(padrão). As partes são compostas por várias frases.sentences. As partes são compostos por frases simples. O que constitui uma "frase" depende da linguagem. Em inglês, a pontuação de término de frase padrão, como.ou!é usada. O idioma é controlado pelo parâmetrodefaultLanguageCode.
O parâmetro pages adiciona parâmetros extras:
maximumPageLengthdefine o número máximo de caracteres 1 ou tokens 2 em cada parte. O divisor de texto evita a quebra de frases, portanto, a contagem real de caracteres depende do conteúdo.pageOverlapLengthdefine quantos caracteres do final da página anterior estão incluídos no início da próxima página. Se definido, deverá ter menos da metade do tamanho máximo da página.maximumPagesToTakedefine quantas páginas/partes tirar de um documento. O valor padrão é 0, o que significa tirar todas as páginas ou partes do documento.
1 Caracteres não se alinham à definição de um token. O número de tokens medidos pela LLM pode ser diferente do tamanho do caractere medido pela habilidade de Divisão de Texto.
2 O agrupamento de tokens está disponível em 2024-09-01-preview e inclui parâmetros extras para especificar um gerador de token e quaisquer tokens que não devem ser divididos durante o agrupamento.
A tabela a seguir mostra como a escolha dos parâmetros afeta a contagem total de partes do livro eletrônico Earth at Night:
textSplitMode |
maximumPageLength |
pageOverlapLength |
Contagem Total de Partes |
|---|---|---|---|
pages |
1000 | 0 | 172 |
pages |
1000 | 200 | 216 |
pages |
2000 | 0 | 85 |
pages |
2000 | 500 | 113 |
pages |
5000 | 0 | 34 |
pages |
5000 | 500 | 38 |
sentences |
N/D | N/D | 13361 |
Usar um textSplitMode dos pages resulta na maioria das partes com contagens totais de caracteres próximas a maximumPageLength. A contagem de caracteres de partes varia devido a diferenças em que os limites de sentença se enquadram dentro da parte. O comprimento do token de parte varia devido a diferenças no conteúdo da parte.
Os histogramas a seguir mostram como a distribuição do comprimento do caractere de parte se compara ao comprimento do token de parte para gpt-35-turbo ao usar um textSplitMode de pages um maximumPageLength de 2000 e um pageOverlapLength de 500 no livro eletrônico Earth at Night:
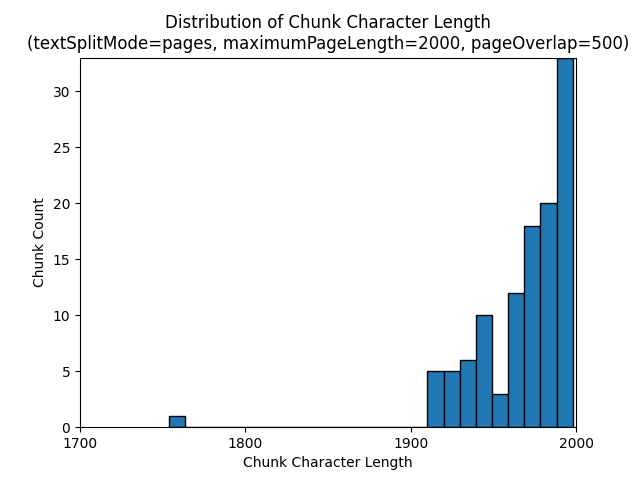
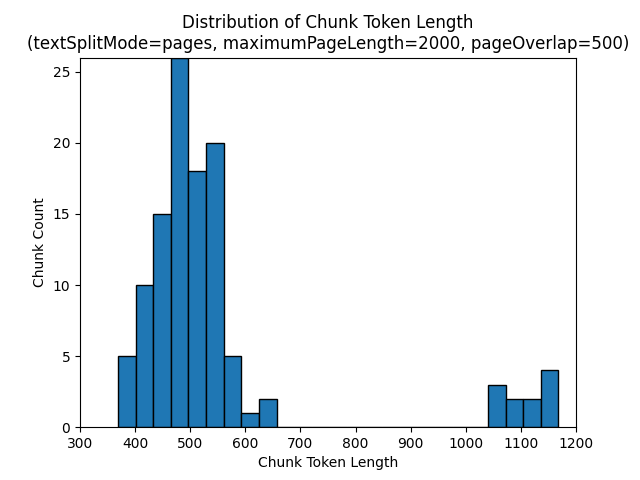
Usar um textSplitMode dos sentences resulta em um grande número de partes que consistem em frases individuais. Essas partes são significativamente menores do que as produzidas por pages e a contagem de tokens das partes corresponde mais de perto às contagens de caracteres.
Os histogramas a seguir mostram como a distribuição do comprimento do caractere de parte se compara ao comprimento do token de parte para gpt-35-turbo ao usar um textSplitMode de sentences no livro eletrônico Earth at Night:
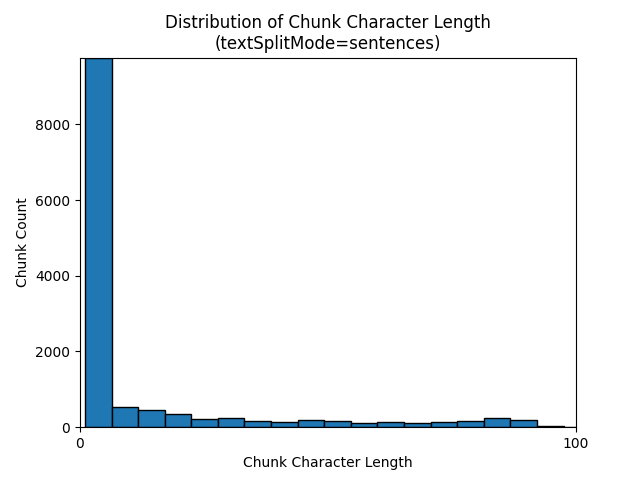
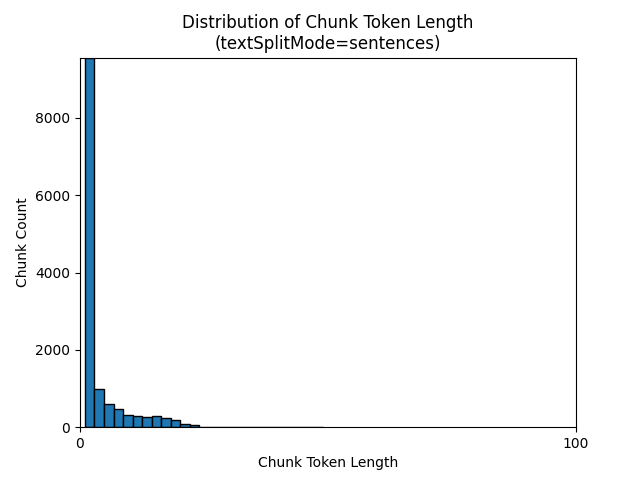
A escolha ideal dos parâmetros depende de como as partes serão usadas. Para a maioria dos aplicativos, é recomendável começar com os seguintes parâmetros padrão:
textSplitMode |
maximumPageLength |
pageOverlapLength |
|---|---|---|
pages |
2000 | 500 |
Exemplo de agrupamento de dados LangChain
O LangChain fornece carregadores de documentos e divisores de texto. Este exemplo mostra como carregar um PDF, obter contagens de token e configurar um divisor de texto. Obter contagens de token ajuda você a tomar uma decisão informada sobre o dimensionamento de partes.
Um bloco de anotações de exemplo para este exemplo pode ser encontrado no repositório azure-search-vector-samples.
from langchain_community.document_loaders import PyPDFLoader
loader = PyPDFLoader("./data/earth_at_night_508.pdf")
pages = loader.load()
print(len(pages))
A saída indica 200 documentos ou páginas no PDF.
Para obter uma contagem de tokens estimada para essas páginas, use TikToken.
import tiktoken
tokenizer = tiktoken.get_encoding('cl100k_base')
def tiktoken_len(text):
tokens = tokenizer.encode(
text,
disallowed_special=()
)
return len(tokens)
tiktoken.encoding_for_model('gpt-3.5-turbo')
# create the length function
token_counts = []
for page in pages:
token_counts.append(tiktoken_len(page.page_content))
min_token_count = min(token_counts)
avg_token_count = int(sum(token_counts) / len(token_counts))
max_token_count = max(token_counts)
# print token counts
print(f"Min: {min_token_count}")
print(f"Avg: {avg_token_count}")
print(f"Max: {max_token_count}")
A saída indica que nenhuma página tem tokens, o comprimento médio do token por página é de 189 tokens e a contagem máxima de tokens de qualquer página é de 1.583.
Conhecer o tamanho médio e máximo do token fornece insights sobre como definir o tamanho da parte. Embora você possa usar a recomendação padrão de 2.000 caracteres com uma sobreposição de 500 caracteres, nesse caso, faz sentido diminuir, considerando as contagens de token do documento de exemplo. Na verdade, definir um valor de sobreposição muito grande pode fazer com que nenhuma sobreposição apareça.
from langchain.text_splitter import RecursiveCharacterTextSplitter
# split documents into text and embeddings
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000,
chunk_overlap=200,
length_function=len,
is_separator_regex=False
)
chunks = text_splitter.split_documents(pages)
print(chunks[20])
print(chunks[21])
A saída de duas partes consecutivas mostra o texto da primeira parte sobreposta na segunda parte. A saída é levemente editada para legibilidade.
'x Earth at NightForeword\nNASA’s Earth at Night explores the brilliance of our planet when it is in darkness. \n It is a compilation of stories depicting the interactions between science and \nwonder, and I am pleased to share this visually stunning and captivating exploration of \nour home planet.\nFrom space, our Earth looks tranquil. The blue ethereal vastness of the oceans \nharmoniously shares the space with verdant green land—an undercurrent of gentle-ness and solitude. But spending time gazing at the images presented in this book, our home planet at night instantly reveals a different reality. Beautiful, filled with glow-ing communities, natural wonders, and striking illumination, our world is bustling with activity and life.**\nDarkness is not void of illumination. It is the contrast, the area between light and'** metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
'**Darkness is not void of illumination. It is the contrast, the area between light and **\ndark, that is often the most illustrative. Darkness reminds me of where I came from and where I am now—from a small town in the mountains, to the unique vantage point of the Nation’s capital. Darkness is where dreamers and learners of all ages peer into the universe and think of questions about themselves and their space in the cosmos. Light is where they work, where they gather, and take time together.\nNASA’s spacefaring satellites have compiled an unprecedented record of our \nEarth, and its luminescence in darkness, to captivate and spark curiosity. These missions see the contrast between dark and light through the lenses of scientific instruments. Our home planet is full of complex and dynamic cycles and processes. These soaring observers show us new ways to discern the nuances of light created by natural and human-made sources, such as auroras, wildfires, cities, phytoplankton, and volcanoes.' metadata={'source': './data/earth_at_night_508.pdf', 'page': 9}
Habilidade personalizada
Uma amostra de geração de agrupamento e inserção de tamanho fixo demonstra a geração de agrupamento e inserção de vetores usando os modelos de inserção do Azure OpenAI. Este exemplo usa uma habilidade personalizada da Pesquisa de IA do Azure no repositório do Power Skills para encapsular a etapa de fragmentação.