Linguagem de Consulta Kusto no Microsoft Sentinel
A Linguagem de Consulta do Kusto é a linguagem que você usará para trabalhar e manipular dados no Microsoft Sentinel. Os logs que você alimentar em seu workspace não têm muito valor se você não pode analisá-los e obter informações importantes ocultas em todos esses dados. A Linguagem de Consulta Kusto não só tem a potência e a flexibilidade para obter essas informações, mas a simplicidade para ajudar você a começar rapidamente. Se você tiver algum conhecimento em script ou em trabalho com bancos de dados, vários dos conteúdos deste artigo serão muito familiares. Caso contrário, não se preocupe, pois a natureza intuitiva da linguagem permite começar rapidamente a escrever suas consultas e gerar valor para sua organização.
Este artigo apresenta os fundamentos da Linguagem de Consulta Kusto, cobrindo algumas das funções e operadores mais usados, que devem abranger de 75 a 80% das consultas que você escreverá diariamente. Quando precisar de mais profundidade ou quiser executar consultas mais avançadas, você poderá aproveitar a nova pasta de trabalho KQL avançada para o Microsoft Sentinel (confira esta postagem no blog introdutória). Confira também a documentação oficial da Linguagem de Consulta Kusto, bem como uma variedade de cursos online (como o da Pluralsight).
Contexto – por que a Linguagem de Consulta Kusto?
O Microsoft Sentinel se baseia no serviço de Azure Monitor e usa workspaces do Log Analytics do Azure Monitor para armazenar todos os próprios dados. Esses dados incluem qualquer um dos seguintes:
- dados ingeridos de fontes externas em tabelas predefinidas usando conectores de dados do Microsoft Sentinel;
- dados ingeridos de fontes externas em tabelas personalizadas definidas pelo usuário, usando conectores de dados criados de modo personalizado, bem como alguns tipos de conectores prontos para uso;
- dados criados pelo Microsoft Sentinel propriamente dito, resultantes das análises que ele cria e executa (por exemplo, alertas, incidentes e informações relacionadas ao UEBA);
- dados carregados no Microsoft Sentinel para auxiliar na detecção e análise (por exemplo, feeds de inteligência contra ameaças e watchlists).
A Linguagem de Consulta Kusto foi desenvolvida como parte do serviço Azure Data Explorer e, portanto, é otimizada para pesquisar armazenamentos de Big Data em um ambiente de nuvem. Inspirado no renomado explorador marítimo Jacques Cousteau (e pronunciado de acordo, "Koo-STOH"), ele foi projetado para ajudar você a se aprofundar em seus oceanos de dados e explorar os tesouros ocultos neles.
A Linguagem de Consulta Kusto também é usada no Azure Monitor (e, portanto, no Microsoft Sentinel), incluindo alguns recursos adicionais do Azure Monitor, que permite que você recupere, visualize e analise dados em armazenamentos de dados do Log Analytics. No Microsoft Sentinel, você estará usando ferramentas baseadas na Linguagem de Consulta Kusto sempre que estiver visualizando e analisando dados e procurando ameaças, seja em regras e pastas de trabalho existentes ou ao criar as suas.
Já que a Linguagem de Consulta Kusto faz parte de praticamente tudo o que você faz no Microsoft Sentinel, uma compreensão clara de como ela funciona ajuda você a aproveitar muito mais o SIEM.
O que é uma consulta?
Uma consulta da Linguagem de Consulta Kusto é uma solicitação somente leitura para processar dados e retornar resultados. Ela não grava nenhum dado. A consulta usa entidades de esquema que são organizadas em uma hierarquia de bancos de dados, tabelas e colunas, semelhante à do SQL.
As solicitações são declaradas em linguagem sem formatação e usam um modelo de fluxo de dados criado para tornar a sintaxe fácil de ler, escrever e automatizar. Veremos isso em detalhes.
As consultas de Linguagem de Consulta Kusto são feitas de instruções separadas por ponto e vírgula. Há muitos tipos de instruções, mas discutiremos aqui apenas dois tipos amplamente usados:
instruções de expressão de tabela são o que normalmente queremos dizer quando falamos sobre consultas, o que chamamos de corpo da consulta. O importante a saber sobre as instruções de expressão de tabela é que elas aceitam uma entrada de tabela (uma tabela ou outra expressão de tabela) e produzem uma saída tabular. É necessário usar pelo menos uma delas. A maior parte do restante deste artigo discutirá esse tipo de instrução.
As instruções let permitem que você crie e defina variáveis e constantes fora do corpo da consulta, para mais legibilidade e versatilidade. Elas são opcionais e dependem de suas necessidades específicas. Abordaremos esse tipo de instrução no final do artigo.
Ambiente de demonstração
Você pode praticar instruções da Linguagem de Consulta Kusto, incluindo as neste artigo, em um ambiente de demonstração do Log Analytics no portal do Azure. Não há nenhum encargo para usar esse ambiente de prática, mas você precisa de uma conta do Azure para acessá-lo.
Explore o ambiente de demonstração. Assim como o Log Analytics em seu ambiente de produção, ele pode ser usado de várias maneiras:
Escolha uma tabela na qual criar uma consulta. Na guia Tabelas padrão (mostrada no retângulo vermelho no canto superior esquerdo), selecione uma tabela na lista de tabelas agrupadas por tópicos (mostrada na parte inferior esquerda). Expanda os tópicos para ver as tabelas individuais e você poderá expandir cada tabela para ver todos os respectivos campos (colunas). Clicar duas vezes em uma tabela ou em um nome de campo o posicionará no ponto do cursor na janela de consulta. Digite o restante da sua consulta após o nome da tabela, conforme indicado abaixo.
Encontre uma consulta existente para estudar ou modificar. Selecione a guia Consultas (mostrada no retângulo vermelho no canto superior esquerdo) para ver uma lista de consultas disponíveis prontas para uso. Ou então, selecione Consultas na barra de botões na parte superior direita. Você pode explorar as consultas prontas para uso que acompanham o Microsoft Sentinel. Clicar duas vezes em uma consulta posicionará toda a consulta na janela de consulta no indicador do cursor.
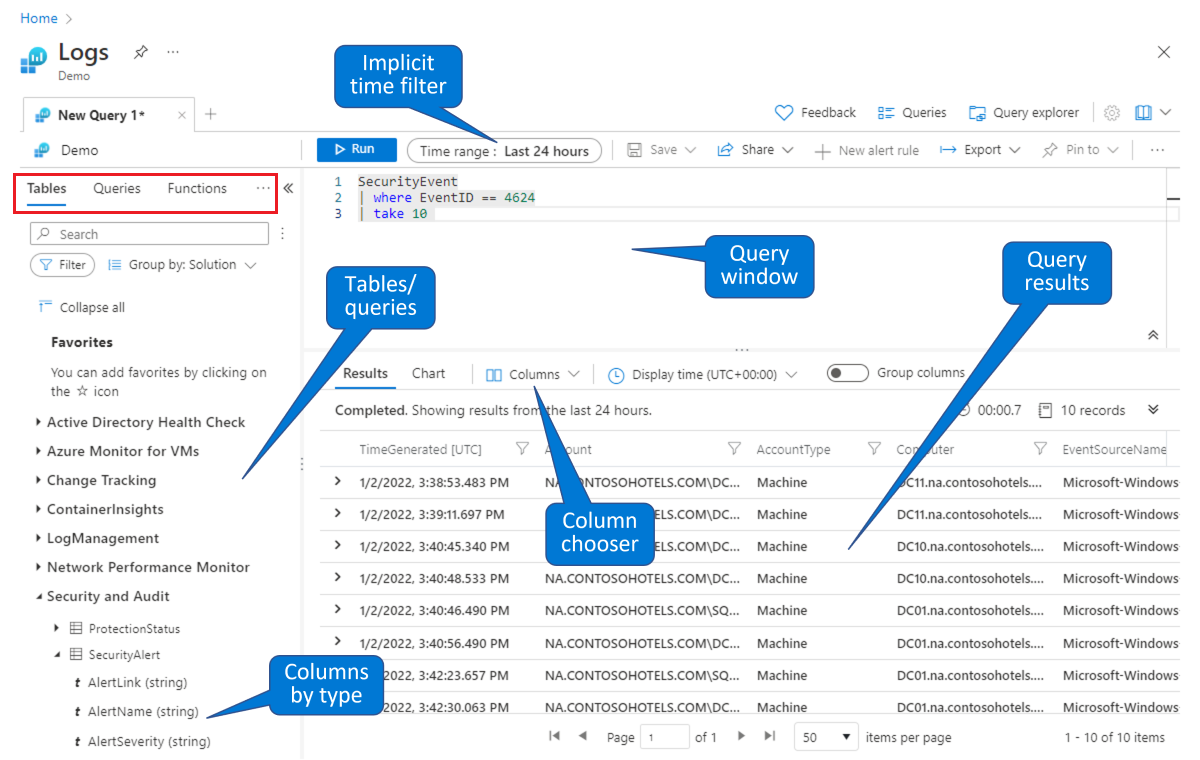
Como neste ambiente de demonstração, você pode consultar e filtrar dados na página de Logs do Microsoft Sentinel. Você pode selecionar uma tabela e fazer uma busca detalhada para ver as colunas. Você pode modificar as colunas padrão mostradas usando o Seletor de coluna e pode definir o intervalo de tempo padrão para consultas. Se o intervalo de tempo for explicitamente definido na consulta, o filtro de tempo ficará indisponível (esmaecido).
Estrutura da consulta
Um bom ponto de partida para aprender a Linguagem de Consulta Kusto é entender a estrutura geral da consulta. A primeira coisa que você observará ao examinar uma consulta Kusto é o uso do símbolo de barra vertical (|). A estrutura de uma consulta Kusto começa com a obtenção dos dados de uma fonte de dados e, em seguida, a passagem dos dados por um "pipeline". Cada etapa fornece algum nível de processamento e depois passa os dados para a próxima etapa. No final do pipeline, você obterá o resultado final. Este é o nosso pipeline:
Get Data | Filter | Summarize | Sort | Select
Este conceito de passagem de dados pelo pipeline resulta em uma estrutura bastante intuitiva, pois é fácil criar uma imagem mental dos dados em cada etapa.
Para ilustrar isso, vamos dar uma olhada na consulta a seguir, que examina os logs de entrada do Microsoft Entra. Ao ler cada linha, você pode ver as palavras-chave que indicam o que está acontecendo com os dados. Incluímos o estágio relevante no pipeline como um comentário em cada linha.
Observação
Você pode adicionar comentários a qualquer linha em uma consulta, precedendo-os com uma barra dupla (//).
SigninLogs // Get data
| evaluate bag_unpack(LocationDetails) // Ignore this line for now; we'll come back to it at the end.
| where RiskLevelDuringSignIn == 'none' // Filter
and TimeGenerated >= ago(7d) // Filter
| summarize Count = count() by city // Summarize
| sort by Count desc // Sort
| take 5 // Select
Já que a saída de cada etapa serve como a entrada para a etapa seguinte, a ordem das etapas pode determinar os resultados da consulta e afetar o desempenho dela. É crucial que você ordene as etapas de acordo com o que deseja obter da consulta.
Dica
- Uma boa regra prática é filtrar os dados antecipadamente, para que você só passe os dados relevantes pelo pipeline. Isso aumentará muito o desempenho e garantirá que você não inclua acidentalmente dados irrelevantes nas etapas de resumo.
- Este artigo indicará algumas outras práticas recomendadas para ter em mente. Para obter uma lista mais completa, confira práticas recomendadas de consulta.
Espero que agora você tenha um conhecimento básico da estrutura geral de uma consulta na Linguagem de Consulta Kusto. Agora, vamos examinar os operadores de consulta propriamente ditos, que são usados para criar uma consulta.
Tipos de dados
Antes de entrarmos nos operadores de consulta, vamos primeiro dar uma olhada rápida nos tipos de dados. Como na maioria das linguagens de programação, o tipo de dados determina quais cálculos e manipulações podem ser executados em um valor. Por exemplo, se você tiver um valor que seja do tipo string, não poderá executar cálculos aritméticos nele.
Na Linguagem de Consulta Kusto, a maioria dos tipos de dados segue as convenções padrão e tem nomes que você provavelmente já viu antes. A seguinte tabela mostra a lista completa:
Tabela de tipos de dados
| Type | Nomes adicionais | Tipo equivalente do .NET |
|---|---|---|
bool |
Boolean |
System.Boolean |
datetime |
Date |
System.DateTime |
dynamic |
System.Object |
|
guid |
uuid, uniqueid |
System.Guid |
int |
System.Int32 |
|
long |
System.Int64 |
|
real |
Double |
System.Double |
string |
System.String |
|
timespan |
Time |
System.TimeSpan |
decimal |
System.Data.SqlTypes.SqlDecimal |
Embora a maioria dos tipos de dados seja padrão, você pode estar menos familiarizado com tipos como dynamic, timespan e guid.
Dynamic tem uma estrutura muito semelhante ao JSON, mas com uma diferença importante: ela pode armazenar tipos de dados específicos à Linguagem de Consulta Kusto que o JSON tradicional não pode, como um valor dynamic ou timespan. Aqui está um exemplo de um tipo dynamic:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Timespan é um tipo de dados que se refere a uma medida de tempo, como horas, dias ou segundos. Não confunda timespan com datetime, que é avaliado como uma data e hora reais, não uma medida de tempo. A tabela a seguir mostra uma lista de sufixos de timespan.
Sufixos de timespan
| Função | Descrição |
|---|---|
D |
dias |
H |
horas |
M |
minutes |
S |
segundos |
Ms |
milissegundos |
Microsecond |
microssegundos |
Tick |
nanossegundos |
Guid é um tipo de dados que representa um identificador global exclusivo de 128 bits, que segue o formato padrão de [8]-[4]-[4]-[4]-[12], em que cada [número] representa o número de caracteres e cada caractere pode variar de 0-9 ou a-f.
Observação
A Linguagem de Consulta Kusto tem operadores de tabela e escalares. No restante deste artigo, se você simplesmente vê a palavra "operador", pode pressupor que isso significa um operador tabular, salvo indicação em contrário.
Obtenção, limitação, classificação e filtragem de dados
O vocabulário principal da Linguagem de Consulta Kusto – a base que permitirá que você realize a grande maioria das tarefas – é uma coleção de operadores para filtrar, classificar e selecionar seus dados. As tarefas restantes que você precisará fazer exigirão que você amplie seu conhecimento da linguagem para atender às suas necessidades mais avançadas. Vamos falar em mais detalhes sobre alguns dos comandos que usamos no exemplo acima e examinar take, sort e where.
Examinaremos o uso de cada um desses operadores em nosso exemplo anterior de SigninLogs e aprenderemos uma dica útil ou uma prática recomendada.
Obtendo dados
A primeira linha de qualquer consulta básica especifica a tabela com a qual você deseja trabalhar. No caso do Microsoft Sentinel, provavelmente será o nome de um tipo de log em workspace, como SigninLogs, SecurityAlert ou CommonSecurityLog. Por exemplo:
SigninLogs
Observe que na Linguagem de Consulta Kusto, os nomes de log diferenciam maiúsculas de minúsculas, então SigninLogs e signinLogs serão interpretados de maneira diferente. Tome cuidado ao escolher nomes para seus logs personalizados, para que eles sejam facilmente identificáveis e não sejam semelhantes demais a outro log.
Limitando dados: take / limit
O operador take (e o operador limit idêntico) é usado para limitar os resultados retornando apenas um determinado número de linhas. Ele é seguido por um inteiro que especifica o número de linhas a serem retornadas. Normalmente, ele é usado no final de uma consulta depois que você determina a ordem de classificação e, nesse caso, retorna o número determinado de linhas na parte superior da ordem classificada.
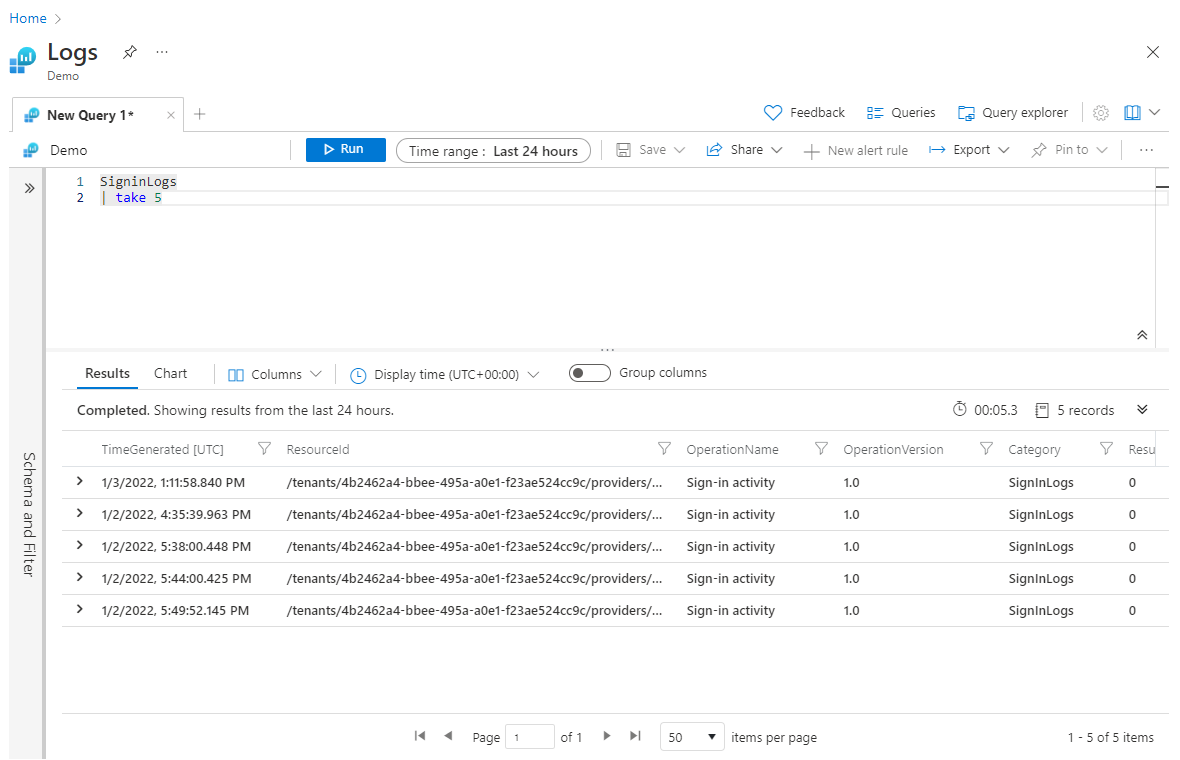
O uso de take anteriormente na consulta pode ser útil para testar uma consulta, quando você não deseja retornar grandes conjuntos de altos. No entanto, se você posicionar a operação take antes de qualquer operação sort, o take retornará linhas selecionadas aleatoriamente e, possivelmente, um conjunto diferente de linhas toda vez que a consulta for executada. Veja um exemplo de como usar o take:
SigninLogs
| take 5
Dica
Ao trabalhar em uma consulta totalmente nova, caso em que você pode não saber qual será a aparência da consulta, pode ser útil colocar uma instrução take no começo para limitar artificialmente o seu conjunto de dados para experimentações e processamento mais rápidos. Quando estiver satisfeito com a consulta completa, você poderá remover a etapa inicial take.
Classificando dados: sort / order
O operador sort (e o operador order idêntico) é usado para classificar os dados por uma coluna especificada. No exemplo a seguir, ordenamos os resultados por TimeGenerated e definimos a direção da ordem como decrescente com o parâmetro desc, colocando os valores mais altos primeiro; para ordem crescente, usamos asc.
Observação
A direção padrão para classificações é decrescente, portanto, tecnicamente, você só precisa especificar algo se deseja classificar em ordem crescente. No entanto, especificar a direção de classificação sempre tornará sua consulta mais legível.
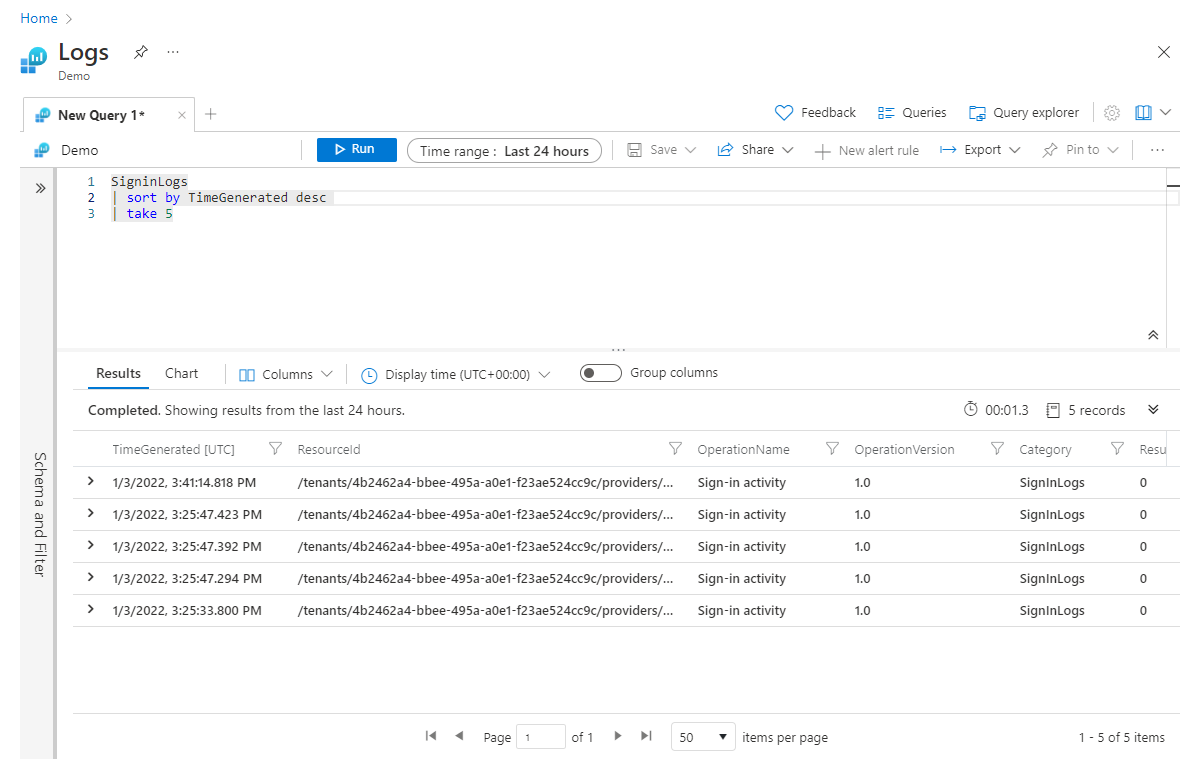
SigninLogs
| sort by TimeGenerated desc
| take 5
Como mencionamos, colocamos o operador sort antes do operador take. Precisamos classificar primeiro para garantir que obtenhamos os cinco registros apropriados.
Top
O operador top nos permite combinar as operações sort e take em apenas um operador:
SigninLogs
| top 5 by TimeGenerated desc
Nos casos em que dois ou mais registros têm o mesmo valor na coluna pela qual você está classificando, você pode adicionar mais colunas pelas quais classificar. Adicione colunas de classificação extras em uma lista separada por vírgulas, localizadas após a primeira coluna de classificação, mas antes da palavra-chave da ordem de classificação. Por exemplo:
SigninLogs
| sort by TimeGenerated, Identity desc
| take 5
Agora, se TimeGenerated for o mesmo entre vários registros, ele tentará classificar pelo valor na coluna Identity.
Observação
Quando usar sort e take, e quando usar top
Se você estiver classificando por apenas um campo, use
top, pois ele fornece um melhor desempenho do que a combinação desortetake.Se você precisar classificar por mais de um campo (como no último exemplo acima),
topnão poderá fazê-lo, então você precisará usarsortetake.
Filtrando dados: where
O operador where é, sem dúvida, o operador mais importante, porque é a chave para garantir que você está trabalhando apenas com o subconjunto de dados que é relevante para seu cenário. Você deve fazer o melhor para filtrar seus dados o mais cedo possível na consulta, pois isso aprimorará o desempenho da consulta, reduzindo a quantidade de dados que precisarão ser processados nas etapas subsequentes; isso também garantirá que você esteja apenas realizando cálculos nos dados desejados. Confira este exemplo:
SigninLogs
| where TimeGenerated >= ago(7d)
| sort by TimeGenerated, Identity desc
| take 5
O operador where especifica uma variável, um operador de comparação (scalar) e um valor. Em nosso caso, usamos >= para indicar que o valor na coluna TimeGenerated precisa ser maior que (ou seja, mais tarde que) ou igual a sete dias atrás.
Há dois tipos de operadores de comparação na Linguagem de Consulta Kusto: de cadeia de caracteres e numéricos. A seguinte tabela mostra a lista completa de operadores numéricos:
Operadores numéricos
| Operador | Descrição |
|---|---|
+ |
Adição |
- |
Subtração |
* |
Multiplicação |
/ |
Divisão |
% |
Módulo |
< |
Menor que |
> |
Maior que |
== |
Igual a |
!= |
É diferente de |
<= |
Menor que ou igual a |
>= |
Maior que ou igual a |
in |
Igual a um dos elementos |
!in |
Diferente de qualquer um dos elementos |
A lista de operadores de cadeia de caracteres é uma lista muito mais longa porque tem permutações para diferenciação de maiúsculas e minúsculas, localizações de substrings, prefixos, sufixos e muito mais. O operador == é um operador numérico e de cadeia de caracteres, o que significa que ele pode ser usado para números e texto. Por exemplo, ambas as seguintes instruções seriam válidas em instruções where:
| where ResultType == 0| where Category == 'SignInLogs'
Dica
Prática recomendada: na maioria dos casos, você provavelmente desejará filtrar os dados por mais de uma coluna ou filtrar a mesma coluna de mais de uma maneira. Nessas instâncias, há duas práticas recomendadas que você deve ter em mente.
Você pode combinar várias instruções where em apenas uma etapa usando a palavra-chave and. Por exemplo:
SigninLogs
| where Resource == ResourceGroup
and TimeGenerated >= ago(7d)
Quando você tiver vários filtros unidos em apenas uma instrução where usando a palavra-chave and, como acima, obterá um melhor desempenho colocando primeiro filtros que apenas façam referência a uma coluna. Portanto, uma maneira melhor de escrever a consulta acima seria:
SigninLogs
| where TimeGenerated >= ago(7d)
and Resource == ResourceGroup
Neste exemplo, o primeiro filtro menciona apenas uma coluna (TimeGenerated), enquanto a segunda faz referência a duas colunas (Resource e ResourceGroup).
Resumindo dados
Summarize é um dos operadores de tabela mais importantes na Linguagem de Consulta Kusto, mas também é um dos operadores mais complexos para saber se você é novo para as linguagens de consulta em geral. O trabalho do summarize é pegar uma tabela de dados e gerar uma nova tabela agregada por uma ou mais colunas.
Estrutura da instrução summarize
A estrutura básica de uma instrução summarize é a seguinte:
| summarize <aggregation> by <column>
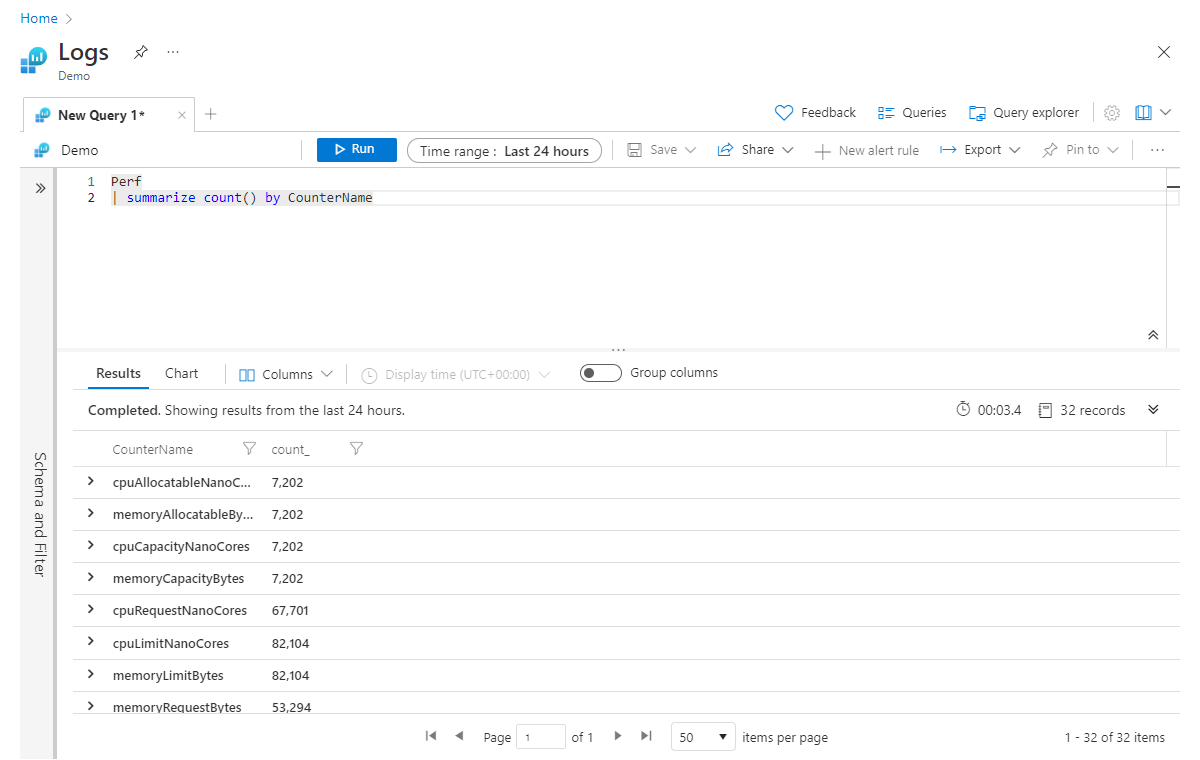
Por exemplo, o seguinte retornaria a contagem de registros para cada valor CounterName na tabela Perf:
Perf
| summarize count() by CounterName
Como a saída de summarize é uma nova tabela, todas as colunas não especificadas explicitamente na instrução summarizenão serão passadas para o pipeline. Para ilustrar esse conceito, considere este exemplo:
Perf
| project ObjectName, CounterValue, CounterName
| summarize count() by CounterName
| sort by ObjectName asc
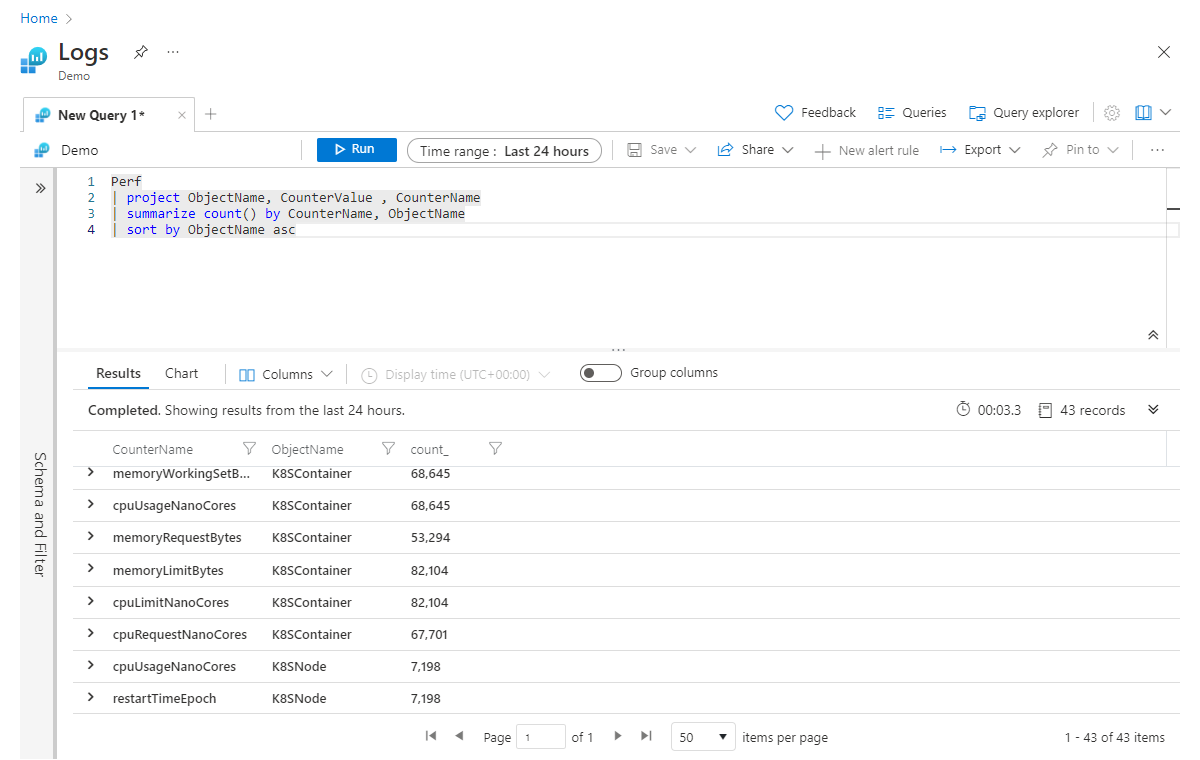
Na segunda linha, estamos especificando que nos preocupamos apenas com as colunas ObjectName, CounterValue e CounterName. Em seguida, resumimos para obter a contagem de registros por CounterName e, por fim, tentamos classificar os dados em ordem crescente com base na coluna ObjectName. Infelizmente, essa consulta falhará com um erro (indicando que o ObjectName é desconhecido) porque, quando resumimos, incluímos apenas as colunas Count e CounterName em nossa nova tabela. Para evitar esse erro, podemos simplesmente adicionar ObjectName ao final de nossa etapa summarize, deste modo:
Perf
| project ObjectName, CounterValue , CounterName
| summarize count() by CounterName, ObjectName
| sort by ObjectName asc
Para você, a maneira de ler a linha summarize seria: "resumir a contagem de registros por CounterName e agrupar por ObjectName". Você pode continuar adicionando colunas, separadas por vírgulas, ao final da instrução summarize.
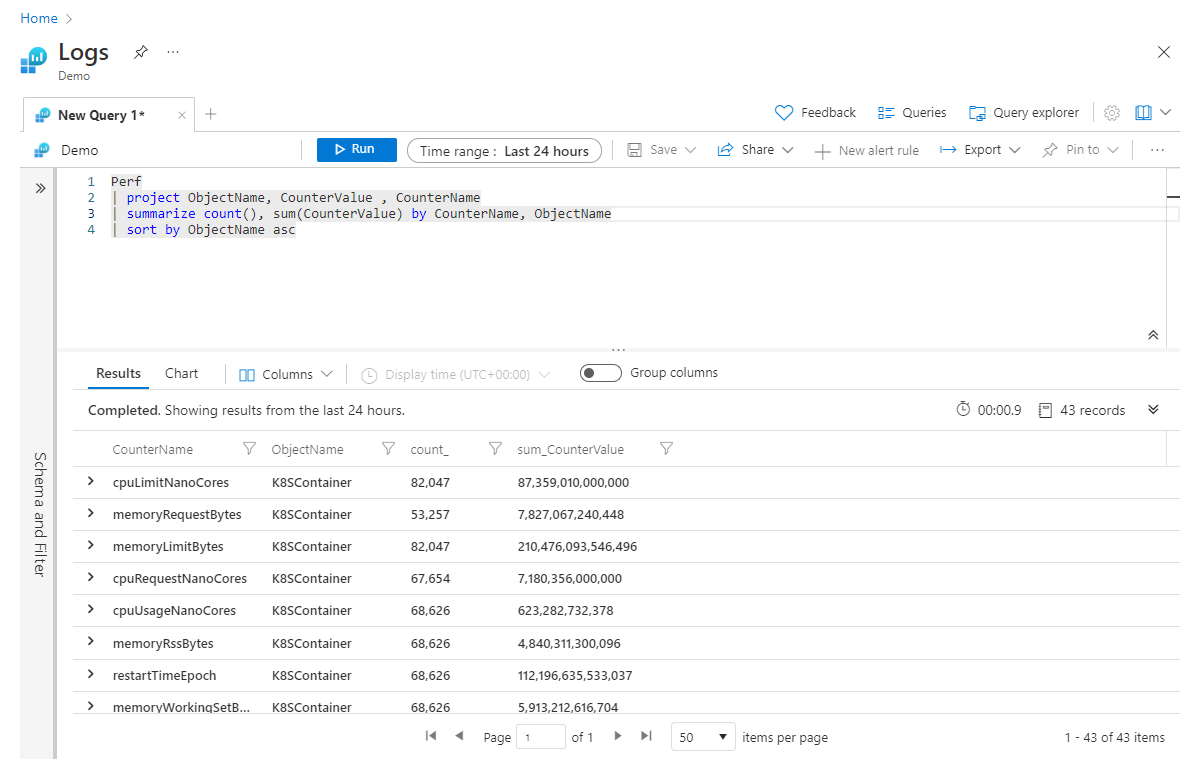
Com base no exemplo anterior, se quisermos agregar várias colunas ao mesmo tempo, podemos conseguir isso adicionando agregações ao operador summarize, separadas por vírgulas. No exemplo a seguir, estamos obtendo não apenas uma contagem de todos os registros, mas também uma soma dos valores na coluna CounterValue em todos os registros (que correspondem a quaisquer filtros na consulta):
Perf
| project ObjectName, CounterValue , CounterName
| summarize count(), sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
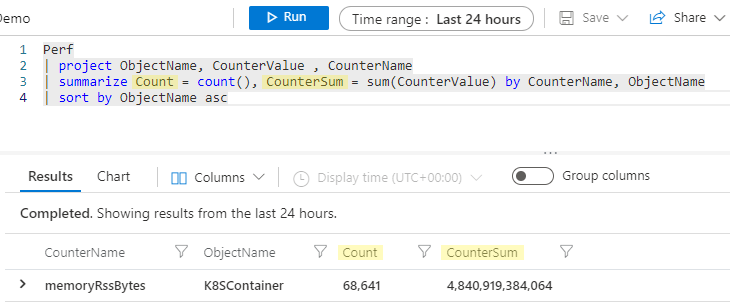
Renomeando colunas agregadas
Este parece um bom momento para falar sobre nomes de coluna para essas colunas agregadas. No início desta seção, dissemos que o operador summarize recebe uma tabela de dados e produz uma nova tabela, e somente as colunas que você especificar na instrução summarize continuarão pelo pipeline. Portanto, se você executar o exemplo acima, as colunas resultantes para nossa agregação serão count_ e sum_CounterValue.
O mecanismo Kusto criará automaticamente um nome de coluna sem que seja preciso ser explícito, mas, muitas vezes, será preferível que sua nova coluna tenha um nome mais amigável. Você pode renomear facilmente sua coluna na instrução summarize especificando um novo nome, seguido por = e a agregação, desta forma:
Perf
| project ObjectName, CounterValue , CounterName
| summarize Count = count(), CounterSum = sum(CounterValue) by CounterName, ObjectName
| sort by ObjectName asc
Agora, nossas colunas resumidas serão nomeadas Count e CounterSum.
O operador summarize é muito mais complexo do que podemos abranger aqui, mas você deve investir tempo para aprender, pois ele é um componente fundamental para qualquer análise de dados que você planeje executar em seus dados do Microsoft Sentinel.
Referência de agregação
Há muitas funções de agregação, mas algumas das mais comumente usadas são sum(), count() e avg(). Aqui está uma lista parcial (consulte a lista completa):
Funções de agregação
| Função | Descrição |
|---|---|
arg_max() |
Retorna uma ou mais expressões quando o argumento é maximizado |
arg_min() |
Retorna uma ou mais expressões quando o argumento é minimizado |
avg() |
Retorna um valor médio do grupo |
buildschema() |
Retorna o esquema mínimo que admite todos os valores da entrada dinâmica |
count() |
Retorna a contagem do grupo |
countif() |
Retorna a contagem com o predicado do grupo |
dcount() |
Retorna uma contagem distinta aproximada dos elementos do grupo |
make_bag() |
Retorna um recipiente de propriedades de valores dinâmicos dentro do grupo |
make_list() |
Retorna uma lista de todos os valores dentro do grupo |
make_set() |
Retorna um conjunto de valores distintos dentro do grupo |
max() |
Retorna o valor máximo no grupo |
min() |
Retorna o valor mínimo no grupo |
percentiles() |
Retorna o percentual aproximado do grupo |
stdev() |
Retorna o desvio padrão no grupo |
sum() |
Retorna a soma dos elementos dentro do grupo |
take_any() |
Retorna um valor não vazio aleatório para o grupo |
variance() |
Retorna a variância no grupo |
Seleção: adicionar e remover colunas
À medida que você começa a trabalhar mais com consultas, pode achar que tem mais informações do que precisa em suas entidades (ou seja, muitas colunas em sua tabela). Ou talvez você precise de mais informações do que tem (ou seja, você precisa adicionar uma nova coluna que conterá os resultados da análise de outras colunas). Vamos ver alguns dos principais operadores para manipulação de colunas.
Project e project-away
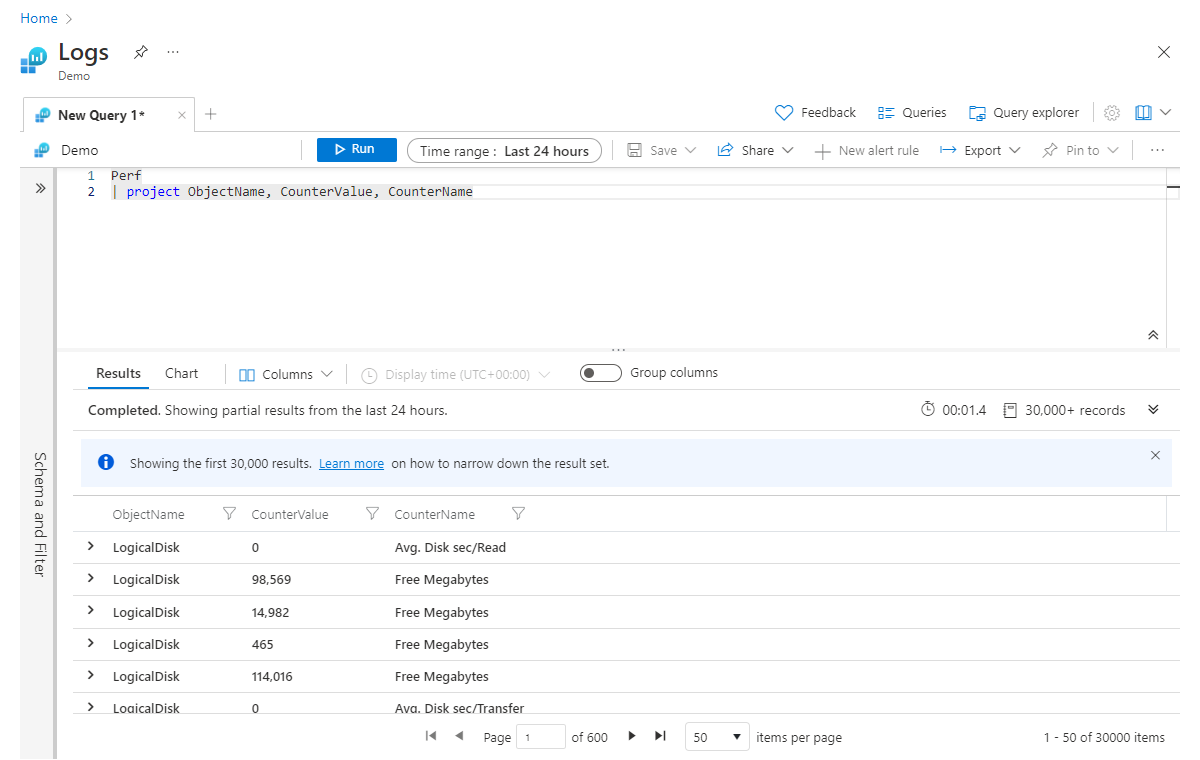
Project é aproximadamente equivalente às instruções select de várias linguagens de programação. Isso permite que você escolha quais colunas deseja manter. A ordem das colunas retornadas corresponderá à ordem das colunas listadas na instrução project, conforme mostrado neste exemplo:
Perf
| project ObjectName, CounterValue, CounterName
Como você pode imaginar, ao trabalhar com conjuntos de dados muito amplos, você pode ter muitas colunas que deseja manter e especificar todas elas por nome exigiria muita digitação. Para esses casos, você tem project-away, que permite especificar quais colunas remover, em vez de quais manter, deste modo:
Perf
| project-away MG, _ResourceId, Type
Dica
Pode ser útil usar project em dois locais em suas consultas, no início e novamente no final. O uso precoce de project em sua consulta pode ajudar a aprimorar o desempenho, retirando grandes partes de dados que você não precisa passar pelo pipeline. Usá-lo novamente no final permite que você se livre de todas as colunas que podem ter sido criadas nas etapas anteriores e não são necessárias na saída final.
Estender
Extend é usado para criar uma coluna calculada. Isso pode ser útil quando você deseja executar um cálculo em relação a colunas existentes e ver a saída para cada linha. Vejamos um exemplo simples em que calculamos uma nova coluna chamada Kbytes, que podemos calcular multiplicando o valor de MB (na coluna Quantidade existente) por 1.024.
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| project ResourceUri, MBytes=Quantity, KBytes
Na linha final em nossa instrução project, renomearemos a coluna Quantidade para Mbytes, para que possamos facilmente dizer qual unidade de medida é relevante para cada coluna.
Vale a pena notar que extend também funciona com colunas já calculadas. Por exemplo, podemos adicionar mais uma coluna chamada Bytes, calculada de Kbytes:
Usage
| where QuantityUnit == 'MBytes'
| extend KBytes = Quantity * 1024
| extend Bytes = KBytes * 1024
| project ResourceUri, MBytes=Quantity, KBytes, Bytes
Unir tabelas
Grande parte do seu trabalho no Microsoft Sentinel pode ser executada usando apenas um tipo de log, mas há ocasiões em que você deseja correlacionar dados ou executar uma pesquisa em a outro conjunto de dados. Assim como a maioria das linguagens de consulta, a Linguagem de Consulta Kusto oferece alguns operadores usados para executar vários tipos de junções. Nesta seção, vamos ver os operadores mais usados, union e join.
Union
Union simplesmente pega duas ou mais tabelas e retorna todas as linhas. Por exemplo:
OfficeActivity
| union SecurityEvent
Isso retornaria todas as linhas das tabelas OfficeActivity e SecurityEvent. Union oferece alguns parâmetros que podem ser usados para ajustar o comportamento da união. Dois dos mais úteis são withsource e kind:
OfficeActivity
| union withsource = SourceTable kind = inner SecurityEvent
O parâmetro withsource permite especificar o nome de uma nova coluna cujo valor em uma determinada linha será o nome da tabela da qual a linha for proveniente. No exemplo acima, nomeamos a coluna SourceTable e, dependendo da linha, o valor será OfficeActivity ou SecurityEvent.
O outro parâmetro que especificamos era kind, que tem duas opções: inner ou outer. No exemplo acima, especificamos inner, o que significa que as únicas colunas que serão mantidas durante a união são aquelas que existem em ambas as tabelas. Como alternativa, se especificássemos outer (que é o valor padrão), todas as colunas de ambas as tabelas seriam retornadas.
Join
Join funciona de forma semelhante a union, exceto que, em vez de unir tabelas para formar uma nova tabela, estamos unindo linhas para formar uma nova tabela. Assim como na maioria das linguagens do banco de dados, há vários tipos de junções que você pode executar. A sintaxe geral para um join é:
T1
| join kind = <join type>
(
T2
) on $left.<T1Column> == $right.<T2Column>
Após o operador join, especificamos o kind (tipo) de junção que desejamos executar, seguido por um parêntese aberto. Dentro dos parênteses, você especifica a tabela que deseja unir, bem como qualquer outra instrução de consulta naquela tabela que você deseja adicionar. Após o parêntese de fechamento, usamos a palavra-chave on seguida por nossas colunas esquerda ($left.<nomeDaColuna> palavra-chave) e direita ($right.<nomeDaColuna>) separadas pelo operador ==. Segue abaixo um exemplo de junção interna:
OfficeActivity
| where TimeGenerated >= ago(1d)
and LogonUserSid != ''
| join kind = inner (
SecurityEvent
| where TimeGenerated >= ago(1d)
and SubjectUserSid != ''
) on $left.LogonUserSid == $right.SubjectUserSid
Observação
Se ambas as tabelas têm o mesmo nome para as colunas nas quais você está executando uma junção, você não precisa usar $left e $right; em vez disso, você pode apenas especificar o nome da coluna. Usar $left e $right, no entanto, é mais explícito e geralmente considerado uma boa prática.
Para sua referência, a tabela a seguir mostra uma lista de tipos de junções disponíveis.
Tipos de junções
| Tipo de junção | Descrição |
|---|---|
inner |
Retorna um valor single para cada combinação de linhas correspondentes de ambas as tabelas. |
innerunique |
Retorna linhas da tabela esquerda com valores distintos no campo vinculado que têm uma correspondência na tabela à direita. Esse é o tipo de junção não especificado padrão. |
leftsemi |
Retorna todos os registros da tabela à esquerda que têm uma correspondência na tabela à direita. Somente colunas da tabela à esquerda serão retornadas. |
rightsemi |
Retorna todos os registros da tabela à direita que têm uma correspondência na tabela à esquerda. Somente colunas da tabela à direita serão retornadas. |
leftanti/leftantisemi |
Retorna todos os registros da tabela à esquerda que não têm nenhuma correspondência na tabela à direita. Somente colunas da tabela à esquerda serão retornadas. |
rightanti/rightantisemi |
Retorna todos os registros da tabela à direita que não têm nenhuma correspondência na tabela à esquerda. Somente colunas da tabela à direita serão retornadas. |
leftouter |
Retorna todos os registros da tabela à esquerda. Para registros que não tiverem nenhuma correspondência na tabela à direita, os valores de célula serão nulos. |
rightouter |
Retorna todos os registros da tabela à direita. Para registros que não tiverem nenhuma correspondência na tabela à esquerda, os valores de célula serão nulos. |
fullouter |
Retorna todos os registros das tabelas à esquerda e à direita, correspondentes ou não. Os valores sem correspondência serão nulos. |
Dica
É uma prática recomendada manter sua menor tabela à esquerda. Em alguns casos, seguir essa regra pode lhe fornecer grandes benefícios de desempenho, dependendo dos tipos de junções que você está executando e do tamanho das tabelas.
Avaliar
Você pode se lembrar que, de volta no primeiro exemplo, vimos o operador evaluate em uma das linhas. O operador evaluate é usado com menos frequência do que aqueles que abordamos anteriormente. No entanto, é muito útil saber como o operador evaluate funciona. Mais uma vez, aqui está a primeira consulta, onde você verá evaluate na segunda linha.
SigninLogs
| evaluate bag_unpack(LocationDetails)
| where RiskLevelDuringSignIn == 'none'
and TimeGenerated >= ago(7d)
| summarize Count = count() by city
| sort by Count desc
| take 5
Esse operador permite que você invoque os plug-ins disponíveis (basicamente, funções internas). Muitos desses plug-ins se concentram em ciência de dados, como autocluster, diffpatterns e sequence_detect, permitindo que você execute análises avançadas e descubra exceções e anomalias estatísticas.
O plug-in usado no exemplo acima foi chamado de bag_unpack e torna muito fácil pegar uma parte dos dados dinâmicos e convertê-los em colunas. Lembre-se de que dados dinâmicos são um tipo de dados que parece muito semelhante ao JSON, conforme mostrado neste exemplo:
{
"countryOrRegion":"US",
"geoCoordinates": {
"longitude":-122.12094116210936,
"latitude":47.68050003051758
},
"state":"Washington",
"city":"Redmond"
}
Nesse caso, queríamos resumir os dados por cidade, mas city está contido como uma propriedade dentro da coluna LocationDetails. Para usar a propriedade city em nossa consulta, tivemos que primeiro convertê-la em uma coluna usando bag_unpack.
Voltando para nossas etapas de pipeline originais, vimos o seguinte:
Get Data | Filter | Summarize | Sort | Select
Agora que já consideramos o operador evaluate, podemos ver que ele representa um novo estágio no pipeline, que agora tem a seguinte aparência:
Get Data | Parse | Filter | Summarize | Sort | Select
Há muitos outros exemplos de operadores e funções que podem ser usados para analisar fontes de dados em um formato mais legível e manipulável. Você pode aprender sobre eles e sobre o restante da Linguagem de Consulta Kusto na documentação completa e na pasta de trabalho.
Instruções LET
Agora que já abordamos muitos dos principais operadores e tipos de dados, vamos concluir falando da instrução let, que é uma ótima maneira de facilitar a leitura, a edição e a manutenção de suas consultas.
A let permite que você crie e defina uma variável ou atribua um nome a uma expressão. Essa expressão pode ser apenas um único valor, mas também pode ser uma consulta completa. Confira um exemplo simples:
let aWeekAgo = ago(7d);
SigninLogs
| where TimeGenerated >= aWeekAgo
Aqui, especificamos um nome de aWeekAgo e o definimos como sendo igual à saída de uma função timespan, que retorna um valor datetime. Em seguida, encerramos a instrução let com um ponto e vírgula. Agora temos uma nova variável chamada aWeekAgo, que pode ser usada em qualquer lugar em nossa consulta.
Como acabamos de mencionar, você pode usar uma instrução let para fazer uma consulta inteira e dar um nome ao resultado. Como os resultados da consulta, sendo expressões tabulares, podem ser usados como entradas de consultas, você pode tratar esse resultado nomeado como uma tabela para executar outra consulta nele. Aqui está uma pequena modificação no exemplo anterior:
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
Nesse caso, criamos uma segunda instrução let, na qual encapsulamos nossa consulta inteira em uma nova variável chamada getSignins. Exatamente como antes, encerramos a instrução let com um ponto e vírgula. Em seguida, chamamos a variável na linha final, que executará a consulta. Observe que foi possível usar aWeekAgo na segunda instrução let. Isso ocorre porque especificamos isso na linha anterior; se alternássemos as instruções let para que getSignins viessem primeiro, obteríamos um erro.
Agora, podemos usar getSignins como a base de outra consulta (na mesma janela):
let aWeekAgo = ago(7d);
let getSignins = SigninLogs
| where TimeGenerated >= aWeekAgo;
getSignins
| where level >= 3
| project IPAddress, UserDisplayName, Level
As instruções let oferecem mais poder e flexibilidade para ajudar a organizar suas consultas. Instruções let podem definir valores escalares e tabulares, bem como criar funções definidas pelo usuário. Elas são realmente úteis quando você está organizando consultas mais complexas, que podem estar fazendo várias junções.
Próximas etapas
Embora este artigo tenha tratado destes temas apenas superficialmente, agora você tem a base necessária, e nós abordamos as partes que você usará com mais frequência para realizar seu trabalho no Microsoft Sentinel.
KQL avançado para a pasta de trabalho do Microsoft Sentinel
Aproveite uma pasta de trabalho da Linguagem de Consulta Kusto diretamente no Microsoft Sentinel – a pasta de trabalho KQL avançada para o Microsoft Sentinel. Ela fornece a você ajuda passo a passo e exemplos para muitas das situações que você provavelmente encontrará durante as operações de segurança cotidianas, e também indica muitos exemplos prontos para uso de regras de análise, pastas de trabalho, regras de busca e mais elementos que usam consultas Kusto. Inicie esta pasta de trabalho na folha Pastas de trabalho do Microsoft Sentinel.
Advanced KQL Framework Workbook - Empowering you to become KQL-savvy é uma postagem no blog excelente que mostra como usar essa pasta de trabalho.
Mais recursos
Confira esta coleção de recursos de aprendizado, treinamento e desenvolvimento de habilidades para ampliar e aprofundar seu conhecimento sobre a Linguagem de Consulta Kusto.