Introdução aos Reliable Actors do Service Fabric
Os Reliable Actors são uma estrutura do aplicativo do Service Fabric baseada no padrão de Ator Virtual. A API dos Reliable Actors fornece um modelo de programação single-threaded fundamentado nas garantias de escalabilidade e confiabilidade fornecidas pelo Service Fabric.
O que são Atores?
Um ator é uma unidade isolada e independente de computação e de estado com execução single-threaded. O padrão de ator é um modelo computacional para sistemas simultâneos ou distribuídos nos quais uma grande quantidade desses atores pode ser executada de modo simultâneo e independente entre si. Os atores podem se comunicar entre si e criar outros atores.
Quando usar os Reliable Actors
Os Reliable Actors do Service Fabric são uma implementação do padrão de design de ator. Assim como ocorre com qualquer padrão de design de software, a escolha de determinado padrão leva em conta se um problema relacionado ao design de software é adequado ao padrão ou não.
Embora o padrão de design de ator possa ser uma boa opção para diversos problemas e cenários de sistemas distribuídos, deve-se ter bastante cuidado no que diz respeito às restrições do padrão e à estrutura utilizada para a implementação. Como diretriz geral, considere o padrão de ator para modelar seu problema ou cenário se:
- Seu problema de espaço envolve um grande número (milhares ou milhões) de pequenas unidades de estado e lógica que, além de serem independentes, são isoladas.
- Você deseja trabalhar com objetos single-threaded que não exigem interação significativa de componentes externos, incluindo a consulta de estado em um conjunto de atores.
- Suas instâncias de ator não bloquearão chamadores com atrasos imprevisíveis emitindo operações de E/S.
Atores no Service Fabric
No Service Fabric, os atores são implementados na estrutura dos Reliable Actors: uma estrutura do aplicativo baseada no padrão de ator criada nos Reliable Services do Service Fabric. Cada serviço escrito do Reliable Actor é, de fato, um Reliable Service com estado particionado.
Cada ator é definido como uma instância de um tipo de ator, da mesma forma que um objeto do .NET é uma instância de um tipo do .NET. Por exemplo, pode haver um tipo de ator que implementa a funcionalidade de uma calculadora e pode haver muitos atores desse tipo que são distribuídos em vários nós em um cluster. Cada ator desse é exclusivamente identificado por uma ID de ator.
Tempo de vida do ator
Os atores de Malha de Serviço são virtuais, o que significa que o tempo de vida não está associado à sua representação na memória. Como resultado, eles não precisam ser explicitamente criados ou destruídos. O runtime dos Reliable Actors ativa automaticamente um ator na primeira vez que ele recebe uma solicitação para essa ID de ator. Caso um ator não seja usado por determinado período de tempo, o objeto na memória é coletado como lixo pelo runtime dos Reliable Actors. Ele também mantém a informação da existência do ator caso seja necessário reativá-lo mais tarde. Para obter mais detalhes, veja Ciclo de vida do ator e coleta de lixo.
Em virtude do modelo de ator virtual, há alguns alertas para a abstração do tempo de vida desse ator virtual. De fato, a implementação dos Reliable Actors, às vezes, desvia desse modelo.
- Um ator é ativado automaticamente (possibilitando a construção de um objeto de ator) na primeira vez que uma mensagem é enviada à sua ID de ator. Após algum tempo, o objeto de ator é coletado como lixo. No futuro, ao usar a ID de ator novamente, isso faz com que um novo objeto de ator seja construído. O estado de um ator é maior que o tempo de vida do objeto quando ele é armazenado no gerenciador de estado.
- A chamada a qualquer método de ator para obter uma ID de ator ativa esse ator. Por esse motivo, os tipos de ator têm seus construtores chamados implicitamente pelo runtime. Portanto, o código cliente não pode passar parâmetros ao construtor do tipo de ator, embora os parâmetros possam ser passados para o construtor do ator pelo próprio serviço. O resultado é que os atores poderão ser construídos em um estado parcialmente inicializado quando os outros métodos forem chamados neles, caso os atores exijam parâmetros de inicialização do cliente. Não há um ponto de entrada único para a ativação de um ator por meio do cliente.
- Embora os Reliable Actors criem implicitamente objetos de ator, você tem a capacidade de excluir explicitamente um ator e seu estado.
Distribuição e failover
Para fornecer escalabilidade e confiabilidade, o Service Fabric distribui atores em todo o cluster e os migra automaticamente de nós com falha para nós íntegros conforme necessário. Essa é uma abstração de um Reliable Service com estado particionado. Distribuição, escalabilidade, confiabilidade e failover automático são todos fornecidos em virtude do fato de que os atores são executados em um Reliable Service com estado chamado Serviço de Ator.
Os atores são distribuídos entre as partições do Serviço de Ator que, por sua vez, são distribuídas entre os nós em um cluster do Service Fabric. Cada partição de serviço contém um conjunto de atores. O Service Fabric gerencia a distribuição e o failover das partições de serviço.
Por exemplo, um serviço de ator com nove partições implantadas em três nós usando o posicionamento padrão de partição de ator seria distribuído deste modo:
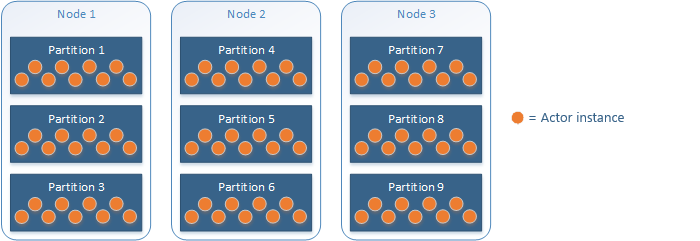
A Estrutura de Ator gerencia o esquema de partição e as configurações de intervalo de chaves para você. Isso simplifica algumas escolhas, mas também traz algumas considerações:
- Os Reliable Services permitem escolher um esquema de particionamento, um intervalo de chaves (ao usar um esquema de particionamento de intervalos) e uma contagem de partições. Os Reliable Actors são restritos ao esquema de particionamento de intervalos (o esquema Int64 uniforme) e exige o uso do intervalo de chaves Int64 completo.
- Por padrão, os atores são colocados aleatoriamente em partições, resultando em uma distribuição uniforme.
- Como os atores são colocados aleatoriamente, deve-se esperar que as operações de ator sempre exijam a comunicação de rede, incluindo a serialização e desserialização de dados de chamada de método, incorrendo em latência e sobrecarga.
- Em cenários avançados, é possível controlar o posicionamento de partições de ator usando IDs de ator do tipo Int64 que são mapeadas para partições específicas. No entanto, isso poderá resultar em uma distribuição desbalanceada de atores nas partições.
Para obter mais informações sobre como os serviços de ator são particionados, veja conceitos de particionamento para atores.
Comunicação do ator
As interações de ator são definidas em uma interface compartilhada pelo ator que implementa a interface e pelo cliente que obtém um proxy para um ator pela mesma interface. Como essa interface é usada para invocar métodos de ator de forma assíncrona, cada método na interface deve ser do tipo Retorno de tarefas.
As invocações de método e suas respostas resultam, em última análise, em solicitações de rede no cluster; portanto, os argumentos e os tipos de resultado das tarefas retornados por elas devem ser serializáveis pela plataforma. Em particular, eles devem ser contrato de dados serializáveis.
O proxy de ator
A API do cliente Reliable Actors permite a comunicação entre uma instância do ator e um cliente do ator. Para se comunicar com um ator, um cliente cria um objeto proxy de ator que implementa a interface do ator. O cliente interage com o ator invocando métodos no objeto proxy. O proxy de ator pode ser usado para a comunicação entre cliente e ator, bem como entre ator e ator.
// Create a randomly distributed actor ID
ActorId actorId = ActorId.CreateRandom();
// This only creates a proxy object, it does not activate an actor or invoke any methods yet.
IMyActor myActor = ActorProxy.Create<IMyActor>(actorId, new Uri("fabric:/MyApp/MyActorService"));
// This will invoke a method on the actor. If an actor with the given ID does not exist, it will be activated by this method call.
await myActor.DoWorkAsync();
// Create actor ID with some name
ActorId actorId = new ActorId("Actor1");
// This only creates a proxy object, it does not activate an actor or invoke any methods yet.
MyActor myActor = ActorProxyBase.create(actorId, new URI("fabric:/MyApp/MyActorService"), MyActor.class);
// This will invoke a method on the actor. If an actor with the given ID does not exist, it will be activated by this method call.
myActor.DoWorkAsync().get();
Observe que os dois conjuntos de informações usadas para criar o objeto de proxy de ator são a ID do ator e o nome do aplicativo. A ID de ator é um identificador exclusivo do ator, enquanto o nome do aplicativo identifica o aplicativo do Service Fabric em que o ator foi implantado.
A classe ActorProxy(C#) / ActorProxyBase(Java) do lado do cliente executa a resolução necessária para localizar o ator por ID e abrir um canal de comunicação com ele. Ela também tenta localizar novamente o ator no caso de falhas de comunicação e failovers. Como resultado, a entrega de mensagem tem as seguintes características:
- A entrega de mensagem é o melhor esforço.
- Os atores podem receber mensagens duplicadas do mesmo cliente.
Simultaneidade
O runtime dos Reliable Actors fornece um modelo de acesso baseado em turno simples para acessar os métodos de ator. Isso significa que não é permitido mais de um thread ativo no código do objeto de um ator a qualquer momento. O acesso baseado em turno simplifica consideravelmente os sistemas simultâneos, pois não há necessidade de mecanismos de sincronização para o acesso a dados. Isso também significa que os sistemas devem ser projetados com considerações especiais sobre a natureza do acesso single-threaded de cada instância de ator.
- Uma única instância de ator não pode processar mais de uma solicitação por vez. Uma instância de ator poderá causar um gargalo da taxa de transferência se tiver de manipular solicitações simultâneas.
- Os atores poderão causar um deadlock mútuo se houver uma solicitação circular entre dois atores caso uma solicitação externa seja feita para um dos atores simultaneamente. O runtime do ator atingirá automaticamente o tempo limite nas chamadas de ator e gerará uma exceção ao chamador para que este interrompa as possíveis situações de deadlock.
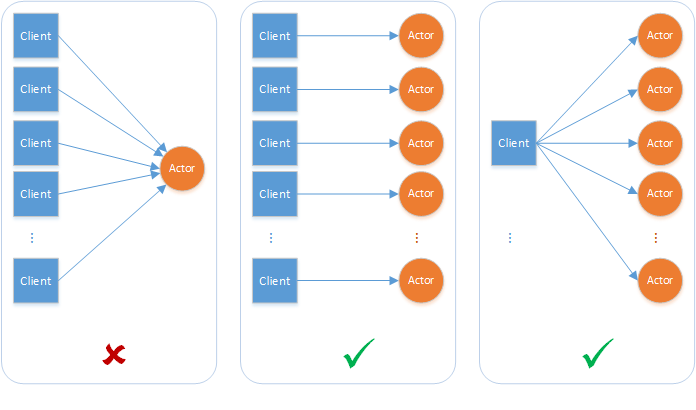
Acesso com base em vez
Um turno consiste na execução completa de um método de ator em resposta a uma solicitação de outros atores ou clientes, ou na execução completa de um retorno de chamada de temporizador/lembrete . Mesmo que esses métodos e retornos de chamada sejam assíncronos, o runtime dos Atores não os intercala. Um turno deve ser totalmente concluído antes que um novo turno seja permitido. Em outras palavras, um método de ator ou retorno de chamada de temporizador/lembrete que está em execução no momento deve ser concluído totalmente antes que uma nova chamada a um método ou um retorno de chamada seja permitido. Um método ou retorno de chamada será considerado concluído se a execução tiver sido retornada do método ou retorno de chamada, e a Tarefa retornada pelo método ou retorno de chamada tiver sido concluída. Vale enfatizar que a simultaneidade baseada em turno é respeitada mesmo entre métodos, temporizadores e retornos de chamada diferentes.
O runtime dos Atores impõe simultaneidade baseada em turno adquirindo um bloqueio por ator no início de um turno e liberando o bloqueio no fim do turno. Desse modo, a simultaneidade baseada em turno é imposta por ator e não entre atores. Os métodos de ator e retornos de chamada de temporizador/lembrete podem ser executados simultaneamente em nome de diferentes atores.
O exemplo a seguir ilustra os conceitos acima. Considere um tipo de ator que implementa dois métodos assíncronos (digamos, Method1 e Method2), um temporizador e um lembrete. O diagrama abaixo mostra um exemplo de uma linha do tempo para a execução desses métodos e retornos de chamada em nome de dois atores (ActorId1 e ActorId2) que pertencem a esse tipo de ator.
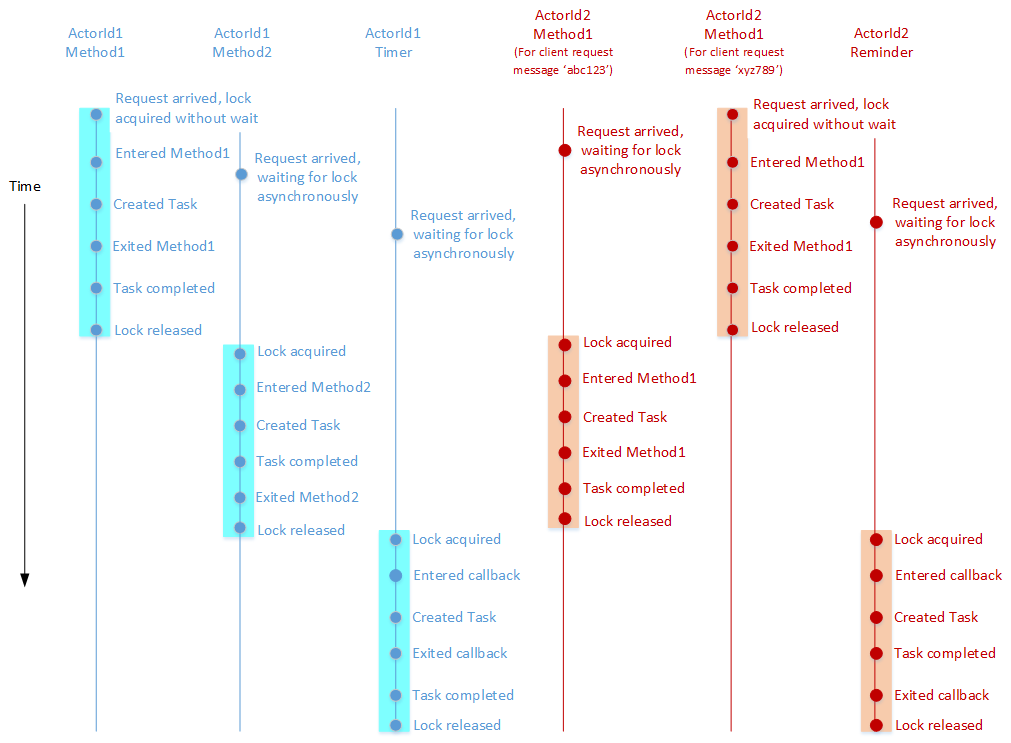
O diagrama segue as seguintes convenções:
- Cada linha vertical mostra o fluxo lógico de execução de um método ou um retorno de chamada em nome de um ator específico.
- Os eventos marcados em cada linha vertical ocorrem em ordem cronológica com os eventos mais recentes ocorrendo abaixo dos mais antigos.
- As diferentes cores são usadas para linhas do tempo que correspondem a diferentes atores.
- O realce é usado para indicar por quanto tempo o bloqueio por ator é mantido em nome de um método ou retorno de chamada.
Alguns pontos importantes a considerar:
- Enquanto Method1 está sendo executado em nome de ActorId2 em resposta à solicitação do cliente xyz789, outra solicitação de cliente (abc123) chega e também exige que Method1 seja executado por ActorId2. No entanto, a segunda execução de Method1 não é iniciada até que a execução anterior seja concluída. Da mesma forma, um lembrete registrado por ActorId2 é acionado enquanto Method1 está sendo executado em resposta à solicitação do cliente xyz789. O retorno de chamada de lembrete é executado somente depois que ambas as execuções de Method1 são concluídas. Tudo isso se deve à simultaneidade baseada em turno que está sendo imposta para ActorId2.
- Da mesma forma, a simultaneidade baseada em turno também é imposta para ActorId1, como demonstrado pela execução de Method1, Method2 e do retorno de chamada do temporizador em nome de ActorId1 que ocorre de maneira serial.
- A execução de Method1 em nome de ActorId1 é sobreposta por sua execução em nome de ActorId2. Isso porque a simultaneidade baseada em turno é imposta apenas em um ator, e não entre atores.
- Em algumas das execuções de método/retorno de chamada, a
Task(C#) /CompletableFuture(Java) retornada pelo método/retorno de chamada é concluída após o retorno do método. Em outras, a operação assíncrona já terá sido concluída quando o método/retorno de chamada for retornado. Em ambos os casos, o bloqueio por ator será liberado apenas depois que o método e o retorno de chamada forem retornados e a operação assíncrona for concluída.
Reentrada
O runtime dos Atores permite reentrância por padrão. Isso significa que, se um método de ator do Ator A chamar um método no Ator B, que, por sua vez, chamar outro método no Ator A, esse método terá permissão para ser executado. Isso ocorre porque ele faz parte do mesmo contexto lógico da cadeia de chamadas. Todas as chamadas de temporizador e lembrete começam com o novo contexto lógico de chamada. Veja Reentrância dos Reliable Actors para obter mais detalhes.
Escopo de garantias de simultaneidade
O runtime dos Atores fornece essas garantias de simultaneidade em situações em que ele controla a invocação desses métodos. Por exemplo, ele fornece essas garantias para as invocações de método que são feitas em resposta à solicitação de cliente, bem como para retornos de chamada de temporizador e lembrete. No entanto, se o código de ator envolver diretamente esses métodos fora dos mecanismos fornecidos pelo runtime dos Atores, o runtime não poderá fornecer nenhuma garantia de simultaneidade. Por exemplo, se o método for invocado no contexto de alguma tarefa que não está associada à tarefa retornada pelos métodos de ator, o runtime não poderá fornecer garantias de simultaneidade. Se o método for chamado de um thread criado pelo ator por conta própria, o runtime também não poderá fornecer garantias de simultaneidade. Portanto, para executar operações em segundo plano, os atores devem usar temporizadores e lembretes de ator que respeitam a simultaneidade baseada em turno.
Próximas etapas
Comece criando seu primeiro serviço de Reliable Actors: