Fazer o upgrade e atualizar os clusters do Azure Service Fabric
Um cluster do Azure Service Fabric é um recurso cujo proprietário é você, mas que é parcialmente gerenciado pela Microsoft. Este artigo descreve as opções para quando e como atualizar seu cluster de Service Fabric Azure.
Atualizações automáticas versus manuais
É essencial garantir que seu cluster Service Fabric sempre executa uma versão de runtime com suporte. Quando anunciamos o lançamento de uma nova versão do Service Fabric, a versão anterior é marcada para o fim do suporte após um mínimo de 60 dias a partir da data do comunicado. Novas versões são anunciadas no blog da equipe do Service Fabric.
Catorze dias antes da expiração da versão do cluster em execução, um evento de integridade é gerado, colocando seu cluster em um estado de integridade de Aviso. O cluster permanecerá em um estado de aviso até você atualize para uma versão do runtime com suporte.
Você pode definir seu cluster para receber atualizações automáticas do Service Fabric à medida que elas são lançadas pela Microsoft ou pode escolher manualmente em uma lista de versões compatíveis no momento. Essas opções estão disponíveis na seção Atualizações do Fabric do recurso Service Fabric cluster.
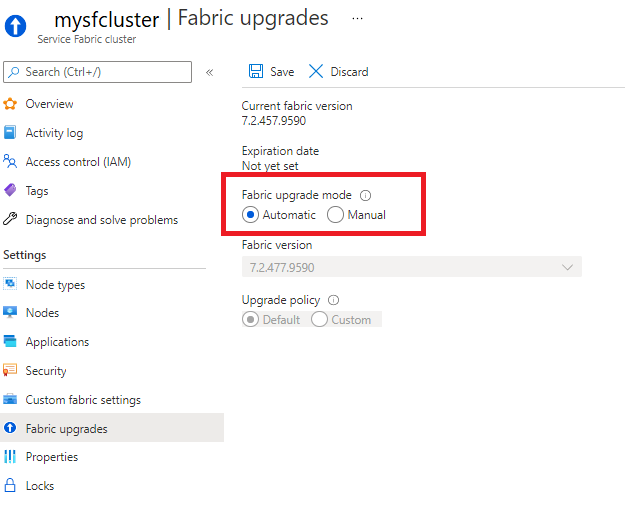
Você também pode definir o modo de atualização do cluster e selecionar uma versão de runtime usando um modelo do Resource Manager.
As atualizações automáticas são o modo de atualização recomendado, pois essa opção garante que o cluster permaneça em um estado com suporte e se benesse das correções e recursos mais recentes, permitindo também agendar atualizações de uma maneira que seja menos interruptiva para suas cargas de trabalho usando uma estratégia de implantação de onda.
Observação
Se você alterar um cluster existente para o modo automático, o cluster será inscrito no próximo período de atualização que começar com uma nova versão. Novas versões são anunciadas no blog da equipe do Service Fabric. É escolhido o caminho de atualização mais alto possível por período de atualização. Consulte versões com suporte. O modo de atualização manual dispara uma atualização imediata.
Implantação de onda para atualizações automáticas
Com a implantação de onda, você pode minimizar a interrupção de uma atualização para o cluster selecionando o nível de maturidade de uma atualização, dependendo da carga de trabalho. Por exemplo, você pode configurar um pipeline de implantação de onda Teste ->Estágio ->Produção para seus vários clusters Service Fabric para testar a compatibilidade de uma atualização de runtime antes de aplicá-la às cargas de trabalho de produção.
Para optar pela implantação de onda, especifique um dos seguintes valores de onda para o cluster (em seu modelo de implantação):
- Onda 0: os clusters são atualizados assim que um novo build do Service Fabric é liberado. Destinado a clusters de desenvolvimento/teste.
- Onda 1: os clusters são atualizados uma semana (sete dias) após o lançamento de um novo build. Destinado a clusters de pré-produção/preparo.
- Onda 2: os clusters são atualizados duas semanas (14 dias) após o lançamento de um novo build. Destinado a clusters de produção.
Você pode se registrar para receber notificações por email com links para obter mais ajuda se houver falha na atualização do cluster. Confira Implantação de onda para atualizações automáticas para começar.
Fases da atualização automática
A Microsoft mantém o código de runtime do Service Fabric e a configuração executada em um cluster do Azure. Executamos atualizações automáticas monitoradas no software de acordo com a necessidade. Essas atualizações podem ser feitas no código, na configuração ou em ambos. Para minimizar o impacto dessas atualizações em seus aplicativos, elas são executadas nas seguintes fases:
Fase 1: uma atualização é executada usando todas as políticas de integridade do cluster
Durante esta fase, as atualizações realizam um domínio de atualização por vez, e os aplicativos em execução no cluster continuam em execução sem qualquer tempo de inatividade. As políticas de saúde do cluster (para a saúde do nó e a saúde do aplicativo) são aderidas durante a atualização.
Se as políticas de integridade do cluster não forem atendidas, a atualização será revertida e um email será enviado ao proprietário da assinatura. O email contém as seguintes informações:
- Uma notificação de que precisamos reverter uma atualização de cluster.
- Sugestões de ações corretivas, se houver alguma.
- O número de dias (n) até a execução da Fase 2.
Tentamos executar a mesma atualização algumas vezes mais, caso alguma atualização falhe por motivos de infraestrutura. Após os n dias a partir da data de envio do email, prosseguiremos para a Fase 2.
Se as políticas de integridade do cluster forem atendidas, a atualização será considerada bem-sucedida e marcada como concluída. Essa situação poderá acontecer durante a atualização inicial ou durante qualquer nova execução das atualizações desta fase. Não há nenhuma confirmação de email de uma execução bem-sucedida, para evitar o envio de emails excessivos. Receber um email indica uma exceção a operações normais. Esperamos que a maioria das atualizações do cluster tenha êxito sem afetar a disponibilidade de seu aplicativo.
Fase 2: uma atualização é executada usando apenas as políticas de integridade padrão
As políticas de integridade desta fase são definidas de forma que o número de aplicativos íntegros no início da atualização permaneça o mesmo durante o processo de atualização. Assim como na Fase 1, na Fase 2 as atualizações ocorrem em um domínio de atualização por vez, e os aplicativos em execução no cluster continuam em execução sem qualquer tempo de inatividade. As políticas de integridade do cluster (uma combinação de integridade do nó e da integridade de todos os aplicativos executados no cluster) são atendidas durante a atualização.
Se as políticas de integridade do cluster em vigor não forem atendidas, a atualização será revertida. Em seguida, um email é enviado ao proprietário da assinatura. O email contém as seguintes informações:
- Uma notificação de que precisamos reverter uma atualização de cluster.
- Sugestões de ações corretivas, se houver alguma.
- O número de dias (n) até a execução da Fase 3.
Tentamos executar a mesma atualização algumas vezes mais, caso alguma atualização falhe por motivos de infraestrutura. Um lembrete será enviado por email alguns dias antes do término dos n dias. Após os n dias a partir da data de envio do email, prosseguiremos para a Fase 3. Os emails que enviamos na Fase 2 devem ser levados a sério e as ações corretivas devem ser realizadas.
Se as políticas de integridade do cluster forem atendidas, a atualização será considerada bem-sucedida e marcada como concluída. Isso poderá acontecer durante a atualização inicial ou durante qualquer nova execução das atualizações desta fase. Nenhum email de confirmação será enviado após uma execução bem-sucedida.
Fase 3: uma atualização é executada usando políticas de integridade agressivas
Essas políticas de integridade desta fase são destinadas à conclusão da atualização, em vez da integridade dos aplicativos. Pouquíssimas atualizações de cluster chegam a esta fase. Caso seu cluster chegue a esta fase, há uma boa chance de seu aplicativo deixar de ser íntegro e/ou de perder a disponibilidade.
Assim como nas duas outras fases, as atualizações da Fase 3 realizam um domínio de atualização por vez.
Se as políticas de integridade do cluster não forem atendidas, a atualização será revertida. Tentamos executar a mesma atualização algumas vezes mais, caso alguma atualização falhe por motivos de infraestrutura. Depois disso, o cluster será marcado para que não receba mais suporte e/ou atualizações.
Um email com essas informações é enviado ao proprietário da assinatura, juntamente com as ações corretivas. Não esperamos que qualquer cluster entre em um estado no qual a Fase 3 falhou.
Se as políticas de integridade do cluster forem atendidas, a atualização será considerada bem-sucedida e marcada como concluída. Isso poderá acontecer durante a atualização inicial ou durante qualquer nova execução das atualizações desta fase. Nenhum email de confirmação será enviado após uma execução bem-sucedida.
Políticas personalizadas para atualizações manuais
Você pode especificar políticas de integridade personalizadas para atualizações manuais do cluster. Essas políticas são aplicadas cada vez que você seleciona uma nova versão de runtime, o que dispara o início da atualização do cluster no sistema. Se você não substituir as políticas, os padrões serão usados. Para obter mais informações, consulte Definir políticas personalizadas para atualizações manuais.
Outras atualizações de cluster
Fora da atualização do tempo de execução, há várias outras ações que talvez você precise executar para manter o cluster atualizado, incluindo o seguinte:
Gerenciando certificados
O Service Fabric usa certificados de servidor X.509 que você especifica ao criar um cluster para proteger as comunicações entre os nós de cluster e autenticar clientes. Você pode adicionar, atualizar ou excluir certificados de cluster e do cliente no portal do Azure ou usando a CLI do Azure/PowerShell. Para saber mais, leia adicionar ou remover certificados
Abrindo portas de aplicativo
Você pode alterar as portas do aplicativo alterando as propriedades do recurso de Balanceador de carga associadas ao tipo de nó. Você pode utilizar o portal do Azure ou pode usar o PowerShell/CLI do Azure. Para obter mais informações, leia Abrir portas do aplicativo para um cluster.
Definindo propriedades de nó
Às vezes, você pode querer garantir que determinadas cargas de trabalho sejam executadas apenas em determinados tipos de nós no cluster. Por exemplo, algumas cargas de trabalho podem exigir GPUs ou SSDs, enquanto outras, não. Para cada um dos tipos de nós em um cluster, você pode adicionar propriedades de nós customizados aos nós do cluster. As restrições de posicionamento são as instruções anexadas a serviços individuais que selecionam uma ou mais propriedades do nó. Restrições de posicionamento definem onde os serviços devem ser executados.
Para obter detalhes sobre o uso de restrições de posicionamento, propriedades do nó e como defini-las, leia propriedades do nó e restrições de posicionamento.
Adicionar métricas de capacidade
Para cada um dos tipos de nó, é possível adicionar métricas de capacidade personalizadas que você deseja usar em seus aplicativos para relatar a carga. Para obter detalhes sobre o uso de métricas de capacidade para relatar carga, confira os documentos do Gerenciador de Recursos do cluster do Service Fabric em Descrevendo seu cluster e Métricas e carga.
Revisando as configurações do cluster
Muitas configurações diferentes podem ser personalizadas em um cluster, como o nível de confiabilidade das propriedades de nó e o cluster. Para obter mais informações, leia as configurações da malha do cluster do Service Fabric .
Observação
Para clusters que usam versões do runtime anteriores a 10.0CU6, 10.1CU5 e 9.1CU12, se você modificou ou planeja modificar quaisquer configurações de NTLM para o FileStoreService, espere algum tempo de inatividade enquanto os nós do cluster são reiniciados. Essa reinicialização está vinculada à limpeza que ocorre durante o ciclo de atualização.
Esse comportamento foi alterado a partir das versões 10.0CU6, 10.1CU5 e 9.1CU12, e nenhuma reinicialização de nós deve ocorrer em clusters executando essas versões ou posteriores.
Para obter mais informações sobre o controle de versão do Service Fabric, confira a página de versões.
Atualizando imagens do sistema operacional para nós de cluster
A habilitação de atualizações automáticas de imagem do sistema operacional para seus nós de Cluster Service Fabric é uma prática recomendada. Para fazer isso, há vários requisitos de cluster e etapas a serem executadas. Outra opção é usar o POA (aplicativo de orquestração de patch). Um aplicativo do Service Fabric que automatiza a correção do sistema operacional em um cluster do Service Fabric sem tempo de inatividade. Para saber mais sobre essas opções, confira Patch do sistema operacional Windows em seu cluster Service Fabric.